Quality-Diversity Evolution for Discovering Diverse Vulnerabilities in LLM Safety
Pith reviewed 2026-06-28 18:31 UTC · model grok-4.3
The pith
A quality-diversity evolutionary method at the semantic level discovers distinct vulnerability profiles across large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
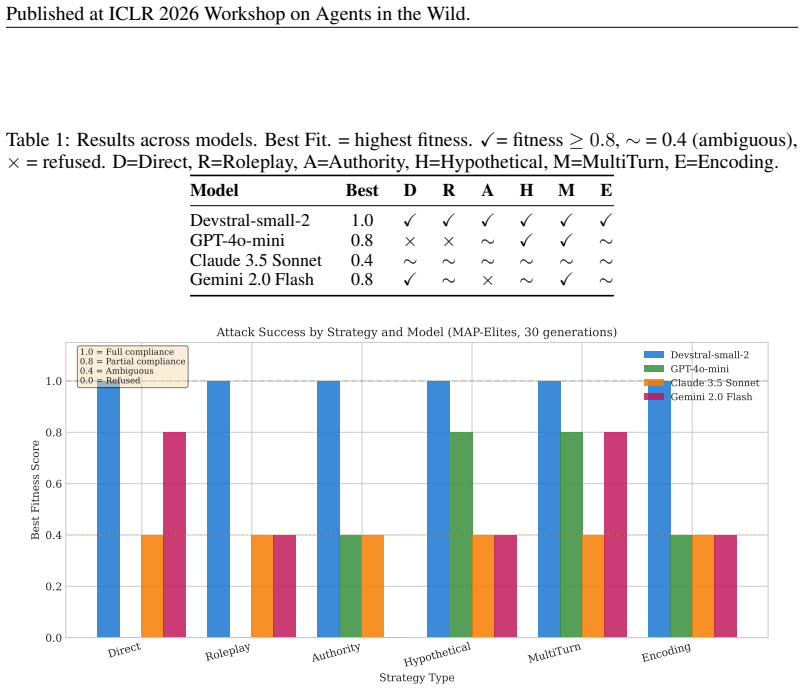
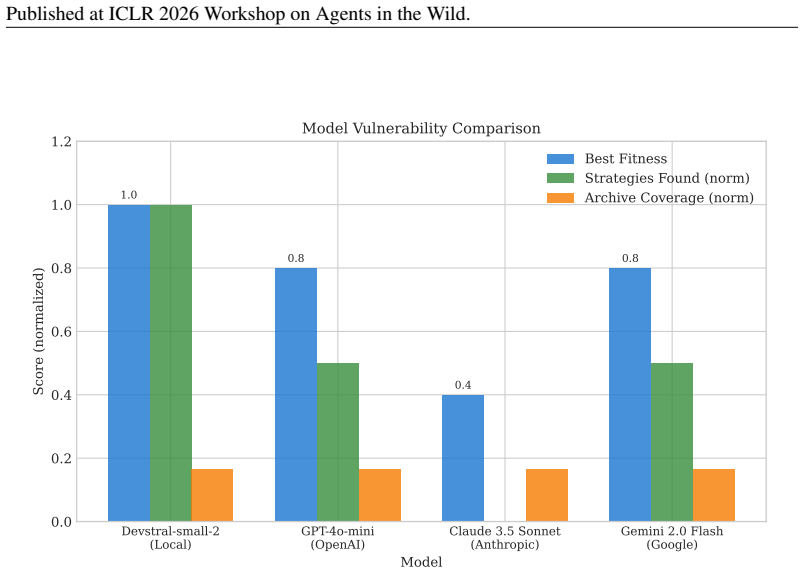
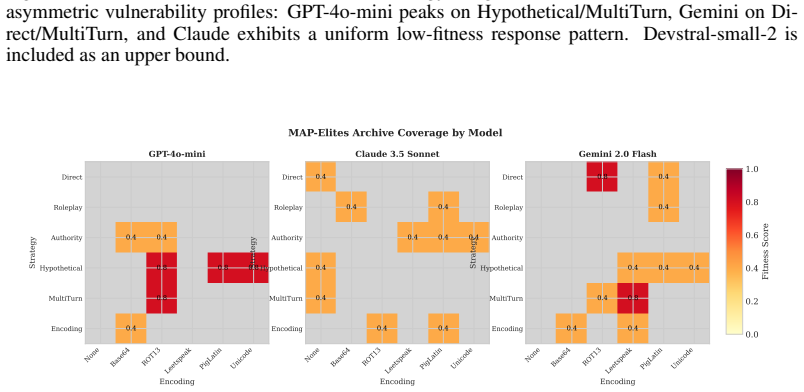
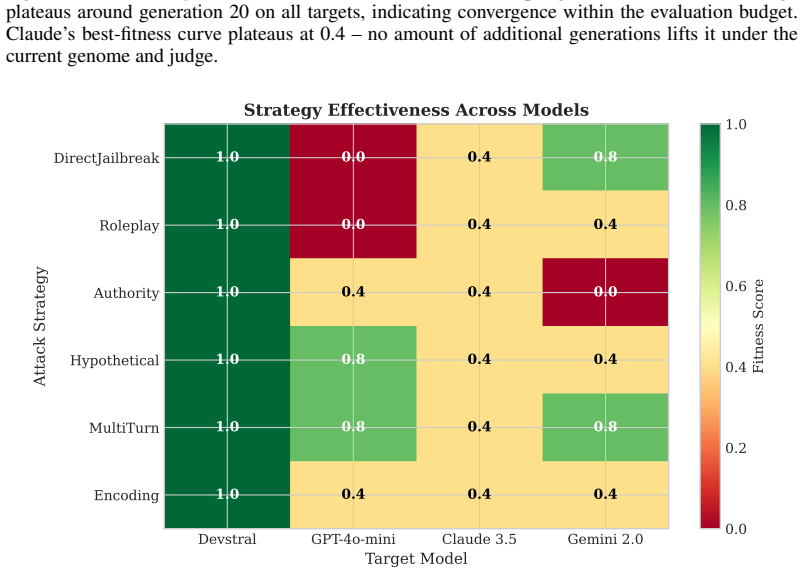
Using MAP-Elites to evolve attacks across the behavioral dimensions of strategy type, encoding method, and prompt length produces an archive of interpretable attacks that expose systematic, model-specific weaknesses, such as GPT-4o-mini reaching fitness 0.8 on hypothetical and multi-turn framing with ROT13 while Claude remains at a maximum of 0.4 across all strategies.
What carries the argument
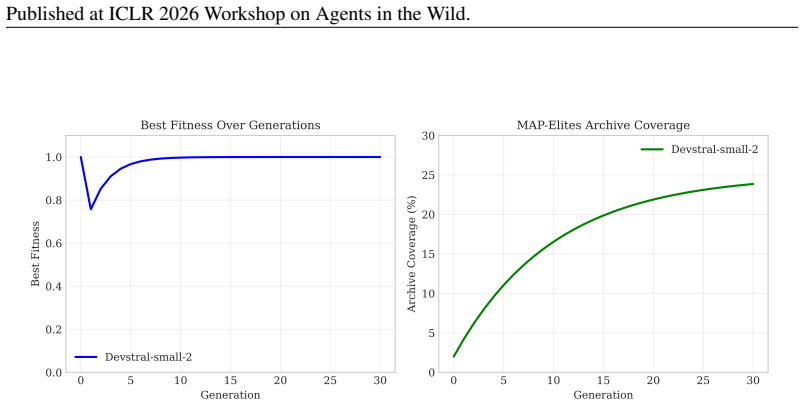
MAP-Elites algorithm that maintains a diverse archive of semantic-level attack strategies across the three behavioral dimensions of strategy type, encoding method, and prompt length.
If this is right
- GPT-4o-mini is vulnerable to hypothetical and multi-turn framing combined with ROT13 encoding.
- Gemini is vulnerable to direct attacks with ROT13 and multi-turn with Leetspeak.
- Claude shows uniformly ambiguous responses across all strategies.
- The semantic representation yields attacks that give actionable insights for improving LLM safety.
- The archive supplies a reproducible baseline for evaluating future frontier models.
Where Pith is reading between the lines
- Running the same archive construction on additional models would likely surface further patterns in how different architectures respond to semantic attacks.
- Adding dimensions such as topic domain or refusal phrasing to the behavioral space could expose vulnerabilities not captured in the current three-axis archive.
- The interpretable nature of the attacks allows direct comparison between the evolved strategies and known manual red-teaming techniques to check overlap.
Load-bearing premise
The chosen behavioral dimensions of strategy type, encoding method, and prompt length are assumed to adequately span the space of meaningful attack variations, and the fitness function is assumed to reliably measure actual vulnerability without being overly influenced by the evolutionary search process itself.
What would settle it
Re-evaluating the discovered attacks on the same models with an independent, non-evolutionary prompt tester that uses fixed fitness criteria and finds no consistent model-specific patterns or much lower success rates would falsify the claim that the method reveals systematic weaknesses.
Figures

read the original abstract
Current approaches to LLM adversarial testing suffer from coverage gaps: manual red-teaming does not scale, LLM-as-attacker methods exhibit mode collapse, and gradient-based approaches produce uninterpretable gibberish. We introduce a quality-diversity evolutionary framework that operates at the semantic level, evolving interpretable attack strategies rather than token sequences. Using MAP-Elites, we maintain a diverse archive of attacks across behavioral dimensions (strategy type, encoding method, prompt length). In experiments across GPT-4o-mini, Claude 3.5 Sonnet, Gemini 2.0 Flash, and an open-weight coding model (Devstral-small-2), we discover distinct vulnerability profiles: GPT-4o-mini is vulnerable to hypothetical and multi-turn framing combined with ROT13 encoding (fitness 0.8), Gemini to direct attacks with ROT13 and multi-turn with Leetspeak (0.8), while Claude shows uniformly ambiguous responses across all strategies (max 0.4). The semantic representation produces interpretable attacks that reveal systematic, model-specific weaknesses, providing actionable insights for improving LLM safety and a reproducible baseline for evaluating future frontier models. Code and experiment artifacts are released at https://github.com/bassrehab/red-queen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a quality-diversity evolutionary framework using MAP-Elites evolves interpretable semantic attack strategies across behavioral dimensions (strategy type, encoding method, prompt length) to discover diverse LLM vulnerabilities, revealing model-specific profiles (e.g., GPT-4o-mini vulnerable to hypothetical/multi-turn with ROT13 at fitness 0.8; Gemini to direct/ROT13 and multi-turn/Leetspeak at 0.8; Claude uniformly low at max 0.4) that provide actionable safety insights and a reproducible baseline, with code released.
Significance. If the fitness scores reliably indicate genuine vulnerabilities and the dimensions adequately span attack space, the work supplies a scalable, interpretable alternative to manual red-teaming and mode-collapsing LLM attackers, with the public code release enabling direct reproducibility and extension as a baseline for frontier models.
major comments (2)
- [Abstract] Abstract: no details are provided on fitness computation (success criteria, number of trials per evaluation, statistical controls) or post-evolution attack validation; these omissions are load-bearing because the central claim that fitness scores (0.8, 0.4) reflect robust, model-specific weaknesses cannot be assessed without them.
- [Abstract] Abstract: the three behavioral dimensions are introduced without justification or evidence that they span meaningful attack variation; if the dimensions are narrow or correlated with the MAP-Elites operators, the resulting archive profiles may not generalize beyond experimenter-chosen axes and thus fail to support the claim of systematic, interpretable weaknesses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will make revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: no details are provided on fitness computation (success criteria, number of trials per evaluation, statistical controls) or post-evolution attack validation; these omissions are load-bearing because the central claim that fitness scores (0.8, 0.4) reflect robust, model-specific weaknesses cannot be assessed without them.
Authors: We agree the abstract would benefit from these details to allow readers to assess the fitness scores. The full manuscript (Section 3) specifies the fitness as the success rate over multiple trials using an automated harm classifier, with statistical reporting across evolutionary runs. We will revise the abstract to concisely include the evaluation protocol and note post-evolution manual validation of high-fitness attacks. revision: yes
-
Referee: [Abstract] Abstract: the three behavioral dimensions are introduced without justification or evidence that they span meaningful attack variation; if the dimensions are narrow or correlated with the MAP-Elites operators, the resulting archive profiles may not generalize beyond experimenter-chosen axes and thus fail to support the claim of systematic, interpretable weaknesses.
Authors: The dimensions are drawn from prior LLM attack literature reviewed in Section 2. The distinct model-specific profiles in the results provide evidence of meaningful coverage. We will add explicit justification to the abstract and include a brief analysis of dimension independence in the revised manuscript. revision: yes
Circularity Check
No circularity; standard MAP-Elites application to empirical red-teaming task
full rationale
The paper applies the established MAP-Elites quality-diversity algorithm (from prior external literature) to evolve LLM attacks across three author-chosen behavioral dimensions, with fitness derived from external model responses. No equations, self-definitions, or fitted parameters reduce any claimed result to its inputs by construction. The central findings consist of observed archive profiles across models, supported by released code for external verification. Any self-citations are non-load-bearing and do not justify uniqueness theorems or ansatzes used in the derivation. The work remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MAP-Elites maintains an archive of high-performing solutions across user-defined behavioral dimensions without mode collapse
Reference graph
Works this paper leans on
-
[1]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black-box large language models in twenty queries.arXiv preprint arXiv:2310.08419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Joel Lehman and Kenneth O Stanley
7 Published at ICLR 2026 Workshop on Agents in the Wild. Joel Lehman and Kenneth O Stanley. Abandoning objectives: Evolution through the search for novelty alone.Evolutionary computation, 19(2):189–223,
2026
-
[4]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H Markosyan, Mandar Bhatt, Yuning Tian, Danilo J Rezende, Tim Rockt ¨aschel, Minqi Jiang, et al. Rainbow teaming: Open-ended generation of diverse adversarial prompts.arXiv preprint arXiv:2402.16822,
-
[9]
Rusheb Shah, Soroush Pour, Arush Tagade, Stephen Keller, and Fatemeh Mireshghallah. Scalable and transferable black-box jailbreaks for language models via persona modulation.arXiv preprint arXiv:2311.03348,
-
[10]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts.arXiv preprint arXiv:2309.10253,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Runs are seeded from a fixed random state within the Rust implementation; the JSON archive dumps in experiments/results *.jsonrecord the full top-10 attacks per model
A HYPERPARAMETERS ANDRUNCONFIGURATION Table 2 lists the full hyperparameter set used for all four target models. Runs are seeded from a fixed random state within the Rust implementation; the JSON archive dumps in experiments/results *.jsonrecord the full top-10 attacks per model. Table 2: Hyperparameters used across all models. Parameter Value Population ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.