Move the Query, Not the Cache: Characterizing Cross-Instance Latent Attention Redistribution Across GPU Fabrics
Pith reviewed 2026-06-28 16:00 UTC · model grok-4.3
The pith
For cross-instance MLA attention, routing the small compressed query to the cache beats moving the cache to the query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
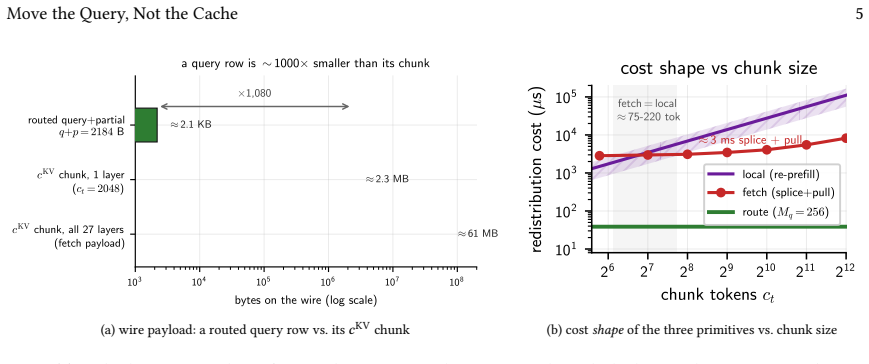
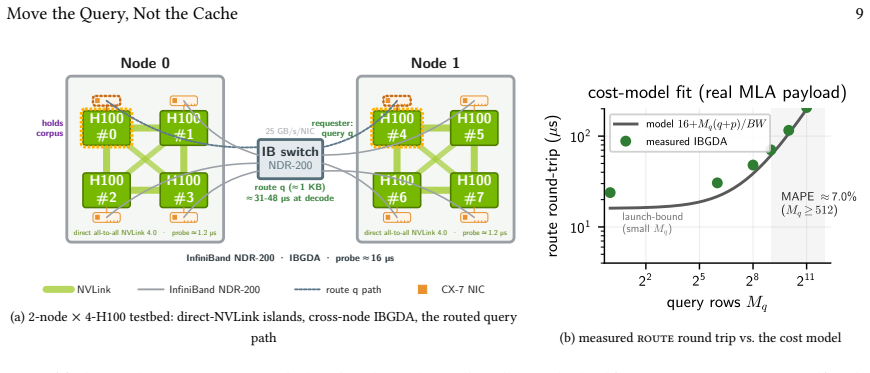
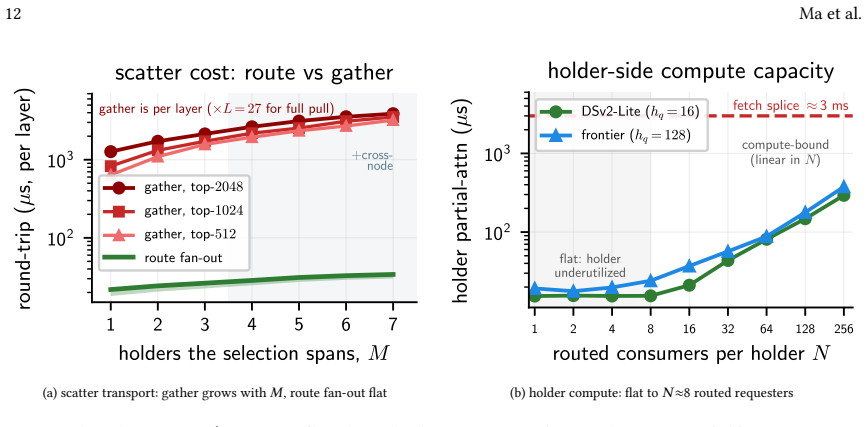
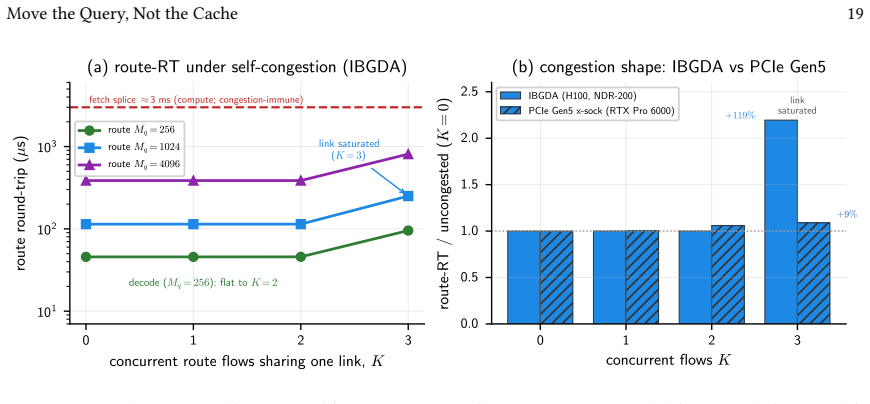
When a query and the KV-cache blocks it selects reside on different GPUs, Multi-head Latent Attention inverts the usual arithmetic because each token's key and value are compressed into one narrow vector, so the routed query row is smaller than the chunk it attends. Characterizing this on a multi-node H100 cluster with IBGDA produces a reusable topology-aware cost model and a closed-form route/fetch/local predicate whose constants are measured on the fabric; the model tracks batched round-trips to within 7 percent. At decode the system therefore routes the query, trading the cost of moving the cache (a 3 ms re-adaptation splice for a contiguous chunk or a scattered gather) for a tens-of-micr
What carries the argument
The topology-aware cost model (probe / transfer / compute / return / merge phases) together with the closed-form route/fetch/local predicate that decides whether to route the query, fetch the cache, or stay local.
If this is right
- At decode, routing the query replaces the 3 ms cache re-adaptation splice with a tens-of-microsecond round trip.
- The predicate selects the interconnect by measured probe latency rather than advertised peak bandwidth.
- The model and predicate extend directly to other compressed or sparsely indexed attention systems such as DeepSeek-V3.2.
- Extending the framework to a new architecture requires measuring only two coefficients: the size of the routed payload and the move-the-cache cost of fetch.
Where Pith is reading between the lines
- Distributed inference schedulers could embed the route/fetch/local predicate to decide data movement per attention step instead of fixing a single policy.
- Workloads that repeatedly query the same large shared corpus across many sub-agents would see the largest reduction in cross-instance traffic.
- The same probe-based decision logic could later guide initial KV-cache placement across instances to minimize expected future routing cost.
Load-bearing premise
MLA compression keeps the routed query row at roughly 1 KB and therefore smaller than the attended cache chunk on the measured fabrics.
What would settle it
A measurement on the same H100 cluster showing that query routing latency exceeds the 3 ms cost of cache movement and re-adaptation for the batch sizes tested would falsify the claimed advantage.
Figures


read the original abstract
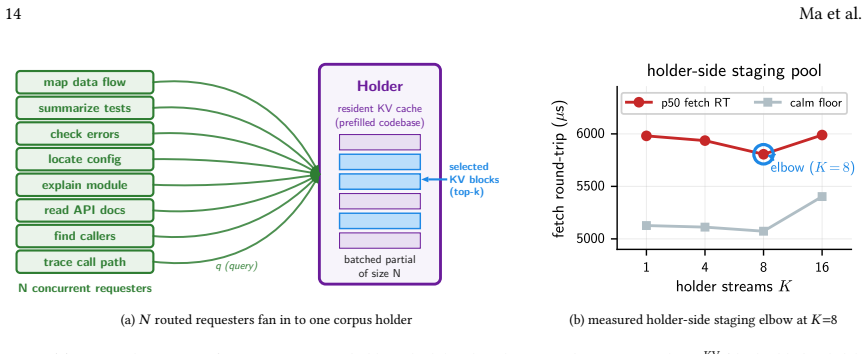
Frontier LLMs increasingly decide what a query attends to with a sparse-attention indexer that picks a few KV-cache blocks per query: attention's unit is now a small, reusable chunk. Agentic workloads hammer it: many sub-agents query one large codebase, reusing the same blocks. When that corpus outgrows one GPU it is partitioned across instances, so a query and the blocks it selects often sit on different GPUs: answering it means attention across instances. The reflex of prior cross-instance KV systems is to move the cache: pull the selected blocks to the requester. Multi-head Latent Attention inverts the arithmetic, compressing each token's key and value into one narrow vector, so a routed query row is only ~1 KB, smaller than the chunk it attends; routing the query is then often cheaper than moving the cache. Which primitive wins, over which fabric and request shape, is uncharted, least of all on device-initiated RDMA that makes per-request cross-node transfers cheap. We characterize cross-instance MLA attention on a real multi-node H100 cluster, distilling two reusable artifacts: a topology-aware cost model (probe / transfer / compute / return / merge) and a closed-form route/fetch/local predicate, whose constants we measure on real IBGDA, where the model tracks batched round-trips to within ~7%. At decode it routes the query, trading the cost of moving the cache (a ~3 ms re-adaptation splice for a contiguous chunk, or a scattered gather under selection) for a tens-of-microsecond round trip, and picks the fabric by probe latency, not peak bandwidth. We instantiate the cost model and predicate for MLA, but neither is MLA-specific: they apply wherever compression or sparse selection shrinks attention to small chunks (DeepSeek-V3.2, V4, and GLM-5.1 today). Extending them to a new architecture requires measuring just two coefficients: the routed payload and fetch's move-the-cache cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript characterizes cross-instance MLA attention on a multi-node H100 cluster with device-initiated RDMA (IBGDA). It claims that MLA compression reduces each query row to ~1 KB—smaller than the attended KV chunk—so routing the query is cheaper than moving the cache (~3 ms re-adaptation splice or scattered gather). The authors distill a reusable topology-aware cost model (probe/transfer/compute/return/merge) and a closed-form route/fetch/local predicate; constants are measured on real hardware and the model tracks batched round-trips to within ~7%. The predicate is instantiated for MLA but presented as general for any compressed or sparse attention that shrinks the attended unit.
Significance. If the measurements and size inequality hold, the work supplies a practical, low-overhead primitive for distributed sparse attention in agentic workloads and a reusable cost model that requires only two hardware-specific coefficients for new architectures. The explicit measurement of constants on production fabrics and the non-MLA-specific formulation are concrete strengths that would make the artifacts immediately usable by systems builders.
major comments (2)
- [Abstract] Abstract: The central claim that query routing is preferred rests on the routed payload being ~1 KB and materially smaller than the attended chunk. No table, derivation, or measured payload size is referenced to anchor this figure or to confirm the inequality on the tested H100/IBGDA configuration; without it the arithmetic inversion and the reported preference for query movement cannot be verified.
- [Results] Results / evaluation section: The statement that the cost model tracks batched round-trips to within ~7% is load-bearing for the contribution, yet the provided text contains no data tables, per-batch error breakdowns, or full methods description that would allow independent assessment of that accuracy claim.
minor comments (1)
- [Discussion] The predicate and cost model are described as reusable beyond MLA, but the manuscript does not include even a brief worked example for another architecture (e.g., DeepSeek-V3.2) to illustrate the two-coefficient measurement process.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify opportunities to strengthen verifiability of the central claims; we address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that query routing is preferred rests on the routed payload being ~1 KB and materially smaller than the attended chunk. No table, derivation, or measured payload size is referenced to anchor this figure or to confirm the inequality on the tested H100/IBGDA configuration; without it the arithmetic inversion and the reported preference for query movement cannot be verified.
Authors: We agree that the abstract would be strengthened by an explicit anchor for the ~1 KB figure. The manuscript derives this size from the MLA compression (one narrow latent vector per token) and confirms the inequality via direct measurement on the target hardware, but the abstract does not cite the relevant section or table. In the revised manuscript we will add a parenthetical reference in the abstract to the section presenting the payload-size measurement and the chunk-size comparison on the H100/IBGDA fabric. revision: yes
-
Referee: [Results] Results / evaluation section: The statement that the cost model tracks batched round-trips to within ~7% is load-bearing for the contribution, yet the provided text contains no data tables, per-batch error breakdowns, or full methods description that would allow independent assessment of that accuracy claim.
Authors: We acknowledge that the current text does not supply the supporting tables or breakdowns needed to assess the ~7% accuracy claim. We will expand the results section to include (1) a table of measured versus predicted batched round-trip latencies, (2) the per-batch relative-error distribution, and (3) an expanded methods subsection describing how the two hardware-specific coefficients were obtained on the IBGDA fabric. These additions will make the accuracy statement independently verifiable. revision: yes
Circularity Check
No circularity: cost model relies on directly measured hardware constants independent of target predictions
full rationale
The paper's closed-form predicate and cost model are constructed from two coefficients (routed payload size and fetch move-the-cache cost) that are measured directly on the target IBGDA/H100 hardware. These inputs are not fitted to the final latency numbers or derived from the predicate's output; the model is then validated against observed round-trips (to ~7%). The ~1 KB query-row claim is stated as a direct consequence of MLA compression rather than derived or fitted inside the paper. No equation or step reduces the reported preference for query routing to a quantity defined by that preference itself. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- routed payload size
- fetch move-the-cache cost
axioms (1)
- domain assumption The five-component breakdown (probe / transfer / compute / return / merge) captures all relevant latency sources on the measured fabrics.
Reference graph
Works this paper leans on
- [1]
-
[2]
Nidhi Bhatia, Ankit More, Ritika Borkar, Tiyasa Mitra, Ramon Matas, Ritchie Zhao, Maximilian Golub, Dheevatsa Mudigere, Brian Phar- ris, and Bita Darvish Rouhani. 2025. Helix Parallelism: Rethinking Sharding Strategies for Interactive Multi-Million-Token LLM Decoding. arXiv:2507.07120 [cs.DC] https://arxiv.org/abs/2507.07120
- [3]
-
[4]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[5]
DeepSeek-AI. 2026. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. https://huggingface.co/deepseek-ai/DeepSeek-V4- Pro/blob/main/DeepSeek_V4.pdf Technical report
2026
-
[6]
DeepSeek-AI et al . 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434 [cs.CL] https://arxiv.org/abs/2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
DeepSeek-AI et al. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556 [cs.CL] https://arxiv.org/abs/2512. 02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low-Latency Serverless Inference for Large Language Models. InOSDI’24
2024
- [9]
-
[10]
GLM-5-Team et al. 2026. GLM-5: from Vibe Coding to Agentic Engineering. arXiv:2602.15763 [cs.LG] https://arxiv.org/abs/2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Amos Goldman, Nimrod Boker, Maayan Sheraizin, Nimrod Admoni, Artem Polyakov, Subhadeep Bhattacharya, Fan Yu, Kai Sun, Georgios Theodorakis, Hsin-Chun Yin, Peter-Jan Gootzen, Aamir Shafi, Assaf Ravid, Salvatore Di Girolamo, James Dinan, Xiaofan Li, Manjunath Gorentla Venkata, and Gil Bloch. 2026. NCCL EP: Towards a Unified Expert Parallel Communication API...
- [12]
-
[13]
Yiyuan He, Minxian Xu, Jingfeng Wu, Jianmin Hu, Chong Ma, Min Shen, Le Chen, Chengzhong Xu, Lin Qu, and Kejiang Ye. 2026. BanaServe: Unified KV Cache and Dynamic Module Migration for Balancing Disaggregated LLM Serving in AI Infrastructure.Software: Practice and Experience 56, 4 (2026), 424–444. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/spe.70...
-
[14]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. 2025. EPIC: efficient position-independent caching for serving large language models. InProceedings of the 42nd International Conference on Machine Learning(Vancouver, Canada)(ICML’25). JMLR.org, Article 956, 12 pages
2025
-
[15]
Yinsicheng Jiang, Yao Fu, Yeqi Huang, Ping Nie, Zhan Lu, Leyang Xue, Congjie He, Man-Kit Sit, Jilong Xue, Li Dong, Ziming Miao, DaYou Du, Tairan Xu, Kai Zou, Edoardo Ponti, and Luo Mai. 2026. MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture- of-Experts Systems. InThe Thirty-ninth Annual Conference on Neural Information Processing Sys...
2026
-
[16]
Yinsicheng Jiang, Yeqi Huang, Liang Cheng, Cheng Deng, Xuan Sun, and Luo Mai. 2026. ContextPilot: Fast Long-Context Inference via Context Reuse. InProceedings of the 9th Conference on Machine Learning and Systems (MLSys 2026). https://arxiv.org/abs/2511.03475
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Shengyu Liu Jiashi Li. 2025. FlashMLA: Efficient Multi-head Latent Attention Kernels. https://github.com/deepseek-ai/FlashMLA. Manuscript submitted to ACM 22 Ma et al
2025
-
[18]
Kimi Team et al. 2026. Kimi K2: Open Agentic Intelligence. arXiv:2507.20534 [cs.LG] https://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (Koblenz, Germany)(SOSP ’23). Association for Computing Machinery, New York, ...
- [20]
- [21]
-
[22]
Nandor Licker, Kevin Hu, Vladimir Zaytsev, and Lequn Chen. 2026. fabric-lib: RDMA Point-to-Point Communication for LLM Systems. arXiv:2510.27656 [cs.DC] https://arxiv.org/abs/2510.27656
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, and Wei Lin. 2024. Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache. arXiv:2401.02669 [cs.DC] https://arxiv.org/abs/2401.02669
- [24]
-
[25]
Maxim Milakov and Natalia Gimelshein. 2018. Online normalizer calculation for softmax.CoRRabs/1805.02867 (2018). arXiv:1805.02867 http://arxiv.org/abs/1805.02867
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Moonshot AI. 2026. Kimi K2.6. Hugging Face model card. https://huggingface.co/moonshotai/Kimi-K2.6
2026
-
[27]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving.ACM Trans. Storage(Nov. 2025). doi:10.1145/3773772 Just Accepted
-
[28]
Nazmul Takbir, Hamidreza Alikhani, Nikil Dutt, and Sangeetha Abdu Jyothi. 2025. FlexiCache: Leveraging Temporal Stability of Attention Heads for Efficient KV Cache Management. arXiv:2511.00868 [cs.LG] https://arxiv.org/abs/2511.00868
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Xiaojuan Tang, Fanxu Meng, Pingzhi Tang, Yuxuan Wang, Di Yin, Xing Sun, and Muhan Zhang. 2026. TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill & Decode Inference. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA)(ASPLOS ’26). Association...
-
[30]
Qian Wang, Zahra Yousefijamarani, Morgan Lindsay Heisler, Rongzhi Gu, Bai Xiaolong, Shan Yizhou, Wei Zhang, Wang Lan, Ying Xiong, Yong Zhang, and Zhenan Fan. 2025. MEPIC: Memory Efficient Position Independent Caching for LLM Serving. arXiv:2512.16822 [cs.LG] https://arxiv.org/abs/2512.16822
-
[31]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM52, 4 (April 2009), 65–76. doi:10.1145/1498765.1498785
- [32]
-
[33]
Feiyu Yao, Zhixiong Niu, Xiaqing Li, Yongqiang Xiong, Juan Fang, and Qian Wang. 2026. An Efficient Hybrid Sparse Attention with CPU-GPU Parallelism for Long-Context Inference. arXiv:2605.07719 [cs.LG] https://arxiv.org/abs/2605.07719
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. InProceedings of the Twentieth European Conference on Computer Systems. 94–109. doi:10.1145/3689031.3696098
-
[35]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving.arXiv preprint arXiv:2501.01005(2025). https://arxiv.org/abs/2501.01005
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. 2025. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. InProceedings of the 63rd Annual Meeting of the Association for Computa...
-
[37]
Sungmin Yun, Seonyong Park, Hwayong Nam, Younjoo Lee, Gunjun Lee, Kwanhee Kyung, Sangpyo Kim, Nam Sung Kim, Jongmin Kim, Hyungyo Kim, Juhwan Cho, Seungmin Baek, and Jung Ho Ahn. 2026. Rethinking LLM Inference Bottlenecks: Insights from Latent Attention and Mixture-of-Experts. arXiv:2507.15465 [cs.AR] https://arxiv.org/abs/2507.15465
-
[38]
Z.ai. 2026. GLM-5.1. Hugging Face model card. https://huggingface.co/zai-org/GLM-5.1
2026
-
[39]
Shiqing Zhang, Mahmood Naderan-Tahan, Magnus Jahre, and Lieven Eeckhout. 2023. Characterizing Multi-Chip GPU Data Sharing.ACM Trans. Archit. Code Optim.20, 4, Article 56 (Dec. 2023), 24 pages. doi:10.1145/3629521
-
[40]
Shiqing Zhang, Mahmood Naderan-Tahan, Magnus Jahre, and Lieven Eeckhout. 2023. SAC: Sharing-Aware Caching in Multi-Chip GPUs. In Proceedings of the 50th Annual International Symposium on Computer Architecture(Orlando, FL, USA)(ISCA ’23). Association for Computing Machinery, New York, NY, USA, Article 43, 13 pages. doi:10.1145/3579371.3589078 Manuscript su...
-
[41]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library. https://github.com/deepseek-ai/DeepEP
2025
-
[42]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: efficient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, C...
2024
-
[43]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serving. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Article...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.