From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification
Pith reviewed 2026-05-22 17:53 UTC · model grok-4.3
The pith
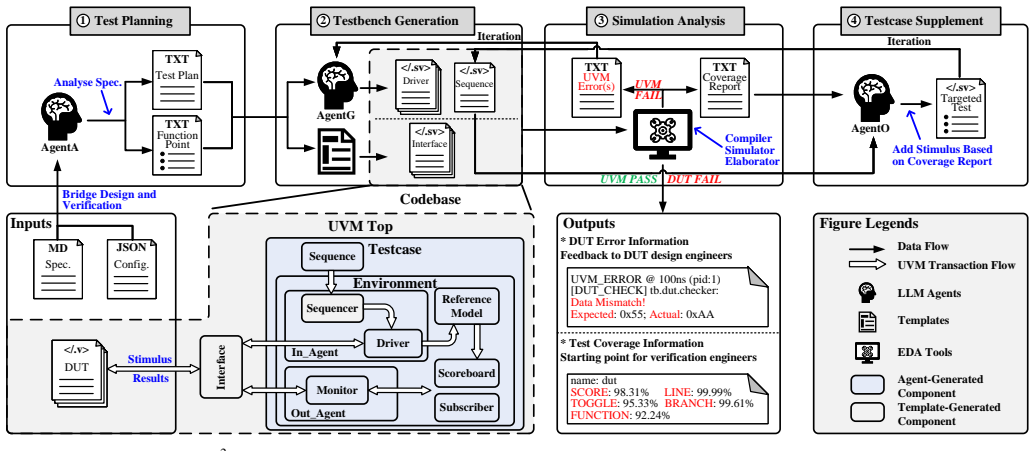
UVM^2 uses LLMs to generate and iteratively refine UVM testbenches from RTL designs using coverage feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UVM^2 leverages LLMs to generate UVM testbenches for RTL designs and iteratively refines them using coverage feedback, reducing testbench setup time by up to UVM^2 compared to experienced engineers while achieving average code coverage of 87.44 percent and function coverage of 89.58 percent, outperforming state-of-the-art solutions by 20.96 percent and 23.51 percent respectively.
What carries the argument
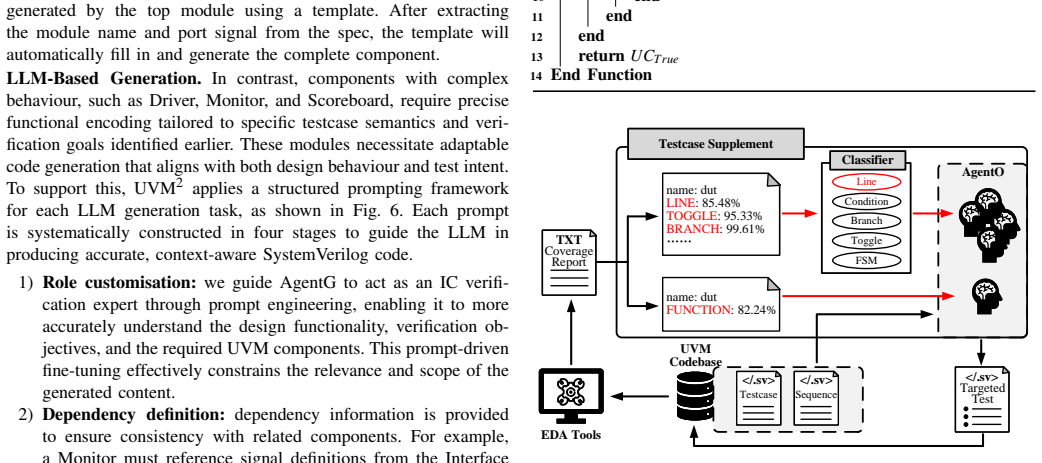
The iterative refinement loop that feeds coverage metrics back to the LLM so it can produce progressively better and still-valid UVM testbench code and stimuli.
If this is right
- Verification engineers spend far less time on manual coding and repeated EDA tool runs.
- Average code and functional coverage exceed what prior automated methods reach.
- The same coverage-driven loop can be applied to other RTL designs of similar scale.
- Structured UVM testbenches remain reusable even when generated automatically.
Where Pith is reading between the lines
- The method could later incorporate bug-detection signals or formal properties as additional feedback.
- Scaling to designs much larger than 1.6K lines would require testing how well the loop maintains validity.
- Integration with existing EDA flows might allow fully hands-off verification pipelines.
Load-bearing premise
Coverage metrics alone give the LLM enough clear signal to improve the testbench without drifting into invalid code or requiring human fixes.
What would settle it
Run the loop on a fresh RTL design and check whether coverage stops rising or the generated code becomes invalid after a few iterations.
Figures









read the original abstract
Verification presents a major bottleneck in Integrated Circuit (IC) development, consuming nearly 70% of the total development effort. While the Universal Verification Methodology (UVM) is widely used in industry to improve verification efficiency through structured and reusable testbenches, constructing these testbenches and generating sufficient stimuli remain challenging. These challenges arise from the considerable manual coding effort required, repetitive manual execution of multiple EDA tools, and the need for in-depth domain expertise to navigate complex designs.Here, we present UVM^2, an automated verification framework that leverages Large Language Models (LLMs) to generate UVM testbenches and iteratively refine them using coverage feedback, significantly reducing manual effort while maintaining rigorous verification standards.To evaluate UVM^2, we introduce a benchmark suite comprising Register Transfer Level (RTL) designs of up to 1.6K lines of code.The results show that UVM^2 reduces testbench setup time by up to UVM^2 compared to experienced engineers, and achieve average code and function coverage of 87.44% and 89.58%, outperforming state-of-the-art solutions by 20.96% and 23.51%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UVM^2, an automated framework that employs large language models to generate UVM testbenches for RTL designs and iteratively refines them using coverage feedback. It presents a new benchmark suite of RTL designs up to 1.6k LOC and reports that UVM^2 reduces testbench setup time by up to UVM^2 relative to experienced engineers while achieving average code coverage of 87.44% and functional coverage of 89.58%, outperforming state-of-the-art methods by 20.96% and 23.51% respectively.
Significance. If the reported coverage gains and time reductions hold under rigorous controls, the work could meaningfully alleviate the verification bottleneck that consumes ~70% of IC development effort. The introduction of a dedicated benchmark suite is a constructive contribution that enables future comparisons, though the framework's dependence on external LLM calls and coverage-driven iteration must be shown to generalize beyond the evaluated designs.
major comments (3)
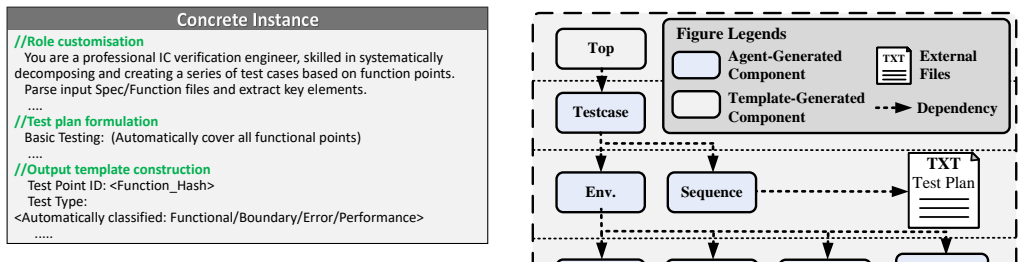
- [Abstract and §4] Abstract and §4: The iterative refinement loop is presented as relying solely on coverage metrics to produce progressively better, syntactically valid UVM testbenches, yet no details are supplied on prompt templates, handling of invalid LLM outputs, or safeguards against over-constrained sequences or hallucinated components. This assumption is load-bearing for the claimed 87.44%/89.58% coverage figures and the 20.96%/23.51% outperformance.
- [§5] §5 (Experimental Setup): The comparison against experienced engineers does not specify the engineers' experience level, the precise tasks timed, measurement protocol, or controls for post-hoc adjustments and benchmark selection. Without these, the reported setup-time reduction cannot be evaluated as a reproducible result.
- [§5.2] §5.2 (Benchmark Suite): The new RTL benchmark suite (designs ≤1.6k LOC) is introduced without disclosure of selection criteria, public availability, or verification that the designs exercise realistic stimulus-generation and interface challenges rather than permitting coverage inflation on narrow cases.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to UVM^2' for the time reduction appears to be a placeholder or typographical error and should be replaced by a concrete numerical factor.
- [Abstract] Notation: The framework name UVM^2 is used both for the system and in the time-reduction claim, creating unnecessary ambiguity.
Simulated Author's Rebuttal
We thank the referee for the insightful comments and recommendations. We address each of the major comments in detail below, indicating the revisions we plan to make to enhance the manuscript's clarity, reproducibility, and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] The iterative refinement loop is presented as relying solely on coverage metrics to produce progressively better, syntactically valid UVM testbenches, yet no details are supplied on prompt templates, handling of invalid LLM outputs, or safeguards against over-constrained sequences or hallucinated components. This assumption is load-bearing for the claimed 87.44%/89.58% coverage figures and the 20.96%/23.51% outperformance.
Authors: We agree that additional details on the iterative refinement process are necessary to fully substantiate our results. In the revised manuscript, we will expand Section 4 to include the specific prompt templates employed for generating and refining UVM testbenches. We will also describe our approach to handling invalid LLM outputs, such as syntax error detection and iterative prompting for corrections. Furthermore, we will detail safeguards implemented to mitigate over-constrained sequences and potential hallucinations, including validation checks and component verification steps. These enhancements will provide greater transparency and support the reported coverage metrics. revision: yes
-
Referee: [§5] The comparison against experienced engineers does not specify the engineers' experience level, the precise tasks timed, measurement protocol, or controls for post-hoc adjustments and benchmark selection. Without these, the reported setup-time reduction cannot be evaluated as a reproducible result.
Authors: We acknowledge the need for more precise documentation of the experimental comparison. In the revision to Section 5, we will provide details on the experience levels of the participating engineers, specifying their years of industry experience with UVM and RTL verification. We will clarify the precise tasks that were timed, including testbench creation and initial stimulus setup. The measurement protocol will be described, including the tools and methods used for timing. Additionally, we will outline the controls employed, such as the use of identical benchmark designs and procedures to prevent post-hoc adjustments or selection bias. This will allow for better evaluation of the time reduction claims. revision: yes
-
Referee: [§5.2] The new RTL benchmark suite (designs ≤1.6k LOC) is introduced without disclosure of selection criteria, public availability, or verification that the designs exercise realistic stimulus-generation and interface challenges rather than permitting coverage inflation on narrow cases.
Authors: We recognize the importance of detailing the benchmark suite for reproducibility and validity. In the revised Section 5.2, we will disclose the selection criteria used for the RTL designs, emphasizing diversity in size, functionality, and complexity up to 1.6k LOC. We commit to making the benchmark suite publicly available, for example via a GitHub repository, upon publication. We will also include a discussion or additional analysis verifying that the designs incorporate realistic stimulus-generation requirements and interface challenges, thereby demonstrating that the coverage results are not due to narrow or inflated cases. revision: yes
Circularity Check
No significant circularity; empirical results are measured outcomes on external benchmarks
full rationale
The paper introduces UVM^2 as an LLM-driven framework that generates and refines UVM testbenches via coverage feedback, then reports measured performance (setup time reductions, 87.44% code coverage, 89.58% functional coverage) on a newly created benchmark suite of RTL designs up to 1.6k LOC. These quantities are direct experimental outputs from running the system against external LLMs and EDA tools rather than quantities defined in terms of the paper's own fitted parameters or self-referential equations. No self-definitional steps, fitted-input predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or described evaluation chain; the results remain falsifiable against independent benchmarks and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can be prompted to produce syntactically correct and functionally useful UVM testbench code for given RTL designs
- domain assumption Coverage feedback supplies sufficient guidance for the LLM to iteratively improve testbench quality without external human fixes
invented entities (1)
-
UVM^2 framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UVM2 employs LLMs guided by domain-specific strategies to produce industrial-grade, UVM testbench, and iteratively refines test stimuli based on coverage feedback.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iteratively improves function coverage by analysing collected coverage data and supplementing test stimuli
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
UVMarvel: an Automated LLM-aided UVM Machine for Subsystem-level RTL Verification
UVMarvel automatically constructs subsystem-level UVM testbenches for mainstream bus protocols using LLMs, an IR, and supporting libraries, reaching 95.65% average code coverage in 4.5 hours of automated runtime.
-
HAVEN: Hybrid Automated Verification ENgine for UVM Testbench Synthesis with LLMs
HAVEN combines LLM agents for planning and gap analysis with protocol-specific templates and a custom DSL to generate correct UVM testbenches, achieving 100% compilation success, 90.6% code coverage, and 87.9% functio...
-
Spec2Cov: An Agentic Framework for Code Coverage Closure of Digital Hardware Designs
Spec2Cov uses an LLM agent in a feedback loop with a hardware simulator to generate tests from specs, achieving 100% coverage on simple designs and up to 49% on complex ones across 26 benchmarks.
-
Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification
Domain-specialized LLM agents for hardware verification close 95-99% coverage using 4-13x fewer tokens and 2-4x faster convergence than general-purpose agents by reallocating tokens toward coverage-directed reasoning.
-
Spec2Cov: An Agentic Framework for Code Coverage Closure of Digital Hardware Designs
Spec2Cov uses an LLM-simulator feedback loop to generate tests from specs, reaching 100% coverage on simple designs and up to 49% on complex ones across 26 benchmarks.
Reference graph
Works this paper leans on
-
[1]
Are we there yet? a study on the state of high-level synthesis,
S. Lahti, P. Sj ¨ovall, J. Vanne, and T. D. H ¨am¨al¨ainen, “Are we there yet? a study on the state of high-level synthesis,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , vol. 38, no. 5, pp. 898–911, 2018
work page 2018
-
[2]
Closing the verification gap with static sign-off,
P. Ashar and V . Viswanath, “Closing the verification gap with static sign-off,” in 20th International Symposium on Quality Electronic Design (ISQED). IEEE, 2019, pp. 343–347
work page 2019
-
[3]
High performance machine learning models for functional verification of hardware designs,
K. A. Ismail and M. A. Abd El Ghany, “High performance machine learning models for functional verification of hardware designs,” in 2021 3rd Novel Intelligent and Leading Emerging Sciences Conference (NILES). IEEE, 2021, pp. 15–18
work page 2021
-
[4]
Coverage fulfillment automation in hard- ware functional verification using genetic algorithms,
G. M. Danciu and A. Dinu, “Coverage fulfillment automation in hard- ware functional verification using genetic algorithms,” Applied Sciences, vol. 12, no. 3, p. 1559, 2022
work page 2022
-
[5]
Machine learning in the service of hardware functional verification,
R. Gal and A. Ziv, “Machine learning in the service of hardware functional verification,” in Machine Learning Applications in Electronic Design Automation. Springer, 2022, pp. 377–424
work page 2022
-
[6]
J. L. Hennessy and D. A. Patterson, Computer architecture: a quantita- tive approach. Elsevier, 2011
work page 2011
-
[7]
S. Harris and D. Harris, Digital Design and Computer Architecture, RISC-V Edition. Morgan Kaufmann, 2021
work page 2021
-
[8]
A uvm-based smart functional verification platform: Concepts, pros, cons, and opportunities,
K. Salah, “A uvm-based smart functional verification platform: Concepts, pros, cons, and opportunities,” in 2014 9th International Design and Test symposium (IDT). IEEE, 2014, pp. 94–99
work page 2014
-
[9]
Pragmatic approaches to implement self-checking mechanism in uvm based testbench,
R. Madan, N. Kumar, and S. Deb, “Pragmatic approaches to implement self-checking mechanism in uvm based testbench,” in 2015 International Conference on Advances in Computer Engineering and Applications . IEEE, 2015, pp. 632–636
work page 2015
-
[10]
Uvm based testbench architecture for coverage driven functional verification of spi protocol,
B. Vineeth and B. B. T. Sundari, “Uvm based testbench architecture for coverage driven functional verification of spi protocol,” in 2018 International conference on advances in computing, communications and informatics (ICACCI). IEEE, 2018, pp. 307–310
work page 2018
-
[11]
Beyond uvm for practical soc verification,
Y .-N. Yun, J.-B. Kim, N.-D. Kim, and B. Min, “Beyond uvm for practical soc verification,” in 2011 International SoC Design Conference . IEEE, 2011, pp. 158–162
work page 2011
-
[12]
Simplified stimuli generation for scenario and assertion based verification,
L. Piccolboni and G. Pravadelli, “Simplified stimuli generation for scenario and assertion based verification,” in 2014 15th Latin American Test Workshop-LATW. IEEE, 2014, pp. 1–6
work page 2014
-
[13]
Uvm-based verification of ecc module for flash memories,
G. Visalli, “Uvm-based verification of ecc module for flash memories,” in 2017 European Conference on Circuit Theory and Design (ECCTD) . IEEE, 2017, pp. 1–4
work page 2017
-
[14]
A. Vintila, I. Tolea, H. Du, and Q. Gong, “Portable stimulus driven systemverilog/uvm verification environment for the verification of a high-capacity ethernet communication endpoint,” in Proceedings of the 2018 DVCON Conference and Exhibition Europe, Munich, Germany , 2018, pp. 24–25
work page 2018
-
[15]
J. Bromley, “If systemverilog is so good, why do we need the uvm? sharing responsibilities between libraries and the core language,” in Proceedings of the 2013 Forum on specification and Design Languages (FDL). IEEE, 2013, pp. 1–7
work page 2013
-
[16]
Uvm based testbench architecture for unit verification,
J. Francesconi, J. A. Rodriguez, and P. M. Julian, “Uvm based testbench architecture for unit verification,” in 2014 Argentine Conference on Micro-Nanoelectronics, Technology and Applications. IEEE, 2014, pp. 89–94
work page 2014
-
[17]
Case study: Uvm-fie: Enhancing uvm-based fault injection library for complex designs,
L. S. Tavares, W. J. Chau, and F. J. Fonseca, “Case study: Uvm-fie: Enhancing uvm-based fault injection library for complex designs,” in 2025 IEEE 26th Latin American Test Symposium . IEEE, 2025
work page 2025
-
[18]
Uvm based testbench architecture for logic sub-system verification,
T. Pavithran and R. Bhakthavatchalu, “Uvm based testbench architecture for logic sub-system verification,” in 2017 International Conference on Technological Advancements in Power and Energy (TAP Energy). IEEE, 2017, pp. 1–5
work page 2017
-
[19]
Design and verification process of combinational adder using uvm methodology,
M. Dharani, M. Bharathi, N. Padmaja, and K. Praveena, “Design and verification process of combinational adder using uvm methodology,” in 2023 International Conference on Advances in Electronics, Communica- tion, Computing and Intelligent Information Systems (ICAECIS) . IEEE, 2023, pp. 359–362
work page 2023
-
[20]
Robust serial driver verification through uvm framework,
P. S. Kumar, R. Rajalakshmi, N. H. Kumar, B. P. Gupta, C. H. Nikhilesh, and J. S. P. Pavan, “Robust serial driver verification through uvm framework,” in 2024 Control Instrumentation System Conference (CISCON). IEEE, 2024, pp. 1–6
work page 2024
-
[21]
Modified condition decision coverage: A hardware verification perspective,
M. A. Salem and K. I. Eder, “Modified condition decision coverage: A hardware verification perspective,” in 2013 14th International Workshop on Microprocessor Test and Verification. IEEE, 2013, pp. 8–13
work page 2013
-
[22]
An uvm-based verification platform for hardware and software co-design,
S. Wu, K. Zhao, X. Wang, S. He, and D. Guo, “An uvm-based verification platform for hardware and software co-design,” in 2023 IEEE 17th International Conference on Anti-counterfeiting, Security, and Identification (ASID). IEEE, 2023, pp. 21–24
work page 2023
-
[23]
Uvm methodology: Industry-specific applications in modern hardware verification,
K. V . Reddy, “Uvm methodology: Industry-specific applications in modern hardware verification,” International Journal of Computer En- gineering and Technology (IJCET) , vol. 15, no. 6, pp. 20–32, 2024
work page 2024
-
[24]
Verigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,” arXiv preprint arXiv:2308.00708 , 2023
-
[25]
Chip-chat: Challenges and opportunities in conversational hardware design,
J. Blocklove, S. Garg, R. Karri, and H. Pearce, “Chip-chat: Challenges and opportunities in conversational hardware design,” arXiv preprint arXiv:2305.13243, 2023
-
[26]
Rtlfixer: Automatically fixing rtl syntax errors with large language models,
Y . Tsai, M. Liu, and H. Ren, “Rtlfixer: Automatically fixing rtl syntax errors with large language models,” arXiv preprint arXiv:2311.16543 , 2023
-
[27]
Fixing hardware security bugs with large language models,
B. Ahmad, S. Thakur, B. Tan, R. Karri, and H. Pearce, “Fixing hardware security bugs with large language models,” arXiv preprint arXiv:2302.01215, 2023
-
[28]
Llm4sechw: Leveraging domain-specific large language model for hardware debug- ging,
W. Fu, K. Yang, R. G. Dutta, X. Guo, and G. Qu, “Llm4sechw: Leveraging domain-specific large language model for hardware debug- ging,” in 2023 Asian Hardware Oriented Security and Trust Symposium (AsianHOST). IEEE, 2023, pp. 1–6
work page 2023
-
[29]
Make every move count: Llm-based high-quality rtl code generation using mcts,
M. DeLorenzo, A. B. Chowdhury, V . Gohil, S. Thakur, R. Karri, S. Garg, and J. Rajendran, “Make every move count: Llm-based high-quality rtl code generation using mcts,” arXiv preprint arXiv:2402.03289 , 2024
-
[30]
Domain- adapted llms for vlsi design and verification: A case study on formal verification,
M. Liu, M. Kang, G. B. Hamad, S. Suhaib, and H. Ren, “Domain- adapted llms for vlsi design and verification: A case study on formal verification,” in 2024 IEEE 42nd VLSI Test Symposium (VTS) . IEEE, 2024, pp. 1–4
work page 2024
-
[31]
Hdldebugger: Streamlining hdl debugging with large language models,
X. Yao, H. Li, T. H. Chan, W. Xiao, M. Yuan, Y . Huang, L. Chen, and B. Yu, “Hdldebugger: Streamlining hdl debugging with large language models,” arXiv preprint arXiv:2403.11671 , 2024
-
[32]
W. Fang, M. Li, M. Li, Z. Yan, S. Liu, H. Zhang, and Z. Xie, “Assertllm: Generating and evaluating hardware verification assertions from design specifications via multi-llms,” arXiv preprint arXiv:2402.00386 , 2024
-
[33]
Location is key: Leveraging large language model for functional bug localization in verilog,
B. Yao, N. Wang, J. Zhou, X. Wang, H. Gao, Z. Jiang, and N. Guan, “Location is key: Leveraging large language model for functional bug localization in verilog,” arXiv preprint arXiv:2409.15186 , 2024
-
[34]
J. Zhou, Y . Ji, N. Wang, Y . Hu, X. Jiao, B. Yao, X. Fang, S. Zhao, N. Guan, and Z. Jiang, “Insights from rights and wrongs: A large language model for solving assertion failures in rtl design,” arXiv preprint arXiv:2503.04057, 2025
-
[35]
Meic: Re-thinking rtl debug automation using llms,
K. Xu, J. Sun, Y . Hu, X. Fang, W. Shan, X. Wang, and Z. Jiang, “Meic: Re-thinking rtl debug automation using llms,” in Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design , ser. ICCAD ’24. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3676536.3676801
-
[36]
Uvllm: An automated universal rtl verification framework using llms,
Y . Hu, J. Ye, K. Xu, J. Sun, S. Zhang, X. Jiao, D. Pan, J. Zhou, N. Wang, W. Shan et al., “Uvllm: An automated universal rtl verification framework using llms,” arXiv preprint arXiv:2411.16238 , 2024
-
[37]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
J. White, Q. Fu, S. Hays, M. Sandborn, C. Olea, H. Gilbert, A. El- nashar, J. Spencer-Smith, and D. C. Schmidt, “A prompt pattern catalog to enhance prompt engineering with chatgpt,” arXiv preprint arXiv:2302.11382, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD) . IEEE, 2023, pp. 1–8
work page 2023
-
[39]
Chipgpt: How far are we from natural language hardware design,
K. Chang, Y . Wang, H. Ren, M. Wang, S. Liang, Y . Han, H. Li, and X. Li, “Chipgpt: How far are we from natural language hardware design,” arXiv preprint arXiv:2305.14019 , 2023
-
[40]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,” arXiv preprint arXiv:2402.07927 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Hallucinations in llms: Understanding and addressing challenges,
G. Perkovi ´c, A. Drobnjak, and I. Boti ˇcki, “Hallucinations in llms: Understanding and addressing challenges,” in 2024 47th MIPRO ICT and Electronics Convention (MIPRO) . IEEE, 2024, pp. 2084–2088
work page 2024
-
[42]
Hallucinations in large language models (llms),
G. P. Reddy, Y . P. Kumar, and K. P. Prakash, “Hallucinations in large language models (llms),” in 2024 IEEE Open Conference of Electrical, Electronic and Information Sciences (eStream) . IEEE, 2024, pp. 1–6
work page 2024
-
[43]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
S. Tonmoy, S. Zaman, V . Jain, A. Rani, V . Rawte, A. Chadha, and A. Das, “A comprehensive survey of hallucination mitigation techniques in large language models,” arXiv preprint arXiv:2401.01313 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” arXiv preprint arXiv:2308.05345, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.