AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving
Pith reviewed 2026-05-18 20:16 UTC · model grok-4.3
The pith
A VLA framework for autonomous driving gains better reasoning by using chain-of-thought processing and self-reflection during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
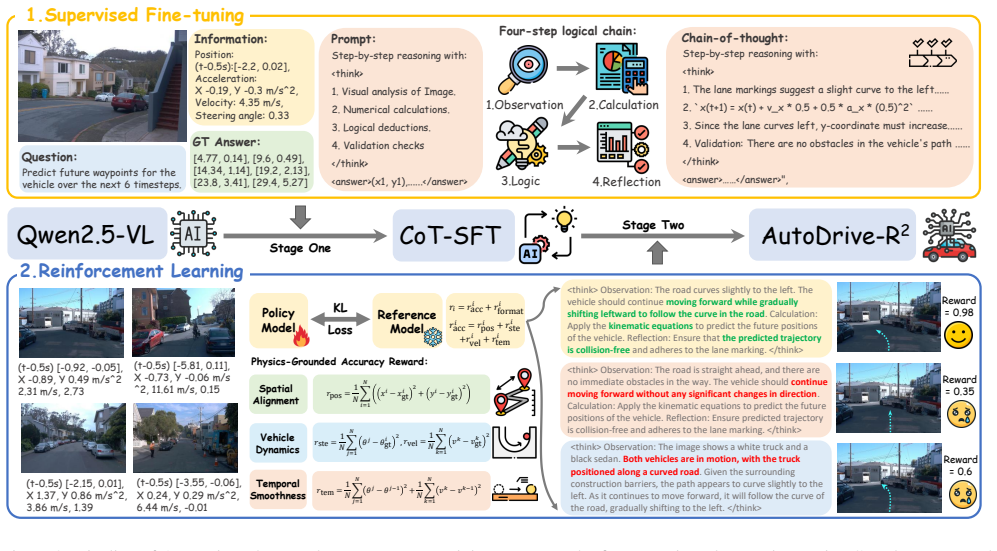
The central discovery is that fine-tuning on the nuScenesR²-6K dataset, which uses a four-step logical chain with self-reflection for validation, followed by optimization using the Group Relative Policy Optimization algorithm in a physics-grounded reward framework that includes spatial alignment, vehicle dynamics, and temporal smoothness, enables VLA models to achieve state-of-the-art performance and robust generalization on both nuScenes and Waymo datasets.
What carries the argument
The four-step logical chain with self-reflection in the nuScenesR²-6K dataset combined with Group Relative Policy Optimization under physics-grounded rewards for trajectory planning.
Load-bearing premise
The four-step logical chain with self-reflection builds real cognitive connections between perception and safe driving actions, while the physics rewards accurately reflect what makes trajectories feasible and safe in practice.
What would settle it
Running the trained model on a set of edge-case scenarios involving potential hazards and checking if it generates fewer invalid or unsafe trajectories than versions without the self-reflection step or the specific rewards.
Figures






read the original abstract
Vision-Language-Action (VLA) models in autonomous driving systems have recently demonstrated transformative potential by integrating multimodal perception with decision-making capabilities. However, the interpretability and coherence of the decision process and the plausibility of action sequences remain largely underexplored. To address these issues, we propose AutoDrive-R$^2$, a novel VLA framework that enhances both reasoning and self-reflection capabilities of autonomous driving systems through chain-of-thought (CoT) processing and reinforcement learning (RL). Specifically, we first propose an innovative CoT dataset named nuScenesR$^2$-6K for supervised fine-tuning, which effectively builds cognitive bridges between input information and output trajectories through a four-step logical chain with self-reflection for validation. Moreover, to maximize both reasoning and self-reflection during the RL stage, we further employ the Group Relative Policy Optimization (GRPO) algorithm within a physics-grounded reward framework that incorporates spatial alignment, vehicle dynamic, and temporal smoothness criteria to ensure reliable and realistic trajectory planning. Extensive evaluation results across both nuScenes and Waymo datasets demonstrates the state-of-the-art performance and robust generalization capacity of our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AutoDrive-R², a Vision-Language-Action (VLA) framework for autonomous driving that integrates chain-of-thought (CoT) processing with self-reflection via a new nuScenesR²-6K dataset for supervised fine-tuning (using a four-step logical chain) and Group Relative Policy Optimization (GRPO) reinforcement learning with a physics-grounded reward model incorporating spatial alignment, vehicle dynamics, and temporal smoothness criteria. It reports state-of-the-art performance and robust generalization on nuScenes and Waymo datasets.
Significance. If the central claims hold after proper verification, the work could meaningfully advance VLA models for autonomous driving by explicitly incentivizing interpretable reasoning and self-reflection, potentially leading to more coherent and safer trajectory outputs than standard end-to-end approaches. The combination of a specialized CoT dataset and physics-informed rewards is a promising direction for addressing plausibility issues in decision-making.
major comments (2)
- [Evaluation] Evaluation section: The manuscript asserts state-of-the-art performance and robust generalization across nuScenes and Waymo, yet the abstract and evaluation description provide no quantitative tables, ablation studies isolating the contribution of the four-step CoT self-reflection step, closed-loop simulation results, or direct comparisons against recent VLA baselines trained on equivalent data volumes. Without these, it is impossible to establish that the reported gains arise from the proposed reasoning mechanisms rather than dataset scale or base model capacity.
- [Reward Framework] Reward framework (physics-grounded terms): The reward function combines spatial alignment, vehicle dynamics, and temporal smoothness, but the weights for these terms are not shown to have been derived independently of the nuScenes/Waymo evaluation splits. If any tuning occurred on the same data used for final reporting, the performance numbers risk partial circularity, weakening the claim that the rewards ensure reliable real-world safety and feasibility.
minor comments (1)
- [Abstract] Abstract: The phrase 'Extensive evaluation results' is used without any accompanying metrics, baseline names, or improvement deltas, which reduces immediate readability and makes it harder for readers to gauge the scale of the claimed advances.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for major revision. We have addressed each of the major comments in detail below and revised the manuscript to include the requested clarifications, additional experiments, and explanations to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript asserts state-of-the-art performance and robust generalization across nuScenes and Waymo, yet the abstract and evaluation description provide no quantitative tables, ablation studies isolating the contribution of the four-step CoT self-reflection step, closed-loop simulation results, or direct comparisons against recent VLA baselines trained on equivalent data volumes. Without these, it is impossible to establish that the reported gains arise from the proposed reasoning mechanisms rather than dataset scale or base model capacity.
Authors: We agree that these additional elements are necessary to rigorously substantiate the claims. In the revised manuscript, we have incorporated quantitative tables with direct comparisons against recent VLA baselines trained on comparable data volumes. We have added ablation studies that isolate the contribution of the four-step CoT self-reflection mechanism. We also include closed-loop simulation results on both nuScenes and Waymo to demonstrate practical generalization and safety. These changes clarify that the observed gains derive from the proposed reasoning and self-reflection components rather than data scale or base model alone. revision: yes
-
Referee: [Reward Framework] Reward framework (physics-grounded terms): The reward function combines spatial alignment, vehicle dynamics, and temporal smoothness, but the weights for these terms are not shown to have been derived independently of the nuScenes/Waymo evaluation splits. If any tuning occurred on the same data used for final reporting, the performance numbers risk partial circularity, weakening the claim that the rewards ensure reliable real-world safety and feasibility.
Authors: We thank the referee for highlighting this potential issue of circularity. The reward weights were determined using physical principles and a separate held-out validation subset drawn from the training data, with no overlap to the final nuScenes or Waymo evaluation splits. In the revised manuscript, we have expanded the reward framework section to explicitly describe this independent tuning procedure, including the validation protocol used. This addition removes any ambiguity and supports the reliability of the physics-grounded rewards for real-world safety and feasibility. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained against external benchmarks
full rationale
The paper constructs a custom CoT dataset (nuScenesR²-6K) via a four-step logical chain, applies GRPO under explicitly physics-grounded reward terms (spatial alignment, vehicle dynamics, temporal smoothness), and reports open-loop metrics on nuScenes and Waymo. None of these steps reduce by construction to the reported performance numbers: the reward criteria are presented as independent physical priors rather than fitted parameters, the evaluation splits are standard public benchmarks, and no load-bearing self-citation or uniqueness theorem is invoked to force the outcome. The central claims therefore rest on empirical comparison rather than definitional equivalence or statistical forcing.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward weights for spatial alignment, dynamics, and smoothness
axioms (1)
- domain assumption The four-step logical chain with self-reflection produces trajectories that are more coherent and plausible than direct mapping from perception to action.
Forward citations
Cited by 14 Pith papers
-
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
MindVLA-U1 introduces a unified streaming VLA with shared backbone, framewise memory, and language-guided action diffusion that surpasses human drivers on WOD-E2E planning metrics.
-
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
ConeSep tackles noisy triplet correspondences in composed image retrieval by introducing geometric fidelity quantization to locate noise, negative boundary learning for semantic opposites, and targeted unlearning via ...
-
Learning Vision-Language-Action World Models for Autonomous Driving
VLA-World improves autonomous driving by using action-guided future image generation followed by reflective reasoning over the imagined scene to refine trajectories.
-
The Blind Spot of Adaptation: Quantifying and Mitigating Forgetting in Fine-tuned Driving Models
Fine-tuning VLMs for driving erodes pre-trained world knowledge, but shifting adaptation to prompt space via the Drive Expert Adapter preserves generalization while improving task performance.
-
Learning Physics from Pretrained Video Models: A Multimodal Continuous and Sequential World Interaction Models for Robotic Manipulation
PhysGen uses video models to learn physics for robots, outperforming baselines by up to 13.8% on Libero and matching specialized models in real-world tasks.
-
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
MindVLA-U1 is the first unified streaming VLA architecture that surpasses human drivers on WOD-E2E planning metrics while matching VA latency and preserving language interfaces.
-
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval
Air-Know decouples MLLM-based external arbitration from proxy learning via knowledge internalization and dual-stream training to overcome noisy triplet correspondence in composed image retrieval.
-
Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
Alpamayo-R1 introduces a VLA model with a Chain of Causation dataset and multi-stage SFT-plus-RL training that reports 12% better planning accuracy and 35% fewer close encounters versus trajectory-only baselines in dr...
-
IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
IndusAgent achieves state-of-the-art zero-shot performance on industrial anomaly benchmarks by using a custom Indus-CoT dataset, dynamic tool orchestration, and gated RL to optimize anomaly classification, localizatio...
-
EponaV2: Driving World Model with Comprehensive Future Reasoning
EponaV2 advances perception-free driving world models by forecasting comprehensive future 3D geometry and semantic representations, achieving SOTA planning performance on NAVSIM benchmarks.
-
Causality-Aware End-to-End Autonomous Driving via Ego-Centric Joint Scene Modeling
CaAD adds ego-centric joint-causal modeling and causality-aware policy alignment to end-to-end driving, reporting Driving Score 87.53 and Success Rate 71.81 on Bench2Drive plus PDMS 91.1 on NAVSIM.
-
Causality-Aware End-to-End Autonomous Driving via Ego-Centric Joint Scene Modeling
CaAD adds ego-centric joint-causal modeling and causality-aware policy alignment to end-to-end driving, reporting Driving Score 87.53 and PDMS 91.1 on Bench2Drive and NAVSIM.
-
Latency Analysis and Optimization of Alpamayo 1 via Efficient Trajectory Generation
Redesigning Alpamayo 1 to single-reasoning and optimizing diffusion action generation cuts inference latency by 69.23% while preserving trajectory diversity and prediction quality.
-
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
A survey of physical AI that distinguishes theoretical physics reasoning from applied understanding and synthesizes advances in symbolic reasoning, embodied systems, and generative models to advocate for physics-groun...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, and et al. Gpt-4 technical report, 2024. 3
work page 2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A visi...
work page 2024
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz...
work page 2020
-
[5]
Long Chen, Lukas Platinsky, Stefanie Speichert, Bła ˙zej Osi´nski, Oliver Scheel, Yawei Ye, Hugo Grimmett, Luca Del Pero, and Peter Ondruska. What data do we need for training an av motion planner? In2021 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 1066–1072. IEEE, 2021. 2
work page 2021
-
[6]
Rui Chen, Lei Sun, Jing Tang, Geng Li, and Xiangxi- ang Chu. Finger: Content aware fine-grained evaluation with reasoning for ai-generated videos.arXiv preprint arXiv:2504.10358, 2025. 3
-
[7]
Vadv2: End-to-end vectorized autonomous driving via probabilistic planning, 2024
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning, 2024. 2, 3
work page 2024
-
[8]
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Xiangxiang Chu, Limeng Qiao, Xinyang Lin, Shuang Xu, Yang Yang, Yiming Hu, Fei Wei, Xinyu Zhang, Bo Zhang, Xiaolin Wei, et al. Mobilevlm: A fast, strong and open vi- sion language assistant for mobile devices.arXiv preprint arXiv:2312.16886, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
arXiv preprint arXiv:2504.02546 , year=
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. Gpg: A simple and strong reinforce- ment learning baseline for model reasoning.arXiv preprint arXiv:2504.02546, 2025. 3
-
[10]
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, and et al. Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025. 3, 4
work page 2025
-
[11]
Planning-oriented autonomous driv- ing
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driv- ing. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17853–17862, 2023. 2
work page 2023
-
[12]
Drivemm: All-in-one large multimodal model for autonomous driving,
Zhijian Huang, Chengjian Fen, Feng Yan, Baihui Xiao, Ze- qun Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Drivemm: All-in-one large multimodal model for autonomous driving. arXiv preprint arXiv:2412.07689, 2024. 3
-
[13]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. In2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 8306–8316, 2023. 2, 3
work page 2023
-
[14]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xing- gang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reason- ing, 2025. 5
work page 2025
-
[15]
Alex Kendall, Jeffrey Hawke, David Janz, Przemyslaw Mazur, Daniele Reda, John-Mark Allen, Vinh-Dieu Lam, Alex Bewley, and Amar Shah. Learning to drive in a day. In2019 International Conference on Robotics and Automa- tion (ICRA), pages 8248–8254. IEEE, 2019. 2
work page 2019
-
[16]
Reinforcement learning from human feed- back, 2025
Nathan Lambert. Reinforcement learning from human feed- back, 2025. 3
work page 2025
-
[17]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceed- ings of the 39th International Conference on Machine Learn- ing, pages 12888–12900. PMLR, 2022. 3
work page 2022
-
[18]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InPro- ceedings of the 40th International Conference on Machine Learning, pages 19730–19742. PMLR, 2023. 3
work page 2023
-
[19]
Deepseek-v3 technical report, 2025
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, and et al. Deepseek-v3 technical report, 2025. 3
work page 2025
-
[20]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 3
work page 2023
-
[21]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 3
work page 2021
-
[22]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728–53741, 2023. 3
work page 2023
-
[23]
Proximal policy optimization algo- rithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms, 2017. 3
work page 2017
-
[24]
Waslander, Yu Liu, and Hongsheng Li
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L. Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. In2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 15120–15130, 2024. 2, 3
work page 2024
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Sparsedrive: End-to-end au- tonomous driving via sparse scene representation, 2024
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Hao- ran Wu, and Sifa Zheng. Sparsedrive: End-to-end au- tonomous driving via sparse scene representation, 2024. 2
work page 2024
-
[27]
Drivevlm: The convergence of autonomous driving and large vision-language models, 2024
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models, 2024. 2, 3
work page 2024
-
[28]
Llama: Open and efficient foundation lan- guage models, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aure- lien Rodriguez, Armand Joulin, Edouard Grave, and Guil- laume Lample. Llama: Open and efficient foundation lan- guage models, 2023. 3
work page 2023
-
[29]
Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, Hao Tian, Lewei Lu, Xizhou Zhu, Xiaogang Wang, Yu Qiao, and Jifeng Dai. Drivemlm: Aligning multi- modal large language models with behavioral planning states for autonomous driving, 2023. 2, 3
work page 2023
-
[30]
Omni- gen2: Exploration to advanced multimodal generation, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Jun- jie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jia- hao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omni- gen2: Exploration to advanced multimodal generation, 2025. 3
work page 2025
-
[31]
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Let- ters, 2024. 3
work page 2024
-
[32]
Zhenjie Yang, Yilin Chai, Xiaosong Jia, Qifeng Li, Yuqian Shao, Xuekai Zhu, Haisheng Su, and Junchi Yan. Drivemoe: Mixture-of-experts for vision-language-action model in end- to-end autonomous driving, 2025. 2, 3
work page 2025
-
[33]
Fusionad: Multi-modality fusion for predic- tion and planning tasks of autonomous driving, 2023
Tengju Ye, Wei Jing, Chunyong Hu, Shikun Huang, Ling- ping Gao, Fangzhen Li, Jingke Wang, Ke Guo, Wencong Xiao, Weibo Mao, Hang Zheng, Kun Li, Junbo Chen, and Kaicheng Yu. Fusionad: Multi-modality fusion for predic- tion and planning tasks of autonomous driving, 2023. 3
work page 2023
-
[34]
Vasilakos, and Thippa Reddy Gadekallu
Gokul Yenduri, Ramalingam M, Chemmalar Selvi G, Supriya Y , Gautam Srivastava, Praveen Kumar Reddy Mad- dikunta, Deepti Raj G, Rutvij H Jhaveri, Prabadevi B, Weizheng Wang, Athanasios V . Vasilakos, and Thippa Reddy Gadekallu. Generative pre-trained trans- former: A comprehensive review on enabling technologies, potential applications, emerging challenges...
work page 2023
-
[35]
Scaling relationship on learning mathematical reasoning with large language models, 2023
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models, 2023. 3
work page 2023
-
[36]
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, and Alois C. Knoll. Opendrivevla: Towards end-to-end au- tonomous driving with large vision language action model,
-
[37]
Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning, 2025. 2, 3
work page 2025
-
[38]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 3 AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving Supplementary Material A. Summary This supplementary ma...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.