Guidance Contrastive Token Credit Assignment for Discrete Policy Optimization
Pith reviewed 2026-06-29 08:56 UTC · model grok-4.3
The pith
GCPO assigns token-level advantages proportional to prediction differences under positive and negative prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
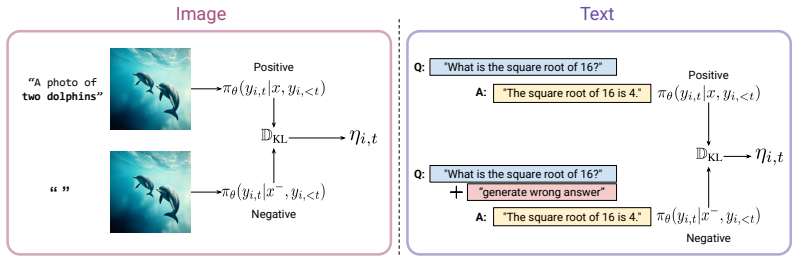
Rather than broadcasting sample-level advantages uniformly, GCPO assigns token-level advantages proportional to the difference between model predictions under positive and negative prompts, supplying finer-grained credit assignment for discrete policy optimization.
What carries the argument
The difference between contrastive model predictions under positive and negative prompts, used to scale token-level advantages.
If this is right
- Token-level advantages become more precise and informative than uniform sample-level rewards.
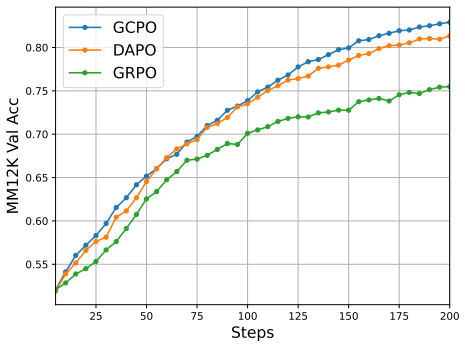
- GCPO consistently outperforms GRPO and DAPO on text-to-image generation benchmarks.
- GCPO consistently outperforms GRPO and DAPO on chain-of-thought reasoning benchmarks.
- The method emphasizes semantically relevant visual regions aligned with prompts and critical keywords in reasoning traces.
Where Pith is reading between the lines
- The same contrast mechanism could be tested on other discrete sequence tasks such as code generation.
- Performance may depend on careful design of the positive and negative prompt pairs in ways the experiments do not fully vary.
- GCPO could be combined with existing advantage estimators to further refine the token signals.
Load-bearing premise
The difference in model predictions under positive and negative prompts accurately isolates each token's contribution to the sample reward without systematic bias from prompt construction.
What would settle it
An ablation that replaces the positive and negative prompts with unrelated prompts and measures whether the performance gains over GRPO and DAPO disappear.
Figures









read the original abstract
Group-advantage-based reinforcement learning methods, such as GRPO and DAPO, have demonstrated strong performance across diverse domains, including mathematical reasoning and text-to-image generation. However, their reliance on sample-level rewards introduces a key limitation as uniform credit assignment across all tokens fails to capture fine-grained, token-level contributions. To address this issue, we propose Guidance Contrastive Policy Optimization (GCPO), a novel algorithm that enables per-token credit assignment by contrasting model predictions under positive and negative prompts. Rather than uniformly broadcasting sample-level advantages, GCPO assigns token-level advantages proportional to the difference between these contrastive predictions, allowing more precise and informative learning signals. Empirically, we find that GCPO emphasizes semantically relevant regions such as visual areas aligned with textual prompts in text-to-image generation, and critical keywords within reasoning traces for chain-of-thought tasks. Through extensive experiments, GCPO consistently outperforms GRPO and DAPO baselines on both text-to-image generation and chain-of-thought reasoning benchmarks, demonstrating its effectiveness as a general and scalable optimization strategy for discrete policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Guidance Contrastive Policy Optimization (GCPO) as an extension to group-advantage RL methods such as GRPO and DAPO. GCPO enables per-token credit assignment by defining token-level advantages as proportional to the difference in model predictions (or logits) conditioned on positive versus negative prompts, rather than broadcasting uniform sample-level advantages. The authors claim this yields more precise learning signals, emphasizes semantically relevant tokens (e.g., prompt-aligned visual regions or critical keywords in CoT traces), and produces consistent empirical gains over the baselines on text-to-image generation and chain-of-thought reasoning benchmarks.
Significance. If the core construction is shown to isolate token contributions without systematic bias and the reported gains are reproducible with standard statistical controls, GCPO would address a recognized limitation of sample-level reward propagation in discrete policy optimization. The approach is general and could scale to other generation tasks, but the current manuscript supplies no quantitative metrics, dataset sizes, variance estimates, or protocol details, so the practical significance cannot yet be assessed.
major comments (2)
- [Abstract] Abstract: the central empirical claim that GCPO 'consistently outperforms GRPO and DAPO' is unsupported because the abstract (and visible text) contains no metrics, dataset sizes, statistical tests, ablation results, or experimental protocol; this prevents any evaluation of whether the data-to-claim link holds.
- [Abstract / §3] Method definition (abstract and §3): the token advantage is defined as proportional to the contrastive prediction difference under positive/negative prompts, yet no derivation, identity, or bound is supplied showing that this difference recovers the true marginal contribution of each token to the sample reward or is free of prompt-construction bias and global effects (attention, KV cache). This assumption is load-bearing for the credit-assignment claim.
minor comments (1)
- [Abstract] Notation for the contrastive difference operator and the exact proportionality constant should be introduced with an equation rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support in the abstract and a formal justification for the token advantage. We will revise the manuscript to address both points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that GCPO 'consistently outperforms GRPO and DAPO' is unsupported because the abstract (and visible text) contains no metrics, dataset sizes, statistical tests, ablation results, or experimental protocol; this prevents any evaluation of whether the data-to-claim link holds.
Authors: We agree that the abstract should be self-contained with quantitative support. The full manuscript reports results in Section 4 on text-to-image and CoT benchmarks, but to resolve this, we will revise the abstract to include representative metrics (e.g., relative improvements), dataset sizes, and a brief note on the evaluation protocol and variance. revision: yes
-
Referee: [Abstract / §3] Method definition (abstract and §3): the token advantage is defined as proportional to the contrastive prediction difference under positive/negative prompts, yet no derivation, identity, or bound is supplied showing that this difference recovers the true marginal contribution of each token to the sample reward or is free of prompt-construction bias and global effects (attention, KV cache). This assumption is load-bearing for the credit-assignment claim.
Authors: We acknowledge that the current version motivates the advantage via contrastive guidance but lacks a formal derivation or bound. In revision we will add a subsection in §3 deriving the form under an independence assumption on token contributions, plus explicit discussion of prompt-construction bias and global effects from attention/KV cache, supported by sensitivity analysis. revision: yes
Circularity Check
No circularity: GCPO contrastive advantage defined independently of fitted inputs or self-citations
full rationale
The abstract and provided excerpts define GCPO token advantages directly via the contrastive difference between positive/negative prompt predictions, without any equation reducing this quantity to a fitted parameter, a renamed baseline, or a self-cited uniqueness result. GRPO and DAPO are referenced only as performance baselines, not as load-bearing premises whose validity is imported via author overlap. No self-definitional loop, ansatz smuggling, or renaming of empirical patterns is exhibited. The construction is presented as an empirical proposal whose justification rests on downstream benchmarks rather than tautological identity with its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Difference in model predictions under positive versus negative prompts isolates token-level contributions to sample reward
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Understanding the impact of negative prompts: When and how do they take effect? Ineuropean conference on computer vision, pages 190–206
Yuanhao Ban, Ruochen Wang, Tianyi Zhou, Minhao Cheng, Boqing Gong, and Cho-Jui Hsieh. Understanding the impact of negative prompts: When and how do they take effect? Ineuropean conference on computer vision, pages 190–206. Springer, 2024
2024
-
[4]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.NeurIPS, 2017
2017
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[10]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025
-
[13]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[14]
Lavida-o: Elastic masked diffusion models for unified multimodal understanding and generation
Shufan Li, Jiuxiang Gu, Kangning Liu, Zhe Lin, Zijun Wei, Aditya Grover, and Jason Kuen. Lavida-o: Elastic masked diffusion models for unified multimodal understanding and generation. arXiv preprint arXiv:2509.19244, 2025
-
[15]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol and Prafulla Dhariwal. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Sean O’Brien and Mike Lewis. Contrastive decoding improves reasoning in large language models.arXiv preprint arXiv:2309.09117, 2023
-
[20]
Charles O’Neill et al. Steering language generation: Harnessing contrastive expert guidance and negative prompting.arXiv preprint arXiv:2308.07645, 2023
-
[21]
Dall·e 3.https://openai.com/index/dall-e-3/, 2023
OpenAI. Dall·e 3.https://openai.com/index/dall-e-3/, 2023
2023
-
[22]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[23]
Kaihang Pan, Yang Wu, Wendong Bu, Kai Shen, Juncheng Li, Yingting Wang, Yunfei Li, Siliang Tang, Jun Xiao, Fei Wu, et al. Janus-pro-r1: Advancing collaborative visual comprehension and generation via reinforcement learning.arXiv preprint arXiv:2506.01480, 2025
-
[24]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[25]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia et al. Photorealistic text-to-image diffusion models with deep language understanding.arXiv preprint arXiv:2205.11487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Stay on topic with classifier-free guidance.arXiv preprint arXiv:2306.17806, 2023
Guillaume Sanchez, Honglu Fan, Alexander Spangher, Elad Levi, Pawan Sasanka Ammana- manchi, and Stella Biderman. Stay on topic with classifier-free guidance.arXiv preprint arXiv:2306.17806, 2023
-
[28]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Learning to summarize with human feedback.NeurIPS, 2020
Nisan Stiennon et al. Learning to summarize with human feedback.NeurIPS, 2020
2020
-
[33]
Wei Sun, Wen Yang, Pu Jian, Qianlong Du, Fuwei Cui, Shuo Ren, and Jiajun Zhang. Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning.arXiv preprint arXiv:2505.16826, 2025
-
[34]
Joty, and Nikhil Naik
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq R. Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8228–8238, 2023
2024
-
[35]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. arXiv preprint arXiv:2504.08837, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[37]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[40]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Unlocking Exploration in RLVR: Uncertainty-aware Advantage Shaping for Deeper Reasoning
Can Xie, Ruotong Pan, Xiangyu Wu, Yunfei Zhang, Jiayi Fu, Tingting Gao, and Guorui Zhou. Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning.arXiv preprint arXiv:2510.10649, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Haotian Ye, Kaiwen Zheng, Jiashu Xu, Puheng Li, Huayu Chen, Jiaqi Han, Sheng Liu, Qinsheng Zhang, Hanzi Mao, Zekun Hao, et al. Data-regularized reinforcement learning for diffusion models at scale.arXiv preprint arXiv:2512.04332, 2025
-
[46]
En Yu, Kangheng Lin, Liang Zhao, Jisheng Yin, Yana Wei, Yuang Peng, Haoran Wei, Jian- jian Sun, Chunrui Han, Zheng Ge, et al. Perception-r1: Pioneering perception policy with reinforcement learning.arXiv preprint arXiv:2504.07954, 2025
-
[47]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186, 2025
2025
-
[49]
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?arXiv preprint arXiv:2403.14624, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025. 12 A Additional Implementation Details Text-to-Image.We employ Janus-Pro-7B as the base model and train GCPO for 1,600 ste...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
generate a wrong answer
as our base model. We followed the setup of VPPO and train the model for two epochs, which amounts to 202 steps on ViRL39K dataset. The specific hyperparameter are listed in Table 6 Table 6:Training configurations for Text-to-Image tasks. Learning Rate1×10 −6 Steps 202 β1 0.99 β2 0.999 optimizer AdamW Learning Rate Schedule Constant Model Size 8B Global B...
-
[53]
Rearrange the equation to isolate x: x + 4 + 6 = 3x implies x + 10 = 3x implies 10 = 2x implies x = 5
For the sides, the equation derived from the equality of opposite sides will be: x + 4 = 3x - 6 Solving for x: x + 4 = 3x - 6. Rearrange the equation to isolate x: x + 4 + 6 = 3x implies x + 10 = 3x implies 10 = 2x implies x = 5
-
[54]
Specifically, the angles at the point of intersection where the diagonals split the parallelogram will help in finding y
For the angles, the sum of the interior angles on the same side of a transversal is supplementary (180 degrees). Specifically, the angles at the point of intersection where the diagonals split the parallelogram will help in finding y. However, the value of y can be found directly from the side lengths equality. So, the value of x that makes the quadrilatera...
-
[55]
The triangle is in the top-left corner
The first image has a triangle in the top-left, a square in the top-right, and a circle in the bottom-left. The triangle is in the top-left corner
-
[56]
The second image shows a square in the top-right, a circle in the bottom-left, and the triangle is missing from the top-left position
-
[57]
The circle is in the top-left corner
The third image has a circle in the top-left, a triangle in the top-right, and a square in the bottom-left. The circle is in the top-left corner
-
[58]
Now, observing the position changes: - In the first image, the triangle is in the top-left
The fourth image shows a square in the top-right, a circle in the bottom-left, and the triangle is missing from the top-left position. Now, observing the position changes: - In the first image, the triangle is in the top-left. - In the second image, it moves to the top-right, and the circle goes to the bottom-left. - In the third image, the circle is in th...
-
[59]
replaces all squares with stars,
The first operation is "replaces all squares with stars," meaning any square symbol (\(\text{⬛ }\)) is replaced by a star (\(\star\)). So, \(\text{⬛ }\) becomes \(\star\). The set now is: \(\text{O} \, \star \, \star\)
-
[60]
changes the shading on the symbols
The second operation is "changes the shading on the symbols." This operation will change the shading of each symbol. In the initial set, the symbols are: - O (circle) - \(\star\) (star) - \(\text{⬛ }\) (black square, which becomes \(\star\)) After replacing the square with a star, the set is \(\text{O} \, \star \, \star\). Now applying the shading change ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.