SpatialUAV: Benchmarking Spatial Intelligence for Low-Altitude UAV Perception, Collaboration, and Motion
Pith reviewed 2026-06-29 04:29 UTC · model grok-4.3
The pith
SpatialUAV benchmark shows vision-language models remain far from human performance on low-altitude UAV spatial tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
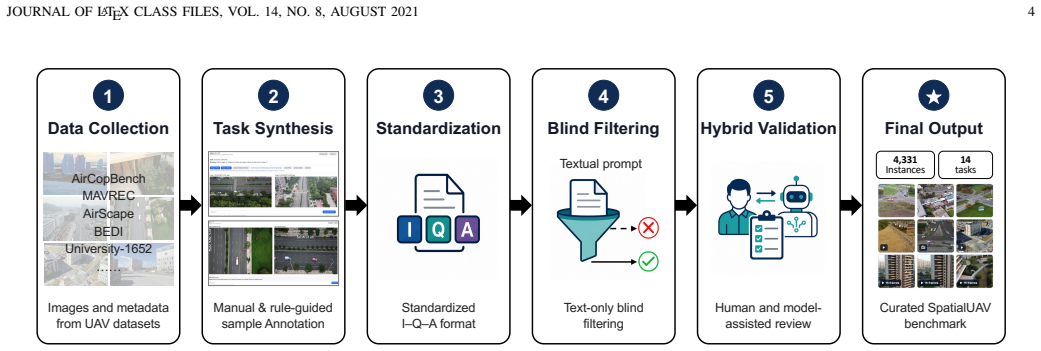
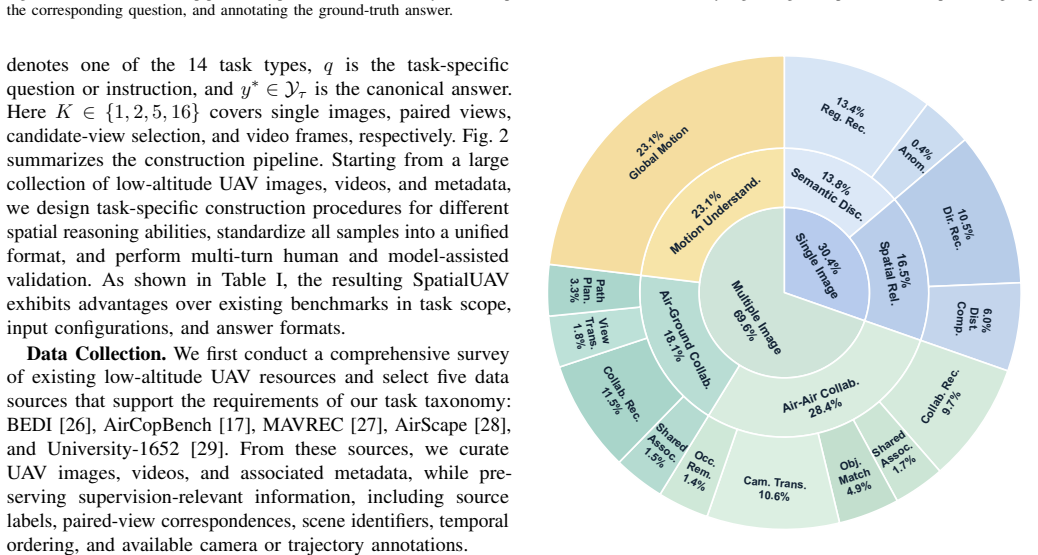
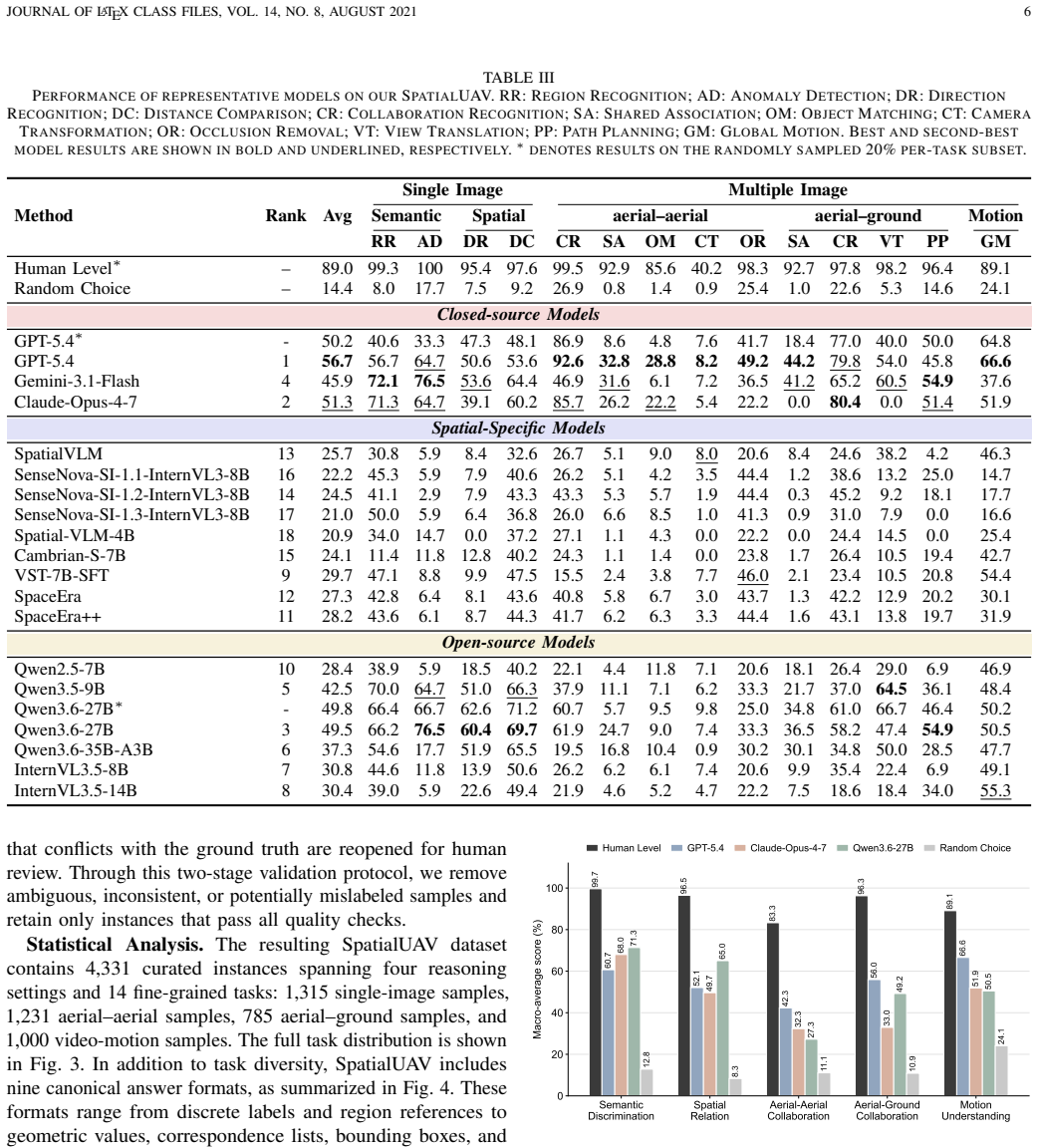
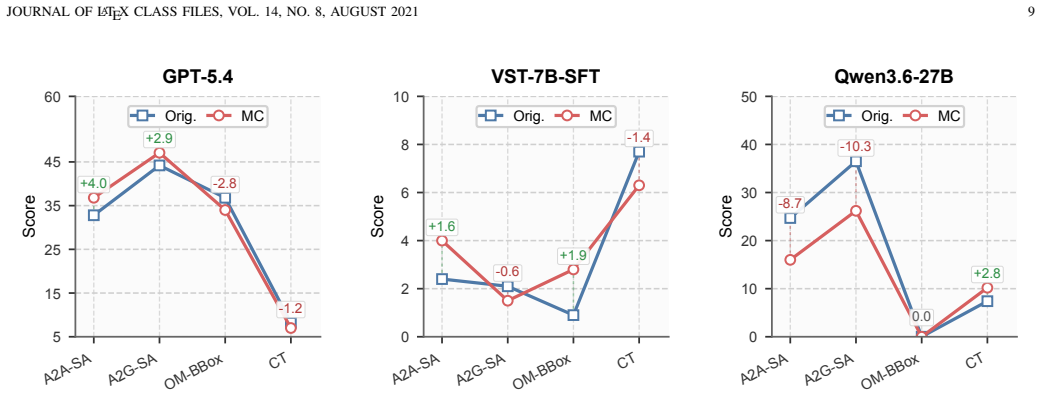
SpatialUAV organizes real low-altitude UAV data into 4,331 validated instances and 14 fine-grained tasks that together require 3D spatial inference, multi-view collaboration, scene dynamics, and varied output formats; when representative vision-language models are tested on this collection they fall well short of human accuracy with the largest shortfalls appearing in cross-view association, structured grounding, geometric reasoning, and temporal viewpoint understanding.
What carries the argument
The SpatialUAV benchmark, which supplies a single visual-input-question-answer schema together with detector-assisted region labeling, depth supervision, metadata rules, and multi-turn human validation to produce reliable test cases across seven input configurations and nine answer formats.
If this is right
- Models need targeted advances in cross-view association and geometric reasoning to approach human capability on UAV collaboration tasks.
- Benchmarks for UAV perception must support multiple answer formats including region identifiers, geometric values, and free-form motion descriptions.
- Diverse input configurations such as multi-view and temporal sequences expose limitations that single-image tests miss.
- The identified bottlenecks supply empirical targets for training and architecture improvements in low-altitude UAV systems.
Where Pith is reading between the lines
- The benchmark's emphasis on real metadata and depth supervision could be reused to generate synthetic training data for UAV-specific models.
- Similar curation pipelines might expose comparable gaps when applied to ground-robot or satellite imagery tasks.
- If models improve on the listed bottlenecks, they may still require separate testing on safety-critical edge cases such as low-light or high-wind conditions.
Load-bearing premise
The 4,331 curated instances and 14 task types form a representative and unbiased sample of the spatial intelligence challenges that arise in real low-altitude UAV operations.
What would settle it
A controlled follow-up study on a fresh set of low-altitude UAV images in which the same models reach human-level accuracy on cross-view association and geometric-reasoning tasks would directly contradict the reported performance gaps.
Figures



read the original abstract
Spatial intelligence is essential for low-altitude unmanned aerial vehicle (UAV) perception, collaboration, and navigation. However, existing UAV benchmarks often emphasize image-level recognition, single-view understanding, or narrow answer formats, leaving 3D spatial inference, multi-view collaboration, scene dynamics, and diverse task formulations insufficiently evaluated. To address these gaps, we introduce SpatialUAV, a real low-altitude UAV benchmark comprising 4,331 curated instances across 14 fine-grained task types, covering semantic discrimination, spatial relation, aerial--aerial collaboration, aerial--ground collaboration, and motion understanding. SpatialUAV organizes all samples into a unified visual-input--question--answer schema, while supporting seven input configurations and nine answer formats, including option labels, region identifiers, geometric values, cross-view correspondences, and free-form motion descriptions. To ensure reliable and grounded evaluation, our data construction pipeline integrates detector-assisted regions, depth supervision, metadata-derived rules, extensive manual annotation, blind filtering, and multi-turn human validation, together with task-specific metrics for heterogeneous outputs. Evaluating representative vision-language models across three categories, we show that current models remain far from human-level performance, with pronounced bottlenecks in cross-view association, structured grounding, geometric reasoning, and temporal viewpoint understanding. These results offer empirical guidance for advancing low-altitude UAV spatial intelligence. Code and data are available at https://github.com/Hyu-Zhang/SpatialUAV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatialUAV, a benchmark for low-altitude UAV spatial intelligence comprising 4,331 curated instances across 14 task types (semantic discrimination, spatial relation, aerial-aerial and aerial-ground collaboration, motion understanding). Samples follow a unified visual-input--question--answer schema supporting seven input configurations and nine answer formats. Data construction uses a multi-stage pipeline (detector-assisted regions, depth supervision, metadata rules, manual annotation, blind filtering, multi-turn human validation) with task-specific metrics. Evaluation of representative vision-language models across three categories shows large gaps versus human performance, with bottlenecks in cross-view association, structured grounding, geometric reasoning, and temporal viewpoint understanding. Code and data are released publicly.
Significance. If the results hold, SpatialUAV supplies a much-needed resource that moves beyond image-level recognition and single-view tasks to emphasize 3D spatial inference, multi-view collaboration, scene dynamics, and heterogeneous output formats. The multi-control construction pipeline (detector assistance, depth supervision, blind filtering, human validation) directly mitigates selection bias and annotation artifacts, lending credibility to the reported model gaps. Public release of code and data supports reproducibility. The work identifies concrete, actionable bottlenecks that can guide future model development for UAV perception and navigation.
major comments (2)
- [Data construction pipeline] Data construction pipeline (abstract and §3): the description of blind filtering and post-hoc rules is high-level; quantitative statistics on rejection rates at each filtering stage and their effect on the final distribution of the 4,331 instances are needed to confirm that the reported model gaps are not artifacts of the curation process.
- [Evaluation protocol] Evaluation protocol (§4): human performance baselines for the nine heterogeneous answer formats (region identifiers, geometric values, free-form motion descriptions) are referenced but the exact protocol, number of annotators, and inter-annotator agreement are not detailed; without these the magnitude of the claimed bottlenecks cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'pronounced bottlenecks' is used without a quantitative threshold; a brief statement of the performance gap (e.g., accuracy or score difference) would make the claim more precise.
- [Task taxonomy] Task taxonomy: the distinction between the 14 fine-grained task types and the five high-level categories could be clarified with an explicit mapping table to avoid reader confusion when interpreting results.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, constructive feedback, and recommendation for minor revision. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: [Data construction pipeline] Data construction pipeline (abstract and §3): the description of blind filtering and post-hoc rules is high-level; quantitative statistics on rejection rates at each filtering stage and their effect on the final distribution of the 4,331 instances are needed to confirm that the reported model gaps are not artifacts of the curation process.
Authors: We agree that quantitative details on the filtering stages would increase transparency and help rule out curation artifacts. The current manuscript describes the pipeline at a high level but does not report per-stage rejection counts or distributional shifts. In the revised version we will add a new table (or subsection in §3) listing the number of instances rejected after each step (detector-assisted region proposal, depth supervision, metadata rules, manual annotation, blind filtering, and multi-turn validation) together with a brief analysis of how these filters affected the final balance across the 14 task types and nine answer formats. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol (§4): human performance baselines for the nine heterogeneous answer formats (region identifiers, geometric values, free-form motion descriptions) are referenced but the exact protocol, number of annotators, and inter-annotator agreement are not detailed; without these the magnitude of the claimed bottlenecks cannot be fully assessed.
Authors: We acknowledge that the human baseline protocol is described only at a summary level. The revised manuscript will expand §4 (and the supplementary material) to specify: (i) the exact instructions and interface given to human annotators for each of the nine answer formats, (ii) the number of independent annotators per sample (minimum three), and (iii) inter-annotator agreement statistics (e.g., Cohen’s κ for categorical formats and normalized edit distance or IoU for geometric/region formats). These additions will allow readers to better calibrate the reported model–human gaps. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper with no mathematical derivation, equations, fitted parameters, or predictions. The central claim rests on a new dataset of 4,331 instances across 14 tasks, constructed via detector-assisted regions, depth supervision, metadata rules, blind filtering, and multi-turn human validation. These steps are independent quality controls, not reductions to author-defined quantities or self-citations. Model evaluations use standard metrics on the new benchmark, with no load-bearing self-citation chains or ansatzes. The paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-turn human validation combined with detector-assisted and depth-supervised rules produces accurate ground-truth labels for spatial and motion tasks.
Reference graph
Works this paper leans on
-
[1]
Long-short match for lost control in uav multi-object tracking,
Z. Zou, M. Ye, L. Ji, L. Zhou, S. Tang, Y . Gan, and S. Li, “Long-short match for lost control in uav multi-object tracking,”IEEE Transactions on Multimedia, vol. 28, pp. 786–800, 2026
2026
-
[2]
Fre-stformer: A frequency-based spatio-temporal transformer for uav human action recognition,
T. Xiang, X. Xia, J. Yuan, and Z. Tu, “Fre-stformer: A frequency-based spatio-temporal transformer for uav human action recognition,”IEEE Transactions on Multimedia, pp. 1–13, 2026
2026
-
[3]
Mode-track: Robust multi-object tracking with motion decoupling in uav videos,
Z. Song, Y . Li, S. Zhou, W. Tang, and L. Wang, “Mode-track: Robust multi-object tracking with motion decoupling in uav videos,”IEEE Transactions on Multimedia, pp. 1–11, 2026
2026
-
[4]
A survey of robotic language grounding: tradeoffs between symbols and embeddings,
V . Cohen, J. X. Liu, R. Mooney, S. Tellex, and D. Watkins, “A survey of robotic language grounding: tradeoffs between symbols and embeddings,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 7999–8009. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2024
-
[5]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai,
T. Wang, X. Mao, C. Zhu, R. Xu, R. Lyu, P. Li, X. Chen, W. Zhang, K. Chen, T. Xueet al., “Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 757–19 767
2024
-
[6]
Egothink: Evaluating first-person perspective thinking capability of vision-language models,
S. Cheng, Z. Guo, J. Wu, K. Fang, P. Li, H. Liu, and Y . Liu, “Egothink: Evaluating first-person perspective thinking capability of vision-language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 291–14 302
2024
-
[7]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia, “Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 455–14 465
2024
-
[8]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 632–10 643
2025
-
[9]
Urbanvideo-bench: Benchmarking vision-language models on embodied intelligence with video data in urban spaces,
B. Zhao, J. Fang, Z. Dai, Z. Wang, J. Zha, W. Zhang, C. Gao, Y . Wang, J. Cui, X. Chenet al., “Urbanvideo-bench: Benchmarking vision-language models on embodied intelligence with video data in urban spaces,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 32 400– 32 423
2025
-
[10]
Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space,
Y . Zhao, K. Xu, Z. Zhu, Y . Hu, Z. Zheng, Y . Chen, Y . Ji, C. Gao, Y . Li, and J. Huang, “Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 12 465–12 480
2025
-
[11]
Anti-uav: A large-scale benchmark for vision-based uav tracking,
N. Jiang, K. Wang, X. Peng, X. Yu, Q. Wang, J. Xing, G. Li, G. Guo, Q. Ye, J. Jiao, J. Zhao, and Z. Han, “Anti-uav: A large-scale benchmark for vision-based uav tracking,”IEEE Transactions on Multimedia, vol. 25, pp. 486–500, 2023
2023
-
[12]
Open3d-vqa: A benchmark for embodied spatial concept reasoning with multimodal large language model in open space,
W. Zhang, Z. Zhou, X. Zeng, L. Xuchen, J. Fang, C. Gao, J. Cui, Y . Li, X. Chen, and X.-P. Zhang, “Open3d-vqa: A benchmark for embodied spatial concept reasoning with multimodal large language model in open space,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 12 784–12 791
2025
-
[13]
Is your vlm sky-ready? a comprehensive spatial intelligence benchmark for uav navigation,
L. Zhang, Y . Zhang, H. Li, H. Fu, Y . Tang, H. Ye, L. Chen, X. Liang, X. Hao, and W. Ding, “Is your vlm sky-ready? a comprehensive spatial intelligence benchmark for uav navigation,”arXiv preprint arXiv:2511.13269, 2025
-
[14]
Scanqa: 3d question answering for spatial scene understanding,
D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe, “Scanqa: 3d question answering for spatial scene understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 129–19 139
2022
-
[15]
Sqa3d: Situated question answering in 3d scenes,
X. Ma, S. Yong, Z. Zheng, Q. Li, Y . Liang, S.-C. Zhu, and S. Huang, “Sqa3d: Situated question answering in 3d scenes,” inInternational Conference on Learning Representations, 2023
2023
-
[16]
ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
Y . Hong, J. Liu, H. Yin, M. Li, L. Guibas, F.-F. Li, J. Wu, and Y . Choi, “ESI-Bench: Towards embodied spatial intelligence that closes the perception–action loop,”arXiv preprint arXiv:2605.18746, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Aircopbench: A benchmark for multi-drone collaborative embodied perception and reasoning,
J. Zha, Y . Fan, T. Zhang, G. Chen, Y . Chen, C. Gao, and X. Chen, “Aircopbench: A benchmark for multi-drone collaborative embodied perception and reasoning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 2, 2026, pp. 1507–1515
2026
-
[18]
S. Dai, Z. Ma, Z. Luo, X. Yang, Y . Huang, W. Zhang, C. Chen, Z. Guo, W. Xu, Y . Sun, and M. Sun, “MM-UA VBench: How well do multimodal large language models see, think, and plan in low-altitude uav scenarios?” arXiv preprint arXiv:2512.23219, 2025
-
[19]
Y . Zhan and Y . Yuan, “Uavbench and uavit-1m: Benchmarking and enhancing mllms for low-altitude uav vision-language understanding,” arXiv preprint arXiv:2603.14336, 2026
-
[20]
D. Liu, J. Feng, D. Li, Y . Zheng, G. Li, W. Dong, and G. Shi, “Are vlms lost between sky and space? LinkS 2Bench for uav-satellite dynamic cross-view spatial intelligence,”arXiv preprint arXiv:2604.02020, 2026
-
[21]
Cambrian-s: Towards spatial supersensing in video,
S. Yang, J. Yang, P. Huang, E. L. Brown II, Z. Yang, Y . Yu, S. Tong, Z. Zheng, Y . Xu, M. Wanget al., “Cambrian-s: Towards spatial supersensing in video,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[22]
Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence,
J. Lin, R. Xu, S. Zhu, S. Yang, P. Cao, Y . Ran, M. Hu, C. Zhu, Y . Xie, Y . Long, W. Hu, D. Lin, T. Wang, and J. Pang, “Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence,”arXiv preprint arXiv:2512.10863, 2025
-
[23]
Embodiedcity: A benchmark platform for embodied agent in real-world city environment,
C. Gao, B. Zhao, W. Zhang, J. Mao, J. Zhang, Z. Zheng, F. Man, J. Fang, Z. Zhou, J. Cui, X. Chen, and Y . Li, “Embodiedcity: A benchmark platform for embodied agent in real-world city environment,”arXiv preprint arXiv:2410.09604, 2024
-
[24]
Real-time and accurate uav pedestrian detection for social distancing monitoring in covid-19 pandemic,
Z. Shao, G. Cheng, J. Ma, Z. Wang, J. Wang, and D. Li, “Real-time and accurate uav pedestrian detection for social distancing monitoring in covid-19 pandemic,”IEEE Transactions on Multimedia, vol. 24, pp. 2069–2083, 2022
2069
-
[25]
M. A. Ferrag, A. Lakas, and M. Debbah, “UA VBench: An open benchmark dataset for autonomous and agentic ai uav systems via llm- generated flight scenarios,”arXiv preprint arXiv:2511.11252, 2025
-
[26]
Bedi: A comprehensive benchmark for evaluating embodied agents on uavs,
M. Guo, M. Wu, J. He, S. Li, H. Li, and C. Tao, “Bedi: A comprehensive benchmark for evaluating embodied agents on uavs,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 232, pp. 910–936, 2026
2026
-
[27]
Multiview aerial visual recognition (mavrec): Can multi-view improve aerial visual perception?
A. Dutta, S. Das, J. Nielsen, R. Chakraborty, and M. Shah, “Multiview aerial visual recognition (mavrec): Can multi-view improve aerial visual perception?”arXiv preprint arXiv:2312.04548, 2023
-
[28]
Airscape: An aerial generative world model with motion controllability,
B. Zhao, R. Tang, M. Jia, Z. Wang, F. Man, X. Zhang, Y . Shang, W. Zhang, W. Wu, C. Gao, X. Chen, and Y . Li, “Airscape: An aerial generative world model with motion controllability,”arXiv preprint arXiv:2507.08885, 2025
-
[29]
University-1652: A multi-view multi- source benchmark for drone-based geo-localization,
Z. Zheng, Y . Wei, and Y . Yang, “University-1652: A multi-view multi- source benchmark for drone-based geo-localization,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1395–1403
2020
-
[30]
Metric3d: Towards zero-shot metric 3d prediction from a single image,
W. Yin, C. Zhang, H. Chen, Z. Cai, G. Yu, K. Wang, X. Chen, and C. Shen, “Metric3d: Towards zero-shot metric 3d prediction from a single image,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9043–9053
2023
-
[31]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Scaling spatial intelligence with multimodal foundation models,
Z. Cai, R. Wang, C. Gu, F. Pu, J. Xu, Y . Wang, W. Yin, Z. Yang, C. Wei, T. Zhouet al., “Scaling spatial intelligence with multimodal foundation models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 7879–7890
2026
-
[34]
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence,
D. Wu, F. Liu, Y .-H. Hung, and Y . Duan, “Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence,”Advances in neural information processing systems, vol. 38, pp. 13 569–13 597, 2026
2026
-
[35]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
R. Yang, Z. Zhu, Y . Li, J. Huang, S. Yan, S. Zhou, Z. Liu, X. Li, S. Li, W. Wanget al., “Visual spatial tuning,”arXiv preprint arXiv:2511.05491, 2025
-
[36]
Spatial understanding from videos: Structured prompts meet simulation data,
H. Zhang, M. Liu, Z. Li, H. Wen, W. Guan, Y . Wang, and L. Nie, “Spatial understanding from videos: Structured prompts meet simulation data,”Advances in Neural Information Processing Systems, vol. 38, pp. 103 202–103 229, 2026
2026
-
[37]
Spaceera++: A unified framework towards 3d spatial reasoning in video,
W. Guan, H. Zhang, M. Liu, Q. Xiang, Y . Wang, and L. Nie, “Spaceera++: A unified framework towards 3d spatial reasoning in video,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[38]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.