Kernel Foundry: A Diagnosis-driven Evolutionary Kernel Optimizer with Multi-Experts
Pith reviewed 2026-06-30 23:32 UTC · model grok-4.3
The pith
Kernel Foundry combines diagnostic feedback with evolutionary search and an experience library to make LLM-generated GPU kernels both correct and efficient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
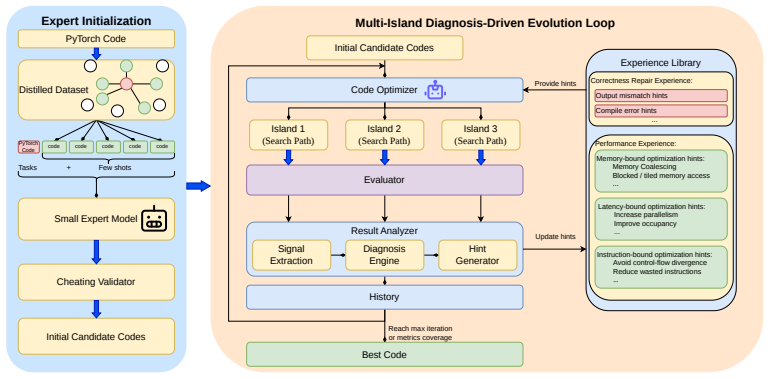
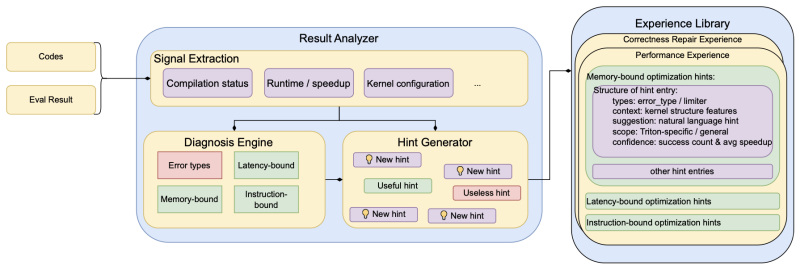
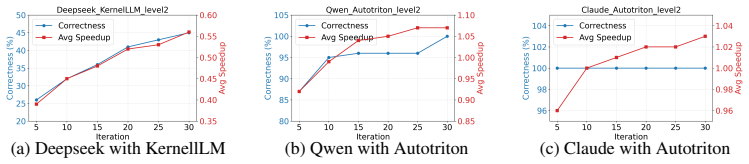
Kernel Foundry is a diagnosis-driven evolutionary framework that performs expert-guided, retrieval-augmented initialization followed by multi-island evolutionary search. Candidate kernels are iteratively refined by structured diagnostic feedback on correctness and efficiency errors. A centralized experience library accumulates reusable optimization knowledge across runs, and explicit mechanisms block behaviors that bypass kernel-level computation. On KernelBench this produces consistent gains in both correctness and runtime performance over strong baselines, reaching up to 100 percent correctness on Level 2.
What carries the argument
Multi-island evolutionary search driven by structured diagnostic feedback and guided by an accumulating centralized experience library.
If this is right
- The method produces higher correctness and runtime performance than prior LLM-based kernel generators on the same benchmark.
- The experience library stores reusable optimization knowledge that can be retrieved in later searches.
- Explicit anti-cheating mechanisms prevent candidates from bypassing actual kernel execution.
- Correctness reaches 100 percent on Level 2 of KernelBench while still improving measured performance.
Where Pith is reading between the lines
- The same feedback-plus-library loop could be applied to other domains where LLMs generate code that must run efficiently on specific hardware.
- Over many tasks the library might reduce the total number of LLM calls needed by reusing past successful patterns.
- The multi-island structure could be extended to search across different GPU architectures without changing the core feedback mechanism.
Load-bearing premise
Structured diagnostic feedback together with evolutionary search and an accumulating experience library can overcome LLM limitations to produce kernels that are both correct and hardware-efficient without post-hoc tuning or evaluation bias.
What would settle it
Running the full pipeline on a fresh suite of Level-2 KernelBench problems and finding that correctness stays below the strongest baseline or that removing the diagnostic feedback produces no measurable drop in final performance.
Figures
read the original abstract
Generating high-performance GPU kernels remains challenging due to the need for both correctness and hardware-aware optimization. While large language models (LLMs) show promise in code generation, they often fail to produce kernels that are both correct and efficient. We propose Kernel Foundry, a diagnosis-driven evolutionary framework for automatic GPU kernel optimization. Our method combines expert-guided, retrieval-augmented initialization with a multi-island evolutionary search, where candidate kernels are iteratively refined using structured diagnostic feedback. A centralized experience library accumulates reusable optimization knowledge to guide subsequent evolution, while explicit mechanisms prevent cheating behaviors that bypass kernel-level computation. Experiments on KernelBench show that our method consistently improves both correctness and performance over strong baselines, achieving up to 100% correctness on Level~2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Kernel Foundry, a diagnosis-driven evolutionary framework for automatic GPU kernel optimization. It integrates expert-guided retrieval-augmented initialization, multi-island evolutionary search refined iteratively by structured diagnostic feedback, a centralized accumulating experience library for reusable knowledge, and explicit anti-cheating mechanisms. The central claim is that experiments on KernelBench demonstrate consistent improvements in both correctness and performance over strong baselines, reaching up to 100% correctness on Level 2.
Significance. If the empirical claims are substantiated with full experimental details, the work could contribute to automated high-performance computing by showing how structured diagnostic feedback and evolutionary search can mitigate LLM limitations in kernel generation. The combination of multi-expert initialization, experience accumulation, and anti-cheating safeguards addresses practical issues in LLM-based code synthesis.
major comments (1)
- [Abstract] Abstract: The manuscript asserts that 'Experiments on KernelBench show that our method consistently improves both correctness and performance over strong baselines, achieving up to 100% correctness on Level 2,' yet supplies no quantitative results, tables, baseline descriptions, error bars, statistical analysis, or methodological protocol. This absence makes it impossible to evaluate whether the results support the central claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We agree that the current abstract would benefit from explicit quantitative support and will revise it in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'Experiments on KernelBench show that our method consistently improves both correctness and performance over strong baselines, achieving up to 100% correctness on Level 2,' yet supplies no quantitative results, tables, baseline descriptions, error bars, statistical analysis, or methodological protocol. This absence makes it impossible to evaluate whether the results support the central claim.
Authors: We agree that the abstract as written does not embed the specific numerical results or protocol details. The Experiments section (with tables comparing against baselines, correctness rates reaching 100% on Level 2, performance deltas, and the evaluation protocol) already contains these elements. In the revision we will expand the abstract to include the key quantitative outcomes (e.g., correctness percentages and relative speedups) while preserving length constraints, and we will add a brief pointer to the experimental setup. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical method combining evolutionary search, diagnostic feedback, and an accumulating experience library for GPU kernel generation. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or high-level description. Central claims rest on experimental results on the external KernelBench benchmark, which are falsifiable and independent of the method's internal construction. The provided text contains no self-definitional steps or reductions to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
{TensorFlow}: a system for {Large-Scale} machine learning
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. {TensorFlow}: a system for {Large-Scale} machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16), pages 265–283, 2016
2016
-
[2]
Introducing claude sonnet 4.5
Anthropic. Introducing claude sonnet 4.5. https://www.anthropic.com/news/ claude-sonnet-4-5, 2024. Accessed: 2025-12-12
2024
-
[3]
Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948, 2025
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948, 2025
-
[4]
{TVM}: An automated {End-to-End} optimizing compiler for deep learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 578–594, 2018
2018
-
[5]
Fisches, Sahan Paliskara, Simon Guo, Alex Zhang, Joe Spisak, Chris Cummins, Hugh Leather, Gabriel Synnaeve, Joe Isaacson, Aram Markosyan, and Mark Saroufim
Zacharias V . Fisches, Sahan Paliskara, Simon Guo, Alex Zhang, Joe Spisak, Chris Cummins, Hugh Leather, Gabriel Synnaeve, Joe Isaacson, Aram Markosyan, and Mark Saroufim. Ker- nelllm: Making kernel development more accessible, 6 2025. Corresponding authors: Aram Markosyan, Mark Saroufim
2025
-
[6]
Dynamic warp formation and scheduling for efficient gpu control flow
Wilson WL Fung, Ivan Sham, George Yuan, and Tor M Aamodt. Dynamic warp formation and scheduling for efficient gpu control flow. In40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), pages 407–420. IEEE, 2007
2007
-
[7]
Qwen3.5: Large language model
Alibaba Group. Qwen3.5: Large language model. https://qwenlm.github.io/, 2025. Accessed: 2026
2025
-
[8]
The ai cuda engineer: Agentic cuda kernel discovery, optimization and composition
Robert Tjarko Lange, Aaditya Prasad, Qi Sun, Maxence Faldor, Yujin Tang, and David Ha. The ai cuda engineer: Agentic cuda kernel discovery, optimization and composition. Technical report, Technical report, Sakana AI, 02 2025, 2025
2025
-
[9]
Shangzhan Li, Zefan Wang, Ye He, Yuxuan Li, Qi Shi, Jianling Li, Yonggang Hu, Wanxiang Che, Xu Han, Zhiyuan Liu, et al. Autotriton: Automatic triton programming with reinforcement learning in llms.arXiv preprint arXiv:2507.05687, 2025
-
[10]
Xiaoya Li, Xiaofei Sun, Albert Wang, Jiwei Li, and Chris Shum. Cuda-l1: Improving cuda optimization via contrastive reinforcement learning.arXiv preprint arXiv:2507.14111, 2025
-
[11]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
NVIDIA, 2025
NVIDIA Corporation.CUDA C Programming Guide. NVIDIA, 2025. https://docs. nvidia.com/cuda/cuda-c-programming-guide/. 10
2025
-
[15]
Gpt-5.4.https://platform.openai.com/, 2026
OpenAI. Gpt-5.4.https://platform.openai.com/, 2026
2026
-
[16]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Kernelbook, 5 2025
Sahan Paliskara and Mark Saroufim. Kernelbook, 5 2025
2025
-
[18]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[19]
Graphcode: Learning from multiparameter persistent homology using graph neural networks.Advances in Neural Information Processing Systems, 37:41103–41131, 2024
Florian Russold and Michael Kerber. Graphcode: Learning from multiparameter persistent homology using graph neural networks.Advances in Neural Information Processing Systems, 37:41103–41131, 2024
2024
-
[20]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019
2019
-
[21]
Arya Tschand, Muhammad Awad, Ryan Swann, Kesavan Ramakrishnan, Jeffrey Ma, Keith Lowery, Ganesh Dasika, and Vijay Janapa Reddi. Swizzleperf: Hardware-aware llms for gpu kernel performance optimization.arXiv preprint arXiv:2508.20258, 2025
-
[22]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[23]
Milvus: A purpose-built vector data management system
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. Milvus: A purpose-built vector data management system. InProceedings of the 2021 international conference on management of data, pages 2614–2627, 2021. 11 A System Prompt for Triton Kernel Evolution System Prompt: Evolver Yo...
2021
-
[24]
Direct Operator Replacement: Implement Triton kernels that faithfully reproduce the functionality of existing PyTorch operators
-
[25]
Operator Fusion: Combine multiple sequential operators into a single Triton kernel (e.g.,matmul + relu,layernorm + GELU,softmax + dropout)
-
[26]
Algorithmic Optimization: Modify the computation strategy to improve perfor- mance (e.g., online softmax, reduced precision, layout transformation)
-
[27]
Multi-Operator Rewrite: Replace multiple operators in a single iteration if benefi- cial. Evolution Workflow • You will be provided with: –Historical evolution code –Current evolved code –Performance metrics (speedup, runtimes, correctness and so on) • Based on this context, your goal is to generate thenext evolved versionof the code. You are only limited...
-
[28]
Optimize the architecture named Model with custom Triton operators while preserv- ing full functional equivalence: {initial_param_code}
-
[29]
Output only the new model code, with no additional text and no testing code
Generate a single, complete, and syntactically correct Python code block named ModelNew. Output only the new model code, with no additional text and no testing code
-
[30]
The core logic must be implemented in a Triton kernel decorated with@triton.jit. 12
-
[31]
Always include the following imports: import torch import triton import triton.language as tl
-
[32]
Do not change parameter names, counts, or order
Define each function with exactly the required signature. Do not change parameter names, counts, or order. Use PyTorch tensor type hints and usetl.constexpr only for compile-time constants
-
[33]
Carefully manage data types and use Triton operations ( tl.load, tl.store, tl.dot,tl.arange, masks, andtl.math) correctly
-
[34]
Final Verification
Assume Triton version 3.1.0 or later. Final Verification
-
[35]
All function signatures exactly match the required definitions
-
[36]
All function calls match their definitions
-
[37]
No undefined functions are called
-
[38]
B Expert Recommendations for Triton Kernel Optimization Curated Expert Recommendations: Correctness
No required parameters are missing. B Expert Recommendations for Triton Kernel Optimization Curated Expert Recommendations: Correctness
-
[39]
Ensure numerical stability by normalizing data before exponentiation to prevent over- flow, and use float32 for intermediate computations along with high-precision accumu- lators to reduce errors in accumulation
-
[40]
Follow API usage constraints strictly: avoid return, break, or continue in kernels and use masks instead; avoid lambda expressions and chained boolean operations, replacing them with inline functions or stepwise mask computations; avoid direct tensor indexing and usetl.loadandtl.store
-
[41]
Use tl.constexpr only for compile-time kernel parameters, such as block sizes or flags that control kernel structure, and never on the host side or in kernel launch functions
-
[42]
Maintain a systematic debugging checklist: verify all loads/stores have masks or bound- ary checks, strides are correct, array indexing does not exceed bounds, control flow uses masks appropriately, atomic operations are correctly applied for concurrent writes, and performance-related configurations (BLOCK_SIZE, memory access, grid size) are appropriate
-
[43]
Follow development best practices: write descriptive variable names, include sufficient comments explaining computation logic, and keep kernel functions concise and clear
-
[44]
Fix random seeds before kernel execution to maintain reproducibility, and ensure parameter names and module calls match the original PyTorch module
For convolution kernels, ensure that PyTorch random weights are replicated on the Triton host side using the same module and device as in PyTorch. Fix random seeds before kernel execution to maintain reproducibility, and ensure parameter names and module calls match the original PyTorch module
-
[45]
When debugging kernels, check for grid and program ID mismatches, e.g., launching a 1D grid while the kernel expects 2D program IDs, and ensure program IDs are correctly mapped inside the kernel to avoid runtime errors
-
[46]
Introduce controlled approximation techniques where exact precision is unnecessary: reduce intermediate precision selectively, enable early termination for iterative compu- tations, and apply approximate or statistically unbiased accumulation to trade minimal accuracy loss for significant performance gains. 13
-
[47]
Memory-bound
Handle precision explicitly and consistently: mix precisions only where numerically safe, avoid dynamic scaling inside kernels, apply saturation or clamping logic explicitly when required, and prefer deterministic rounding unless stochastic rounding provides measurable benefits. Memory-bound
-
[48]
Use tl.make_block_ptr with boundary_check for 2D data and carefully design stride parameters to prevent performance degradation
For memory access optimization, maintain contiguous and local memory access patterns. Use tl.make_block_ptr with boundary_check for 2D data and carefully design stride parameters to prevent performance degradation
-
[49]
Pack data explicitly to improve vectorization and memory coalescing: reorganize inputs into structure-of-arrays (SoA) layouts, apply sub-tile packing for irregular shapes, and handle diagonal or sparse-like access patterns via pre-packed contiguous buffers
-
[50]
Employ flexible tiling strategies: dynamically adjust tile sizes based on tensor aspect ratios, use rectangular tiles for asymmetric dimensions, and apply hierarchical tiling (register-level, shared-memory-level, global-memory-level) to maximize locality while maintaining occupancy
-
[51]
Tune prefetch distance to balance latency hiding and cache pollution, and differentiate between temporal reuse (keep in cache) and streaming accesses (avoid cache thrashing)
Utilize software-managed prefetching by staging future data accesses across pipeline stages. Tune prefetch distance to balance latency hiding and cache pollution, and differentiate between temporal reuse (keep in cache) and streaming accesses (avoid cache thrashing)
-
[52]
Design parallelization schemes that minimize synchronization: decompose work recur- sively when beneficial, structure kernels to avoid global barriers, and rely on implicit program independence rather than explicit coordination whenever possible
-
[53]
Optimize cache utilization by enforcing cache-line-aligned accesses, batching writes to enable write-combining, and applying sliding-window or cache-oblivious access patterns to sustain reuse across successive tiles
-
[54]
Instruction-bound
Minimize memory access overhead by reducing pointer arithmetic, selecting stride- minimizing layouts, avoiding redundant transpositions, and choosing blocking factors that align with L1/L2 cache capacities. Instruction-bound
-
[55]
Avoid sizes that are excessively small or large, as they can reduce performance or limit concurrency
Choose block sizes as powers of two (e.g., 256, 512, 1024) and tune them to balance parallelism and resource usage. Avoid sizes that are excessively small or large, as they can reduce performance or limit concurrency
-
[56]
Avoid excessive unrolling that may cause register spilling or reduce occupancy
Align kernel designs with hardware execution characteristics by explicitly unrolling compute-heavy loops when register pressure allows, and interleave arithmetic instruc- tions with memory operations to hide global memory latency. Avoid excessive unrolling that may cause register spilling or reduce occupancy
-
[57]
Fuse type conversions into load/store paths to avoid standalone cast operations and unnecessary kernel launches
Exploit mixed-precision computation safely by promoting accumulators to higher pre- cision (e.g., FP32 accumulation for FP16 inputs) while keeping inputs and outputs in lower precision. Fuse type conversions into load/store paths to avoid standalone cast operations and unnecessary kernel launches
-
[58]
Favor instruction selections that map efficiently to GPU hardware: replace branches with mask-based arithmetic, maximize fused multiply-add (FMA) usage, leverage native FP16/BF16 operations when supported, and avoid instructions with high latency or low throughput
-
[59]
Structure kernels to naturally pipeline FMA-heavy instruction streams and maximize instruction-level parallelism within each program instance
Map SIMD-style parallelism onto Triton abstractions by expressing vectorized computa- tion through block-level operations. Structure kernels to naturally pipeline FMA-heavy instruction streams and maximize instruction-level parallelism within each program instance. Latency-bound
-
[60]
Avoid overly complex kernels that are difficult to tune and debug
Decompose complex operators into multiple simpler kernels when possible. Avoid overly complex kernels that are difficult to tune and debug. 14
-
[61]
Maximize performance by dynamically exploring key parameters such as BLOCK_SIZE, num_stages, and num_warps, experimenting with alternative algo- rithmic implementations (e.g., naive, online, fused softmax), optimizing memory access patterns and numerical stability, and evaluating all feasible operator fusion strategies while respecting hardware resource c...
-
[62]
Autotune primary kernel fields systematically: choose appropriate tile sizes for GEMM or tensor contractions (BLOCK_M, BLOCK_N, BLOCK_K) to balance compute den- sity and cache locality; select pipeline depth (num_stages) according to the number of fused GEMMs; and choose the number of warps per block (num_warps, typically 1–16) to balance utilization, reg...
-
[63]
Convert conditional branches into mask-based arithmetic or masked loads/stores to reduce divergence and improve warp-level efficiency
Replace control-flow-heavy logic with predicated execution whenever feasible. Convert conditional branches into mask-based arithmetic or masked loads/stores to reduce divergence and improve warp-level efficiency
-
[64]
Select algorithms adaptively based on input size and shape: prefer direct or outer- product formulations for small or skinny tensors, switch to tiled inner-product or block GEMM-style implementations for large workloads, and introduce size-based thresholds to avoid inefficient recursive or asymptotically optimal algorithms in practice
-
[65]
Schedule instructions to minimize critical paths: separate dependent load–compute–store chains across stages, prefetch data early using staged pipelines (num_stages), and balance arithmetic intensity across warps to avoid execution port underutilization
-
[66]
Optimize reduction patterns by using hierarchical, multi-stage reductions: perform partial reductions within registers or shared memory, cache intermediate results when reused, and avoid atomic operations unless inter-program synchronization is unavoid- able
-
[67]
Dispatch these fast paths from the host to avoid penalizing the general kernel with extra conditionals
Provide specialized kernel variants for common corner cases, such as very small tensors, power-of-two dimensions, or strictly contiguous layouts. Dispatch these fast paths from the host to avoid penalizing the general kernel with extra conditionals
-
[68]
Construct software pipelines that explicitly overlap loads, computation, and stores: break long dependency chains, minimize pipeline bubbles by balancing instruction mix, and tune num_stages and num_warps jointly to maximize sustained throughput on the target GPU
-
[69]
"" 40Model that performs a 3D convolution, applies Softmax (via Triton), and performs two max pooling operations. 41
Balance workload assignment across Triton programs by partitioning work according to computational intensity rather than raw element count. Prefer fine-grained program decomposition for irregular workloads, and prioritize critical-path computations to avoid stragglers that limit overall kernel completion time. C Case Study C.1 Cheating Case of AutoTriton ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.