Fin-PRM: A Domain-Specialized Process Reward Model for Financial Reasoning in Large Language Models
Pith reviewed 2026-05-18 22:37 UTC · model grok-4.3
The pith
Fin-PRM improves financial reasoning in LLMs by providing step-level and trajectory-level supervision from multi-source labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fin-PRM is a trajectory-aware process reward model that jointly models step-level correctness and trajectory-level coherence through binary supervision signals derived from Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification, yielding a unified ranking score that improves performance when applied to offline trajectory selection, reward-guided Best-of-N inference, and process-aware reward shaping for reinforcement learning on financial reasoning tasks.
What carries the argument
The unified ranking score that integrates binary step-level and trajectory-level rewards generated from Monte Carlo rollouts, LLM evaluation, and financial knowledge verification.
If this is right
- Offline selection of reasoning trajectories for supervised fine-tuning on financial tasks becomes more accurate.
- Best-of-N inference at test time gains from process-level signals rather than final-answer rewards alone.
- Reinforcement learning for financial reasoning can use finer-grained process supervision to shape rewards.
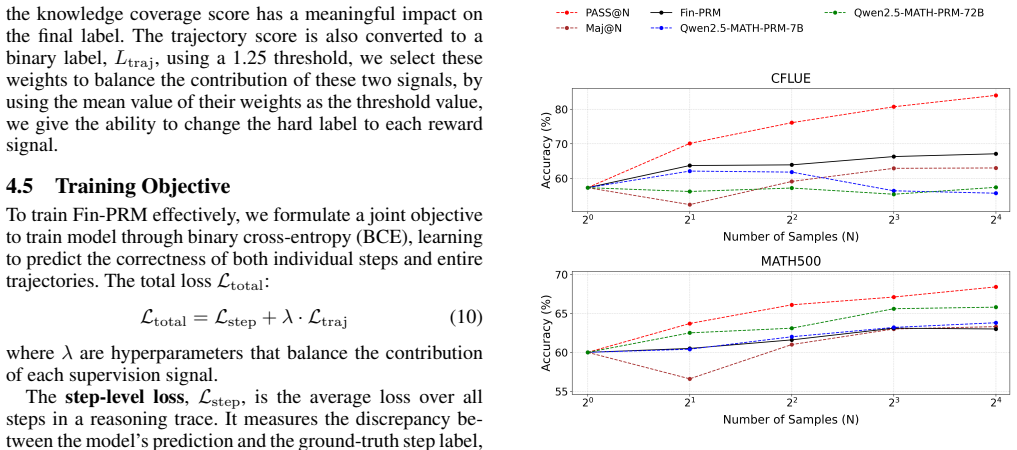
- The performance gains hold across multiple financial benchmarks including CFLUE and FinQA.
Where Pith is reading between the lines
- The multi-source automatic labeling approach could be adapted to create reliable supervision in other knowledge-intensive domains such as legal or medical reasoning.
- Combining rollout-based signals with explicit domain knowledge checks may reduce reliance on costly human annotations for new specialized tasks.
- The same trajectory-aware scoring could be tested for improving calibration and error detection in non-financial structured reasoning problems.
Load-bearing premise
Automatically derived labels from Monte Carlo rollouts, LLM evaluation, and financial knowledge verification produce reliable step and trajectory supervision without systematic bias or circularity.
What would settle it
Human experts rating a random sample of the auto-labeled trajectories and finding frequent errors in step correctness, or a replication experiment in which Fin-PRM shows no advantage or underperforms general PRMs on the same benchmarks.
Figures



read the original abstract
Process Reward Models (PRMs) supervise intermediate reasoning steps in large language models (LLMs), but existing PRMs are mainly trained on general-domain data and struggle with the structured, symbolic, and fact-sensitive nature of financial reasoning. Financial tasks require not only correct final answers but also verifiable intermediate steps grounded in domain knowledge. In this paper, we propose Fin-PRM, a domain-specialized, trajectory-aware PRM for financial reasoning that jointly models step-level correctness and trajectory-level coherence, producing binary supervision signals for both local and global reasoning quality. To support reliable supervision, we construct a high-quality financial reasoning dataset of 3K trajectories, where step- and trajectory-level labels are automatically derived from multi-source reward signals, including Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification. Fin-PRM defines a unified ranking score that integrates step- and trajectory-level rewards, enabling consistent use across multiple settings. We evaluate Fin-PRM in three scenarios: (1) offline trajectory selection for supervised fine-tuning, (2) reward-guided Best-of-$N$ inference for test-time scaling, and (3) process-aware reward shaping for reinforcement learning. Experiments on financial reasoning benchmarks, including CFLUE and FinQA, show that Fin-PRM consistently outperforms general-purpose PRMs and strong baselines. Our project resources will be available at https://github.com/aliyun/qwen-dianjin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Fin-PRM, a domain-specialized process reward model for financial reasoning in LLMs. It constructs a 3K-trajectory dataset with step- and trajectory-level binary labels automatically derived from Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification. A unified ranking score is defined, and the model is evaluated in three settings: offline trajectory selection for SFT, reward-guided Best-of-N inference, and process-aware reward shaping for RL. Experiments on CFLUE and FinQA benchmarks claim consistent outperformance over general-purpose PRMs and baselines.
Significance. If the multi-source labeling produces reliable, unbiased supervision independent of the target models, this could meaningfully advance process supervision for structured, fact-sensitive domains like finance. The three-scenario evaluation and planned resource release strengthen potential utility and reproducibility.
major comments (2)
- [Dataset construction] Dataset construction (abstract and §3): no quantitative validation is reported for the automatic labeling pipeline, such as human agreement rates, error rates on the 3K trajectories, or ablation results isolating the contribution of Monte Carlo rollouts versus LLM evaluation versus knowledge verification. This directly undermines confidence in the binary supervision signals that support all three evaluation scenarios.
- [Labeling process] Labeling process (abstract): the description of labels derived from LLM-based evaluation and Monte Carlo rollouts does not address potential circularity when the evaluator models share architecture, training data, or prompting style with the base models used in the CFLUE/FinQA experiments. This is load-bearing because the central outperformance claim rests on the independence of the supervision signal.
minor comments (1)
- [Abstract] The abstract states that project resources will be available at the GitHub link but does not enumerate exactly which artifacts (dataset, code, trained model) will be released.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction (abstract and §3): no quantitative validation is reported for the automatic labeling pipeline, such as human agreement rates, error rates on the 3K trajectories, or ablation results isolating the contribution of Monte Carlo rollouts versus LLM evaluation versus knowledge verification. This directly undermines confidence in the binary supervision signals that support all three evaluation scenarios.
Authors: We agree that the absence of quantitative validation for the automatic labeling pipeline is a limitation that reduces confidence in the reported supervision signals. In the revised manuscript we will add a human evaluation on a random subset of 200 trajectories, reporting inter-annotator agreement and estimated error rates. We will also include ablation studies that measure the incremental contribution of Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification to the final Fin-PRM performance. These additions will be placed in a new subsection of §3. revision: yes
-
Referee: [Labeling process] Labeling process (abstract): the description of labels derived from LLM-based evaluation and Monte Carlo rollouts does not address potential circularity when the evaluator models share architecture, training data, or prompting style with the base models used in the CFLUE/FinQA experiments. This is load-bearing because the central outperformance claim rests on the independence of the supervision signal.
Authors: We acknowledge that the current description does not explicitly discuss independence between the labeling models and the downstream evaluation models. The multi-source pipeline combines Monte Carlo outcome rollouts (which depend only on final-answer correctness) with explicit financial knowledge verification that uses rule-based fact checking rather than LLM judgments. The LLM component uses a model prompted with domain-specific financial instructions that differ from the general-purpose prompting used in the CFLUE and FinQA experiments. We will expand §3 to detail the specific models, prompting strategies, and verification rules employed, thereby clarifying how the supervision signal remains independent of the target models. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs a 3K-trajectory dataset with step- and trajectory-level binary labels derived from multi-source signals (Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification). Fin-PRM is then trained on these labels to produce a unified ranking score, which is applied in offline selection, Best-of-N, and RL shaping. Evaluation occurs on external benchmarks (CFLUE, FinQA) against general-purpose PRMs and baselines. No equations or steps reduce the claimed outperformance to the labeling inputs by construction, no self-citation chains justify core premises, and no ansatz or uniqueness result is smuggled in. The supervision pipeline is presented as independent domain-specific construction rather than a definitional loop or fitted-input renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-source automatic labeling (Monte Carlo rollouts + LLM evaluation + explicit financial knowledge verification) produces reliable step- and trajectory-level binary labels.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a high-quality financial reasoning dataset of 3K trajectories, where step- and trajectory-level labels are automatically derived from multi-source reward signals, including Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltotal = Lstep + λ · Ltraj … LBCE(Rϕ, L) = −[L log σ(Rϕ) + (1−L) log(1−σ(Rϕ))]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
DataPRM is a new process reward model for data analysis agents that detects silent errors via environment interaction and ternary rewards, yielding 7-11% gains on benchmarks and further RL improvements.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; Joseph, N.; Kadavath, S.; Kernion, J.; Conerly, T.; El-Showk, S.; Elhage, N.; Hatfield-Dodds, Z.; Hernandez, D.; Hume, T.; Johnston, S.; Kravec, S.; Lovitt, L.; Nanda, N.; Olsson, C.; Amodei, D.; Brown, T.; Clark, J.; McCandlish, S.; Olah, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Cui, G.; Yuan, L.; Wang, Z.; Wang, H.; Li, W.; He, B.; Fan, Y.; Yu, T.; Xu, Q.; Chen, W.; Yuan, J.; Chen, H.; Zhang, K.; Lv, X.; Wang, S.; Yao, Y.; Han, X.; Peng, H.; Cheng, Y.; Liu, Z.; Sun, M.; Zhou, B.; and Ding, N. 2025. Process Reinforcement through Implicit Rewards. arXiv:2502.01456
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; Zhang, X.; Yu, X.; Wu, Y.; Wu, Z. F.; Gou, Z.; Shao, Z.; Li, Z.; Gao, Z.; Liu, A.; Xue, B.; Wang, B.; Wu, B.; Feng, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; Dai, D.; Chen, D.; Ji, D.; Li, E.; Lin, F.; Dai, F.; Luo, F.; Hao, G.; Chen, G.; ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Gu, J.; Jiang, X.; Shi, Z.; Tan, H.; Zhai, X.; Xu, C.; Li, W.; Shen, Y.; Ma, S.; Liu, H.; Wang, S.; Zhang, K.; Wang, Y.; Gao, W.; Ni, L.; and Guo, J. 2025. A Survey on LLM-as-a-Judge. arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Guha, E.; Marten, R.; Keh, S.; Raoof, N.; Smyrnis, G.; Bansal, H.; Nezhurina, M.; Mercat, J.; Vu, T.; Sprague, Z.; Suvarna, A.; Feuer, B.; Chen, L.; Khan, Z.; Frankel, E.; Grover, S.; Choi, C.; Muennighoff, N.; Su, S.; Zhao, W.; Yang, J.; Pimpalgaonkar, S.; Sharma, K.; Ji, C. C.-J.; Deng, Y.; Pratt, S.; Ramanujan, V.; Saad-Falcon, J.; Li, J.; Dave, A.; Al...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gunasekar, S.; Zhang, Y.; Aneja, J.; Mendes, C. C. T.; Giorno, A. D.; Gopi, S.; Javaheripi, M.; Kauffmann, P.; de Rosa, G.; Saarikivi, O.; Salim, A.; Shah, S.; Behl, H. S.; Wang, X.; Bubeck, S.; Eldan, R.; Kalai, A. T.; Lee, Y. T.; and Li, Y. 2023. Textbooks Are All You Need. arXiv:2306.11644
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Y.; Zeng, L.; Wang, X.; Wang, B.; Li, Y.; Zhang, F.; Xu, J.; An, B.; Liu, Y.; and Zhou, Y
He, J.; Wei, T.; Yan, R.; Liu, J.; Wang, C.; Gan, Y.; Tu, S.; Liu, C. Y.; Zeng, L.; Wang, X.; Wang, B.; Li, Y.; Zhang, F.; Xu, J.; An, B.; Liu, Y.; and Zhou, Y. 2024. Skywork-o1 Open Series. https://huggingface.co/Skywork
work page 2024
- [10]
-
[12]
Lightman, H.; Kosaraju, V.; Burda, Y.; Edwards, H.; Baker, B.; Lee, T.; Leike, J.; Schulman, J.; Sutskever, I.; and Cobbe, K. 2023 b . Let's Verify Step by Step. arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Luo, H.; Sun, Q.; Xu, C.; Zhao, P.; Lou, J.; Tao, C.; Geng, X.; Lin, Q.; Chen, S.; Tang, Y.; and Zhang, D. 2025. WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct. arXiv:2308.09583
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Muennighoff, N.; Yang, Z.; Shi, W.; Li, X. L.; Fei-Fei, L.; Hajishirzi, H.; Zettlemoyer, L.; Liang, P.; Candès, E.; and Hashimoto, T. 2025. s1: Simple test-time scaling. arXiv:2501.19393
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Mukherjee, S.; Mitra, A.; Jawahar, G.; Agarwal, S.; Palangi, H.; and Awadallah, A. 2023. Orca: Progressive Learning from Complex Explanation Traces of GPT-4. arXiv:2306.02707
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Setlur, A.; Nagpal, C.; Fisch, A.; Geng, X.; Eisenstein, J.; Agarwal, R.; Agarwal, A.; Berant, J.; and Kumar, A. 2024. Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. arXiv:2410.08146
work page internal anchor Pith review arXiv 2024
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y. K.; Wu, Y.; and Guo, D. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Snell, C.; Lee, J.; Xu, K.; and Kumar, A. 2024. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv:2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Uesato, J.; Kushman, N.; Kumar, R.; Song, F.; Siegel, N.; Wang, L.; Creswell, A.; Irving, G.; and Higgins, I. 2022. Solving math word problems with process- and outcome-based feedback. arXiv:2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Wang, P.; Li, L.; Shao, Z.; Xu, R. X.; Dai, D.; Li, Y.; Chen, D.; Wu, Y.; and Sui, Z. 2024. Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations. arXiv:2312.08935
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
- [23]
-
[24]
Le, Tengyu Ma, and Adams Wei Yu
Xie, S. M.; Pham, H.; Dong, X.; Du, N.; Liu, H.; Lu, Y.; Liang, P.; Le, Q. V.; Ma, T.; and Yu, A. W. 2023. DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining. arXiv:2305.10429
- [25]
-
[26]
Ye, Y.; Huang, Z.; Xiao, Y.; Chern, E.; Xia, S.; and Liu, P. 2025. LIMO: Less is More for Reasoning. arXiv:2502.03387
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Yu, L.; Jiang, W.; Shi, H.; Yu, J.; Liu, Z.; Zhang, Y.; Kwok, J. T.; Li, Z.; Weller, A.; and Liu, W. 2024. MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models. arXiv:2309.12284
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Zhang, K.; Zhang, J.; Li, H.; Zhu, X.; Hua, E.; Lv, X.; Ding, N.; Qi, B.; and Zhou, B. 2024. OpenPRM: Building Open-domain Process-based Reward Models with Preference Trees. ICLR 2024
work page 2024
-
[29]
Zhang, Z.; Zheng, C.; Wu, Y.; Zhang, B.; Lin, R.; Yu, B.; Liu, D.; Zhou, J.; and Lin, J. 2025. The Lessons of Developing Process Reward Models in Mathematical Reasoning. arXiv:2501.07301
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E. P.; Zhang, H.; Gonzalez, J. E.; and Stoica, I. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [31]
-
[32]
Zhu, J.; Li, J.; Wen, Y.; and Guo, L. 2024. Benchmarking Large Language Models on CFLUE - A C hinese Financial Language Understanding Evaluation Dataset. In Ku, L.-W.; Martins, A.; and Srikumar, V., eds., Findings of the Association for Computational Linguistics: ACL 2024, 5673--5693. Bangkok, Thailand: Association for Computational Linguistics
work page 2024
- [33]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.