Pelican-Unify 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
Pith reviewed 2026-05-22 09:40 UTC · model grok-4.3
The pith
A single VLM with joint language-video-action losses and a future generator can match specialist performance on understanding, reasoning, and embodied action.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
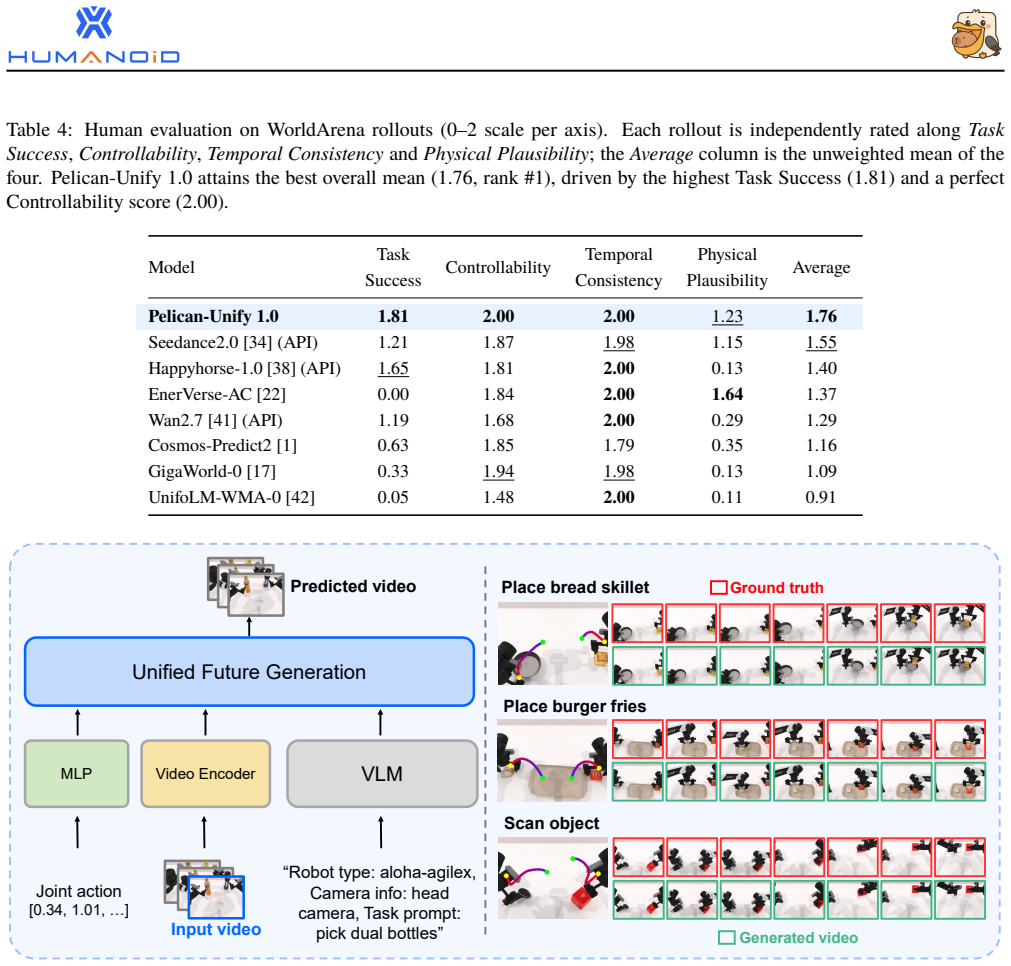
The paper establishes that a single VLM can act as unified understanding and reasoning module by mapping inputs into a shared semantic space and autoregressively generating chains of thought while projecting the final state to a latent; a Unified Future Generator then conditions on this latent to jointly generate future videos and future actions via modality-specific heads in one denoising process, with language, video, and action losses all back-propagated into the shared representation, allowing the model to reach 64.7 on VLM benchmarks, 66.03 on WorldArena (first), and 93.5 on RoboTwin (second-best) using one checkpoint.
What carries the argument
The Unified Future Generator (UFG) that takes the VLM's final hidden-state latent and produces future videos and actions through two modality-specific heads inside the same denoising process.
If this is right
- Embodied systems could replace separate perception, reasoning, and control modules with one jointly trained network.
- Planning in robots could directly use the model's generated future videos and actions for decision making.
- Training pipelines for embodied AI can focus on a single shared representation instead of staged specialist training.
- Performance on language and vision benchmarks can transfer to action generation without separate fine-tuning.
Where Pith is reading between the lines
- The approach may reduce overall system complexity and latency by eliminating hand-offs between separate models.
- Extending the joint denoising process to longer video horizons or additional sensor modalities could be tested directly on the same architecture.
- Real-world robot deployment would show whether the shared representation improves robustness to distribution shift compared with specialist stacks.
Load-bearing premise
Joint back-propagation of language, video, and action losses through one shared VLM representation is enough to couple understanding, reasoning, imagination, and action without creating performance trade-offs.
What would settle it
If independent specialist models trained on the same data volume and scale outperform the unified model on any of the reported VLM, WorldArena, or RoboTwin metrics, the claim that joint optimization avoids compromises would be refuted.
Figures







read the original abstract
We present Pelican-Unify 1.0, the first embodied foundation model trained according to the principle of unification. Pelican-Unify 1.0 uses a single VLM as a unified understanding module, mapping scenes, instructions, visual contexts, and action histories into a shared semantic space. The same VLM also serves as a unified reasoning module, autoregressively producing task-, action-, and future-oriented chains of thought in a single forward pass and projecting the final hidden state into a dense latent variable. A Unified Future Generator (UFG) then conditions on this latent variable and jointly generates future videos and future actions through two modality-specific output heads within the same denoising process. The language, video, and action losses are all backpropagated into the shared representation, enabling the model to jointly optimize understanding, reasoning, imagination, and action during training, rather than training three isolated expert systems. Experiments demonstrate that unification does not imply compromise. With a single checkpoint, Pelican-Unify 1.0 achieves strong performance across all three capabilities: 64.7 on eight VLM benchmarks, the best among comparable-scale models; 66.03 on WorldArena, ranking first; and 93.5 on RoboTwin, the second-best average among compared action methods. These results show that the unified paradigm succeeds in preserving specialist strength while bringing understanding, reasoning, imagination, and action into one model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pelican-Unify 1.0 as the first embodied foundation model trained under a unification principle. A single VLM serves as both the understanding module (mapping scenes, instructions, and histories into a shared semantic space) and the reasoning module (autoregressively generating task-, action-, and future-oriented chains of thought while projecting a final hidden state to a latent variable). A Unified Future Generator (UFG) then conditions on this latent to jointly generate future videos and actions via modality-specific heads in one denoising process. Language, video, and action losses are back-propagated into the shared VLM representation. The abstract reports that a single checkpoint achieves 64.7 on eight VLM benchmarks (best among comparable-scale models), 66.03 on WorldArena (rank 1), and 93.5 on RoboTwin (second-best average), concluding that unification preserves specialist strength without compromise.
Significance. If the unification mechanism and benchmark results can be rigorously verified, the work would constitute a meaningful advance in embodied AI by demonstrating that joint optimization of understanding, reasoning, imagination, and action within one model need not incur the performance trade-offs typical of multi-task or modular systems. It offers a concrete architectural path (shared VLM + UFG with joint loss back-propagation) toward more integrated robotic intelligence and challenges the prevailing specialist-model paradigm.
major comments (2)
- [Abstract] Abstract: The central claim that 64.7 constitutes 'the best among comparable-scale models' on VLM benchmarks cannot be evaluated because the manuscript reports neither the parameter count, layer count, hidden dimension, nor FLOPs for Pelican-Unify 1.0 nor for any baseline. Without this information the qualifier 'comparable-scale' is unverifiable and the assertion that unification avoids performance compromise rests on an uncheckable premise.
- [Abstract] Abstract / Experiments: The reported results (66.03 on WorldArena, 93.5 on RoboTwin) are presented without any description of the experimental protocol, baseline selection criteria, statistical significance tests, or ablation studies on the joint language-video-action loss. This absence prevents assessment of whether the numbers genuinely support the 'no compromise' conclusion or could arise from capacity differences or post-hoc selection.
minor comments (1)
- [Abstract] Abstract: The acronym 'UFG' is introduced without an inline expansion on first use, which reduces immediate readability for readers scanning the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that additional information on model scale and experimental rigor is required to fully substantiate the claims in the abstract. We address each major comment below and will incorporate the necessary revisions into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 64.7 constitutes 'the best among comparable-scale models' on VLM benchmarks cannot be evaluated because the manuscript reports neither the parameter count, layer count, hidden dimension, nor FLOPs for Pelican-Unify 1.0 nor for any baseline. Without this information the qualifier 'comparable-scale' is unverifiable and the assertion that unification avoids performance compromise rests on an uncheckable premise.
Authors: We agree that explicit model-scale specifications are essential for verifying the 'comparable-scale' qualifier. In the revised manuscript we will add a new table (or subsection within Experiments) that reports the exact parameter count, layer count, hidden dimension, and estimated FLOPs for Pelican-Unify 1.0 together with the corresponding figures for all VLM baselines. This addition will make the performance comparison directly verifiable and will strengthen the claim that unification preserves specialist-level results. revision: yes
-
Referee: [Abstract] Abstract / Experiments: The reported results (66.03 on WorldArena, 93.5 on RoboTwin) are presented without any description of the experimental protocol, baseline selection criteria, statistical significance tests, or ablation studies on the joint language-video-action loss. This absence prevents assessment of whether the numbers genuinely support the 'no compromise' conclusion or could arise from capacity differences or post-hoc selection.
Authors: We acknowledge that the current manuscript lacks sufficient detail on the evaluation setup. We will expand the Experiments section to include: (i) a complete description of the WorldArena and RoboTwin evaluation protocols, (ii) explicit criteria used to select the reported baselines, (iii) statistical significance results (standard deviations across multiple runs and p-values where applicable), and (iv) ablation studies that isolate the contribution of the joint language-video-action loss. These additions will allow readers to assess whether the observed performance truly reflects the benefits of unification rather than capacity or selection artifacts. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper describes an architecture (single VLM for understanding/reasoning plus UFG for joint video/action generation) and states that joint back-propagation of language/video/action losses couples the capabilities. The central claim that unification preserves specialist strength is supported by reported scores on independent external benchmarks (eight VLM benchmarks, WorldArena, RoboTwin). These are not shown to reduce to the model's own definitions or fitted parameters by construction; they are presented as measured outcomes. No equations, self-citations, or ansatzes in the provided text create a load-bearing circular reduction. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Unified Future Generator (UFG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The language, video, and action losses are all backpropagated into the shared representation, enabling the model to jointly optimize understanding, reasoning, imagination, and action during training
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A Unified Future Generator (UFG) then conditions on this latent variable and jointly generates future videos and future actions through two modality-specific output heads within the same denoising process
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified understanding, which embeds scenes, instructions, action histories, and visual contexts into a shared semantic space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N. Agarwal, A. Ali, M. Bala, Y. Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y. Chen, Y. Cui, Y. Ding, et al. Cosmos world foundation model platform for physical ai, 2025
work page 2025
-
[2]
A. Ali, J. Bai, M. Bala, Y. Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y.-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
S. Bai et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y. Feng, C. Xiang, Y. Rong, H. Zhao, H. Liu, Z. Su, L. Ma, H. Su, and J. Zhu. Motus: A unified latent action world model, 2025
work page 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
L. Chen, J. Li, X. Dong, P. Zhang, Y. Zang, Z. Chen, H. Duan, J. Wang, Y. Qiao, D. Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Y. Chen, R. Chen, D. Huo, Y. Yang, D. Qi, H. Liu, T. Lin, S. Zeng, J. Xiao, X. Chang, F. Xiong, X. Wei, Z. Ma, and M. Xu. Abot-physworld: Interactive world foundation model for robotic manipulation with physics alignment, 2026
work page 2026
- [8]
-
[9]
A. Clark. Whatever next? predictive brains, situated agents, and the future of cognitive science.Behavioral and brain sciences, 36(3):181–204, 2013
work page 2013
-
[10]
Clark.Surfing Uncertainty: Prediction, Action, and the Embodied Mind
A. Clark.Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Oxford University Press, Oxford, 2016
work page 2016
-
[11]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
S. Community. Starvla: A lego-like codebase for vision-language-action model developing.arXiv preprint arXiv:2604.05014, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [12]
-
[13]
Accessed: 2026-05-14
work page 2026
-
[14]
D. C. Dennett. The embodied mind: Cognitive science and human experience, 1993
work page 1993
-
[15]
L. Fan, Z. Xu, C. Cao, W. Zhang, M. Yuan, and J. Chen. Aim: Intent-aware unified world action modeling with spatial value maps.arXiv preprint arXiv:2604.11135, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
A. Figure. Helix: A vision-language-action model for generalist humanoid control, 2024
work page 2024
-
[17]
K. Friston. The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11(2):127–138, 2010
work page 2010
-
[18]
Gigaworld-0: World models as data engine to empower embodied ai, 2025
GigaAI. Gigaworld-0: World models as data engine to empower embodied ai, 2025
work page 2025
-
[19]
Y. Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation. In The Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[20]
G. Hesslow. Conscious thought as simulation of behaviour and perception.Trends in Cognitive Sciences, 6(6):242–247, 2002
work page 2002
-
[21]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
- [23]
- [24]
-
[25]
E. R. Kandel, J. D. Koester, S. H. Mack, and S. A. Siegelbaum.Principles of Neural Science. McGraw-Hill Education, New York, 6 edition, 2021. page 13 of 16
work page 2021
-
[26]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
J. Lee, J. Duan, H. Fang, Y. Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y. R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space, 2025
work page 2025
-
[28]
L. Li, Q. Zhang, Y. Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y. Shen, and Y. Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[30]
H. Luo, W. Zhang, Y. Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y. Fu, and Z. Lu. Being-h0.7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
L. Maes, Q. L. Lidec, D. Scieur, Y. LeCun, and R. Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
A. Masry, D. Long, J. Q. Tan, S. Joty, and E. Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, May 2022. Association for Computational Linguistics
work page 2022
- [33]
-
[34]
S. Miao, N. Feng, J. Wu, Y. Lin, X. He, D. Li, and M. Long. Jepa-vla: Video predictive embedding is needed for vla models, 2026
work page 2026
-
[35]
T. Seedance, D. Chen, L. Chen, X. Chen, Y. Chen, Z. Chen, Z. Chen, F. Cheng, T. Cheng, Y. Cheng, et al. Seedance 2.0: Advancing video generation for world complexity, 2026
work page 2026
-
[36]
Y. Shang, Z. Li, Y. Ma, W. Su, X. Jin, Z. Wang, L. Jin, X. Zhang, Y. Tang, H. Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[37]
H. Shen, T. Wu, Q. Han, Y. Hsieh, J. Wang, Y. Zhang, Y. Cheng, Z. Hao, Y. Ni, X. Wang, Z. Wan, K. Zhang, W. Xu, J. Xiong, P. Luo, W. Chen, C. Tao, Z. Mao, and N. Wong. Phyx: Does your model have the ”wits” for physical reasoning?, 2025
work page 2025
-
[38]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
H. Team. Happyhorse-1.0, 2026
work page 2026
-
[40]
M. Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, L. Liu, M. Cai, R. Cui, R. Zhao, R. Wang, S. Huang, Y. Feng, Y. Rong, Z. Wang, and J. Zhu. Motubrain: An advanced world action model for robot control, 2026
work page 2026
-
[41]
W. Team. Wan2.6: A state-of-the-art video generation model.WanAI:LeadingAIVideoGenerationModel, 2026. Accessed: 2026-05-14
work page 2026
-
[42]
W. Team. Wan2.7, 2026
work page 2026
-
[43]
Unifolm-wma-0: A world-model-action (wma) framework under unifolm family, 2025
Unitree. Unifolm-wma-0: A world-model-action (wma) framework under unifolm family, 2025
work page 2025
-
[44]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
W. Wu, F. Lu, Y. Wang, S. Yang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y. Wang, S. Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Y. Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y. Chen, D. Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y. Yang, W. Hong, X. Zhang, G. Feng, D. Yin, Y. Zhang, W. Wang, Y. Cheng, B. Xu, X. Gu, Y. Dong, and J. Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025
work page 2025
-
[48]
S. Ye, Y. Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y. L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. page 14 of 16
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
T. Yuan, Z. Dong, Y. Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
W. Yuan, J. Duan, V. Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision- language model for spatial affordance prediction for robotics, 2024
work page 2024
-
[51]
X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y. Liu, W. Huang, H. Sun, Y. Su, and W. Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of CVPR, 2024
work page 2024
-
[52]
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning, 2025
work page 2025
- [53]
-
[54]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y. Feng, Y. Zheng, J. Zou, Y. Chen, J. Zeng, T. Wang, Y.-Q. Zhang, J. Liu, and X. Zhan. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[55]
E. Zhou, J. An, C. Chi, Y. Han, S. Rong, C. Zhang, P. Wang, Z. Wang, T. Huang, L. Sheng, and S. Zhang. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics, 2026
work page 2026
-
[56]
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. page 15 of 16
work page 2023
-
[57]
Contributions Our contributors are organized based on their roles and magnitude of contribution. The final public release will replace the group-level placeholders below with individual names after internal approval. 6.1. Core Contributors Unified VLM and Action capability: Yi Zhang, Yinda Chen, Che Liu, Zeyuan Ding Unified World-model capability: Jin Xu,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.