RewardBench 2: Advancing Reward Model Evaluation
Pith reviewed 2026-05-19 11:14 UTC · model grok-4.3
The pith
RewardBench 2 evaluates reward models using entirely new human prompts and finds the scores still predict success in best-of-N sampling and RLHF training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
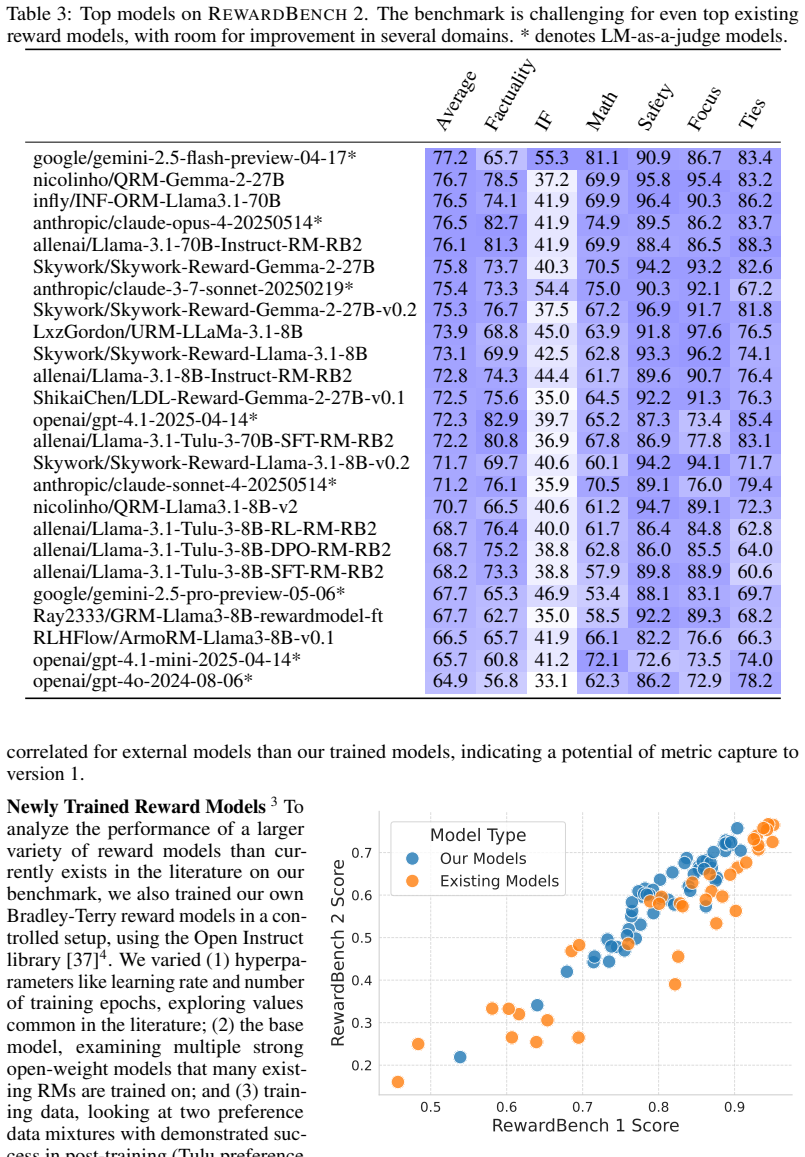
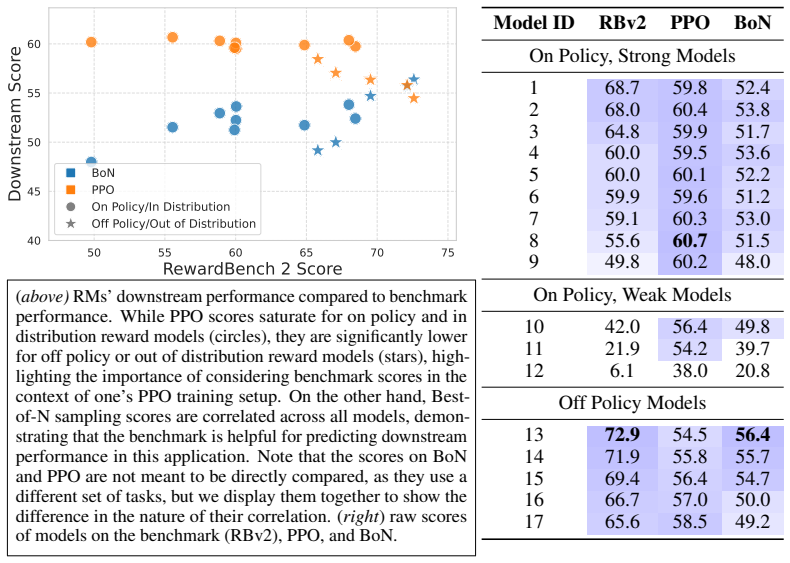
RewardBench 2 sources new human prompts to create a multi-skill reward modeling benchmark. This produces an average score drop of about 20 points for current models relative to the original RewardBench. The benchmark scores nevertheless correlate highly with downstream results in inference-time scaling methods such as best-of-N and in RLHF training methods such as proximal policy optimization.
What carries the argument
RewardBench 2, a benchmark assembled from fresh human prompts to measure reward model accuracy across multiple capability areas.
If this is right
- Reward models that rank higher on RewardBench 2 are expected to produce stronger results when used for best-of-N sampling during inference.
- Reward models selected by RewardBench 2 scores should improve outcomes when applied inside proximal policy optimization for RLHF.
- The benchmark supplies an independent test set that avoids data overlap with the tasks it is meant to support.
- Developers gain a practical signal for choosing reward models before committing to full post-training runs.
Where Pith is reading between the lines
- Teams could shorten reward model development cycles by iterating against RewardBench 2 before launching expensive training experiments.
- The practice of writing original prompts for benchmarks might raise predictive reliability in other evaluation settings that currently recycle task data.
- Researchers could measure whether the observed correlation weakens or strengthens when models are tested on narrower skill subsets of the benchmark.
Load-bearing premise
That sourcing entirely new human prompts rather than reusing prompts from downstream evaluations produces scores that more reliably indicate real-world utility in best-of-N and PPO-style training.
What would settle it
Train or select reward models using only RewardBench 2 scores and check whether they deliver measurably better outputs in best-of-N sampling and PPO runs than models chosen by earlier benchmarks.
Figures




read the original abstract
Reward models are used throughout the post-training of language models to capture nuanced signals from preference data and provide a training target for optimization across instruction following, reasoning, safety, and more domains. The community has begun establishing best practices for evaluating reward models, from the development of benchmarks that test capabilities in specific skill areas to others that test agreement with human preferences. At the same time, progress in evaluation has not been mirrored by the effectiveness of reward models in downstream tasks -- simpler direct alignment algorithms are reported to work better in many cases. This paper introduces RewardBench 2, a new multi-skill reward modeling benchmark designed to bring new, challenging data for accuracy-based reward model evaluation -- models score about 20 points on average lower on RewardBench 2 compared to the first RewardBench -- while being highly correlated with downstream performance. Compared to most other benchmarks, RewardBench 2 sources new human prompts instead of existing prompts from downstream evaluations, facilitating more rigorous evaluation practices. In this paper, we describe our benchmark construction process and report how existing models perform on it, while quantifying how performance on the benchmark correlates with downstream use of the models in both inference-time scaling algorithms, like best-of-N sampling, and RLHF training algorithms like proximal policy optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RewardBench 2, a new multi-skill benchmark for reward models that sources entirely new human prompts (rather than reusing prompts from downstream evaluations). It reports that models score ~20 points lower on average than on the original RewardBench, describes the construction process, and quantifies high correlation between RewardBench 2 scores and downstream performance in inference-time scaling (best-of-N) and RLHF training (PPO).
Significance. If the reported correlations are robust and the new-prompt design demonstrably improves predictive validity over reused-prompt benchmarks, the work would strengthen evaluation practices by reducing the risk of benchmark overfitting and providing a more reliable signal for reward model utility in post-training. The explicit focus on new data collection is a methodological strength that could influence future benchmark design.
major comments (1)
- [§4 and abstract] §4 (Correlation with Downstream Tasks) and the abstract: the central claim that sourcing new human prompts 'facilitates more rigorous evaluation practices' and yields scores that 'more reliably predict real-world utility' is not supported by any head-to-head comparison. The manuscript shows high correlation for RewardBench 2 but provides no Spearman ρ, R², or ranking agreement metrics comparing RewardBench 2 versus RewardBench 1 (or other reused-prompt benchmarks) on the identical best-of-N and PPO downstream metrics. Without this, the design choice cannot be shown to improve predictive power rather than merely increasing difficulty.
minor comments (2)
- [Figure 3] Figure 3 (or equivalent correlation plot): axis labels and error bars are not described in the caption; it is unclear whether the plotted points reflect per-model variance or aggregated statistics.
- [Table 2] Table 2 (model scores): the 'average' row does not specify whether it is a simple mean or weighted by category size; this affects interpretation of the reported 20-point drop.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. We address below the major concern raised about the absence of head-to-head comparisons between RewardBench 2 and prior benchmarks in terms of downstream predictive power.
read point-by-point responses
-
Referee: [§4 and abstract] §4 (Correlation with Downstream Tasks) and the abstract: the central claim that sourcing new human prompts 'facilitates more rigorous evaluation practices' and yields scores that 'more reliably predict real-world utility' is not supported by any head-to-head comparison. The manuscript shows high correlation for RewardBench 2 but provides no Spearman ρ, R², or ranking agreement metrics comparing RewardBench 2 versus RewardBench 1 (or other reused-prompt benchmarks) on the identical best-of-N and PPO downstream metrics. Without this, the design choice cannot be shown to improve predictive power rather than merely increasing difficulty.
Authors: We agree that including direct comparative metrics, such as Spearman ρ or ranking agreement between RewardBench 2 and the original RewardBench on the same downstream tasks, would strengthen the manuscript's claims. The current work demonstrates a strong correlation between RewardBench 2 scores and performance in best-of-N and PPO settings, alongside a notable increase in difficulty (approximately 20 points lower scores). Our rationale for new prompt collection is to mitigate the risk of benchmark contamination from prompts potentially seen during model development or evaluation. While we did not perform the head-to-head analysis due to differences in experimental setups from the original RewardBench paper, we will revise the manuscript to include a more explicit discussion of this point and the methodological advantages of fresh data collection. revision: partial
Circularity Check
Benchmark construction and correlations presented as empirical results against external tasks
full rationale
The paper introduces RewardBench 2 by sourcing new human prompts and reports average score drops plus correlations with downstream inference-time scaling and RLHF tasks. These are framed as measurements on external data rather than internal predictions or fitted parameters. No self-definitional reductions, fitted-input-as-prediction, or load-bearing self-citation chains appear in the described construction or evaluation process. Minor self-citation of prior RewardBench work is present but not load-bearing for the central claims, which rest on new data collection and external task correlations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward model accuracy on held-out preference data is a meaningful proxy for downstream utility in alignment algorithms.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RewardBench 2 sources new human prompts instead of existing prompts from downstream evaluations... highly correlated with downstream performance in inference-time scaling and RLHF training.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 17 Pith papers
-
Boiling the Frog: A Multi-Turn Benchmark for Agentic Safety
Boiling the Frog is a new stateful multi-turn benchmark for agentic safety that reports an aggregate strict attack success rate of 44.4% across nine models, with rates ranging from 20.5% to 92.9% depending on the mode...
-
Boiling the Frog: A Multi-Turn Benchmark for Agentic Safety
Boiling the Frog is a new stateful multi-turn benchmark that finds an aggregate 44.4% strict attack success rate for incremental safety violations across nine AI models, with rates ranging from 20.5% to 92.9%.
-
Think-with-Rubrics: From External Evaluator to Internal Reasoning Guidance
Think-with-Rubrics has LLMs generate rubrics internally before responding, outperforming external rubric-as-reward baselines by 3.87 points on average across benchmarks.
-
You Only Judge Once: Multi-response Reward Modeling in a Single Forward Pass
A multi-response discriminative reward model scores N candidates in one pass via concatenation and cross-entropy, achieving SOTA on multimodal benchmarks and improving RL policies over single-response baselines.
-
Beyond Semantic Manipulation: Token-Space Attacks on Reward Models
TOMPA performs black-box adversarial optimization in token space to discover non-linguistic patterns that nearly double the reward scores of GPT-5 answers on Skywork-Reward-V2 while producing gibberish text.
-
Transitivity Meets Cyclicity: Explicit Preference Decomposition for Dynamic Large Language Model Alignment
Introduces HRC model for game-theoretic decomposition of preferences into orthogonal transitive and cyclic components, paired with DSPPO for dynamic Nash-seeking alignment, reporting gains over BT and GPM baselines on...
-
Reasoning Is Not Free: Robust Adaptive Cost-Efficient Routing for LLM-as-a-Judge
RACER routes between reasoning and non-reasoning LLM judges via constrained distributionally robust optimization to achieve better accuracy-cost trade-offs under distribution shift.
-
Calibrate, Don't Curate: Label-Efficient Estimation from Noisy LLM Judges
Calibrating the full set of LLM judges with labeled data halves calibration error versus top-5 accuracy selection on RewardBench2 and outperforms on four benchmarks.
-
Video Understanding Reward Modeling: A Robust Benchmark and Performant Reward Models
Introduces VURB benchmark and VUP-35K dataset to train discriminative and generative video reward models that achieve SOTA performance on VURB and VideoRewardBench.
-
When Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Certain errors in proxy rewards for policy gradient methods can be benign or beneficial by preventing policies from stalling on outputs with mediocre ground truth rewards, enabling improved RLHF metrics and reward des...
-
Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization
Personalized RewardBench reveals that state-of-the-art reward models reach only 75.94% accuracy on personalized preferences and shows stronger correlation with downstream BoN and PPO performance than prior benchmarks.
-
Reflective Context Learning: Studying the Optimization Primitives of Context Space
Reflective Context Learning unifies context optimization for agents by recasting prior methods as instances of a shared learning problem and extending them with classical primitives such as batching, failure replay, a...
-
Mitigating Reward Hacking in RLHF via Advantage Sign Robustness
SignCert-PO mitigates reward hacking in RLHF by down-weighting completions whose advantage signs are not robust to small reward-model perturbations, using a certified preservation radius derived at the policy optimiza...
-
Robust Policy Optimization to Prevent Catastrophic Forgetting
FRPO applies a max-min robust optimization over KL-bounded policy neighborhoods during RLHF to reduce catastrophic forgetting of safety and accuracy under subsequent SFT or RL fine-tuning.
-
Placing Puzzle Pieces Where They Matter: A Question Augmentation Framework for Reinforcement Learning
PieceHint strategically scores and injects critical reasoning hints in RL training to let a 1.5B model match 32B baselines on math benchmarks while preserving pass@k diversity.
-
On Cost-Effective LLM-as-a-Judge Improvement Techniques
Ensemble scoring plus task-specific criteria injection raises LLM judge accuracy to 85.8 percent on RewardBench 2, a 13.5-point gain over baseline, with small models gaining the most.
-
Reinforcement Learning from Human Feedback
The book introduces the origins, mathematical setup, and optimization stages of RLHF including reward modeling, reinforcement learning, rejection sampling, and direct alignment algorithms.
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Improving alignment of dialogue agents via targeted human judgements
Amelia Glaese, Nat McAleese, Maja Tr˛ ebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
D2po: Discriminator- guided dpo with response evaluation models,
Prasann Singhal, Nathan Lambert, Scott Niekum, Tanya Goyal, and Greg Durrett. D2po: Discriminator-guided dpo with response evaluation models. arXiv preprint arXiv:2405.01511, 2024
-
[8]
arXiv preprint arXiv:2402.16827
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, et al. A survey on data selection for language models. arXiv preprint arXiv:2402.16827, 2024
-
[9]
Sample, don’t search: Rethinking test-time alignment for language models
Gonçalo Faria and Noah A Smith. Sample, don’t search: Rethinking test-time alignment for language models. arXiv preprint arXiv:2504.03790, 2025
-
[10]
Inference-aware fine-tuning for best-of-n sampling in large language models
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine-tuning for best-of-n sampling in large language models. arXiv preprint arXiv:2412.15287, 2024
-
[11]
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787, 2024
-
[12]
Rm-bench: Benchmarking reward models of language models with subtlety and style, 2024
Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Rm-bench: Benchmarking reward models of language models with subtlety and style. arXiv preprint arXiv:2410.16184, 2024
-
[13]
RMB: Comprehensively benchmarking reward models in LLM alignment
Enyu Zhou, Guodong Zheng, Binghai Wang, Zhiheng Xi, Shihan Dou, Rong Bao, Wei Shen, Limao Xiong, Jessica Fan, Yurong Mou, et al. Rmb: Comprehensively benchmarking reward models in llm alignment. arXiv preprint arXiv:2410.09893, 2024
-
[14]
Athene-70b: Redefining the boundaries of post-training for open models, July 2024a
Evan Frick, Tianle Li, Connor Chen, Wei-Lin Chiang, Anastasios N Angelopoulos, Jiantao Jiao, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. How to evaluate reward models for rlhf. arXiv preprint arXiv:2410.14872, 2024
-
[15]
WildChat: 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild. arXiv preprint arXiv:2405.01470, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Reinforcement Learning from Human Feedback
Nathan Lambert. Reinforcement learning from human feedback. arXiv preprint arXiv:2504.12501, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[18]
Evaluating robustness of reward models for mathematical reasoning,
Sunghwan Kim, Dongjin Kang, Taeyoon Kwon, Hyungjoo Chae, Jungsoo Won, Dongha Lee, and Jinyoung Yeo. Evaluating robustness of reward models for mathematical reasoning. arXiv preprint arXiv:2410.01729, 2024
-
[19]
reWordBench: Benchmarking and improving the robustness of reward models with transformed inputs,
Zhaofeng Wu, Michihiro Yasunaga, Andrew Cohen, Yoon Kim, Asli Celikyilmaz, and Marjan Ghazvininejad. rewordbench: Benchmarking and improving the robustness of reward models with transformed inputs. arXiv preprint arXiv:2503.11751, 2025
-
[20]
M-rewardbench: Evaluating reward models in multilingual settings
Srishti Gureja, Lester James V Miranda, Shayekh Bin Islam, Rishabh Maheshwary, Dr- ishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh Fadaee. M-rewardbench: Evaluating reward models in multilingual settings. arXiv preprint arXiv:2410.15522, 2024
-
[21]
Xueru Wen, Jie Lou, Yaojie Lu, Hongyu Lin, Xing Yu, Xinyu Lu, Ben He, Xianpei Han, Debing Zhang, and Le Sun. Rethinking reward model evaluation: Are we barking up the wrong tree? arXiv preprint arXiv:2410.05584, 2024
-
[22]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejan- dra Zambrano, Karolina Sta´nczak, Peter Shaw, Christopher J. Pal, and Siva Reddy. Agentre- wardbench: Evaluating automatic evaluations of web agent trajectories, 2025
work page 2025
-
[23]
Zhuoran Jin, Hongbang Yuan, Tianyi Men, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Rag-rewardbench: Benchmarking reward models in retrieval augmented generation for preference alignment. arXiv preprint arXiv:2412.13746, 2024
-
[24]
MJ-bench: Is your multimodal reward model really a good judge for text-to-image generation?
Zhaorun Chen, Yichao Du, Zichen Wen, Yiyang Zhou, Chenhang Cui, Zhenzhen Weng, Haoqin Tu, Chaoqi Wang, Zhengwei Tong, Qinglan Huang, et al. Mj-bench: Is your multimodal reward model really a good judge for text-to-image generation? arXiv preprint arXiv:2407.04842, 2024
-
[25]
Multimodal rewardbench: Holistic evaluation of reward models for vision language models,
Michihiro Yasunaga, Luke Zettlemoyer, and Marjan Ghazvininejad. Multimodal reward- bench: Holistic evaluation of reward models for vision language models. arXiv preprint arXiv:2502.14191, 2025
-
[26]
VLRewardBench: A challenging benchmark for vision-language generative reward models,
Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiyi Wang, Chenxin An, Tianyu Liu, Sujian Li, Bill Yuchen Lin, et al. Vlrewardbench: A challenging benchmark for vision-language generative reward models. arXiv preprint arXiv:2411.17451, 2024
-
[27]
Vlrmbench: A comprehensive and challenging benchmark for vision- language reward models,
Jiacheng Ruan, Wenzhen Yuan, Xian Gao, Ye Guo, Daoxin Zhang, Zhe Xu, Yao Hu, Ting Liu, and Yuzhuo Fu. Vlrmbench: A comprehensive and challenging benchmark for vision-language reward models. arXiv preprint arXiv:2503.07478, 2025
-
[28]
Prmbench: A fine-grained and challenging benchmark for process-level reward models
Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine-grained and challenging benchmark for process-level reward models. arXiv preprint arXiv:2501.03124, 2025
-
[29]
VisualPRM: An effective process reward model for multimodal reasoning,
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visualprm: An effective process reward model for multimodal reasoning. arXiv preprint arXiv:2503.10291, 2025
-
[30]
Vilbench: A suite for vision-language process reward modeling, Mar 2025
Haoqin Tu, Weitao Feng, Hardy Chen, Hui Liu, Xianfeng Tang, and Cihang Xie. Vilbench: A suite for vision-language process reward modeling, Mar 2025
work page 2025
-
[31]
Entangled preferences: The history and risks of reinforcement learning and human feedback,
Nathan Lambert, Thomas Krendl Gilbert, and Tom Zick. The history and risks of reinforcement learning and human feedback. arXiv preprint arXiv:2310.13595, 2023
-
[32]
Michael JQ Zhang, Zhilin Wang, Jena D Hwang, Yi Dong, Olivier Delalleau, Yejin Choi, Eunsol Choi, Xiang Ren, and Valentina Pyatkin. Diverging preferences: When do annotators disagree and do models know? arXiv preprint arXiv:2410.14632, 2024. 11
-
[33]
Qurating: Selecting high-quality data for training language models, 2024
Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. Qurating: Selecting high-quality data for training language models, 2024
work page 2024
-
[34]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirz...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
The art of saying no: Contextual noncompliance in language models
Faeze Brahman, Sachin Kumar, Vidhisha Balachandran, Pradeep Dasigi, Valentina Pyatkin, Abhilasha Ravichander, Sarah Wiegreffe, Nouha Dziri, Khyathi Chandu, Jack Hessel, et al. The art of saying no: Contextual noncompliance in language models. Advances in Neural Information Processing Systems, 37:49706–49748, 2024
work page 2024
-
[36]
Evaluating large language models at evaluating instruction following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. Evaluating large language models at evaluating instruction following. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[37]
Smith, Iz Beltagy, and Hannaneh Ha- jishirzi
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Ha- jishirzi. How far can camels go? exploring the state of instruction tuning on open resources, 2023
work page 2023
-
[38]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Banghua Zhu, Michael I Jordan, and Jiantao Jiao. Iterative data smoothing: Mitigating reward overfitting and overoptimization in rlhf. arXiv preprint arXiv:2401.16335, 2024
-
[41]
HelpSteer2: Open-source dataset for training top-performing reward models,
Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J Zhang, Makesh Narsimhan Sreedhar, and Oleksii Kuchaiev. Helpsteer2: Open-source dataset for training top-performing reward models. arXiv preprint arXiv:2406.08673, 2024
-
[42]
Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D Lee, and Sanjeev Arora. What makes a reward model a good teacher? an optimization perspective. arXiv preprint arXiv:2503.15477, 2025
-
[43]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[45]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [46]
-
[47]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022. 12
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories, 2023
work page 2023
-
[49]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[50]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[51]
Unpacking dpo and ppo: Disentangling best practices for learning from preference feedback
Hamish Ivison, Yizhong Wang, Jiacheng Liu, Zeqiu Wu, Valentina Pyatkin, Nathan Lambert, Noah A Smith, Yejin Choi, and Hanna Hajishirzi. Unpacking dpo and ppo: Disentangling best practices for learning from preference feedback. Advances in neural information processing systems, 37:36602–36633, 2024
work page 2024
-
[52]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
work page 2024
-
[53]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023
work page 2023
-
[54]
Quantile regression for distributional reward models in rlhf, 2024
Nicolai Dorka. Quantile regression for distributional reward models in rlhf, 2024
work page 2024
-
[55]
Offsetbias: Leveraging debiased data for tuning evaluators
Junsoo Park, Seungyeon Jwa, Meiying Ren, Daeyoung Kim, and Sanghyuk Choi. Offsetbias: Leveraging debiased data for tuning evaluators. arXiv preprint arXiv:2407.06551, 2024
-
[56]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
work page 2024
-
[57]
Interpretable preferences via multi-objective reward modeling and mixture-of-experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. arXiv preprint arXiv:2406.12845, 2024
-
[58]
Helpsteer2-preference: Complementing ratings with prefer- ences
Zhilin Wang, Alexander Bukharin, Olivier Delalleau, Daniel Egert, Gerald Shen, Jiaqi Zeng, Oleksii Kuchaiev, and Yi Dong. Helpsteer2-preference: Complementing ratings with prefer- ences. arXiv preprint arXiv:2410.01257, 2024
-
[59]
Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, et al. Nemotron-4 340b technical report. arXiv preprint arXiv:2406.11704, 2024
-
[60]
Dakota Mahan, Duy Van Phung, Rafael Rafailov, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak. Generative reward models.arXiv preprint arXiv:2410.12832, 2024
-
[61]
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. arXiv preprint arXiv:2408.15240, 2024
-
[62]
Self-generated critiques boost reward modeling for language models
Yue Yu, Zhengxing Chen, Aston Zhang, Liang Tan, Chenguang Zhu, Richard Yuanzhe Pang, Yundi Qian, Xuewei Wang, Suchin Gururangan, Chao Zhang, Melanie Kambadur, Dhruv Mahajan, and Rui Hou. Self-generated critiques boost reward modeling for language models. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computation...
work page 2025
-
[63]
Critique-out-loud reward models,
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. Critique-out-loud reward models. arXiv preprint arXiv:2408.11791, 2024
-
[64]
Inference-time scaling for generalist reward modeling,
Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. Inference-time scaling for generalist reward modeling. arXiv preprint arXiv:2504.02495, 2025
-
[65]
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 13
work page 2024
-
[66]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Advances in Neural Information Processing Systems (NeurIPS) , 2022. arXiv:2206.14858
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR) , 2023. arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Fixing open llm leaderboard with math-verify
Hynek Kydlicek, Alina Lozovskaya, Nathan Habib, and Clémentine Fourrier. Fixing open llm leaderboard with math-verify. https://huggingface.co/blog/math_verify_ leaderboard, February 2025. Hugging Face Blog, published February 14 2025
work page 2025
-
[69]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023
work page 2023
-
[70]
Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku
Anthropic. Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku. Anthropic,
-
[71]
Accessed: 2024-10-22
work page 2024
- [72]
-
[73]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
work page 2024
-
[74]
Smith, Iz Beltagy, and Hannaneh Hajishirzi
Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. Camels in a changing climate: Enhancing lm adaptation with tulu 2, 2023
work page 2023
-
[75]
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment, 2023. 14 A Additional Background Reward models are used throughout post-traini...
work page 2023
-
[76]
We also vary the learning rate across 1 × 10−6, 3 × 10−6, and 2 × 10−5
Hyperparameters: While common practice is to train reward models for only one epoch [1, 2, 3, 39, 40, 41], several recent works have found strong results with training for two or more [38, 41, 54, 55], so we experiment with training over 1, 2, and 3 epochs. We also vary the learning rate across 1 × 10−6, 3 × 10−6, and 2 × 10−5
-
[77]
Base Model: We conduct the bulk of initial hyperparameter sweeps on Tulu 8B SFT [34], following standard practice of initializing the first reward model from a supervised fine- tuned (SFT) model [1, 51],6, and also experimented with Tulu 3 8B DPO and RL to ablate initializing from different stages in the Tulu post-training recipe. We also experimented wit...
-
[78]
Training Data: We focus on two preference mixtures for training (and mixes of them): the Tulu 8B preference mix [34], comprising 270K pairwise GPT-4o-as-a-judge preferences between model completions drawn from a wide model pool and variety of prompt sources, and the Skywork preference mix [38], which curates 80K preferences from existing prefer- ence data...
work page 2024
-
[79]
Rankings: In this setting, for a best-of-4 datapoint, we give the generative model a prompt and all four candidate completions and ask it to judge which is best
-
[80]
Tulu” as a base model referring to Tulu 3 8B SFT, and “Qwen
Ratings: In this setting, for each best-of-4 datapoint, we query the model separately to produce an absolute rating on a scale of 1-10. Then, we aggregate the judgments for each set of 4 (or more, for ties) and score those ratings as though they were rewards—by giving the model a point for rating the correct response highest, and scoring two-way ties as p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.