StochasT: Learning with Stochastic Turn Depth for Visual Instruction Tuning
Pith reviewed 2026-07-02 15:01 UTC · model grok-4.3
The pith
StochasT stochastically varies training turn depth to align multi-turn training with single-turn testing in LVLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
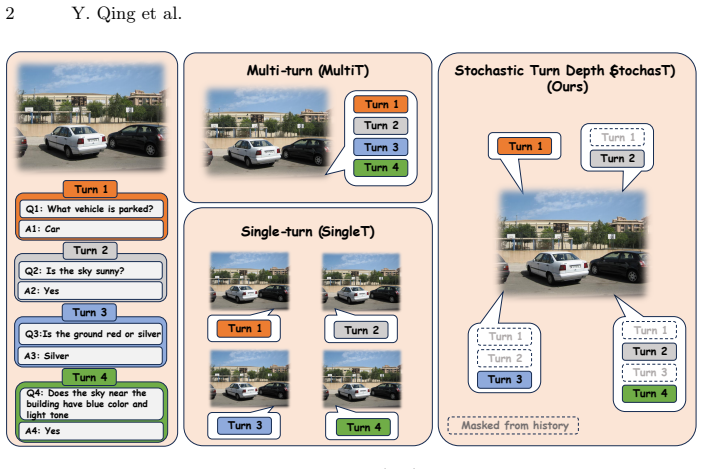
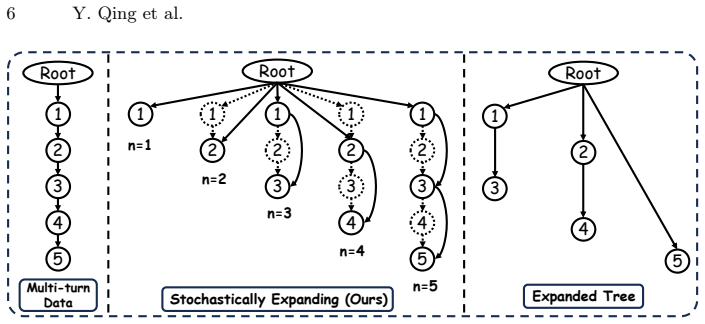
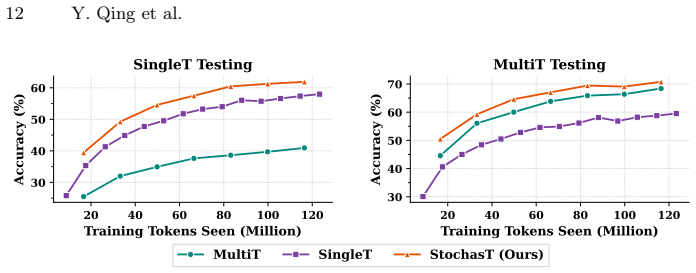
StochasT learns with stochastic turn depth by grouping language tasks for the same image into clusters of varying sizes while preserving their organic order. This mitigates visual attention decay and contextual overfitting from multi-turn training, closing the gap to single-turn test scenarios. As a result, LVLMs gain strong, harmonized capabilities for both single-turn and multi-turn use cases. The method is benchmark-agnostic and uses a Balanced Latin Square evaluation to test robustness under varying contextual dependencies.
What carries the argument
Stochastic Turn Depth: stochastically grouping tasks into clusters of varying sizes while preserving organic order to avoid dropping data.
If this is right
- LVLMs will realize their full potential in single-turn benchmarks.
- Models will have harmonized performance in both single-turn and multi-turn scenarios.
- The new Balanced Latin Square evaluation will accurately measure robustness to contextual dependencies.
- Training utility is maximized as no data is dropped unlike in dropout methods.
Where Pith is reading between the lines
- StochasT could be adapted to other sequential data training in language or multimodal models to reduce context overfitting.
- Varying turn depths might reveal that fixed training contexts are a common source of generalization issues in instruction tuning.
- The method suggests potential for improved data efficiency in visual instruction datasets.
Load-bearing premise
Visual attention decay and contextual overfitting during multi-turn training are the primary causes of the train-test discrepancy, and that stochastic grouping of tasks will mitigate them without introducing new issues.
What would settle it
If LVLMs trained with StochasT continue to show significant discrepancies in performance between single-turn and multi-turn evaluations on existing benchmarks, the approach would not have closed the gap as claimed.
Figures



read the original abstract
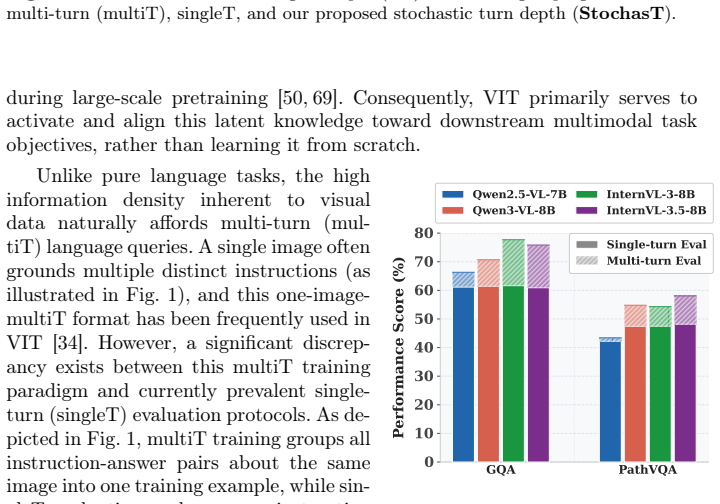
Large Vision-Language Models (LVLMs) rely extensively on Visual Instruction Tuning (VIT) to elicit their multimodal reasoning capabilities. However, we find a discrepancy: VIT often packs multiple language tasks about the same image for conversational, multi-turn training, whereas existing benchmarks evaluate LVLMs in isolated, single-turn scenarios. The models can suffer from visual attention decay and contextual overfitting during multi-turn training, making it hard for them to realize their full potential in the mismatched test phase. To close the gap, we propose learning with Stochastic Turn Depth (StochasT), which stochastically groups language tasks for the same image into clusters of varying sizes (turn depth) while preserving their organic order. Hence, while StochasT draws on Dropout and stochastic depth for ResNets, it does not actually drop anything to maximize the utility of the training data. Furthermore, we introduce a challenging, benchmark-agnostic evaluation mechanism based on the Balanced Latin Square to measure LVLMs' robustness under varying contextual dependencies. Extensive experiments demonstrate that StochasT effectively grants LVLMs strong, harmonized capabilities for both single-turn and multi-turn use cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a train-test discrepancy in LVLMs where multi-turn Visual Instruction Tuning packs multiple tasks per image while benchmarks use isolated single-turn queries, attributing performance gaps to visual attention decay and contextual overfitting. It proposes StochasT to stochastically group ordered tasks into clusters of varying sizes (turn depths) without dropping data, drawing loose inspiration from dropout and stochastic depth. A new benchmark-agnostic evaluation protocol based on the Balanced Latin Square is introduced to test robustness under varying contextual dependencies. Experiments are claimed to show that StochasT yields harmonized strong performance for both single-turn and multi-turn use cases.
Significance. If the empirical results hold under scrutiny, StochasT offers a lightweight training intervention that could improve LVLMs' versatility across interaction lengths without data loss, addressing a practical mismatch in current VIT pipelines. The Balanced Latin Square protocol provides a reusable tool for evaluating contextual robustness that is independent of specific benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that StochasT 'effectively grants LVLMs strong, harmonized capabilities' rests entirely on 'extensive experiments,' yet no metrics, baselines, ablation controls, or error bars are described even at a high level; without these, it is impossible to assess whether the stochastic grouping actually mitigates attention decay or merely trades one form of overfitting for another.
- [Abstract] Abstract: the premise that attention decay and contextual overfitting are the dominant causes of the discrepancy is presented as motivation, but the manuscript supplies no direct measurement or ablation isolating these factors from other possible sources (e.g., task ordering statistics or image complexity); this makes the design choice of stochastic clustering load-bearing yet untested in the provided description.
minor comments (1)
- [Abstract] Abstract: the phrase 'draws on Dropout and stochastic depth for ResNets, it does not actually drop anything' is unclear without a precise statement of the sampling distribution over cluster sizes or how order preservation is enforced.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address each major comment below and indicate planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that StochasT 'effectively grants LVLMs strong, harmonized capabilities' rests entirely on 'extensive experiments,' yet no metrics, baselines, ablation controls, or error bars are described even at a high level; without these, it is impossible to assess whether the stochastic grouping actually mitigates attention decay or merely trades one form of overfitting for another.
Authors: We agree the abstract is too high-level. The full manuscript reports concrete metrics (e.g., accuracy deltas on single-turn and multi-turn benchmarks versus standard VIT baselines), ablation studies on turn-depth distributions, and results with standard deviations. In revision we will add one sentence summarizing key quantitative outcomes while respecting length limits. revision: yes
-
Referee: [Abstract] Abstract: the premise that attention decay and contextual overfitting are the dominant causes of the discrepancy is presented as motivation, but the manuscript supplies no direct measurement or ablation isolating these factors from other possible sources (e.g., task ordering statistics or image complexity); this makes the design choice of stochastic clustering load-bearing yet untested in the provided description.
Authors: The motivation section of the paper grounds the discrepancy in observed performance gaps between multi-turn training and single-turn evaluation. Direct isolation via attention maps is not performed; the stochastic clustering is instead validated indirectly through robustness experiments under the Balanced Latin Square protocol. We will expand the introduction to acknowledge alternative factors such as task ordering and note that the current design targets context-length variation. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces StochasT as a direct training intervention: stochastic grouping of tasks into variable-size clusters while preserving order, explicitly distinguished from dropout by not dropping data. No equations, predictions, or results are defined in terms of fitted parameters that are then re-used as outputs. The Balanced Latin Square evaluation protocol is a new measurement construct, not derived from the training method itself. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain consists of a motivated design choice followed by empirical demonstration, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
An, W., Tian, F., Leng, S., Nie, J., Lin, H., Wang, Q., Chen, P., Zhang, X., Lu, S.: Mitigating object hallucinations in large vision-language models with assembly of global and local attention. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29915–29926 (2025)
2025
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bradley, J.V.: Complete counterbalancing of immediate sequential effects in a latin square design. Journal of the American Statistical Association53(282), 525–528 (1958),http://www.jstor.org/stable/2281872
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cha, J., Kang, W., Mun, J., Roh, B.: Honeybee: Locality-enhanced projector for multimodal llm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13817–13827 (2024)
2024
-
[6]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=4SUtAp2cm0
Chen, B., Hong, D., Ji, J., Zheng, J., Dong, B., Zhou, J., Wang, K., Dai, J., Wang, X., Chen, W., Zheng, Q., Li, W., Han, S., Guo, Y., Yang, Y.: InterMT: Multi-turn interleaved preference alignment with human feedback. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.n...
2025
-
[7]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 16 Y. Qing et al
2024
-
[8]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., et al.: Are we on the right way for evaluating large vision- language models? Advances in Neural Information Processing Systems37, 27056– 27087 (2024)
2024
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Y., Sikka, K., Cogswell, M., Ji, H., Divakaran, A.: Dress: Instructing large vision-language models to align and interact with humans via natural language feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14239–14250 (2024)
2024
-
[10]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality (March 2023),https://lmsys.org/ blog/2023-03-30-vicuna/
2023
-
[11]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Advances in neural information processing systems37, 96449–96467 (2024)
Cui, H., Mao, L., Liang, X., Zhang, J., Ren, H., Li, Q., Li, X., Yang, C.: Biomedical visual instruction tuning with clinician preference alignment. Advances in neural information processing systems37, 96449–96467 (2024)
2024
-
[13]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
2023
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
In: Proceedings of the 32nd ACM international conference on multimedia
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al.: Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In: Proceedings of the 32nd ACM international conference on multimedia. pp. 11198–11201 (2024)
2024
- [16]
-
[17]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Feng, J., Sun, Q., Xu, C., Zhao, P., Yang, Y., Tao, C., Zhao, D., Lin, Q.: Mmdi- alog: A large-scale multi-turn dialogue dataset towards multi-modal open-domain conversation. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 7348–7363 (2023)
2023
-
[18]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=DgH9YCsqWm
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: MME: A comprehensive evaluation benchmark for multimodal large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id...
2025
-
[19]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=iRsZHAMNHL
hongyonghan,Wang,W.,Zhang,G.,Li,M.,Wang,Y.:CoralVQA:Alarge-scalevi- sual question answering dataset for coral reef image understanding. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=iRsZHAMNHL
2025
-
[21]
PathVQA: 30000+ Questions for Medical Visual Question Answering
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020) StochasT: Stochastic Turn Depth for VIT 17
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[22]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https: //openreview.net/forum?id=atofIc3x1q
Hsieh, H.Y., Liu, S.W., Meng, C.C., Chen, C.H., Lin, S.Y., Lin, H.J., Huang, H.H., Wu, I.C.: TaiwanVQA: Benchmarking and enhancing cultural understand- ing in vision-language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https: //openreview.net/forum?id=atofIc3x1q
2025
-
[23]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[24]
In: European conference on computer vision
Huang, G., Sun, Y., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In: European conference on computer vision. pp. 646–661. Springer (2016)
2016
-
[25]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7b (2023),https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Lee, Y.: Qwen2-vl-finetune (2024),https://github.com/2U1/Qwen2-VL-Finetune
2024
-
[27]
arXiv preprint arXiv:2505.23121 (2025)
Lei, Y., Yang, Z., Liu, Z., Leng, H., Liu, S., Gao, T., Liu, Q., Wang, Y.: Contextq- former: A new context modeling method for multi-turn multi-modal conversations. arXiv preprint arXiv:2505.23121 (2025)
-
[28]
Li, B., Ge, Y., Chen, Y., Ge, Y., Zhang, R., Shan, Y.: Seed-bench-2-plus: Bench- marking multimodal large language models with text-rich visual comprehension. arXiv preprint arXiv:2404.16790 (2024)
-
[29]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR)
Li, J., Ma, W., Li, X., Lou, Y., Zhou, G., Zhou, X.: Cad-llama: Leveraging large language models for computer-aided design parametric 3d model generation. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR). pp. 18563–18573 (June 2025)
2025
-
[30]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lin, W., Mirza, M.J., Doveh, S., Feris, R., Giryes, R., Hochreiter, S., Karlinsky, L.: Comparison visual instruction tuning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2973–2983 (2025)
2025
-
[32]
In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., Wang, L.: Mitigating hallucination in large multi-modal models via robust instruction tuning. In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview. net/forum?id=J44HfH4JCg
2024
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 26296–26306 (June 2024)
2024
-
[34]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[35]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Liu, J., Zheng, S., Karlsson, B.F., Lu, Z.: Taking notes brings focus? towards multi- turn multimodal dialogue learning. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 33303–33324. Association for Computational Linguistics, Suzhou, China (No...
-
[36]
Advances in Neural Information Processing Systems37, 100734–100782 (2024) 18 Y
Liu, S., Ying, K., Zhang, H., Yang, Y., Lin, Y., Zhang, T., Li, C., Qiao, Y., Luo, P., Shao, W., et al.: Convbench: A multi-turn conversation evaluation benchmark with hierarchical ablation capability for large vision-language models. Advances in Neural Information Processing Systems37, 100734–100782 (2024) 18 Y. Qing et al
2024
-
[37]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024)
2024
-
[38]
Advances in Neural Information Processing Systems37, 8698–8733 (2024)
Liu, Z., Chu, T., Zang, Y., Wei, X., Dong, X., Zhang, P., Liang, Z., Xiong, Y., Qiao, Y., Lin, D., et al.: Mmdu: A multi-turn multi-image dialog understanding bench- mark and instruction-tuning dataset for lvlms. Advances in Neural Information Processing Systems37, 8698–8733 (2024)
2024
-
[39]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Luo, C., Shen, Y., Zhu, Z., Zheng, Q., Yu, Z., Yao, C.: Layoutllm: Layout instruc- tion tuning with large language models for document understanding. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15630–15640 (2024)
2024
-
[41]
In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=yzHiEmLSk8
Oh, C., Li, J., Im, S., Li, S.: Visual instruction bottleneck tuning. In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=yzHiEmLSk8
2025
-
[42]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback (2022),https:// arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
arXiv preprint arXiv:2410.07113 (2024)
Pi, R., Zhang, J., Han, T., Zhang, J., Pan, R., Zhang, T.: Personalized visual instruction tuning. arXiv preprint arXiv:2410.07113 (2024)
-
[44]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[47]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
The journal of machine learning research15(1), 1929–1958 (2014)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research15(1), 1929–1958 (2014)
1929
- [50]
-
[51]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, StochasT: Stochastic Turn Depth for VIT 19 G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Bu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., et al.: Kimi-vl technical report. arXiv preprint arXiv:2504.07491 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Advances in neural information processing systems 17(2004)
Teh, Y., Jordan, M., Beal, M., Blei, D.: Sharing clusters among related groups: Hierarchical dirichlet processes. Advances in neural information processing systems 17(2004)
2004
-
[54]
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: Llama: Open and efficient foundation language models (2023), https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Van Horn, G., Cole, E., Beery, S., Wilber, K., Belongie, S., Mac Aodha, O.: Bench- marking representation learning for natural world image collections. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12884–12893 (2021)
2021
-
[56]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, H., Zhao, Y., Wang, T., Fan, H., Zhang, X., Zhang, Z.: Ross3d: Reconstruc- tive visual instruction tuning with 3d-awareness. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9275–9286 (2025) 20 Y. Qing et al
2025
-
[57]
In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= 8q9NOMzRDg
Wang, H., Zheng, A., Zhao, Y., Wang, T., Ge, Z., Zhang, X., Zhang, Z.: Re- constructive visual instruction tuning. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= 8q9NOMzRDg
2025
-
[58]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hou, Z., Hao, H., Zhang, T., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
In: Pro- ceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers)
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N.A., Khashabi, D., Hajishirzi, H.: Self-instruct: Aligning language models with self-generated instructions. In: Pro- ceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). pp. 13484–13508 (2023)
2023
-
[61]
Wei, J., Bosma, M., Zhao, V.Y., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M., Le, Q.V.: Finetuned language models are zero-shot learners (2022),https: //arxiv.org/abs/2109.01652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
Wei, L., Jiang, Z., Huang, W., Sun, L.: Instructiongpt-4: A 200-instruction paradigm for fine-tuning minigpt-4 (2023),https://arxiv.org/abs/2308.12067
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
arXiv preprint arXiv:2503.18533 (2025)
Yan, D., Li, Y., Chen, Q.G., Luo, W., Wang, P., Zhang, H., Shen, C.: Mmcr: Advancing visual language model in multimodal multi-turn contextual reasoning. arXiv preprint arXiv:2503.18533 (2025)
-
[64]
arXiv preprint arXiv:2508.03469 (2025)
Yang, J., Cui, C., Zhou, Y., Chen, Y., Xia, P., Wei, Y., Yu, T., Huang, Y., Wang, L.: Ikod: Mitigating visual attention degradation in large vision-language models. arXiv preprint arXiv:2508.03469 (2025)
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yuan, Y., Li, W., Liu, J., Tang, D., Luo, X., Qin, C., Zhang, L., Zhu, J.: Os- prey: Pixel understanding with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28202– 28211 (2024)
2024
-
[66]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9556–9567 (2024)
2024
-
[67]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training (2023),https://arxiv.org/abs/2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [68]
-
[69]
Advances in Neural Information Processing Systems36, 55006–55021 (2023) StochasT: Stochastic Turn Depth for VIT 21
Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., Yu, L., et al.: Lima: Less is more for alignment. Advances in Neural Information Processing Systems36, 55006–55021 (2023) StochasT: Stochastic Turn Depth for VIT 21
2023
-
[70]
In: The Thirty-ninth An- nual Conference on Neural Information Processing Systems (2025),https:// openreview.net/forum?id=NQSWkmjODD
Zhou, Z., Hong, F., Luo, J., Ye, Y., Yao, J., Li, D., Han, B., Zhang, Y., Wang, Y.: Learning to instruct for visual instruction tuning. In: The Thirty-ninth An- nual Conference on Neural Information Processing Systems (2025),https:// openreview.net/forum?id=NQSWkmjODD
2025
-
[71]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.