TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
Pith reviewed 2026-05-16 17:46 UTC · model grok-4.3
The pith
TiMem organizes conversation histories into a temporal memory tree to reach higher accuracy with 52 percent shorter recalled memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
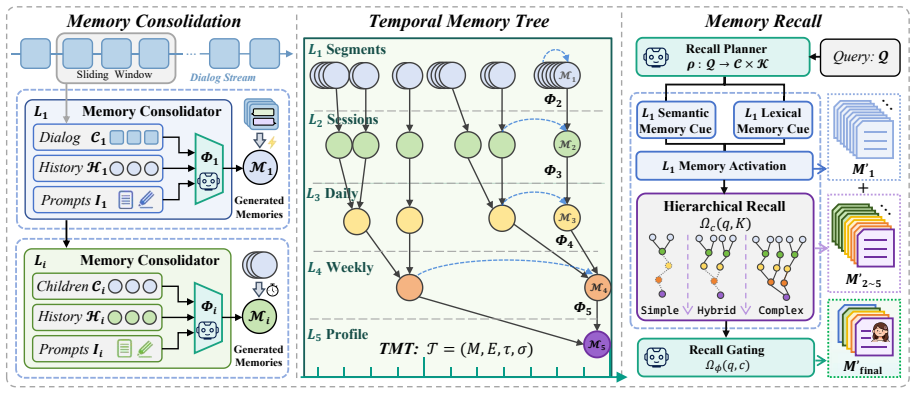
TiMem organizes conversations through a Temporal Memory Tree that enables systematic consolidation from raw observations to abstracted persona representations, using semantic-guided integration across hierarchical levels without fine-tuning and complexity-aware recall that balances precision and efficiency for queries of varying depth, resulting in state-of-the-art accuracy on both benchmarks and a 52.20 percent reduction in recalled memory length on LoCoMo.
What carries the argument
The Temporal Memory Tree (TMT), which arranges memory in temporal-hierarchical levels to support semantic-guided consolidation and complexity-aware recall.
Load-bearing premise
Semantic-guided consolidation across temporal-hierarchical levels produces stable persona representations without any fine-tuning of the underlying language model.
What would settle it
If disabling the temporal hierarchy or semantic guidance causes accuracy to drop below all baselines on LoCoMo and LongMemEval-S while increasing recalled memory length, the central claim would be falsified.
Figures


read the original abstract
Long-horizon conversational agents have to manage ever-growing interaction histories that quickly exceed the finite context windows of large language models (LLMs). Existing memory frameworks provide limited support for temporally structured information across hierarchical levels, often leading to fragmented memories and unstable long-horizon personalization. We present TiMem, a temporal--hierarchical memory framework that organizes conversations through a Temporal Memory Tree (TMT), enabling systematic memory consolidation from raw conversational observations to progressively abstracted persona representations. TiMem is characterized by three core properties: (1) temporal--hierarchical organization through TMT; (2) semantic-guided consolidation that enables memory integration across hierarchical levels without fine-tuning; and (3) complexity-aware memory recall that balances precision and efficiency across queries of varying complexity. Under a consistent evaluation setup, TiMem achieves state-of-the-art accuracy on both benchmarks, reaching 75.30% on LoCoMo and 76.88% on LongMemEval-S. It outperforms all evaluated baselines while reducing the recalled memory length by 52.20% on LoCoMo. Manifold analysis indicates clear persona separation on LoCoMo and reduced dispersion on LongMemEval-S. Overall, TiMem treats temporal continuity as a first-class organizing principle for long-horizon memory in conversational agents. The code is available at https://github.com/TiMEM-AI/timem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TiMem, a temporal-hierarchical memory framework for long-horizon conversational agents organized around a Temporal Memory Tree (TMT). It claims three core properties—temporal-hierarchical organization, semantic-guided consolidation across levels without fine-tuning, and complexity-aware recall—and reports state-of-the-art accuracies of 75.30% on LoCoMo and 76.88% on LongMemEval-S while reducing recalled memory length by 52.20% on LoCoMo, with supporting manifold analysis of persona separation.
Significance. If the empirical claims hold under rigorous validation, TiMem would provide a structured alternative to flat or retrieval-only memory systems by elevating temporal continuity to a first-class principle, potentially improving long-horizon personalization and efficiency. The public release of code at https://github.com/TiMEM-AI/timem is a clear strength that supports reproducibility.
major comments (3)
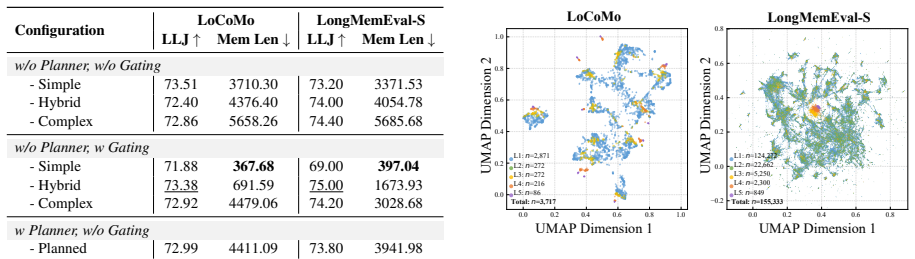
- [Evaluation] Evaluation section: the reported accuracies (75.30% LoCoMo, 76.88% LongMemEval-S) and memory reduction (52.20%) are given as single point estimates without error bars, standard deviations, or results from multiple independent runs, which is required to assess statistical significance given the stochastic LLM-based consolidation steps.
- [Method] Method description of semantic-guided consolidation: repeated LLM abstraction from raw turns to persona summaries at successive TMT levels is presented as producing stable representations without fine-tuning, yet no quantification of variance across temperatures, prompt paraphrases, or random seeds is supplied, leaving the robustness of the central stability claim unverified.
- [Experiments] Experiments: no ablation studies isolate the contributions of TMT hierarchy, semantic-guided consolidation, and complexity-aware recall, so it is impossible to determine whether the reported gains are attributable to the proposed framework or to other implementation choices.
minor comments (1)
- [Abstract] The abstract states that 'Manifold analysis indicates clear persona separation' but provides no corresponding figure, table, or quantitative metric (e.g., silhouette score) in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects of statistical rigor and experimental validation. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported accuracies (75.30% LoCoMo, 76.88% LongMemEval-S) and memory reduction (52.20%) are given as single point estimates without error bars, standard deviations, or results from multiple independent runs, which is required to assess statistical significance given the stochastic LLM-based consolidation steps.
Authors: We agree that single-point estimates are insufficient for assessing statistical significance in the presence of stochastic LLM components. In the revised manuscript, we will rerun all evaluations across 5 independent random seeds and report mean accuracies with standard deviations for both LoCoMo and LongMemEval-S, as well as for the recalled memory length reduction. This will be added to the Evaluation section. revision: yes
-
Referee: [Method] Method description of semantic-guided consolidation: repeated LLM abstraction from raw turns to persona summaries at successive TMT levels is presented as producing stable representations without fine-tuning, yet no quantification of variance across temperatures, prompt paraphrases, or random seeds is supplied, leaving the robustness of the central stability claim unverified.
Authors: We acknowledge the value of quantifying robustness for the stability claim. We will add a dedicated analysis subsection that measures variance in persona summary embeddings across temperatures (0.0, 0.5, 1.0), prompt paraphrases, and seeds, using metrics such as average pairwise cosine similarity. This will be included in the revised Experiments section to support the no-fine-tuning consolidation property. revision: yes
-
Referee: [Experiments] Experiments: no ablation studies isolate the contributions of TMT hierarchy, semantic-guided consolidation, and complexity-aware recall, so it is impossible to determine whether the reported gains are attributable to the proposed framework or to other implementation choices.
Authors: We agree that explicit ablations would better isolate component contributions. While baseline comparisons already contrast against flat and non-hierarchical systems, we will add three targeted ablations in the revised Experiments section: (1) flat memory without TMT hierarchy, (2) non-semantic (direct) consolidation, and (3) uniform rather than complexity-aware recall. Results will be reported on both benchmarks to attribute performance gains. revision: yes
Circularity Check
No circularity: TiMem is an independent engineering framework with empirical results
full rationale
The paper describes TiMem via a Temporal Memory Tree (TMT) with semantic-guided consolidation and complexity-aware recall as an engineering proposal for long-horizon memory. No equations, fitted parameters, or self-citations appear in the provided text that would reduce the claimed accuracies (75.30% LoCoMo, 76.88% LongMemEval-S) or memory reduction (52.20%) to inputs by construction. Results are presented as benchmark evaluations under a consistent setup, with no derivation chain that renames, fits, or self-defines the outputs from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic similarity between conversation segments can be reliably computed by an off-the-shelf embedding model without domain-specific calibration.
invented entities (1)
-
Temporal Memory Tree (TMT)
no independent evidence
Forward citations
Cited by 6 Pith papers
-
Recall Isn't Enough: Bounding Commitments in Personalized Language Systems
CBEA with LCV bounds evidence sets and validates commitments before response generation, achieving zero failures in scoped tests at 0.49-0.60 availability versus near-zero for baselines.
-
Four-Axis Decision Alignment for Long-Horizon Enterprise AI Agents
Long-horizon enterprise AI agents' decisions decompose into four measurable axes, with benchmark experiments on six memory architectures revealing distinct weaknesses and reversing a pre-registered prediction on summa...
-
SAGE: A Self-Evolving Agentic Graph-Memory Engine for Structure-Aware Associative Memory
SAGE is a self-evolving agentic graph-memory engine that dynamically constructs and refines structured memory graphs via writer-reader feedback, yielding performance gains on multi-hop QA, open-domain retrieval, and l...
-
Stateless Decision Memory for Enterprise AI Agents
Deterministic Projection Memory (DPM) delivers stateless, deterministic decision memory for enterprise AI agents that matches or exceeds summarization-based approaches at tight memory budgets while improving speed, de...
-
Synthius-Mem: Brain-Inspired Hallucination-Resistant Persona Memory Achieving 94.4% Memory Accuracy and 99.6% Adversarial Robustness on LoCoMo
Synthius-Mem achieves 94.37% accuracy and 99.55% adversarial robustness on LoCoMo by extracting and consolidating structured persona facts across six domains rather than retrieving dialogue segments.
-
Back to Basics: Let Conversational Agents Remember with Just Retrieval and Generation
A minimalist retrieval-and-generation framework using turn isolation and query-driven pruning outperforms complex memory systems by directly addressing signal sparsity and dual-level redundancy in dialogues.
Reference graph
Works this paper leans on
-
[1]
Zhengjun Huang, Zhoujin Tian, Qintian Guo, Fangyuan Zhang, Yingli Zhou, Di Jiang, and Xiaofang Zhou
Hmt: Hierarchical memory transformer for efficient long context language processing.Preprint, arXiv:2405.06067. Zhengjun Huang, Zhoujin Tian, Qintian Guo, Fangyuan Zhang, Yingli Zhou, Di Jiang, and Xiaofang Zhou
-
[2]
Lightweight and cognitive agentic memory for efficient long- term interaction,
Licomemory: Lightweight and cognitive agentic memory for efficient long-term reasoning. Preprint, arXiv:2511.01448. Kai Tzu iunn Ong, Namyoung Kim, Minju Gwak, Hyungjoo Chae, Taeyoon Kwon, Yohan Jo, Seung won Hwang, Dongha Lee, and Jinyoung Yeo. 2025. Towards lifelong dialogue agents via timeline-based memory management.Preprint, arXiv:2406.10996. Jiazhen...
-
[3]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Evaluating very long-term conversational memory of llm agents.Preprint, arXiv:2402.17753. James L McClelland, Bruce L McNaughton, and Ran- dall C O’Reilly. 1995. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connec- tionist models of learning and memory.Psychologi- cal review, 10...
work page internal anchor Pith review Pith/arXiv arXiv 1995
-
[4]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Nishant Patel and Apurv Patel. 2025. Engram: Effec- tive, lightweight memory orchestration for conversa- tional agents.Preprint, arXiv:2511.12960. Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiy...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms.Preprint, arXiv:2410.14052. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning
-
[6]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Raptor: Recursive abstractive processing for tree-organized retrieval.Preprint, arXiv:2401.18059. Larry R Squire, Lisa Genzel, John T Wixted, and Richard G Morris. 2015. Memory consolida- tion.Cold Spring Harbor perspectives in biology, 7(8):a021766. Haoran Sun, Zekun Zhang, and Shaoning Zeng. 2025. Preference-aware memory update for long-term llm agents....
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
Android in the zoo: Chain-of-action-thought for GUI agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12016–12031, Miami, Florida, USA. Association for Computational Linguistics. Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yi- jia Shao, Diyi Yang, Hamed Zamani, Franck Der- noncourt, Joe Barrow, Tong Yu, Sungchul Kim...
-
[8]
Recall Planner (1 LLM call) Predicts complexity c∈ {simple,hybrid, complex} and extracts keywords K to set level-specific budgets and search scope S(c)
-
[9]
Hierarchical Recall (no LLM calls) Leaf Activa- tion Score L1 leaves by s(m, q, K) =λs sem + (1−λ)s lex with λ=0.9 (cosine similarity + BM25), then select top-k1=20. Ancestor Col- lection For each activated leaf, collect ancestors whose levels satisfy ℓ(m)∈ S(c) (determin- istic traversal). Budgeting Keep up to:Simple( L1:20, L2:4, L5:1);Hy- brid( L1:20, ...
-
[10]
Recall Gating (1 LLM call) Prompt an LLM to retain/drop each candidate memory conditioned on (q, c), producing the final memory setΩ final. Table 6: Recall configuration in TiMem, organized by the three major stages: recall planner, hierarchical recall, and recall gating. C Parameter Studies C.1 LLM Configuration Analysis We investigate the interplay betw...
-
[11]
Through consolidation, spread reduces by 50% to reach 0.345 at L5, while the effective ra- dius (mean distance to centroid) shrinks from 0.789 to 0.444. Dimensionality remains saturated at 100 through L1-L4, then drops to 68 at L5, with the low- dimensional shared structure emerging through pro- gressive consolidation. D.3 Adaptive Consolidation TiMem dem...
work page 2025
-
[12]
Carefully analyze all provided memories from both speakers
-
[13]
Pay special attention to the timestamps to determine the answer
-
[14]
If the question asks about a specific event or fact, look for direct evidence in the memories
-
[15]
If the memories contain contradictory information, prioritize the most recent memory
- [16]
- [17]
-
[18]
Focus only on the content of the memories from both speakers. Do not confuse character names mentioned in memories with the actual users who created those memories
-
[19]
# APPROACH (Think step by step):
The answer should be less than 5-6 words. # APPROACH (Think step by step):
-
[20]
First, examine all memories that contain information related to the question
-
[21]
Examine the timestamps and content of these memories carefully
-
[22]
Look for explicit mentions of dates, times, locations, or events that answer the question
-
[23]
If the answer requires calculation (e.g., converting relative time references), show your work
-
[24]
Formulate a precise, concise answer based solely on the evidence in the memories
-
[25]
Double-check that your answer directly addresses the question asked
-
[26]
Ensure your final answer is specific and avoids vague time references Relevant Memories: {context_memories} Question: {question} Answer: E.1.2 LLM-as-Judge Evaluation Prompt Your task is to label an answer to a question as ’CORRECT’ or ’WRONG’. You will be given the following data: (1) a question (posed by one user to another user), (2) a ’gold’ (ground t...
work page 2025
-
[27]
KEEP if memory directly answers the question
-
[28]
KEEP if memory provides essential context (time/location of the fact)
-
[29]
EXCLUDE if related but does not contribute to answer
-
[30]
EXCLUDE if different topic entirely ## Instructions - Be strict: Only keep memories that help answer the specific question - Remove noise: Exclude tangentially related memories - Aim for 3-8 memories total Question: {question} Candidate memories ({total_count} total): {numbered_memories} Return IDs to keep (JSON format): {{"relevant_ids": [1, 2, 3, ...]}}...
-
[31]
First identify: Does the question require user’s preferences/habits/personality/values? If yes →Deep Retrieval (2)
-
[32]
Second identify: Does the question require reasoning/prediction/evaluation/subjective judgment? If yes→Deep Retrieval (2)
-
[33]
Third identify: Does the question require summarizing multiple fact fragments? If yes→Hybrid Retrieval (1)
-
[34]
Finally: If only single explicit fact needed→Simple Retrieval (0) Keyword extraction requirements:
-
[35]
Extract 1-3 most important keywords from the question
-
[36]
Exclude common stopwords (such as: the, a, in, is, have, and, or, with, etc.)
-
[37]
STRICTLY FORBIDDEN: Never include any personal names, usernames, or names
-
[38]
FOCUS ONLY ON: Action words, object names, location types, concept words, adjectives and other non-name key concepts Question: {question} Please carefully analyze the essential needs of the question and output in the following JSON format: {\n "complexity": 0/1/2,\n "keywords": ["keyword1", "keyword2", "keyword3"]\n } 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.