To Be Multimodal or Not to Be: Query-Adaptive Audio-Visual Person Retrieval via Active Modality Detection
Pith reviewed 2026-06-28 02:07 UTC · model grok-4.3
The pith
A query-adaptive system detects active modalities via cross-modal score consistency to achieve higher person retrieval precision than fixed strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by using cross-modal score consistency to detect active modalities, a retrieval system can adaptively select whether to use audio, visual, or both, avoiding the noise introduced by fusing an absent modality. This adaptive framework achieves 89% accuracy in detecting active modalities and delivers 94.2% P@1 on the BBC Rewind corpus, outperforming unimodal and fixed fusion methods.
What carries the argument
Cross-modal score consistency, which measures agreement between rankings from audio and visual modalities to indicate if both are active for the query target.
If this is right
- The adaptive system recovers 64% of the gap to an oracle with ground-truth modality labels.
- It outperforms speaker-only (82.9%), face-only (93.4%), and fixed fusion (90.0%) approaches.
- Modality detection enables avoiding fusion when one modality is absent, preventing precision degradation.
- The method works on real broadcast videos where targets may be heard but unseen or seen but unheard.
Where Pith is reading between the lines
- This consistency-based detection could extend to other multimodal tasks where modality presence varies per query, such as image-text retrieval.
- Archive search systems could benefit from query-adaptive rather than global modality choices to handle diverse content.
- Testing the approach on additional corpora with known modality labels would confirm its generalizability beyond the BBC Rewind set.
Load-bearing premise
Cross-modal score consistency reliably indicates the presence or absence of a modality in real-world broadcast videos where targets may be heard but unseen, seen but unheard, or both.
What would settle it
A controlled test on videos with ground-truth labels for active modalities per target person, checking whether the consistency features still classify presence or absence at the claimed accuracy level.
Figures

read the original abstract
When retrieving a person from a video archive by voice and face, should the system be multimodal or not? In real-world broadcast archives, unlike curated benchmarks, a target may be heard but unseen, seen but unheard, or both. Fusing scores from an absent modality injects noise, degrading precision below the best unimodal system. We propose a query-adaptive framework that detects active modalities via cross-modal score consistency: when both modalities are active, files retrieved by one also score highly on the other; this agreement breaks down when a modality is absent. Classifiers driven by these cross-modal features achieve 89% detection accuracy. On the BBC Rewind corpus (with over 12,000 broadcast videos) the adaptive system attains 94.2% P@1, outperforming speaker-only (82.9%), face-only (93.4%), and fixed fusion (90.0%), recovering 64% of the gap to an oracle with ground-truth modality labels (96.6%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a query-adaptive audio-visual person retrieval framework that detects active modalities via cross-modal score consistency features. Classifiers trained on these features achieve 89% detection accuracy. On the BBC Rewind corpus (>12,000 broadcast videos), the adaptive system reports 94.2% P@1, outperforming speaker-only (82.9%), face-only (93.4%), and fixed fusion (90.0%) while recovering 64% of the gap to an oracle with ground-truth modality labels (96.6%).
Significance. If the detection mechanism holds, the work addresses a practical issue in real-world archives where targets may be heard but unseen or vice versa. Concrete performance numbers on a large broadcast corpus and explicit comparison to an oracle provide clear, falsifiable evidence of gains from avoiding noisy fusion. The cross-modal consistency signal offers a lightweight, training-free cue for adaptivity that could generalize beyond the reported setting.
major comments (1)
- [Abstract] Abstract: The reported 94.2% P@1 (vs. 93.4% face-only) depends on the claim that cross-modal score agreement reliably drops when a modality is absent. No analysis or ablation is described that tests whether shared training biases between speaker and face embeddings could produce spurious agreement for heard-but-unseen targets, which would make the consistency signal correlational rather than causal and undermine the adaptive improvement.
minor comments (1)
- The abstract states the corpus size and metric values but omits any mention of evaluation protocol, query construction, or how ground-truth modality labels were obtained for the oracle; adding one sentence would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 94.2% P@1 (vs. 93.4% face-only) depends on the claim that cross-modal score agreement reliably drops when a modality is absent. No analysis or ablation is described that tests whether shared training biases between speaker and face embeddings could produce spurious agreement for heard-but-unseen targets, which would make the consistency signal correlational rather than causal and undermine the adaptive improvement.
Authors: We agree that an explicit test isolating potential training biases would strengthen the causal interpretation of the consistency signal. The current manuscript supports the claim via the oracle gap recovery (64% of the 96.6%–82.9% gap closed) and the 89% detection accuracy, but does not contain a dedicated ablation on shared embedding biases. In revision we will add such an analysis (e.g., consistency scores computed with cross-dataset or frozen embeddings) to directly address this concern. revision: yes
Circularity Check
No circularity: empirical method with reported metrics
full rationale
The paper presents an empirical framework that trains classifiers on cross-modal score agreement features to detect active modalities, then applies the detector for adaptive fusion. All reported figures (89% detection accuracy, 94.2% P@1 on BBC Rewind, comparisons to unimodal and fixed-fusion baselines) are experimental outcomes on a held-out corpus rather than predictions derived from fitted parameters or self-referential definitions. No equations, uniqueness theorems, or ansatzes appear in the provided text; the central claim rests on measured retrieval performance, not on any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Person retrieval can exploit two complementary biomet- ric modalities: speaker voice via speaker embeddings [5, 6, 7] and facial appearance via face embeddings [8, 9]
Introduction Locating a specific individual across a large-scale video archive is critical for journalism, forensics, and media indexing [1, 2, 3, 4]. Person retrieval can exploit two complementary biomet- ric modalities: speaker voice via speaker embeddings [5, 6, 7] and facial appearance via face embeddings [8, 9]. When both modalities are available, a ...
-
[2]
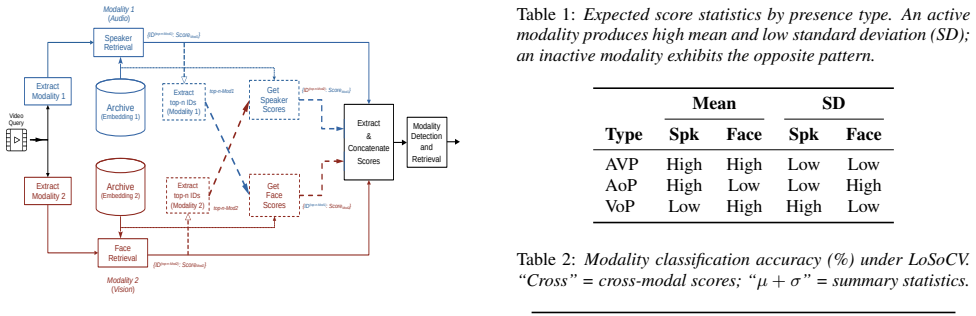
The MVSE Framework This work builds upon the Multimodal Video Search by Ex- amples (MVSE) framework [13, 18], an EPSRC-funded system for content-based retrieval in the BBC Rewind archive—a pub- licly available collection of 12,594 video files (409 h) spanning 1948–1979, covering news footage with diverse acoustic and visual conditions [12]. Figure 1 illus...
work page internal anchor Pith review Pith/arXiv arXiv 1948
-
[3]
Cross” = cross-modal scores; “µ+σ
Query-Adaptive Retrieval Framework Figure 1 illustrates the proposed extension to the MVSE pipeline: amodality combinationmodule that detects which modalities are active for a given query and sets the fusion weight accordingly, before producing the final ranked list. 3.1. Scoring and fusion Given query embeddingse (q) spk ande (q) face, the per-modality s...
-
[4]
Experimental Setup The BBC Rewind corpus [12] is a publicly available, in- the-wild broadcast archive from Northern Ireland, comprising 12,594 video files (409 hours) spanning 1948–1979. Unlike standard curated academic datasets, BBC Rewind reflects real editorial footage, including interviews, debates, voice-overs, and crowd scenes, where a person may be...
1948
-
[5]
Fixed” usesλ=0.5. “Adaptive
Results and Discussion 5.1. Modality classification Table 2 reports classification accuracy under LoSoCV . Within- modal scores alone achieve∼82%, already well above the 81.3% majority-class baseline (note A VP accounts for 425/523 queries). Adding cross-modal scores yields a∼6 pp boost, con- firming inter-modal consistency as the dominant discriminative ...
-
[6]
to be multimodal or not to be
Conclusions We presented a query-adaptive framework that answers the question“to be multimodal or not to be”for audio-visual per- son retrieval in uncurated broadcast archives. By detecting ac- tive modalities through cross-modal score consistency analysis, namely the agreement between one modality’s retrieval set and the other’s scores, the system achiev...
-
[7]
Acknowledgement This work was supported by the UK Engineering and Physical Sciences Research Council (EPSRC) under Grants EP/V002856/1, EP/V006223/1 and EP/V002740/2 (Multi- modal Video Search by Examples), and by Cambridge Univer- sity Press & Assessment (CUP&A), a department of the Chan- cellor, Masters, and Scholars of the University of Cambridge. This...
-
[8]
Multimedia information retrieval: Theory and tech- niques,
L. Stone, “Multimedia information retrieval: Theory and tech- niques,”Library Review, vol. 63, no. 4/5, pp. 373–374, 2014
2014
-
[9]
R ¨uger,Multimedia Information Retrieval, ser
S. R ¨uger,Multimedia Information Retrieval, ser. Synthesis Lec- tures on Information Concepts, Retrieval and Services. Morgan & Claypool Publishers, 2010
2010
-
[10]
Spoken content retrieval: A sur- vey of techniques and technologies,
M. Larson and G. J. F. Jones, “Spoken content retrieval: A sur- vey of techniques and technologies,”Foundations and Trends in Information Retrieval, vol. 5, no. 4–5, pp. 235–422, 2012
2012
-
[11]
Scalable identity-oriented speech retrieval,
C. Chen, D. Jiang, J. Peng, R. Lian, Y . Li, C. Zhang, L. Chen, and L. Fan, “Scalable identity-oriented speech retrieval,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 3, pp. 3261–3265, 2023
2023
-
[12]
X-vectors: Robust DNN embeddings for speaker recogni- tion,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust DNN embeddings for speaker recogni- tion,” inProc. ICASSP, 2018, pp. 5329–5333
2018
-
[13]
ECAPA- TDNN: Emphasized channel attention, propagation and aggre- gation in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggre- gation in TDNN based speaker verification,” inProc. INTER- SPEECH, 2020, pp. 3830–3834
2020
-
[14]
TitaNet: Neural model for speaker representation with 1D depth-wise separable convolu- tions and global context,
N. R. Koluguri, T. Park, and B. Ginsburg, “TitaNet: Neural model for speaker representation with 1D depth-wise separable convolu- tions and global context,” inProc. ICASSP, 2021, pp. 8102–8106
2021
-
[15]
FaceNet: A unified embedding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” inProc. CVPR, 2015, pp. 815–823
2015
-
[16]
ArcFace: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “ArcFace: Additive angular margin loss for deep face recognition,” inProc. CVPR, 2019, pp. 4685–4694
2019
-
[17]
V oxCeleb: A large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A large- scale speaker identification dataset,” inProc. INTERSPEECH, 2017, pp. 2616–2620
2017
-
[18]
V oxCeleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep speaker recognition,” inProc. INTERSPEECH, 2018, pp. 1086– 1090
2018
-
[19]
BBC Rewind,
British Broadcasting Corporation, “BBC Rewind,” https:// bbcrewind.co.uk/, 2024
2024
-
[20]
Multimodal video search by examples (MVSE),
H. Wang, M. Mulvenna, R. Bondet al., “Multimodal video search by examples (MVSE),” 2021, EPSRC Grant Reference EP/V002740/2
2021
-
[21]
On the usefulness of speaker embeddings for speaker retrieval in the wild: A com- parative study of x-vector and ECAPA-TDNN models,
E. Loweimi, M. Qian, K. Knill, and M. Gales, “On the usefulness of speaker embeddings for speaker retrieval in the wild: A com- parative study of x-vector and ECAPA-TDNN models,” inProc. INTERSPEECH 2024, 2024, pp. 3774–3778
2024
-
[22]
Seeing voices and hearing faces: Cross-modal biometric matching,
A. Nagrani, J. S. Chung, and A. Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching,” inProc. ECCV, 2018, pp. 381–396
2018
-
[23]
Self- supervised learning of audio-visual objects from video,
T. Afouras, A. Owens, J. S. Chung, and A. Zisserman, “Self- supervised learning of audio-visual objects from video,” inProc. ECCV, 2020
2020
-
[24]
Multimodal ma- chine learning: A survey and taxonomy,
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency, “Multimodal ma- chine learning: A survey and taxonomy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, pp. 423–443, 2019
2019
-
[25]
Multi-modal video search by examples—a video quality impact analysis,
G. Wu, A. Haider, X. Tian, E. Loweimi, C. H. Chan, M. Qian, A. Muhammad, I. Spence, R. Cooper, W. W. Y . Ng, J. Kit- tler, M. Gales, and H. Wang, “Multi-modal video search by examples—a video quality impact analysis,”IET Computer Vi- sion, vol. 18, no. 7, pp. 1017–1033, 2024
2024
-
[26]
Zero-shot audio topic reranking using large language models,
M. Qian, R. Ma, A. Liusie, E. Loweimi, K. Knill, and M. Gales, “Zero-shot audio topic reranking using large language models,” in IEEE Spoken Language Technology Workshop (SLT), 2024
2024
-
[27]
Speaker retrieval in the wild: Challenges, effectiveness and robustness,
E. Loweimi, M. Qian, K. Knill, and M. Gales, “Speaker retrieval in the wild: Challenges, effectiveness and robustness,” 2025. [Online]. Available: https://arxiv.org/abs/2504.18950
-
[28]
pyannote.audio: Neural building blocks for speaker diarization,
H. Bredin, R. Yin, J. M. Coria, G. Gelly, P. Korshunov, M. Lavechin, D. Fustes, H. Titeux, W. Bouaziz, and M.-P. Gill, “pyannote.audio: Neural building blocks for speaker diarization,” inProc. ICASSP, 2020
2020
-
[29]
End-to-end speaker segmentation for overlap-aware resegmentation,
H. Bredin and A. Laurent, “End-to-end speaker segmentation for overlap-aware resegmentation,” inProc. INTERSPEECH, 2021
2021
-
[30]
SpeechBrain’s ECAPA-TDNN implemen- tation for speaker embedding extraction,
M. Ravanelliet al., “SpeechBrain’s ECAPA-TDNN implemen- tation for speaker embedding extraction,” https://huggingface.co/ speechbrain/spkrec-ecapa-voxceleb, 2021
2021
-
[31]
V oxCeleb: Large-scale speaker verification in the wild,
A. Nagrani, J. S. Chung, W. Xie, and A. Zisserman, “V oxCeleb: Large-scale speaker verification in the wild,”Computer Speech & Language, vol. 60, p. 101027, 2020
2020
-
[32]
Additive margin softmax for face verification,
F. Wang, J. Cheng, W. Liu, and H. Liu, “Additive margin softmax for face verification,”IEEE Signal Processing Letters, vol. 25, no. 7, pp. 926–930, 2018
2018
-
[33]
Keep an eye on faces: Robust face detection with heatmap-assisted spatial attention and scale-aware layer attention,
L. Ju, J. Kittler, M. A. T. Rana, W. Yang, and Z. Feng, “Keep an eye on faces: Robust face detection with heatmap-assisted spatial attention and scale-aware layer attention,”Pattern Recognition, vol. 140, p. 109553, 2023
2023
-
[34]
Least-squares estimation of transformation param- eters between two point patterns,
S. Umeyama, “Least-squares estimation of transformation param- eters between two point patterns,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 13, no. 4, pp. 376–380, 1991
1991
-
[35]
WebFace260M: A benchmark unveiling the power of million-scale deep face recognition,
Z. Zhu, G. Huang, J. Deng, Y . Ye, J. Huang, X. Chen, J. Zhu, T. Yang, D. Du, J. Lu, and J. Zhou, “WebFace260M: A benchmark unveiling the power of million-scale deep face recognition,” in Proc. CVPR, 2021, pp. 10 492–10 502
2021
-
[36]
Scikit-learn: Machine learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
2011
-
[37]
spacy: Industrial-strength natural language pro- cessing in Python,
Explosion AI, “spacy: Industrial-strength natural language pro- cessing in Python,” https://spacy.io, 2015
2015
-
[38]
C. D. Manning, P. Raghavan, and H. Sch ¨utze,Introduction to In- formation Retrieval. Cambridge University Press, 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.