Recognition: no theorem link
HOME-KGQA: A Benchmark Dataset for Multimodal Knowledge Graph Question Answering on Household Daily Activities
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
A new benchmark for household multimodal KGQA shows LLM-based methods underperform on daily activity questions compared to encyclopedic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HOME-KGQA is constructed from a multimodal knowledge graph capturing daily household activities and supplies complex natural language questions together with corresponding graph database queries. The questions require multi-hop reasoning over spatiotemporal structure and multimodal information, features absent from earlier encyclopedic KGQA collections. Evaluations of LLM-based KGQA techniques on this dataset yield performance below the levels obtained on existing benchmarks, thereby exposing limitations that affect deployment in embodied AI contexts.
What carries the argument
HOME-KGQA dataset of complex multi-hop questions over a multimodal household-activity knowledge graph, each paired with graph database query languages to test spatiotemporal and multimodal reasoning.
If this is right
- KGQA systems must incorporate stronger multi-level spatiotemporal reasoning to handle household scenarios.
- Multimodal grounding and aggregate functions become necessary capabilities for practical embodied applications.
- The dataset supplies a concrete testbed for measuring progress toward real-world KGQA reliability.
- Performance shortfalls on this benchmark point to the need for reduced hallucinations in complex query settings.
- Development efforts should prioritize generalization beyond encyclopedic knowledge sources.
Where Pith is reading between the lines
- Smart-home AI prototypes could adopt this benchmark to evaluate combined language, sensor, and knowledge-graph components.
- The construction approach could be replicated for activity domains such as healthcare routines or workplace tasks.
- Improved scores on HOME-KGQA might correlate with better performance in dynamic physical environments where knowledge changes rapidly.
- The emphasis on verifiable graph queries could encourage hybrid LLM-KG architectures that maintain explicit reasoning traces.
Load-bearing premise
The multimodal knowledge graph and the questions generated from it accurately represent real-world household activities and the reasoning demands of embodied AI.
What would settle it
A result in which unmodified LLM-based KGQA methods reach the same accuracy on HOME-KGQA as they do on standard encyclopedic benchmarks would indicate that the claimed new challenges are not present.
Figures



read the original abstract
Large Language Models (LLMs) provide flexible natural language processing capabilities, while knowledge graphs (KGs) offer explicit and structured knowledge. Integrating these two in a complementary manner enables the development of reliable and verifiable AI systems. In particular, knowledge graph question answering (KGQA) has attracted attention as a means to reduce LLM hallucinations and to leverage knowledge beyond the training data. However, existing KGQA benchmark datasets are biased toward encyclopedic knowledge, limited to a single modality, and lack fine-grained spatiotemporal data, which limits their applicability to real-world scenarios targeted by Embodied AI. We introduce HOME-KGQA, a novel KGQA benchmark dataset built on a multimodal KG of daily household activities. HOME-KGQA consists of complex, multi-hop natural language questions paired with graph database query languages. Compared to existing benchmarks, it includes more challenging questions that involve multi-level spatiotemporal reasoning, multimodal grounding, and aggregate functions. Experimental results show that the LLM-based KGQA methods fail to achieve performance comparable to that on existing datasets when evaluated on HOME-KGQA. This highlights significant challenges that should be addressed for the real-world deployment of KGQA systems. Our dataset is available at https://github.com/aistairc/home-kgqa
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HOME-KGQA, a benchmark dataset for multimodal KGQA on household daily activities. It constructs a multimodal knowledge graph from activity logs and generates complex multi-hop natural language questions (paired with graph query languages) that require multi-level spatiotemporal reasoning, multimodal grounding, and aggregate functions. Experiments show that LLM-based KGQA methods achieve lower performance on HOME-KGQA than on existing benchmarks, highlighting challenges for real-world embodied AI deployment. The dataset is released publicly.
Significance. If the dataset's fidelity to real household activities is established, the work would provide a valuable, more realistic benchmark that addresses gaps in current KGQA datasets (encyclopedic focus, single modality, lack of fine-grained spatiotemporal data). The public release supports further research on reliable LLM-KG integration for embodied settings.
major comments (1)
- [Section 3] Section 3: The KG construction from activity logs and question generation (via templates/LLMs) reports no human validation of triple accuracy, no inter-annotator agreement on whether questions demand the claimed multi-hop spatiotemporal/multimodal reasoning, and no comparison of generated questions against real sensor traces or expert household scenarios. This is load-bearing for the central claim, as the observed performance gap and the interpretation of 'significant challenges' for embodied deployment require that the questions genuinely reflect those demands rather than synthetic artifacts or surface patterns.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript introducing HOME-KGQA. We address the major comment point by point below and outline planned revisions.
read point-by-point responses
-
Referee: [Section 3] Section 3: The KG construction from activity logs and question generation (via templates/LLMs) reports no human validation of triple accuracy, no inter-annotator agreement on whether questions demand the claimed multi-hop spatiotemporal/multimodal reasoning, and no comparison of generated questions against real sensor traces or expert household scenarios. This is load-bearing for the central claim, as the observed performance gap and the interpretation of 'significant challenges' for embodied deployment require that the questions genuinely reflect those demands rather than synthetic artifacts or surface patterns.
Authors: We acknowledge that the current version of the manuscript does not report human validation of triple accuracy, inter-annotator agreement on reasoning demands, or explicit comparisons of generated questions to independent expert household scenarios. The KG is built by automated rule-based extraction from structured activity logs collected in real household settings, and questions are produced via templates engineered to enforce multi-hop spatiotemporal, multimodal, and aggregate reasoning. We will revise Section 3 to include: (1) a description of automated consistency checks performed on the extracted triples against the source logs, (2) a small-scale human evaluation (with reported agreement) on a random sample of triples and questions to verify reasoning requirements, and (3) additional details clarifying how the underlying activity logs derive from real sensor traces and daily routines. These additions will directly support the interpretation of the performance results. We view this as a partial revision because a full-scale expert annotation of the entire dataset is beyond the scope of the current work but can be noted as a limitation. revision: partial
Circularity Check
No circularity: dataset construction and empirical benchmarking are self-contained
full rationale
The paper presents a new benchmark dataset built from household activity logs into a multimodal KG, with questions generated via templates and LLMs, followed by direct experimental comparison of LLM-based KGQA methods against prior benchmarks. No equations, parameter fitting, predictions, or derivations exist that could reduce to inputs by construction. The central claim (underperformance on HOME-KGQA) is an empirical observation, not a self-referential result. Self-citations, if any, are not load-bearing for any uniqueness theorem or ansatz. The work contains no self-definitional loops, fitted-input predictions, or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Who are the parents of Barack Obama?
Introduction Large language models (LLMs) and knowledge graphs (KGs) are mutually complementary. By integrating the flexible natural language process- ing capabilities of LLMs with the structured and explicit knowledge provided by KGs, it is possi- ble to build AI systems that are more reliable and verifiable. Knowledge Graph Question Answer- ing (KGQA) ( S...
work page 2021
-
[2]
are required to capture fine-grained knowl- arXiv:2605.09348v1 [cs.CL] 10 May 2026 edge, including 3D spatial knowledge, 2D visual knowledge, and temporal knowledge of human ac- tivities. In this paper, we go beyond conventional KGQA systems that target textual encyclopedic facts and propose a novel benchmark dataset, HOME- KGQA, to facilitate the developm...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Steinmetz and Sattler (2021) analyzed existing KGQA datasets such as LC-QuAD 1.0 ( Trivedi et al
Related Work Many KGQA benchmark datasets have been re- leased to date, and these datasets have been ana- 1https://github.com/aistairc/home-kgqa lyzed from various perspectives. Steinmetz and Sattler (2021) analyzed existing KGQA datasets such as LC-QuAD 1.0 ( Trivedi et al. , 2017), QALD ( Usbeck et al. , 2017), and SimpleDBpe- diaQA ( Azmy et al. , 2018...
work page 2021
-
[4]
The task is to translate q into s = fθ(q), where fθ denotes a KGQA model
Task Definition The input is a natural language question q ∈ Q, and the output is a corresponding SPARQL query s ∈ S. The task is to translate q into s = fθ(q), where fθ denotes a KGQA model. The following shows an example (q, s) pair. The natural language question q: How many times did the agent put a water glass in the kitchen between 7:56 p.m. on April ...
work page 2024
-
[5]
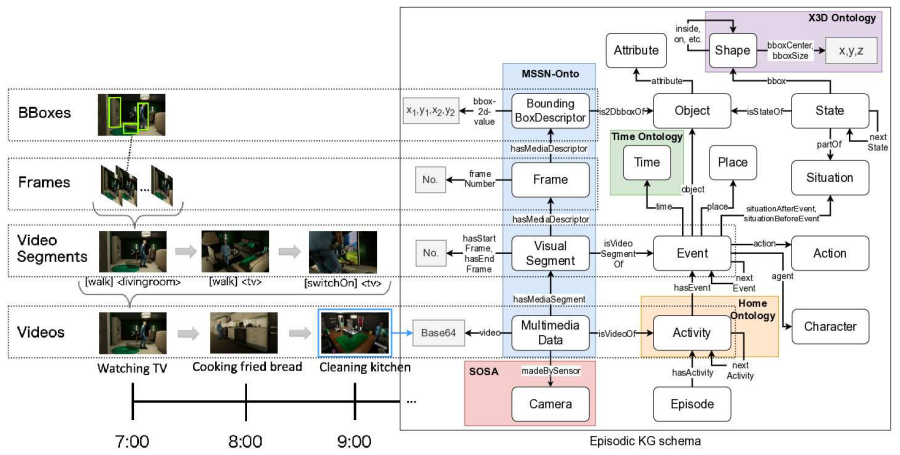
HOME-KGQA Construction In this section, we describe the dataset construc- tion process for HOME-KGQA. We first explain how the target MMKG is constructed, then de- tail the question generation process, and finally present an analysis of the constructed dataset. 4.1. Episodic KG Construction We create an episodic KG of daily life using VHAKG ( Egami et al. ,...
work page 2024
-
[6]
Activity concepts are extended from HomeOntology ( Vas- siliades et al. , 2020), which defines activity cate- gories (e.g., HouseCleaning) and their subclasses (e.g., Cleaning_kitchen). To represent 3D bound- ing boxes and spatial coordinates, the X3D Ontol- ogy ( Brutzman and Flotyński , 2020) is reused. In environments where heterogeneous data in- tegrat...
work page 2020
-
[7]
Correct grammatical errors
-
[8]
Paraphrase time expressions in a more natural way
-
[9]
Paraphrase attribute expressions in a more natural way
-
[10]
Paraphrase state expressions in a more natural way
-
[11]
Paraphrase object names in a more natural way
-
[12]
Paraphrase type expressions in a more natural way
-
[13]
Paraphrase class expressions in a more natural way. Question Category Question Type Question Text Example Object None What is the object . . . Type What is the type of the object . . . Superclass What is the superclass of the object . . . State What is the state of the object . . . Attribute What is the attribute of the object . . . Size What are the widt...
work page 2024
-
[14]
Paraphrase activity expressions in a more natural way
-
[15]
Paraphrase expressions describing what is shown in the video frame in a more natural way
-
[16]
If the question is not about something that happened in the past, use the past tense in the question
-
[17]
Don’t change the original meaning. Next, we manually create a gold dataset of paraphrased question sentences for each ques- tion type defined in Table
-
[18]
The lower row shows values when RDFS-Plus ( Allemang and Hendler, 2011) reasoning is enabled
As a result, 22 pairs of raw and paraphrased question examples are pre- Class Relation Instance Triple 882 (882) 76 (86) 13,191,977 (13,192,053) 154,860,255 (162,609,309) Table 3: Statistics of our episode KG. The lower row shows values when RDFS-Plus ( Allemang and Hendler, 2011) reasoning is enabled. pared. Finally, for a given question, we retrieve the...
work page 2011
-
[19]
Figure 3: Distribution of query hops Figure 4: Question length distribution 5.1
Experiments The purpose of this experiment is to demonstrate the difficulty of HOME-KGQA compared to exist- ing KGQA datasets and to clarify the challenges of KGQA in real-world daily life applications. Figure 3: Distribution of query hops Figure 4: Question length distribution 5.1. Experimental Settings 5.1.1. Benchmark settings Experiments are conducted u...
work page 2022
-
[20]
Conclusion In this paper, we introduced HOME-KGQA, a benchmark dataset for evaluating KGQA models in home environments. By integrating multiple on- tologies into a multimodal episodic KG and gen- erating complex question–SPARQL pairs, HOME- KGQA provides a challenging benchmark for real- world reasoning beyond textual encyclopedic facts. Through comparati...
-
[21]
Ethical Considerations The dataset used in this study, HOME-KGQA, is constructed entirely from synthetic data gener- ated by the VirtualHome simulator ( Puig et al. ,
-
[22]
and contains no personal, biometric, or privacy-related information. We used crowdsourc- ing solely to collect abstract representations of ac- tivity sequences describing typical daily routines. All collected data are non-personal, non-sensitive, and do not include any demographic data
-
[23]
Limitations The dataset is constructed from synthetic simula- tions of single-person households and therefore does not capture the full diversity of real-world daily activities, such as multi-person interactions. From a language resource perspective, the gen- erated questions may reflect the stylistic and lex- ical tendencies of the underlying LLMs and may...
-
[24]
R&D on Generative AI Foundation Models for the Physical Domain
Acknowledgements This paper is based on results obtained from JSPS KAKENHI Grant Numbers JP23H03688 and JP25K03232, and AIST policy-based budget project “R&D on Generative AI Foundation Models for the Physical Domain.”
-
[25]
Bibliographical References Dean Allemang and James Hendler. 2011. Se- mantic web for the working ontologist: effective modeling in RDFS and OWL . Elsevier. Chinnapong Angsuchotmetee, Richard Chbeir, and Yudith Cardinale. 2020. MSSN-Onto: An ontology-based approach for flexible event pro- cessing in Multimedia Sensor Networks . Fu- ture Generation Computer S...
work page 2011
-
[26]
Farewell Freebase: Migrating the Simple- Questions Dataset to DBpedia . In Proceedings of the 27th International Conference on Com- putational Linguistics, pages 2093–2103, Santa Fe, New Mexico, USA. Association for Compu- tational Linguistics. Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023. Knowledge-Augmented Language Model Prompting for Zero-Shot...
work page 2093
-
[27]
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor
ArXiv:2204.12793 [cs]. Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a col- laboratively created graph database for structur- ing human knowledge . In Proceedings of the 2008 ACM SIGMOD international conference on Management of data , SIGMOD ’08, pages 1247–1250, New York, NY , USA. Association for Computing ...
-
[28]
Language Resource References Shulin Cao and Jiaxin Shi and Liangming Pan and Lunyiu Nie and Yutong Xiang and Lei Hou and Juanzi Li and Bin He and Hanwang Zhang. 2022. KQA Pro. 1.0. Alon Talmor and Jonathan Berant. 2018. Com- plexWebQuestions. Wen-tau Yih and Matthew Richardson and Christo- pher Meek and Ming-Wei Chang and Jina Suh. 2016. WebQuestions Sema...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.