Geometry-aware 4D Video Generation for Robot Manipulation
Pith reviewed 2026-05-22 00:08 UTC · model grok-4.3
The pith
Cross-view pointmap alignment during training produces a shared 3D scene representation that lets a video model generate geometrically consistent future sequences from novel viewpoints using only single RGB-D images and no camera poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By supervising training with cross-view pointmap alignment, the model learns a shared 3D scene representation. This representation lets the model generate spatio-temporally aligned future video sequences from novel viewpoints when given only a single RGB-D image per view and without any camera-pose information at inference time.
What carries the argument
cross-view pointmap alignment supervision that enforces multi-view 3D consistency and induces a shared scene representation
If this is right
- Predicted 4D videos yield more visually stable and spatially aligned frames than prior video-generation baselines on both simulated and real robotic datasets.
- An off-the-shelf 6DoF pose tracker applied to the generated videos recovers robot end-effector trajectories.
- The recovered trajectories produce manipulation policies that continue to work when the camera is placed at novel viewpoints.
Where Pith is reading between the lines
- The same geometric supervision might reduce the need for explicit camera calibration when deploying learned policies across multiple robots or environments.
- If the shared representation truly captures 3D structure, the generated videos could serve as synthetic training data for other 3D perception tasks such as depth estimation or object pose prediction.
Load-bearing premise
That forcing pointmap agreement across training views is enough to create a 3D representation that remains consistent and generalizes to unseen viewpoints even when no pose information is ever supplied to the model.
What would settle it
Generate videos from held-out viewpoints on a dataset with known ground-truth 3D structure and measure whether the reconstructed pointmaps or tracked end-effector trajectories diverge systematically from the true geometry.
Figures









read the original abstract
Understanding and predicting dynamics of the physical world can enhance a robot's ability to plan and interact effectively in complex environments. While recent video generation models have shown strong potential in modeling dynamic scenes, generating videos that are both temporally coherent and geometrically consistent across camera views remains a significant challenge. To address this, we propose a 4D video generation model that enforces multi-view 3D consistency of generated videos by supervising the model with cross-view pointmap alignment during training. Through this geometric supervision, the model learns a shared 3D scene representation, enabling it to generate spatio-temporally aligned future video sequences from novel viewpoints given a single RGB-D image per view, and without relying on camera poses as input. Compared to existing baselines, our method produces more visually stable and spatially aligned predictions across multiple simulated and real-world robotic datasets. We further show that the predicted 4D videos can be used to recover robot end-effector trajectories using an off-the-shelf 6DoF pose tracker, yielding robot manipulation policies that generalize well to novel camera viewpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 4D video generation model for robot manipulation that incorporates cross-view pointmap alignment as geometric supervision during training. This supervision is intended to induce a shared 3D scene representation, allowing the model to generate temporally coherent and geometrically consistent future video sequences from novel viewpoints. The input is a single RGB-D image per view with no camera poses or extrinsics provided at inference. The method is evaluated on simulated and real-world robotic datasets, showing improved visual stability and spatial alignment over baselines, and the generated 4D videos are used with an off-the-shelf 6DoF pose tracker to recover end-effector trajectories for viewpoint-generalizing manipulation policies.
Significance. If the cross-view pointmap supervision reliably produces a pose-invariant internal 3D representation that supports novel-view video generation, the work would offer a practical advance for robot planning in dynamic scenes by combining video synthesis with geometric consistency. The downstream use of predicted videos for trajectory recovery via standard pose tracking is a concrete strength, as it directly ties the generation output to policy generalization without requiring explicit 3D reconstruction at test time.
major comments (2)
- [§3.2] §3.2 (Cross-view pointmap alignment loss): The description of how pointmaps are lifted from RGB-D inputs and aligned across views does not specify whether alignment occurs in a canonical world frame or permits view-dependent corrections. If the loss is computed after independent per-view lifting using view-specific intrinsics and depths, it is possible for the network to satisfy the objective via feature adjustments that remain view-dependent, undermining the claim of a shared 3D representation usable at novel viewpoints without poses. A concrete test would be to ablate the alignment loss and measure drift in generated novel-view sequences.
- [§4.3] §4.3 (Novel-view generation experiments): The quantitative metrics for spatial alignment and visual stability are reported only on held-out views that may share similar camera distributions with training; it is unclear whether the evaluation includes truly out-of-distribution viewpoints or camera trajectories. Without such a split, the generalization claim rests on an assumption that the learned representation is pose-invariant rather than interpolative.
minor comments (2)
- [Abstract / §1] The abstract and introduction would benefit from a brief comparison table summarizing how the proposed geometric supervision differs from prior 4D or multi-view video models (e.g., those using explicit NeRF or pose-conditioned diffusion).
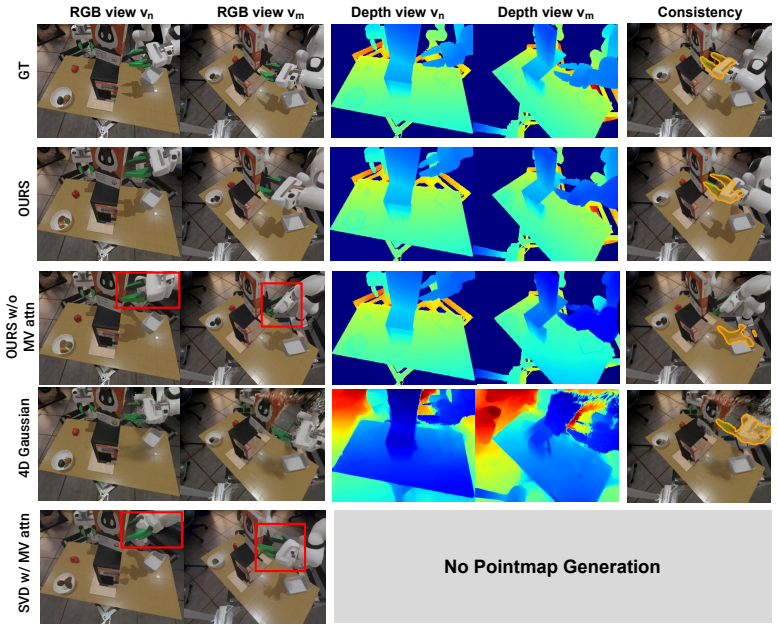
- [Figure 3] Figure 3 (qualitative results) shows generated frames but lacks overlaid pointmap visualizations or error heatmaps that would directly illustrate the effect of the alignment loss.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which have helped us identify areas for clarification and improvement in the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Cross-view pointmap alignment loss): The description of how pointmaps are lifted from RGB-D inputs and aligned across views does not specify whether alignment occurs in a canonical world frame or permits view-dependent corrections. If the loss is computed after independent per-view lifting using view-specific intrinsics and depths, it is possible for the network to satisfy the objective via feature adjustments that remain view-dependent, undermining the claim of a shared 3D representation usable at novel viewpoints without poses. A concrete test would be to ablate the alignment loss and measure drift in generated novel-view sequences.
Authors: We thank the referee for this precise observation on the description in §3.2. During training, pointmaps are lifted independently per view using the respective intrinsics and depth maps, then transformed into a shared canonical coordinate frame via the relative camera poses available in the multi-view training data. The alignment loss is computed directly on these transformed pointmaps in the common 3D space. This formulation is designed to penalize geometric inconsistencies across views and thereby encourage a shared scene representation. We acknowledge that the manuscript text does not explicitly detail the transformation step into the canonical frame, and we will revise §3.2 to include a clearer description of the lifting and alignment procedure. We also agree that an ablation removing the alignment loss and measuring resulting drift in novel-view sequences would strengthen the evidence; we will conduct this experiment and report the quantitative results in the revised manuscript. revision: yes
-
Referee: [§4.3] §4.3 (Novel-view generation experiments): The quantitative metrics for spatial alignment and visual stability are reported only on held-out views that may share similar camera distributions with training; it is unclear whether the evaluation includes truly out-of-distribution viewpoints or camera trajectories. Without such a split, the generalization claim rests on an assumption that the learned representation is pose-invariant rather than interpolative.
Authors: We appreciate the referee highlighting the need for greater clarity on the evaluation protocol in §4.3. The held-out views used for quantitative reporting are distinct poses sampled from the same overall camera distribution as the training data. To more rigorously support the pose-invariance claim, we will revise §4.3 to explicitly characterize the training and test camera pose distributions (including ranges of elevation, azimuth, and distance). We will also add results from additional camera trajectories that lie further outside the training distribution, such as extreme overhead or side angles not encountered during training, to better distinguish between interpolation and generalization to novel viewpoints. revision: partial
Circularity Check
No significant circularity; supervision is external to the model.
full rationale
The paper's core mechanism relies on an external geometric supervision signal (cross-view pointmap alignment computed from RGB-D inputs) applied during training. This does not reduce to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain. The abstract and description present the alignment loss as an independent training objective whose effect on inducing a shared 3D representation is an empirical claim, not a tautology by construction. No equations or uniqueness theorems from the authors' prior work are shown to force the result. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-view pointmap alignment during training enforces multi-view 3D consistency and produces a shared scene representation
Forward citations
Cited by 7 Pith papers
-
VistaBot: View-Robust Robot Manipulation via Spatiotemporal-Aware View Synthesis
VistaBot integrates 4D geometry estimation and spatiotemporal view synthesis into action policies to improve cross-view generalization by 2.6-2.8x on a new VGS metric in simulation and real tasks.
-
Action Images: End-to-End Policy Learning via Multiview Video Generation
Action Images turn robot arm motions into interpretable multiview pixel videos, letting video backbones serve as zero-shot policies for end-to-end robot learning.
-
Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
X-WAM unifies real-time robotic action execution with high-fidelity 4D world synthesis by adapting video diffusion priors through lightweight depth branches and asynchronous noise sampling, achieving 79-91% success on...
-
Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
X-WAM unifies robotic action execution and 4D world synthesis by adapting video diffusion priors with a lightweight depth branch and asynchronous noise sampling, achieving 79-91% success on robot benchmarks.
-
ShapeGen: Robotic Data Generation for Category-Level Manipulation
ShapeGen generates shape-diverse 3D robotic manipulation demonstrations without simulators by curating a functional shape library and applying a minimal-annotation pipeline for novel, physically plausible data.
-
Imagine2Real: Towards Zero-shot Humanoid-Object Interaction via Video Generative Priors
Imagine2Real is a zero-shot humanoid-object interaction method that unifies robot and object motion as 4D point trajectories, tracks only sparse keypoints inside a behavior foundation model latent space, and trains wi...
-
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
GeoPredict improves VLA manipulation accuracy by adding predictive kinematic trajectories and 3D Gaussian workspace geometry as training-time depth-rendering supervision.
Reference graph
Works this paper leans on
-
[1]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advances in Neural Information Processing Systems , 35:8633–8646, 2022
work page 2022
-
[3]
Sv4d: Dy- namic 3d content generation with multi-frame and multi-view consistency
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dy- namic 3d content generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470, 2024
-
[4]
Vivid-zoo: Multi-view video generation with diffusion model
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, and Bernard Ghanem. Vivid-zoo: Multi-view video generation with diffusion model. Advances in Neural Information Processing Systems, 37:62189–62222, 2024
work page 2024
-
[5]
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. 4diffusion: Multi-view video diffusion model for 4d generation.Advances in Neural Information Processing Systems, 37:15272–15295, 2024
work page 2024
-
[6]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697–20709, 2024
work page 2024
-
[7]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868–17879, 2024. 10
work page 2024
-
[8]
Unsupervised learning of video representations using lstms
Nitish Srivastava, Elman Mansimov, and Ruslan Salakhudinov. Unsupervised learning of video representations using lstms. In International conference on machine learning , pages 843–852. PMLR, 2015
work page 2015
-
[9]
Recurrent Environment Simulators
Silvia Chiappa, Sébastien Racaniere, Daan Wierstra, and Shakir Mohamed. Recurrent environ- ment simulators. arXiv preprint arXiv:1704.02254, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Generating videos with scene dynamics
Carl V ondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics. Advances in neural information processing systems , 29, 2016
work page 2016
-
[11]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Mardini: Masked autoregressive diffusion for video generation at scale,
Haozhe Liu, Shikun Liu, Zijian Zhou, Mengmeng Xu, Yanping Xie, Xiao Han, Juan C Pérez, Ding Liu, Kumara Kahatapitiya, Menglin Jia, et al. Mardini: Masked autoregressive diffusion for video generation at scale. arXiv preprint arXiv:2410.20280, 2024
-
[13]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Monocular depth estimation using diffusion models
Saurabh Saxena, Abhishek Kar, Mohammad Norouzi, and David J Fleet. Monocular depth estimation using diffusion models. arXiv preprint arXiv:2302.14816, 2023
-
[16]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. arXiv preprint arXiv:2409.02095, 2024
-
[17]
Learning temporally consistent video depth from video diffusion priors
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Vitor Guizilini, Yue Wang, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors. arXiv preprint arXiv:2406.01493, 2024
-
[18]
Pointmap-conditioned diffusion for consistent novel view synthesis
Thang-Anh-Quan Nguyen, Nathan Piasco, Luis Roldão, Moussab Bennehar, Dzmitry Tsishkou, Laurent Caraffa, Jean-Philippe Tarel, and Roland Brémond. Pointmap-conditioned diffusion for consistent novel view synthesis. arXiv preprint arXiv:2501.02913, 2025
-
[19]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. In European Conference on Computer Vision, pages 313–331. Springer, 2024
work page 2024
-
[20]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation. arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Collaborative video diffusion: Consistent multi-video generation with camera control
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control. Advances in Neural Information Processing Systems , 37:16240–16271, 2024
work page 2024
-
[22]
Boosting camera motion control for video diffusion transformers
Soon Yau Cheong, Duygu Ceylan, Armin Mustafa, Andrew Gilbert, and Chun-Hao Paul Huang. Boosting camera motion control for video diffusion transformers. arXiv preprint arXiv:2410.10802, 2024
-
[23]
Eg4d: Explicit generation of 4d object without score distillation
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, and Houqiang Li. Eg4d: Explicit generation of 4d object without score distillation. arXiv preprint arXiv:2405.18132, 2024
-
[24]
Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian surfels
Yikai Wang, Xinzhou Wang, Zilong Chen, Zhengyi Wang, Fuchun Sun, and Jun Zhu. Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian surfels. arXiv preprint arXiv:2405.16822, 2024. 11
-
[25]
Zeyu Yang, Zijie Pan, Chun Gu, and Li Zhang. Diffusion 2: Dynamic 3d content generation via score composition of video and multi-view diffusion models. arXiv preprint arXiv:2404.02148, 2024
-
[26]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. Advances in neural information processing systems, 36:9156–9172, 2023
work page 2023
-
[27]
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. arXiv preprint arXiv:2412.15109, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
Tesseract: Learning 4d embodied world models
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: Learning 4d embodied world models. arXiv preprint arXiv:2504.20995, 2025
-
[29]
Flow as the cross-domain manipulation interface
Mengda Xu, Zhenjia Xu, Yinghao Xu, Cheng Chi, Gordon Wetzstein, Manuela Veloso, and Shu- ran Song. Flow as the cross-domain manipulation interface. arXiv preprint arXiv:2407.15208, 2024
-
[30]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation. arXiv preprint arXiv:2409.16283, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Enerverse: Envisioning embodied future space for robotics manipulation
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yue Hu, Peng Gao, Hongsheng Li, Maoqing Yao, and Guanghui Ren. Enerverse: Envisioning embodied future space for robotics manipulation. arXiv preprint arXiv:2501.01895, 2025
-
[32]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. arXiv preprint arXiv:2406.16862, 2024
-
[33]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model. arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Auto-encoding variational bayes, 2013
Diederik P Kingma, Max Welling, et al. Auto-encoding variational bayes, 2013
work page 2013
-
[36]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems , 33:6840–6851, 2020
work page 2020
-
[37]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Lbm eval: Drake-based lbm simulation evaluation suite
Toyota Research Institute. Lbm eval: Drake-based lbm simulation evaluation suite. https: //github.com/ToyotaResearchInstitute/lbm_eval, 2025
work page 2025
-
[39]
Drake: Model-based design and verification for robotics, 2019
Russ Tedrake and the Drake Development Team. Drake: Model-based design and verification for robotics, 2019. URL https://drake.mit.edu
work page 2019
-
[40]
Shape of Motion: 4D Reconstruction from a Single Video, July 2024
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruction from a single video. arXiv preprint arXiv:2407.13764, 2024
-
[41]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018. 12
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research , page 02783649241273668, 2023
work page 2023
-
[43]
Megapose: 6d pose estimation of novel objects via render & compare
Yann Labbé, Lucas Manuelli, Arsalan Mousavian, Stephen Tyree, Stan Birchfield, Jonathan Tremblay, Justin Carpentier, Mathieu Aubry, Dieter Fox, and Josef Sivic. Megapose: 6d pose estimation of novel objects via render & compare. arXiv preprint arXiv:2212.06870, 2022
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning , pages 8748–8763. PmLR, 2021
work page 2021
-
[45]
Foundationstereo: Zero-shot stereo matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. Foundationstereo: Zero-shot stereo matching. arXiv preprint arXiv:2501.09898, 2025
-
[46]
Efficient video prediction via sparsely conditioned flow matching
Aram Davtyan, Sepehr Sameni, and Paolo Favaro. Efficient video prediction via sparsely conditioned flow matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23263–23274, 2023
work page 2023
-
[47]
Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954,
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954, 2024
-
[48]
From slow bidirectional to fast causal video generators
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast causal video generators. arXiv preprint arXiv:2412.07772, 2024
-
[49]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation without vector quantization. arXiv preprint arXiv:2412.14169, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Arlon: Boosting diffusion transformers with autoregressive models for long video generation
Zongyi Li, Shujie Hu, Shujie Liu, Long Zhou, Jeongsoo Choi, Lingwei Meng, Xun Guo, Jinyu Li, Hefei Ling, and Furu Wei. Arlon: Boosting diffusion transformers with autoregressive models for long video generation. arXiv preprint arXiv:2410.20502, 2024
-
[51]
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction. arXiv preprint arXiv:2503.19325, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems , 35: 26565–26577, 2022. 13 A Technical Appendices and Supplementary Material In Appendix A.1, we provide more details of our 4D generation model architecture. In Appendix A.2, we des...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.