The Landscape of GPU-Centric Communication
Pith reviewed 2026-05-23 20:37 UTC · model grok-4.3
The pith
A categorized survey of GPU-centric communication techniques shows how to reduce CPU involvement and improve scalability in multi-GPU systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
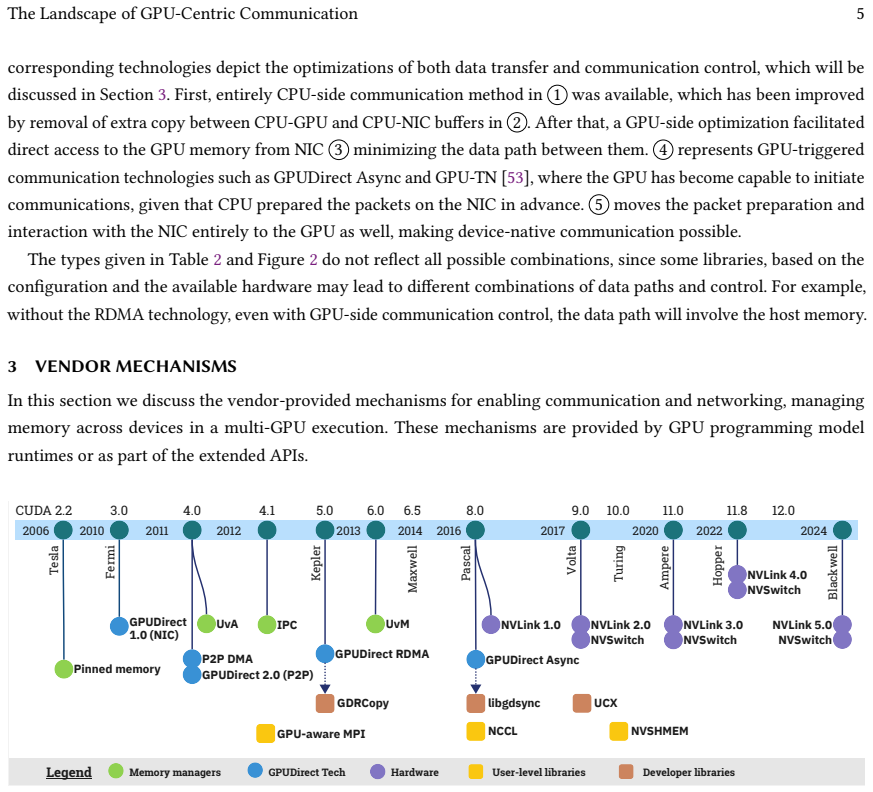
The paper establishes that recent vendor mechanisms and libraries enable GPUs to manage inter-GPU communication with reduced CPU participation, granting greater autonomy to the accelerators; by mapping these techniques across the hardware and software stacks and categorizing them, the survey clarifies the available choices and supplies insights for researchers, programmers, engineers, and library designers on exploiting multi-GPU systems effectively.
What carries the argument
The categorization of vendor-provided mechanisms and user-level libraries for GPU-centric communication within and across nodes
If this is right
- Programmers gain guidance on selecting libraries that align communication patterns with computation needs.
- Library designers receive identified challenges that can direct future improvements.
- Researchers obtain a list of open questions for advancing GPU autonomy in communication.
- Engineers can apply the within-node and across-node categories to tune large-scale deployments.
Where Pith is reading between the lines
- The same categorization could be extended to evaluate communication costs in emerging GPU clusters used for large language model training.
- Future hardware that embeds more communication logic directly on the GPU die would fit naturally into the within-node category described.
- Comparing the surveyed approaches against specific workload communication graphs could reveal which library choices minimize energy use.
Load-bearing premise
The selected vendor mechanisms, libraries, and research paradigms are representative of the current landscape and the proposed categorization clarifies complexities for users without major omissions.
What would settle it
A check that identifies several widely deployed multi-GPU communication methods or libraries absent from the described categories, or practical tests showing that following the survey's guidance yields no measurable reduction in communication bottlenecks.
Figures


read the original abstract
In recent years, GPUs have become the preferred accelerators for HPC and ML applications due to their parallelism and fast memory bandwidth. While GPUs boost computation, inter-GPU communication can create scalability bottlenecks, especially as the number of GPUs per node and cluster grows. Traditionally, the CPU managed multi-GPU communication, but advancements in GPU-centric communication now challenge this CPU dominance by reducing its involvement, granting GPUs more autonomy in communication tasks, and addressing mismatches in multi-GPU communication and computation. This paper provides a landscape of GPU-centric communication, focusing on vendor mechanisms and user-level library supports. It aims to clarify the complexities and diverse options in this field, define the terminology, and categorize existing approaches within and across nodes. The paper discusses vendor-provided mechanisms for communication and memory management in multi-GPU execution and reviews major communication libraries, their benefits, challenges, and performance insights. Then, it explores key research paradigms, future outlooks, and open research questions. By extensively describing GPU-centric communication techniques across the software and hardware stacks, we provide researchers, programmers, engineers, and library designers insights on how to exploit multi-GPU systems at their best.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey of GPU-centric communication in multi-GPU HPC and ML systems. It describes the shift from CPU-managed to GPU-autonomous communication, catalogs vendor mechanisms for inter-GPU communication and memory management, reviews major libraries with their benefits/challenges/performance, categorizes approaches within and across nodes, and discusses research paradigms, future outlooks, and open questions, with the goal of supplying actionable insights to researchers, programmers, and library designers.
Significance. If the coverage of mechanisms, libraries, and paradigms is representative and the categorization is coherent, the survey can reduce the complexity of navigating GPU communication stacks and help practitioners select appropriate techniques. The work is purely descriptive with no new derivations, experiments, or predictions, so its value rests on synthesis and clarity rather than novel claims.
minor comments (2)
- [Abstract] Abstract: the claim that the paper 'clarifies the complexities' would be strengthened by an explicit statement of the literature search methodology or inclusion criteria used to select the reviewed vendor mechanisms and libraries.
- The manuscript would benefit from a dedicated section or table that cross-references the reviewed libraries against the vendor mechanisms they build upon, to make the categorization more immediately usable.
Simulated Author's Rebuttal
We thank the referee for their summary and positive evaluation of our survey manuscript. The recommendation for minor revision is noted; however, no specific major comments were provided in the report. We are prepared to incorporate any editorial or minor clarifications as needed in the revised version.
Circularity Check
No significant circularity
full rationale
This is a purely descriptive survey paper that reviews vendor mechanisms, libraries, and research paradigms for GPU-centric communication without any derivations, equations, predictions, fitted parameters, or theoretical claims that could reduce to self-definition or self-citation. The central contribution is cataloging external literature to provide insights, which is self-contained against external benchmarks and contains no load-bearing steps that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Analyzing Reverse Address Translation Overheads in Multi-GPU Scale-Up Pods
Simulation study shows cold TLB misses in reverse address translation dominate latency for small collectives in multi-GPU pods, causing up to 1.4x degradation, while larger ones see diminishing returns.
-
ChunkFlow: Communication-Aware Chunked Prefetching for Layerwise Offloading in Distributed Diffusion Transformer Inference
ChunkFlow achieves up to 1.28x step-time speedup and up to 49% lower peak GPU memory for DiT inference by using a first-order model to guide communication-aware chunked prefetching.
-
Eliminating Hidden Serialization in Multi-Node Megakernel Communication
Perseus removes serialization bottlenecks in multi-node megakernel MoE communication via batched per-destination fences and hardware fence flags, delivering up to 10.3x speedup on proxy transports and matching or exce...
Reference graph
Works this paper leans on
-
[1]
Elena Agostini, Davide Rossetti, and Sreeram Potluri. 2017. Offloading Communication Control Logic in GPU Accelerated Applications. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (Madrid, Spain) (CCGrid ’17). Institute for Electrical and Electronics Engineers, New York, NY, USA, 248–257. https://doi.org/10...
-
[2]
E. Agostini, D. Rossetti, and S. Potluri. 2018. GPUDirect Async: Exploring GPU synchronous communication techniques for InfiniBand clusters. J. Parallel and Distrib. Comput. 114 (2018), 28–45. https://doi.org/10.1016/j.jpdc.2017.12.007
-
[3]
Palwisha Akhtar, Erhan Tezcan, Fareed Mohammad Qararyah, and Didem Unat. 2021. ComScribe: Identifying Intra-node GPU Communication. In Benchmarking, Measuring, and Optimizing , Felix Wolf and Wanling Gao (Eds.). Springer International Publishing, Cham, 157–174
work page 2021
-
[4]
AMD. [n. d.]. AMD Instinct MI200 Instruction Set Architecture. https://www.amd.com/system/files/TechDocs/instinct-mi200-cdna2-instruction- set-architecture.pdf
-
[5]
AMD. 2021. AMD CDNA ™ 2 ARCHITECTURE. https://www.amd.com/system/files/documents/amd-cdna2-white-paper.pdf
work page 2021
-
[6]
AMD. 2023. GPU-aware MPI with ROCm. https://gpuopen.com/learn/amd-lab-notes/amd-lab-notes-gpu-aware-mpi-readme/#
work page 2023
-
[7]
AMD. 2023. ROCK-Kernel-Driver. https://github.com/RadeonOpenCompute/ROCK-Kernel-Driver
work page 2023
-
[8]
AMD. 2023. ROCm Documentation: GPU-Enabled MPI. https://rocm.docs.amd.com/en/latest/how_to/gpu_aware_mpi.html
work page 2023
-
[9]
AMD. 2023. ROCnRDMA. https://github.com/rocmarchive/ROCnRDMA
work page 2023
-
[10]
AMD. 2023. ROC_SHMEM. https://github.com/ROCm-Developer-Tools/ROC_SHMEM
work page 2023
-
[11]
A. A. Awan, K. Hamidouche, A. Venkatesh, and D. K. Panda. 2016. Efficient Large Message Broadcast Using NCCL and CUDA-Aware MPI for Deep Learning. In Proceedings of the 23rd European MPI Users’ Group Meeting (Edinburgh, United Kingdom) (EuroMPI 2016). Association for Computing Machinery, New York, NY, USA, 15–22. https://doi.org/10.1145/2966884.2966912
-
[12]
Ammar Ahmad Awan, Karthik Vadambacheri Manian, Ching-Hsiang Chu, Hari Subramoni, and Dhabaleswar K. Panda. 2019. Optimized large- message broadcast for deep learning workloads: MPI, MPI+NCCL, or NCCL2? Parallel Comput. 85 (2019), 141–152. https://doi.org/10.1016/j.parco. 2019.03.005
-
[13]
Dip Sankar Banerjee, Khaled Hamidouche, and Dhabaleswar K. Panda. 2016. Designing High Performance Communication Runtime for GPU Managed Memory: Early Experiences (GPGPU ’16). Association for Computing Machinery, New York, NY, USA, 82–91. https://doi.org/10.1145/ 2884045.2884050
-
[14]
Tal Ben-Nun, Michael Sutton, Sreepathi Pai, and Keshav Pingali. 2020. Groute: Asynchronous Multi-GPU Programming Model with Applications to Large-Scale Graph Processing. ACM Trans. Parallel Comput. 7, 3, Article 18 (jun 2020), 27 pages. https://doi.org/10.1145/3399730
-
[15]
Massimo Bernaschi, Elena Agostini, and Davide Rossetti. 2021. Benchmarking multi-GPU applications on modern multi-GPU in- tegrated systems. Concurrency and Computation: Practice and Experience 33, 14 (2021), e5470. https://doi.org/10.1002/cpe.5470 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.5470
-
[16]
Stephen Brosky. 2023. Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO. https://developer.nvidia.com/blog/inline-gpu-packet- processing-with-nvidia-doca-gpunetio/
work page 2023
-
[17]
Stephen Brosky. 2023. Optimizing Inline Packet Processing Using DPDK and GPUDirect with GPUs. https://developer.nvidia.com/blog/optimizing- inline-packet-processing-using-dpdk-and-gpudev-with-gpus/
work page 2023
-
[18]
Idan Burstein. 2021. Nvidia Data Center Processing Unit (DPU) Architecture. In 2021 IEEE Hot Chips 33 Symposium (HCS) . 1–20. https: //doi.org/10.1109/HCS52781.2021.9567066
-
[19]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madanlal Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing Optimal Collective Algorithms. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (Virtual Event, Republic of Korea) (PPoPP ’21). Association for Computing Machinery, New York, N...
-
[20]
Chen-Chun Chen, Kawthar Shafie Khorassani, Quentin G. Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K. Panda. 2022. Highly Efficient Alltoall and Alltoallv Communication Algorithms for GPU Systems. In 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). 24–33. https://doi.org/10.1109/IPDPSW55747.2022.00014
-
[21]
Yuxin Chen, Benjamin Brock, Serban Porumbescu, Aydın Buluç, Katherine Yelick, and John D. Owens. 2022. Scalable Irregular Parallelism with GPUs: Getting CPUs out of the Way. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (Dallas, Texas) (SC ’22). Institute for Electrical and Electronics Engin...
work page 2022
-
[22]
Jaemin Choi, Zane Fink, Sam White, Nitin Bhat, David F. Richards, and Laxmikant V. Kale. 2021. GPU-aware Communication with UCX in Parallel Programming Models: Charm++, MPI, and Python. In 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW) . 479–488. https://doi.org/10.1109/IPDPSW52791.2021.00079
-
[23]
Jaemin Choi, Zane Fink, Sam White, Nitin Bhat, David F. Richards, and Laxmikant V. Kale. 2022. Accelerating communication for parallel programming models on GPU systems. Parallel Comput. 113 (2022), 102969. https://doi.org/10.1016/j.parco.2022.102969 Manuscript submitted to ACM The Landscape of GPU-Centric Communication 21
-
[24]
Jaemin Choi, David F. Richards, and Laxmikant V. Kale. 2021. CharminG: A Scalable GPU-Resident Runtime System. In Proceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing (Virtual Event, Sweden) (HPDC ’21). Association for Computing Machinery, New York, NY, USA, 261–262. https://doi.org/10.1145/3431379.3464454
-
[25]
Ching-Hsiang Chu, Sreeram Potluri, Anshuman Goswami, Manjunath Gorentla Venkata, Neena Imam, and Chris J. Newburn. 2019. Designing High-Performance In-Memory Key-Value Operations with Persistent GPU Kernels and OpenSHMEM. In OpenSHMEM and Related Technologies. OpenSHMEM in the Era of Extreme Heterogeneity , Swaroop Pophale, Neena Imam, Ferrol Aderholdt, a...
work page 2019
-
[26]
Jan Ciesko. 2023. Kokkos Remote Spaces Repository. https://github.com/kokkos/kokkos-remote-spaces
work page 2023
-
[27]
NVIDIA Corporation. 2023. NVIDIA DOCA SDK Documentation. https://docs.nvidia.com/doca/sdk/index.html
work page 2023
-
[28]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft Collective Communication Language. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (Vancouver, BC, Canada) (ASPLOS 2023). Association for Computing Machinery, ...
-
[29]
CSC. 2024. LUMI-G Supercomputer. https://docs.lumi-supercomputer.eu/hardware/lumig/
work page 2024
-
[30]
Feras Daoud, Amir Watad, and Mark Silberstein. 2016. GPUrdma: GPU-Side Library for High Performance Networking from GPU Kernels (ROSS ’16). Association for Computing Machinery, New York, NY, USA, Article 6, 8 pages. https://doi.org/10.1145/2931088.2931091
-
[31]
Seth Howell Davide Rossetti, Pak Markthub. 2021. The Latest in GPUDirect. https://www.nvidia.com/en-us/on-demand/session/gtcspring21- s32039/
work page 2021
-
[32]
Nikoli Dryden, Naoya Maruyama, Tim Moon, Tom Benson, Andy Yoo, Marc Snir, and Brian Van Essen. 2018. Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems. In 2018 IEEE/ACM Machine Learning in HPC Environments (MLHPC) . 1–13. https://doi.org/10.1109/MLHPC.2018.8638639
-
[33]
Jonathon Evans, Michael Andersch, Vikram Sethi, Gonzalo Brito, and Vishal Mehta. 2022. NVIDIA Grace Hopper Superchip Architecture In-Depth. https://developer.nvidia.com/blog/nvidia-grace-hopper-superchip-architecture-in-depth/
work page 2022
-
[34]
Denis Foley and John Danskin. 2017. Ultra-Performance Pascal GPU and NVLink Interconnect. IEEE Micro 37, 2 (2017), 7–17. https://doi.org/10. 1109/MM.2017.37
work page 2017
-
[35]
Ibrahim, Lenny Oliker, Nicholas J
Taylor Groves, Ben Brock, Yuxin Chen, Khaled Z. Ibrahim, Lenny Oliker, Nicholas J. Wright, Samuel Williams, and Katherine Yelick. 2020. Performance Trade-offs in GPU Communication: A Study of Host and Device-initiated Approaches. In 2020 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS) . 126–137. https...
-
[36]
Tobias Gysi, Jeremia Bär, and Torsten Hoefler. 2016. dCUDA: Hardware Supported Overlap of Computation and Communication. In SC ’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis . 609–620. https://doi.org/10.1109/SC. 2016.51
work page doi:10.1109/sc 2016
-
[37]
Khaled Hamidouche, Ammar Ahmad Awan, Akshay Venkatesh, and Dhabaleswar K. Panda. 2016. CUDA M3: Designing Efficient CUDA Managed Memory-Aware MPI by Exploiting GDR and IPC. In 2016 IEEE 23rd International Conference on High Performance Computing (HiPC) . 52–61. https://doi.org/10.1109/HiPC.2016.016
-
[38]
Khaled Hamidouche and Michael LeBeane. 2020. GPU INitiated OPenSHMEM: Correct and Efficient Intra-Kernel Networking for DGPUs. In Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (San Diego, California) (PPoPP ’20). Association for Computing Machinery, New York, NY, USA, 336–347. https://doi.org/10.1145/3332...
-
[39]
Mark Harris. 2012. How to Optimize Data Transfers in CUDA C/C++. https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
work page 2012
-
[40]
HPE. 2021. Cray MPICH Documentation. https://cpe.ext.hpe.com/docs/mpt/mpich/intro_mpi.html
work page 2021
-
[41]
Alexaner Ishii and Ryan Wells. 2023. The NVLink-Network Switch: NVIDIA’s Switch Chip for High Communication-Bandwidth Superpods. https://hc34.hotchips.org/assets/program/conference/day2/Network%20and%20Switches/NVSwitch%20HotChips%202022%20r5.pdf
work page 2023
-
[42]
Ismayil Ismayilov, Javid Baydamirli, Doğan Sağbili, Mohamed Wahib, and Didem Unat. 2023. Multi-GPU Communication Schemes for Iterative Solvers: When CPUs Are Not in Charge. In Proceedings of the 37th International Conference on Supercomputing (Orlando, FL, USA) (ICS ’23). Association for Computing Machinery, New York, NY, USA, 192–202. https://doi.org/10....
-
[43]
Mohammad Kefah Taha Issa, Muhammad Aditya Sasongko, Ilyas Turimbetov, Javid Baydamirli, Doğan Sağbili, and Didem Unat. 2024. Snoopie: A Multi-GPU Communication Profiler and Visualizer. In Proceedings of the 38th ACM International Conference on Supercomputing (Kyoto, Japan) (ICS ’24). Association for Computing Machinery, New York, NY, USA, 525–536. https:/...
- [44]
-
[45]
Sylvain Jeaugey. 2017. NCCL 2.0. https://on-demand.gputechconf.com/gtc/2017/presentation/s7155-jeaugey-nccl.pdf
work page 2017
-
[46]
Sylvain Jeaugey. 2019. Distributed Neural Network Training: NCCL On Summit. https://www.olcf.ornl.gov/wp-content/uploads/2019/12/Summit- NCCL.pdf
work page 2019
-
[47]
Benjamin Klenk, Lena Oden, and Holger Froening. 2014. Analyzing Put/Get APIs for Thread-Collaborative Processors. In 2014 43rd International Conference on Parallel Processing Workshops. 411–418. https://doi.org/10.1109/ICPPW.2014.61
-
[48]
Benjamin Klenk, Lena Oden, and Holger Fröning. 2014. GPU-centric communication for improved efficiency. In International Workshop on Green Programming, Computing and Data Processing (GPCDP) in conjunction with International Green Computing Conference (IGCC), Dallas, TX, USA . Manuscript submitted to ACM 22 D. Unat et al
work page 2014
-
[49]
Benjamin Klenk, Lena Oden, and Holger Froning. 2015. Analyzing communication models for distributed thread-collaborative processors in terms of energy and time. In 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) . 318–327. https: //doi.org/10.1109/ISPASS.2015.7095817
-
[50]
Jiri Kraus. 2021. Multi-GPU Programming Models. https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31050/
work page 2021
-
[51]
Akhil Langer and Jim Dinan. 2021. NVSHMEM: GPU-Integrated Communication for NVIDIA GPU Clusters. https://www.nvidia.com/en-us/on- demand/session/gtcspring21-s32515/
work page 2021
-
[52]
lattice. 2023. QUDA Repository. https://github.com/lattice/quda
work page 2023
-
[53]
Michael LeBeane, Khaled Hamidouche, Brad Benton, Mauricio Breternitz, Steven K. Reinhardt, and Lizy K. John. 2017. GPU Triggered Networking for Intra-Kernel Communications (SC ’17). Association for Computing Machinery, New York, NY, USA, Article 22, 12 pages. https://doi.org/10. 1145/3126908.3126950
-
[54]
Michael LeBeane, Khaled Hamidouche, Brad Benton, Mauricio Breternitz, Steven K. Reinhardt, and Lizy K. John. 2018. ComP-Net: Command Processor Networking for Efficient Intra-Kernel Communications on GPUs. InProceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques (Limassol, Cyprus) (PACT ’18). Association for C...
-
[55]
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, and Kevin J. Barker. 2020. Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect. IEEE Trans. Parallel Distrib. Syst. 31, 1 (jan 2020), 94–110. https://doi.org/10.1109/TPDS.2019.2928289
-
[56]
K. V. Manian, A. A. Ammar, A. Ruhela, C.-H. Chu, H. Subramoni, and D. K. Panda. 2019. Characterizing CUDA Unified Memory (UM)-Aware MPI Designs on Modern GPU Architectures. In Proceedings of the 12th Workshop on General Purpose Processing Using GPUs (Providence, RI, USA) (GPGPU ’19). Association for Computing Machinery, New York, NY, USA, 43–52. https://d...
-
[57]
Naoya Maruyama, Brian Van Essen, Jan Ciesko, Jeremiah Wilke, Christian Trott, Chung-Hsing Hsu, Neena Imam, Jim Dinan, Akhil Langer, CJ Newburn, and Sreeram Potluri. 2020. Scaling Scientific Computing with NVSHMEM. https://developer.nvidia.com/blog/scaling-scientific- computing-with-nvshmem/
work page 2020
-
[58]
Hans Meuer, Erich Strohmaier, Jack Dongarra, Horst Simon, and Martin Meuer. 2023. Top 500. https://www.top500.org/. Accessed: 2023-07-29
work page 2023
-
[59]
Takefumi Miyoshi, Hidetsugu Irie, Keigo Shima, Hiroki Honda, Masaaki Kondo, and Tsutomu Yoshinaga. 2012. FLAT: A GPU Programming Framework to Provide Embedded MPI. In Proceedings of the 5th Annual Workshop on General Purpose Processing with Graphics Processing Units (London, United Kingdom) (GPGPU-5). Association for Computing Machinery, New York, NY, USA...
-
[60]
Timothy Prickett Morgan. 2024. Key Hyperscalers And Chip Makers Gang Up On Nvidia’s NVSwitch Interconnect. https://www.hpcwire.com/ 2024/05/30/everyone-except-nvidia-forms-ultra-accelerator-link-ualink-consortium/
work page 2024
-
[61]
IBM Spectrum MPI. 2021. IBM Spectrum MPI Version 10.2 Release Notes. https://www.ibm.com/docs/en/smpi/10.2?topic=release-notes
work page 2021
-
[62]
Cosa: Scheduling by constrained optimization for spatial accelerators,
Harini Muthukrishnan, David Nellans, Daniel Lustig, Jeffrey A. Fessler, and Thomas F. Wenisch. 2021. Efficient Multi-GPU Shared Memory via Automatic Optimization of Fine-Grained Transfers. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) . 139–152. https://doi.org/10.1109/ISCA52012.2021.00020
- [63]
- [64]
-
[65]
NVIDIA. [n. d.]. https://docs.nvidia.com/compute-sanitizer/ComputeSanitizer/index.html#racecheck-tool
-
[66]
NVIDIA. 2011. CUDA 4.0 Release Notes. https://developer.nvidia.com/cuda-toolkit-40
work page 2011
-
[67]
NVIDIA. 2012. NVIDIA GPUDirect ™ Technology. https://developer.download.nvidia.com/devzone/devcenter/cuda/docs/GPUDirect_Technology_ Overview.pdf
work page 2012
-
[68]
NVIDIA. 2016. Fast Multi-GPU collectives with NCCL. https://developer.nvidia.com/blog/fast-multi-gpu-collectives-nccl/
work page 2016
-
[69]
NVIDIA. 2017. CUDA 4.1 Release Notes. https://developer.nvidia.com/cuda-toolkit-41-archive
work page 2017
-
[70]
NVIDIA. 2017. NVIDIA DGX-1 With Tesla V100 System Architecture. https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture- whitepaper.pdf
work page 2017
-
[71]
NVIDIA. 2021. Improving GPU Memory Oversubscription Performance. https://developer.nvidia.com/blog/improving-gpu-memory- oversubscription-performance/
work page 2021
-
[72]
NVIDIA. 2023. CUDA Programming Guide Release 12.2. https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
work page 2023
-
[73]
NVIDIA. 2023. CUDA Runtime - Device Management. https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__DEVICE.html#group_ _CUDART__DEVICE
work page 2023
-
[74]
NVIDIA. 2023. DGX-2. https://www.nvidia.com/en-gb/data-center/dgx-2/
work page 2023
-
[75]
NVIDIA. 2023. GPUDirect RDMA. https://docs.nvidia.com/cuda/gpudirect-rdma/
work page 2023
-
[76]
NVIDIA. 2023. Magnum IO GDRCopy. https://developer.nvidia.com/gdrcopy
work page 2023
-
[77]
NVIDIA. 2023. NCCL. https://developer.nvidia.com/nccl
work page 2023
-
[78]
NVIDIA. 2023. NVIDIA GPUDirect Family. https://developer.nvidia.com/gpudirect
work page 2023
-
[79]
NVIDIA. 2023. NVLink and NVSwitch. https://www.nvidia.com/en-us/data-center/nvlink/
work page 2023
-
[80]
NVIDIA. 2023. NVSHMEM. https://developer.nvidia.com/nvshmem. Manuscript submitted to ACM The Landscape of GPU-Centric Communication 23
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.