Autonomous Frontier-Based Exploration with VLM Guidance
Pith reviewed 2026-05-25 04:35 UTC · model grok-4.3
The pith
A VLM uses map and image prompts to select frontiers, improving robotic exploration coverage by up to 24% over geometric methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
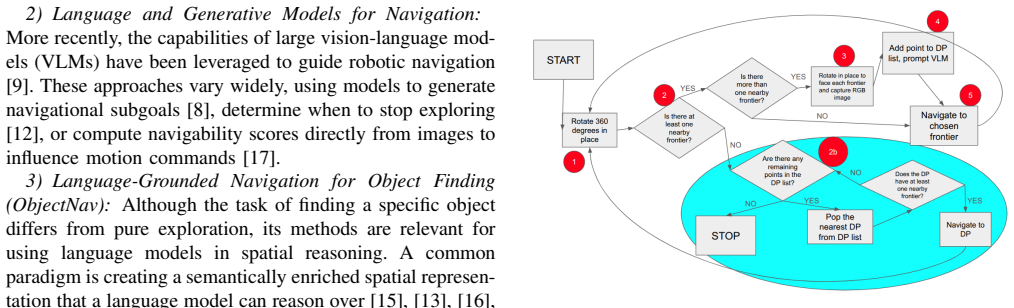
The paper establishes that incorporating a vision-language model for strategic frontier selection via multimodal prompts containing the current map and visual imagery of frontiers leads to improved exploration performance, with map coverage gains of up to 24% in six simulated indoor environments, while maintaining a lightweight and training-free pipeline compatible with standard robotic hardware.
What carries the argument
Multimodal prompt-based VLM frontier selection replacing geometric heuristics
Load-bearing premise
The vision-language model performs reliable high-level contextual spatial reasoning from the multimodal prompts to select promising frontiers.
What would settle it
A direct comparison in the same six indoor simulation environments showing that the VLM method does not achieve higher map coverage than geometric heuristic methods would falsify the performance claim.
Figures







read the original abstract
Autonomous robotic exploration of unknown and hazardous environments, a long-standing challenge, can be significantly improved by leveraging the advanced reasoning of Vision-Language Models (VLMs). We introduce a novel exploration pipeline where a VLM performs high-level strategic decision-making, guiding a conventional low-level robotics control stack. At decision points, the robot generates a multimodal prompt with its current map and visual imagery of potential paths, or frontiers. The VLM analyzes this prompt to select the most promising frontier, replacing simple geometric heuristics with contextual spatial reasoning. This approach, validated in simulation across six indoor environments, improves map coverage by up to 24\% over existing methods. Our pipeline is lightweight, training-free, and easily transferable to any robot with standard sensors and an internet connection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a frontier-based robotic exploration pipeline in which a Vision-Language Model (VLM) performs high-level frontier selection from multimodal prompts that combine the current occupancy map with visual imagery of candidate frontiers. This replaces conventional geometric heuristics with contextual spatial reasoning. The method is described as training-free and lightweight; simulation experiments across six indoor environments are reported to yield up to 24% higher map coverage than existing approaches.
Significance. If the empirical claims hold after proper controls, the work would demonstrate a practical way to inject off-the-shelf VLM reasoning into existing low-level robotics stacks, potentially improving exploration efficiency in unknown or hazardous settings without retraining or specialized hardware. The training-free and transferable character is a concrete strength that could accelerate adoption.
major comments (3)
- [Abstract] Abstract: the headline claim of 'up to 24% coverage gain' supplies no information on the exact baselines, number of trials, statistical tests, or environment parameters, preventing assessment of whether the VLM component is responsible for the reported improvement rather than other pipeline details.
- [Experiments] Experiments (or equivalent validation section): no ablation isolating the VLM selector against a pure geometric baseline, no metric of VLM decision accuracy or query-consistency, and no comparison to an oracle or random selector are presented, leaving the central assumption that 'contextual spatial reasoning' drives the gain unverified.
- [Method] Method: the description of the multimodal prompt construction and VLM output parsing does not include any failure-mode analysis or consistency statistics across repeated identical prompts, which is load-bearing for claims that the VLM reliably outperforms heuristics.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the specific VLM model and the low-level controller stack used in the experiments.
- [Figures] Figure captions should explicitly state whether the illustrated maps are from the proposed method or a baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for clarifying our experimental claims and strengthening the validation of the VLM component. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'up to 24% coverage gain' supplies no information on the exact baselines, number of trials, statistical tests, or environment parameters, preventing assessment of whether the VLM component is responsible for the reported improvement rather than other pipeline details.
Authors: We agree that the abstract should provide more context to allow readers to assess the claims. In the revised version, we will expand the abstract to specify that the up to 24% improvement is measured against standard geometric heuristics (nearest and largest frontier) in six simulated indoor environments, based on multiple trials per scene with average coverage reported. We will also note the absence of formal statistical significance tests in the original experiments. revision: yes
-
Referee: [Experiments] Experiments (or equivalent validation section): no ablation isolating the VLM selector against a pure geometric baseline, no metric of VLM decision accuracy or query-consistency, and no comparison to an oracle or random selector are presented, leaving the central assumption that 'contextual spatial reasoning' drives the gain unverified.
Authors: The current manuscript compares against existing methods but lacks dedicated ablations within the pipeline. We will add an ablation study comparing the full VLM-guided approach to a pure geometric baseline using the same low-level stack, as well as a random selector baseline. A direct metric of VLM decision accuracy is challenging without oracle labels for optimal frontiers in exploration; we will instead report query consistency on repeated prompts for a subset of decisions and discuss this as a limitation. revision: partial
-
Referee: [Method] Method: the description of the multimodal prompt construction and VLM output parsing does not include any failure-mode analysis or consistency statistics across repeated identical prompts, which is load-bearing for claims that the VLM reliably outperforms heuristics.
Authors: We acknowledge the absence of such analysis in the method section. In the revision, we will add a discussion of observed failure modes (such as occasional misinterpretation of map connectivity) and include consistency statistics obtained by re-querying the VLM on a sample of identical prompts, reporting agreement rates to support reliability claims. revision: yes
Circularity Check
No circularity; empirical validation only
full rationale
The paper describes a VLM-guided frontier selection pipeline and reports simulation results (up to 24% coverage gain across six indoor environments). No derivation chain, equations, fitted parameters, or first-principles claims are present that could reduce to inputs by construction. The result is obtained by running the described system in simulation and comparing coverage metrics; this is external to any self-referential definition or self-citation load-bearing step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can perform reliable contextual spatial reasoning from map and image prompts without fine-tuning
Reference graph
Works this paper leans on
-
[1]
A frontier-based approach for autonomous exploration,
B. Yamauchi, “A frontier-based approach for autonomous exploration,” inProc. IEEE Int. Symp. Computational Intelligence in Robotics and Automation (CIRA), 1997, pp. 146–151
work page 1997
-
[2]
Frontier Based Exploration for Autonomous Robot
A. Topiwala, P. Inani, and A. Kathpal, “Frontier based exploration for autonomous robot,”arXiv preprint arXiv:1806.03581, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Receding horizon next-best-view planner for 3D exploration,
A. Bircher, M. Kamel, K. Alexis, H. Oleynikova, and R. Siegwart, “Receding horizon next-best-view planner for 3D exploration,” in Proc. IEEE Int. Conf. Robotics and Automation (ICRA), 2016, pp. 1462–1468. (a) (b) (c) (d) (e) Fig. 10: Histograms of path revisit counts for Environment
work page 2016
-
[4]
(a) Ours, (b) Greedy, (c) OpenCV + NBV , (d) TARE, and (e) DSVP
-
[5]
FUEL: Fast UA V explo- ration using incremental frontier structure and hierarchical planning,
B. Zhou, Y . Zhang, X. Chen, and S. Shen, “FUEL: Fast UA V explo- ration using incremental frontier structure and hierarchical planning,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 779–786, 2021
work page 2021
-
[6]
Y . Zhao, L. Yan, H. Xie, J. Dai, and P. Wei, “Autonomous explo- ration method for fast unknown environment mapping by using UA V equipped with limited FoV sensor,”IEEE Trans. Ind. Electron., vol. 71, no. 5, pp. 4933–4943, 2023
work page 2023
-
[7]
F. Niroui, K. Zhang, Z. Kashino, and G. Nejat, “Deep reinforcement learning robot for search and rescue applications: Exploration in unknown cluttered environments,”IEEE Robot. Autom. Lett., vol. 4, no. 2, pp. 610–617, 2019
work page 2019
-
[8]
J. Hu, H. Niu, J. Carrasco, B. Lennox, and F. Arvin, “V oronoi-based multi-robot autonomous exploration in unknown environments via deep reinforcement learning,”IEEE Trans. Veh. Technol., vol. 69, no. 12, pp. 14413–14423, 2020
work page 2020
-
[9]
VLM guided exploration via image subgoal synthesis,
A. Bhorkar, “VLM guided exploration via image subgoal synthesis,” 2024, unpublished
work page 2024
-
[10]
ViNT: A foundation model for visual navigation,
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine, “ViNT: A foundation model for visual navigation,” arXiv preprint arXiv:2306.14846, 2023
-
[11]
Nomad: Goal masked diffusion policies for navigation and exploration,
A. Sridhar, D. Shah, C. Glossop, and S. Levine, “Nomad: Goal masked diffusion policies for navigation and exploration,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2024, pp. 63–70
work page 2024
-
[12]
H. Luo, Y . Zeng, L. Yang, K. Chen, Z. Shen, and F. Lv, “VLAI: Explo- ration and exploitation based on visual-language aligned information for robotic object goal navigation,”Image Vis. Comput., vol. 151, p. 105259, 2024
work page 2024
-
[13]
Explore until confident: Efficient exploration for embodied question answering,
A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh, “Explore until confident: Efficient exploration for embodied question answering,”arXiv preprint arXiv:2403.15941, 2024
-
[14]
HuLE-Nav: Human-like exploration for zero-shot object navigation via vision-language mod- els,
P. Han, M. Zhang, H. Tang, Y . Zheng,et al., “HuLE-Nav: Human-like exploration for zero-shot object navigation via vision-language mod- els,” inProc. NeurIPS Workshop on Behavioral Machine Learning, 2024
work page 2024
-
[15]
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batra,et al., “Goat: Go to any thing,” arXiv preprint arXiv:2311.06430, 2023
-
[16]
VLFM: Vision-language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “VLFM: Vision-language frontier maps for zero-shot semantic navigation,” in Proc. IEEE Int. Conf. Robotics and Automation (ICRA), 2024, pp. 42–48
work page 2024
-
[17]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,”arXiv preprint arXiv:2210.05714, 2022
-
[18]
ClipRover: Zero-shot vision-language exploration and target discovery by mobile robots,
Y . Zhang, A. Abdullah, S. Koppal, and M. J. Islam, “ClipRover: Zero-shot vision-language exploration and target discovery by mobile robots,”arXiv preprint arXiv:2502.08791, 2025
-
[19]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3D: Learning from RGB- D data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
M. Labb ´e and F. Michaud, “RTAB-Map as an open-source lidar and visual SLAM library for large-scale and long-term online operation,” LIDAR, vol. 24, 2018
work page 2018
-
[21]
Habitat: A platform for embodied AI research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik,et al., “Habitat: A platform for embodied AI research,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2019, pp. 9339–9347
work page 2019
-
[22]
ROS-x-Habitat: Bridging the ROS ecosystem with embodied AI,
G. Chen, H. Yang, and I. M. Mitchell, “ROS-x-Habitat: Bridging the ROS ecosystem with embodied AI,” inProc. Conf. Robots and Vision (CRV), 2022, pp. 24–31
work page 2022
-
[23]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen,et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “GPT-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
TARE: A hierarchical framework for efficiently exploring complex 3D environments,
C. Cao, H. Zhu, H. Choset, and J. Zhang, “TARE: A hierarchical framework for efficiently exploring complex 3D environments,” in Proc. Robotics: Science and Systems (RSS), 2021, vol. 5, p. 2
work page 2021
-
[26]
Autonomous robotic exploration based on multiple rapidly-exploring randomized trees,
H. Umari and S. Mukhopadhyay, “Autonomous robotic exploration based on multiple rapidly-exploring randomized trees,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2017, pp. 1396–1402
work page 2017
-
[27]
DSVP: Dual-stage viewpoint planner for rapid exploration by dynamic ex- pansion,
H. Zhu, C. Cao, Y . Xia, S. Scherer, J. Zhang, and W. Wang, “DSVP: Dual-stage viewpoint planner for rapid exploration by dynamic ex- pansion,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2021, pp. 7623–7630
work page 2021
-
[28]
Autonomous exploration development environment and the planning algorithms,
C. Cao, H. Zhu, F. Yang, Y . Xia, H. Choset, J. Oh, and J. Zhang, “Autonomous exploration development environment and the planning algorithms,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2022, pp. 8921–8928
work page 2022
-
[29]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wang,et al., “A survey on evaluation of large language models,”ACM Trans. Intell. Syst. Technol., vol. 15, no. 3, pp. 1–45, 2024
work page 2024
-
[30]
LM-Nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osi ´nski, and S. Levine, “LM-Nav: Robotic navigation with large pre-trained models of language, vision, and action,” inProc. Conf. Robot Learning, 2023, pp. 492–504
work page 2023
-
[31]
Timed-elastic-bands for time-optimal point-to-point nonlinear model predictive control,
C. R ¨osmann, F. Hoffmann, and T. Bertram, “Timed-elastic-bands for time-optimal point-to-point nonlinear model predictive control,” in Proc. European Control Conf. (ECC), 2015, pp. 3352–3357
work page 2015
-
[32]
Design and use paradigms for gazebo, an open-source multi-robot simulator,
N. Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2004, vol. 3, pp. 2149–2154
work page 2004
-
[33]
A flexible and scalable SLAM system with full 3D motion estimation,
S. Kohlbrecher, J. Meyer, O. von Stryk, and U. Klingauf, “A flexible and scalable SLAM system with full 3D motion estimation,” inProc. IEEE Int. Symp. Safety, Security and Rescue Robotics (SSRR), 2011
work page 2011
-
[34]
Map-merging for multi-robot system,
J. H ¨orner, “Map-merging for multi-robot system,” Bachelor’s thesis, Charles University in Prague, Faculty of Mathematics and Physics, 2016
work page 2016
-
[35]
E. Marder-Eppstein, “move base ROS package,” 2020. [Online]. Avail- able: http://wiki.ros.org/move base
work page 2020
-
[36]
HiWonder Hexapod Spi- derPi Robot,
HiWonder, “HiWonder Hexapod Spi- derPi Robot,” 2025. [Online]. Available: https://www.hiwonder.com/products/spiderpi?variant=40213126381655
work page 2025
-
[37]
Autonomous frontier-based exploration with high-level VLM guidance,
Aarush Aitha, “Autonomous frontier-based exploration with high-level VLM guidance,” Master’s thesis, EECS Department, University of California, Berkeley, Aug. 2025. [Online]. Available: http://www2.eecs.berkeley.edu/Pubs/TechRpts/2025/EECS-2025- 172.html
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.