SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Pith reviewed 2026-05-19 17:37 UTC · model grok-4.3
The pith
A curriculum of progressively withdrawing skill context during reinforcement learning lets agents internalize procedural knowledge into their parameters for zero-shot task completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
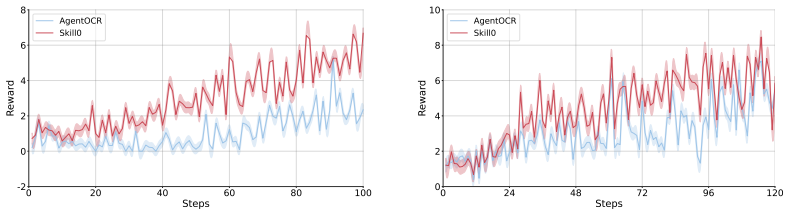
SKILL0 introduces an in-context reinforcement learning setup where skills are grouped by category and combined with interaction history into compact visual context. A Dynamic Curriculum then assesses each skill file's helpfulness to the current policy and retains only useful ones within a budget that decreases linearly, continuing until the agent functions without any skill context.
What carries the argument
The Dynamic Curriculum mechanism, which identifies on-policy helpfulness of skill files and manages their progressive withdrawal from the training context.
If this is right
- The internalized agent maintains performance gains of roughly 7 to 10 percent across environment benchmarks compared to standard reinforcement learning without internalization.
- Inference-time context usage stays below 0.5k tokens per step even as skills are no longer provided.
- The agent learns tool invocation and multi-turn completion through the curriculum without relying on runtime retrieval.
- Full zero-shot operation becomes possible after the curriculum completes.
Where Pith is reading between the lines
- Internalized skills could compound over multiple training phases to handle increasingly complex tasks.
- The method might apply to internalizing other types of knowledge, such as facts or strategies, in agent systems.
- Checking performance on entirely new tasks after internalization would test if the skills have become general capabilities rather than task-specific memorization.
- This could lower the need for large context windows in deployed agents.
Load-bearing premise
That the progressive withdrawal of context during training causes the model to truly encode the skills in its weights instead of learning to perform without them only because of the specific training distribution.
What would settle it
Running the trained agent on the benchmark tasks with all skill files completely removed from any context and observing whether success rates remain above the standard RL baseline or drop back to it.
Figures








read the original abstract
Agent skills, structured packages of procedural knowledge and executable resources that agents dynamically load at inference time, have become a reliable mechanism for augmenting LLM agents. Yet inference-time skill augmentation is fundamentally limited: retrieval noise introduces irrelevant guidance, injected skill content imposes substantial token overhead, and the model never truly acquires the knowledge it merely follows. We ask whether skills can instead be internalized into model parameters, enabling zero-shot autonomous behavior without any runtime skill retrieval. We introduce SKILL0, an in-context reinforcement learning framework designed for skill internalization. SKILL0 introduces a training-time curriculum that begins with full skill context and progressively withdraws it. Skills are grouped offline by category and rendered with interaction history into a compact visual context, teaching he model tool invocation and multi-turn task completion. A Dynamic Curriculum then evaluates each skill file's on-policy helpfulness, retaining only those from which the current policy still benefits within a linearly decaying budget, until the agent operates in a fully zero-shot setting. Extensive agentic experiments demonstrate that SKILL0 achieves substantial improvements over the standard RL baseline (+9.7\% for ALFWorld, +6.6\% for Search-QA, and+10.1\% for WebShop), while maintaining a highly efficient context of fewer than 0.5k tokens per step. Our code is available at https://github.com/ZJU-REAL/SkillZero.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SKILL0, an in-context agentic RL framework for internalizing skills into LLM parameters. It starts with full skill context, groups skills by category, renders them with interaction history, and uses a Dynamic Curriculum to evaluate on-policy helpfulness and progressively withdraw context within a linearly decaying budget until zero-shot operation. Experiments claim gains over a standard RL baseline of +9.7% on ALFWorld, +6.6% on Search-QA, and +10.1% on WebShop, with context under 0.5k tokens per step. Code is released.
Significance. If the internalization mechanism is shown to produce genuine parameter-level skill acquisition rather than distribution adaptation, the work could reduce retrieval overhead and token costs in LLM agents while improving autonomy. The open-source code is a clear strength for reproducibility and follow-up verification.
major comments (2)
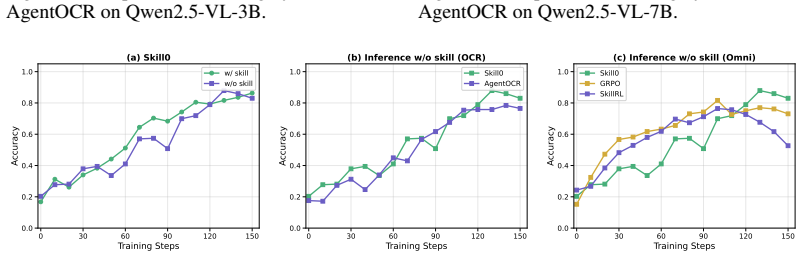
- [Experiments / Dynamic Curriculum description] The central internalization claim rests on the Dynamic Curriculum's on-policy helpfulness metric driving progressive withdrawal. No ablation is reported that compares this dynamic selection against a fixed schedule or random withdrawal (e.g., in the experimental results or §4). Without such a control, it remains unclear whether reported gains reflect parameter encoding of skills or merely curriculum-induced shifts in the training distribution.
- [Abstract and results tables] The abstract and results report concrete percentage improvements but provide no variance estimates, statistical significance tests, number of runs, or detailed baseline configurations. This information is required to evaluate whether the gains support the claim of reliable skill internalization over the RL baseline.
minor comments (2)
- [Abstract] Abstract contains a typo: 'teaching he model' should read 'teaching the model'.
- [Abstract] Abstract formatting: missing space in '+10.1% for WebShop' after the preceding comma.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below, committing to revisions that strengthen the evidence for the Dynamic Curriculum's role and improve the statistical reporting of results.
read point-by-point responses
-
Referee: [Experiments / Dynamic Curriculum description] The central internalization claim rests on the Dynamic Curriculum's on-policy helpfulness metric driving progressive withdrawal. No ablation is reported that compares this dynamic selection against a fixed schedule or random withdrawal (e.g., in the experimental results or §4). Without such a control, it remains unclear whether reported gains reflect parameter encoding of skills or merely curriculum-induced shifts in the training distribution.
Authors: We agree that an ablation isolating the on-policy helpfulness metric from simpler withdrawal strategies would strengthen the internalization claim. The current results show SKILL0 outperforming the RL baseline, but without the requested controls it is difficult to fully attribute gains to parameter encoding versus training distribution effects. In the revised manuscript we will add this ablation to §4, comparing dynamic selection against both a fixed linear schedule and random withdrawal under the same token budget, and report the resulting zero-shot performance differences on ALFWorld, Search-QA, and WebShop. revision: yes
-
Referee: [Abstract and results tables] The abstract and results report concrete percentage improvements but provide no variance estimates, statistical significance tests, number of runs, or detailed baseline configurations. This information is required to evaluate whether the gains support the claim of reliable skill internalization over the RL baseline.
Authors: We accept that variance, run counts, and statistical tests are necessary to substantiate the reliability of the reported gains. The manuscript currently omits these details. In the revision we will update the abstract and all results tables to report means and standard deviations across five independent random seeds, include paired t-test p-values against the RL baseline, and expand the experimental setup section with precise baseline hyper-parameters and training configurations. revision: yes
Circularity Check
No significant circularity; empirical results are externally measured
full rationale
The paper describes SKILL0 as an in-context RL framework whose core mechanism is a Dynamic Curriculum that starts with full skill context and progressively withdraws it based on on-policy helpfulness until zero-shot operation. Reported gains (+9.7% ALFWorld, +6.6% Search-QA, +10.1% WebShop) are presented as measured experimental outcomes against a standard RL baseline, not as quantities defined by construction from fitted parameters or self-referential equations. No load-bearing derivation step reduces to self-definition, fitted-input renaming, or a self-citation chain; the curriculum is a procedural training schedule whose final performance is evaluated externally. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear decay budget schedule
axioms (2)
- domain assumption Skills grouped offline by category can be rendered into compact visual context that supports learning
- domain assumption On-policy helpfulness evaluation reliably identifies skills worth retaining
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Curriculum evaluates each skill file’s on-policy helpfulness by comparing agent performance with and without it... until the agent operates in a fully zero-shot setting.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linear decay of the skill budget M(s) ... M(s) = ceil(N * (NS - s) / (NS - 1))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 15 Pith papers
-
From Context to Skills: Can Language Models Learn from Context Skillfully?
Ctx2Skill lets language models autonomously evolve context-specific skills via multi-agent self-play, improving performance on context learning tasks without human supervision.
-
Terminal-World: Scaling Terminal-Agent Environments via Agent Skills
Terminal-World is a skill-based synthesis pipeline that generates 5,723 training environments and produces Terminal-World-32B which outperforms baselines on Terminal-Bench 2.0 using only 1.2% of the data.
-
Test-Time Learning with an Evolving Library
EvoLib enables LLMs to accumulate, reuse, and evolve knowledge abstractions from inference trajectories at test time, yielding substantial gains on math reasoning, code generation, and agentic benchmarks without param...
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes active external skills in agentic RL via leave-one-skill-out marginal contribution estimates and three lifecycle operations, outperforming baselines by 7.1% on ALFWorld and SearchQA while sh...
-
Evidence Over Plans: Online Trajectory Verification for Skill Distillation
PDI-guided distillation from environment-verified trajectories yields skills that surpass no-skill baselines and human-written skills across 86 tasks with far lower inference cost.
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 trains one policy to jointly evolve skill query generation, re-ranking, task solving, and distillation from a single task-success signal, with low-frequency trends crediting selection and high-frequency variati...
-
Hypothesis generation and updating in large language models
LLMs exhibit Bayesian-like hypothesis updating with strong-sampling bias and an evaluation-generation gap but generalize poorly outside observed data.
-
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
SkillsVote is a governance system for agent skills that profiles corpora, recommends via search, and gates updates on successful reusable outcomes, yielding benchmark gains without model changes.
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes the active external skill set in agentic RL via leave-one-skill-out marginal contribution estimates and lifecycle operations, delivering a 7.1% average gain over baselines on ALFWorld and Se...
-
Ace-Skill: Bootstrapping Multimodal Agents with Prioritized and Clustered Evolution
Ace-Skill boosts multimodal agent self-evolution via prioritized rollouts with lazy-decay tracking and semantic knowledge clustering, yielding up to 35% relative gains on tool-use benchmarks and zero-shot transfer to ...
-
Learning CLI Agents with Structured Action Credit under Selective Observation
CLI agents trained with RL benefit from selective observation via σ-Reveal and structured credit assignment via A³ that leverages AST action sub-chains and trajectory margins.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A survey that taxonomizes agent skills for LLM-based agents across representation, acquisition, retrieval, and evolution stages while reviewing methods, resources, and open challenges.
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 trains a single RL policy to co-evolve skill selection, utilization, and distillation in language model agents from one task-outcome reward, using low-frequency trends to credit selection and high-frequency var...
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 co-evolves skill selection, utilization, and distillation inside a single policy using only task-outcome reward, with low-frequency trends crediting selection and high-frequency variation crediting distillation...
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
If any required knowledge is missing or uncertain, youMUSTcall a search engine to get more external information using format:<search> your query </search>
-
[2]
Additionally, select an image compression factor larger than 1.0 for the next image
Only if you have sufficient information to answer the question with high confidence, provide your final answer within<answer> </answer>tags. Additionally, select an image compression factor larger than 1.0 for the next image. Higher compression lowers cost, but too much compression harms image quality. You must provide the next compression factor within <...
-
[3]
Reasoning: state what you found in the image. 2.<search>...</search>or<answer>...</answer> 3.<compression>...</compression> Figure 12: Prompt template used by SKILL0 for the Search-based QA task environment. 19 Table 7:Representative Skills inSkillBank. Skill Title Principle (Actionable Pattern) When to Apply skills/ALFWorld/general.md Systematic Explorat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.