SkillSmith: Co-Evolving Skills and Tools for Self-Improving Agent Systems
Pith reviewed 2026-06-28 16:54 UTC · model grok-4.3
The pith
SkillSmith shows that jointly evolving skills and tools via an interaction matrix improves agent performance on complex tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
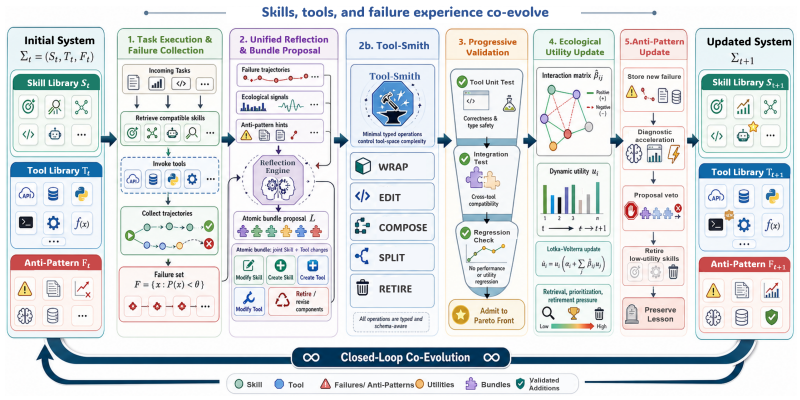
The paper claims that introducing a unified proposal space for joint skill-tool modifications, combined with an interaction matrix from execution traces to model complementarity and conflict, and anti-pattern recording, allows SkillSmith to outperform baselines, with the advantage becoming more pronounced as tasks require greater complexity and simultaneous skill use.
What carries the argument
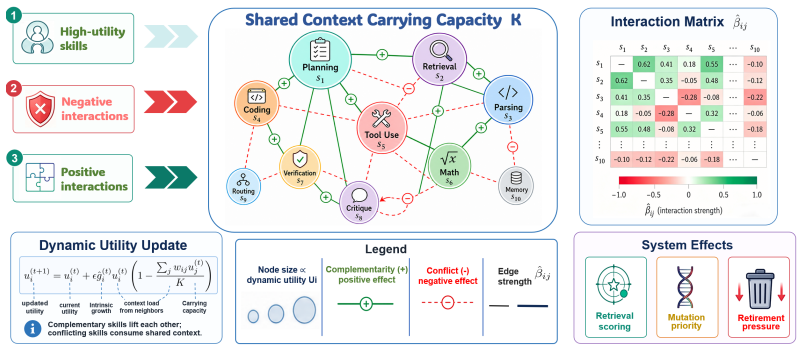
The ecological utility model inspired by Lotka-Volterra dynamics, where an interaction matrix estimated from execution traces provides pressure signals for retrieval, mutation, and retirement of skills and tools.
If this is right
- The performance advantage increases with higher task complexity.
- Gains are larger when multiple skills must be co-activated.
- Tools can be dynamically wrapped, edited, composed, split, or retired based on skill needs.
- Anti-patterns accelerate diagnosis and prevent repeating known failures.
Where Pith is reading between the lines
- Similar co-evolution mechanisms could be applied to other domains like code generation or robotic control.
- The approach may reduce the need for manual tool design in agent development.
- It opens questions about scaling the interaction matrix estimation to very large skill libraries.
Load-bearing premise
The interaction matrix estimated from execution traces accurately captures pairwise complementarity and conflict among skills and tools in a manner that usefully guides proposal prioritization and retirement.
What would settle it
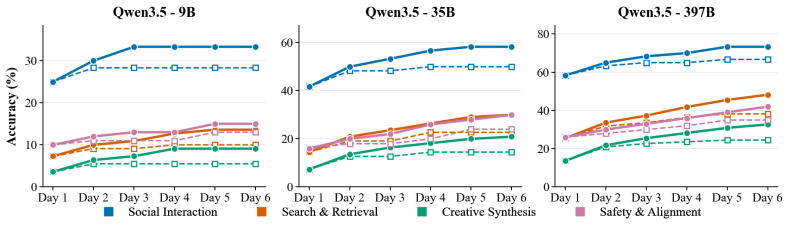
Running SkillSmith and baselines on a new set of tasks with high multi-skill requirements where the gains do not amplify would falsify the claim that benefits increase with complexity.
Figures





read the original abstract
Recent self-evolving agents have shown that skills can be discovered, refined, and accumulated through execution. However, existing skill-evolution frameworks typically assume a fixed tool layer and evaluate each skill independently, limiting their ability to repair tool-level failures or reason about interactions among skills. We propose SkillSmith, a synergy-aware skill-tool co-evolution framework. SkillSmith introduces a unified proposal space in which reflection produces atomic bundles that jointly modify skills and tools, allowing tools to be wrapped, edited, composed, split, or retired when skill evolution identifies a reusable capability gap. To guide this joint search, SkillSmith maintains an ecological utility model inspired by Lotka-Volterra dynamics, where an interaction matrix estimated from execution traces captures pairwise complementarity and conflict among skills and provides pressure signals for retrieval, mutation prioritization, and retirement. Furthermore, SkillSmith records anti-patterns, including failure signatures, causal attributions, and remedies, to accelerate diagnosis and veto proposals that repeat known mistakes. Experiments on three benchmarks, including WildClawBench, and five Qwen3.5 model scales show that SkillSmith consistently outperforms strong baselines, with gains that amplify as task complexity and multi-skill co-activation increase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillSmith, a synergy-aware skill-tool co-evolution framework for self-improving agents. It introduces a unified proposal space where reflection generates atomic bundles that jointly edit skills and tools (wrap, compose, split, retire), guided by an ecological utility model inspired by Lotka-Volterra dynamics. An interaction matrix estimated from execution traces supplies pairwise complementarity/conflict signals for prioritization, retrieval, and retirement; anti-patterns (failure signatures, attributions, remedies) are recorded to veto repeated mistakes. Experiments across three benchmarks (including WildClawBench) and five Qwen3.5 scales claim consistent outperformance over strong baselines, with gains amplifying under higher task complexity and multi-skill co-activation.
Significance. If the empirical claims hold under rigorous controls, the work would advance self-evolving agent systems by moving beyond independent skill evolution and fixed tool layers to joint skill-tool search with explicit interaction modeling. The anti-pattern recording mechanism offers a practical way to accumulate diagnostic knowledge. The Lotka-Volterra framing is novel in this domain, but its value hinges on whether the interaction matrix provides stable, non-circular guidance rather than merely reflecting the system's own traces.
major comments (3)
- [§3.2] §3.2 (Ecological Utility Model): the interaction matrix is estimated from execution traces, yet the manuscript does not specify whether these traces come from an independent baseline agent, a held-out validation set, or the SkillSmith loop itself. If the latter, the matrix encodes self-generated patterns, undermining the claim that it supplies independent 'pressure signals' for prioritization and retirement; this directly affects the central synergy-aware claim.
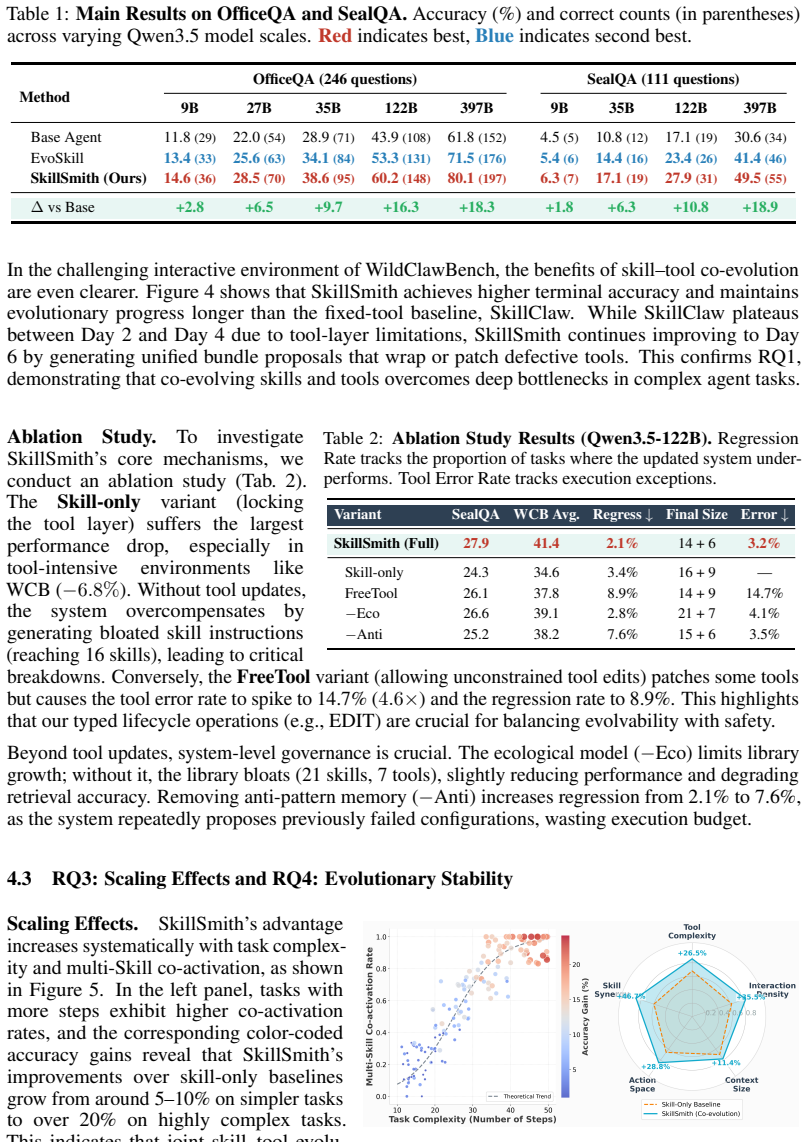
- [§4] §4 (Experiments): the abstract and results claim consistent outperformance with gains that 'amplify as task complexity and multi-skill co-activation increase,' but no details are provided on baseline implementations, number of runs, statistical significance tests, or how utility-model parameters (including matrix entries) are set or tuned. Without these, the headline performance claim cannot be evaluated and is load-bearing for the paper's contribution.
- [§3.3] §3.3 (Anti-pattern Recording): the mechanism for recording and vetoing failure signatures is described at a high level, but the manuscript does not report how anti-patterns are matched at proposal time, their coverage rate, or an ablation showing their contribution to the reported gains; this leaves open whether the performance edge stems from the ecological model or from the veto mechanism.
minor comments (2)
- [§3.2] Notation for the interaction matrix (e.g., symbols for complementarity vs. conflict entries) is introduced without a consolidated table; a single reference table would improve readability.
- [§4] The three benchmarks are named but their task distributions, skill/tool counts, and multi-skill co-activation statistics are not summarized in a table; adding this would clarify where gains are largest.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating the revisions that will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Ecological Utility Model): the interaction matrix is estimated from execution traces, yet the manuscript does not specify whether these traces come from an independent baseline agent, a held-out validation set, or the SkillSmith loop itself. If the latter, the matrix encodes self-generated patterns, undermining the claim that it supplies independent 'pressure signals' for prioritization and retirement; this directly affects the central synergy-aware claim.
Authors: The manuscript does not explicitly identify the source of the execution traces. These traces are generated within the SkillSmith loop. We will revise §3.2 to state this clearly and add justification that the Lotka-Volterra-inspired matrix still provides non-circular guidance through temporal separation: past traces inform current prioritization and retirement decisions for new proposals. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and results claim consistent outperformance with gains that 'amplify as task complexity and multi-skill co-activation increase,' but no details are provided on baseline implementations, number of runs, statistical significance tests, or how utility-model parameters (including matrix entries) are set or tuned. Without these, the headline performance claim cannot be evaluated and is load-bearing for the paper's contribution.
Authors: We agree that §4 lacks these implementation details. We will expand the section to describe baseline implementations, the number of runs, statistical significance tests performed, and the exact procedure for setting and tuning utility-model parameters including interaction matrix entries. revision: yes
-
Referee: [§3.3] §3.3 (Anti-pattern Recording): the mechanism for recording and vetoing failure signatures is described at a high level, but the manuscript does not report how anti-patterns are matched at proposal time, their coverage rate, or an ablation showing their contribution to the reported gains; this leaves open whether the performance edge stems from the ecological model or from the veto mechanism.
Authors: The anti-pattern mechanism is presented at a high level in §3.3. We will revise to specify the matching procedure at proposal time, report observed coverage rates, and add an ablation isolating the veto mechanism's contribution to the reported gains. revision: yes
Circularity Check
No significant circularity; ecological model uses external inspiration and empirical estimation without reducing claims to inputs by construction
full rationale
The paper describes a framework whose central component is an interaction matrix estimated from execution traces to supply pressure signals, explicitly inspired by Lotka-Volterra dynamics (an external reference). Outperformance is reported via benchmark experiments rather than any first-principles derivation or prediction that collapses to the fitted matrix. No equations, self-citations, or uniqueness theorems are invoked that would make the reported gains tautological with the estimation procedure itself. The estimation step is a modeling choice whose validity is tested externally on held-out tasks, satisfying the criteria for a self-contained empirical system.
Axiom & Free-Parameter Ledger
free parameters (1)
- interaction matrix entries
axioms (1)
- domain assumption Lotka-Volterra dynamics provide appropriate pressure signals for skill-tool co-evolution
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Understanding the planning of LLM agents: A survey
URL https://github.com/InternLM/ WildClawBench. Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2603.12056 , year=
Guanyu Jiang, Zhaochen Su, Xiaoye Qu, and Yi R Fung. Xskill: Continual learning from experience and skills in multimodal agents.arXiv preprint arXiv:2603.12056,
-
[5]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, et al. Mrkl systems: A modular, neuro-symbolic ar- chitecture that combines large language models, external knowledge sources and discrete reasoning. arXiv preprint arXiv:2205.00445,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
Xingyan Liu, Xiyue Luo, Linyu Li, Ganghong Huang, Jianfeng Liu, and Honglin Qiao. Skillforge: Forging domain-specific, self-evolving agent skills in cloud technical support.arXiv preprint arXiv:2604.08618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills. arXiv preprint arXiv:2603.25158,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models
Thinh Pham, Nguyen Nguyen, Pratibha Zunjare, Weiyuan Chen, Yu-Min Tseng, and Tu Vu. Sealqa: Raising the bar for reasoning in search-augmented language models.arXiv preprint arXiv:2506.01062,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
gradient descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7957–7968,
2023
-
[12]
Dynamic Dual-Granularity Skill Bank for Agentic RL
Accessed: 2026-02-20. 11 Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dong- bin Zhao. Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, et al. Skillx: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Barry Zhang, Keith Lazuka, and Mahesh Murag. Equipping agents for the real world with agent skills, october 2025.URL https://www. anthropic. com/engineering/equipping-agents-for-the-real- world-with-agent-skills. Accessed, pages 01–28, 2026a. Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Did the European Central Bank raise or lower interest rates at its June 2024 meeting, and by how many basis points?
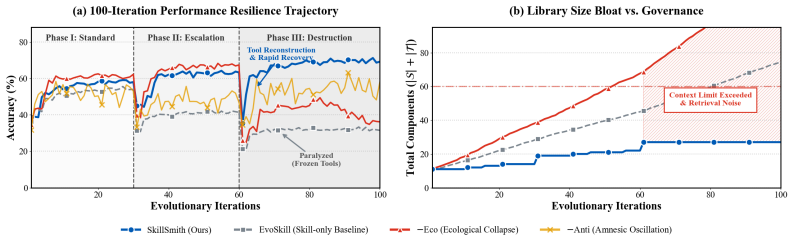
shows how anti-pattern memory prevents amnesic regression on WildClawBench by vetoing a re-proposed configuration that was previously validated to fail. D Experimental Details D.1 Data Splits OfficeQA The Mosaic Research Team [2025].The dataset contains 246 questions over ∼89k pages of U.S. Treasury Bulletin archives. Following the stratified protocol of ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.