ECHO: Prune to act, trace to learn with selective turn memory in agentic RL
Pith reviewed 2026-07-01 06:12 UTC · model grok-4.3
The pith
ECHO lets agents prune history into indexed records and route RL credit back to the exact turns that produced success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ECHO is a selective turn-memory framework that compresses each completed environment turn into a compact memory record, reconstructs bounded policy contexts by selecting from these records, and reuses the selected source indices to route positive outcome credit to the evidence and selection actions that support successful answers.
What carries the argument
source-indexed reconstruction: each turn is stored as a compact record carrying its original index; selection from the record pool both assembles the policy context and supplies the addresses for outcome-based credit assignment.
If this is right
- Agents maintain direct access to original evidence without progressive loss as turn count grows.
- Outcome rewards can update the precise turns and selection decisions that contributed to success.
- Training uses fewer total turns and lower trajectory volume than rolling-summary baselines.
- The learned policy transfers to multi-objective QA, code generation, and information-seeking tasks on both dense and MoE models.
Where Pith is reading between the lines
- The same index-based credit routing could be applied to other memory-compression schemes in long-horizon RL to test whether traceability is the main source of the observed gains.
- If the compression step itself discards critical details, the framework would benefit from adaptive record granularity rather than fixed-size records.
- The separation of pruning (via selection) from credit assignment (via indices) suggests a general pattern for making any bounded-context agent trainable with outcome RL.
Load-bearing premise
Reconstructing contexts from selected compressed records with their original indices still supplies enough fine-grained evidence for the policy to use it effectively and lets credit assignment remain stable without introducing selection bias.
What would settle it
Train two policies on the same data: one with ECHO's indexed credit routing and one with identical compression but credit assigned uniformly or without indices; if the indexed version shows no accuracy gain or higher variance on held-out tasks, the traceability benefit is absent.
Figures





read the original abstract
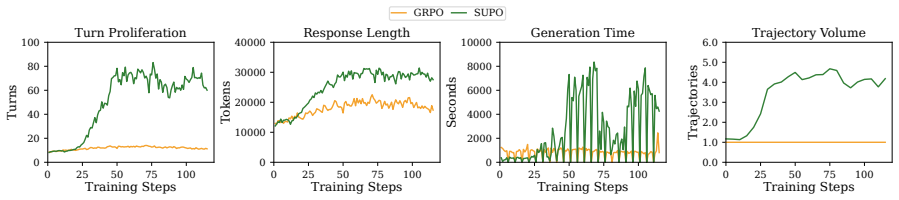
Long-horizon language agents must repeatedly interact with tools, accumulate evidence, and make decisions under bounded context windows. Existing context-management methods make such rollouts feasible by truncating distant history, folding past turns into summaries, or selecting compact memory states. However, these breakthroughs introduce two coupled limitations. First, as the number of turns grows, historical observations are progressively removed or collapsed into compressed states, making it harder for the policy to reuse fine-grained evidence. Second, once the original turns are no longer source-addressable, outcome-based RL loses an explicit path for aligning policy updates with the evidence that supported a successful final answer. To this end, we propose ECHO, a selective turn-memory framework that jointly addresses history collapse and traceable learning through source-indexed reconstruction. Specifically, ECHO compresses each completed environment turn into a compact memory record, reconstructs bounded policy contexts by selecting from these records, and reuses the selected source indices to route positive outcome credit to the evidence and selection actions that support successful answers. On BrowseComp-Plus, ECHO reaches 43.4% held-out accuracy, outperforming GRPO (28.9%) and the rolling-summary baseline SUPO (36.1%), while using fewer turns and lower trajectory volume than SUPO (Figure 1). Additionally, the trained policy improves zero-shot generalization across multi-objective QA, code generation, and deep information-seeking benchmarks on both dense and MoE backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ECHO, a selective turn-memory framework for long-horizon language agents in RL. It compresses each environment turn into a compact memory record, reconstructs bounded policy contexts via selection from these records, and reuses the source indices to route positive outcome credit back to the supporting evidence and selection actions. On BrowseComp-Plus it reports 43.4% held-out accuracy (vs. GRPO 28.9%, SUPO 36.1%), with fewer turns and lower trajectory volume than SUPO, plus improved zero-shot generalization on multi-objective QA, code generation, and information-seeking tasks across dense and MoE backbones.
Significance. If the source-indexed reconstruction and index-based credit routing function as described without substantial information loss or selection bias, the method would address two persistent limitations in agentic RL—progressive history collapse and untraceable outcome credit—potentially enabling more efficient, evidence-reusing policies at scale.
major comments (3)
- [Abstract] Abstract: the central claim that source-indexed reconstruction preserves sufficient fine-grained evidence for policy reuse is unsupported by any reported diagnostic (e.g., token-level overlap, information-retention metrics, or reconstruction-error statistics between original turns and reconstructed contexts).
- [Abstract] Abstract: no ablation or diagnostic is supplied that isolates the contribution of index-based credit routing from the selection heuristic itself; without this, the 43.4% accuracy and reduced trajectory volume cannot be confidently attributed to the traceable-learning component rather than the compression/selection procedure alone.
- [Abstract] Abstract: the reported accuracy figures lack variance estimates, statistical significance tests, or multiple-run statistics, making it impossible to assess whether the gains over GRPO and SUPO are robust or sensitive to unstated implementation choices.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional evidence would strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that source-indexed reconstruction preserves sufficient fine-grained evidence for policy reuse is unsupported by any reported diagnostic (e.g., token-level overlap, information-retention metrics, or reconstruction-error statistics between original turns and reconstructed contexts).
Authors: We acknowledge that the current manuscript does not report explicit diagnostics such as token-level overlap, information-retention metrics, or reconstruction-error statistics. In the revised version we will add these analyses (including quantitative comparisons between original turns and reconstructed contexts) in a new appendix to substantiate the preservation claim. revision: yes
-
Referee: [Abstract] Abstract: no ablation or diagnostic is supplied that isolates the contribution of index-based credit routing from the selection heuristic itself; without this, the 43.4% accuracy and reduced trajectory volume cannot be confidently attributed to the traceable-learning component rather than the compression/selection procedure alone.
Authors: We agree that an ablation isolating the index-based credit routing mechanism from the selection heuristic is necessary to attribute performance gains. The revised manuscript will include this ablation (comparing full ECHO against a variant without credit routing) along with corresponding trajectory and accuracy metrics. revision: yes
-
Referee: [Abstract] Abstract: the reported accuracy figures lack variance estimates, statistical significance tests, or multiple-run statistics, making it impossible to assess whether the gains over GRPO and SUPO are robust or sensitive to unstated implementation choices.
Authors: The reported figures are from single runs without variance or significance statistics. In revision we will rerun all main experiments across multiple random seeds, report means and standard deviations, and include statistical significance tests against the baselines. revision: yes
Circularity Check
No circularity: empirical results are direct measurements, not derived quantities.
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps. The central claims are held-out accuracy numbers (43.4% on BrowseComp-Plus) presented as direct experimental outcomes, with comparisons to baselines like GRPO and SUPO. No self-definitional relations, fitted-input predictions, or load-bearing self-citations appear. The method description (source-indexed reconstruction and credit routing) is presented as a proposed framework whose effectiveness is evaluated empirically rather than proven by construction from its own inputs. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. BrowseComp-Plus: A more fair and trans- parent evaluation benchmark of deep-research agent.arXiv...
-
[2]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Generalizable end-to-end tool-use RL with synthetic CodeGym.arXiv preprint arXiv:2509.17325,
Weihua Du, Hailei Gong, Zhan Ling, Kang Liu, Lingfeng Shen, Xuesong Yao, Yufei Xu, Dingyuan Shi, Yim- ing Yang, and Jiecao Chen. Generalizable end-to-end tool-use RL with synthetic CodeGym.arXiv preprint arXiv:2509.17325,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model.arXiv preprint arXiv:2408.09559,
-
[6]
SAM: State-Adaptive Memory for Long-Horizon Reasoning Agent
Yuyang Hu, Hongjin Qian, Shuting Wang, Jiongnan Liu, Ziliang Zhao, Jiejun Tan, Zheng Liu, and Zhicheng Dou. SAM: State-adaptive memory for long-horizon reasoning agent.arXiv preprint arXiv:2605.24468,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Wang Dong, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents.arXiv preprint arXiv:2510.00615,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologie...
2025
-
[10]
MemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Ruoran Li, Xinghua Zhang, Haiyang Yu, Shitong Duan, Xiang Li, Wenxin Xiang, Chonghua Liao, Xudong Guo, Yongbin Li, and Jinli Suo. MemPO: Self-memory policy optimization for long-horizon agents.arXiv preprint arXiv:2603.00680,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Torl: Scaling tool-integrated rl,
10 Xuefeng Li, Haoyang Zou, and Pengfei Liu. ToRL: Scaling tool-integrated RL.arXiv preprint arXiv:2503.23383,
-
[12]
Compressing context to enhance inference efficiency of large language models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing context to enhance inference efficiency of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[13]
Prompt compression for large language models: A survey.arXiv preprint arXiv:2410.12388,
Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier. Prompt compression for large language models: A survey.arXiv preprint arXiv:2410.12388,
-
[14]
Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling LLM multi-turn RL with end-to-end summarization-based context management.arXiv preprint arXiv:2510.06727,
-
[15]
Gaia: a benchmark for general ai assistants
Gr´egoire Mialon, Cl´ementine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InInternational Conference on Learning Representations, volume 2024, pp. 9025–9049,
2024
-
[16]
Agent-Omit: Adaptive Context Omission for Efficient LLM Agents
Yansong Ning, Jun Fang, Naiqiang Tan, and Hao Liu. Agent-omit: Adaptive context omission for efficient llm agents.arXiv preprint arXiv:2602.04284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Agent-Omit: Adaptive Context Omission for Efficient LLM Agents
doi: 10.48550/arXiv.2602.04284. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.04284
-
[18]
Jiangweizhi Peng, Yuanxin Liu, Ruida Zhou, Charles Fleming, Zhaoran Wang, Alfredo Garcia, and Mingyi Hong. Hiper: Hierarchical reinforcement learning with explicit credit assignment for large language model agents. arXiv preprint arXiv:2602.16165,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 5687–5711,
2023
-
[21]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T ¨ur, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Zile Qiao, Guoxin Chen, Xuanzhong Chen, Donglei Yu, Wenbiao Yin, Xinyu Wang, Zhen Zhang, Baixuan Li, Huifeng Yin, Kuan Li, et al. WebResearcher: Unleashing unbounded reasoning capability in long-horizon agents.arXiv preprint arXiv:2509.13309,
-
[23]
Locobench-agent: An interactive benchmark for llm agents in long-context software engineering
Jielin Qiu, Zuxin Liu, Zhiwei Liu, Rithesh Murthy, Jianguo Zhang, Haolin Chen, Shiyu Wang, Ming Zhu, Liang- wei Yang, Juntao Tan, et al. Locobench-agent: An interactive benchmark for llm agents in long-context software engineering.arXiv preprint arXiv:2511.13998,
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Cognitive memory in large language models
Lianlei Shan, Shixian Luo, Zezhou Zhu, Yu Yuan, and Yong Wu. Cognitive memory in large language models. arXiv preprint arXiv:2504.02441,
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
QwenLong-CPRS: Towards∞-LLMs with dynamic context optimization.arXiv preprint arXiv:2505.18092,
Weizhou Shen, Chenliang Li, Fanqi Wan, Shengyi Liao, Shaopeng Lai, Bo Zhang, Yingcheng Shi, Yuning Wu, Gang Fu, Zhansheng Li, et al. QwenLong-CPRS: Towards∞-LLMs with dynamic context optimization.arXiv preprint arXiv:2505.18092,
-
[28]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-Searcher: Incentivizing the search capability in LLMs via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Hindsight credit assignment for long-horizon llm agents.arXiv preprint arXiv:2603.08754,
11 Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. Hindsight credit assignment for long-horizon llm agents.arXiv preprint arXiv:2603.08754,
-
[30]
In-context former: Lightning-fast compressing context for large language model
Xiangfeng Wang, Zaiyi Chen, Zheyong Xie, Tong Xu, Yongyi He, and Enhong Chen. In-context former: Lightning-fast compressing context for large language model. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024,
2024
-
[31]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen. MIRIX: Multi-agent memory system for LLM-based agents.arXiv preprint arXiv:2507.07957,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Milestone-Guided Policy Learning for Long-Horizon Language Agents
Zixuan Wang, Yuchen Yan, Hongxing Li, Teng Pan, Dingming Li, Ruiqing Zhang, Weiming Lu, Jun Xiao, Yuet- ing Zhuang, and Yongliang Shen. Milestone-guided policy learning for long-horizon language agents.arXiv preprint arXiv:2605.06078,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Resum: Unlocking long-horizon search intelligence via context summarization
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313,
-
[35]
ContextWeaver: Selective and Dependency-Structured Memory Construction for LLM Agents
Yating Wu, Yuhao Zhang, Sayan Ghosh, Sourya Basu, Anoop Deoras, Jun Huan, and Gaurav Gupta. Con- textweaver: Selective and dependency-structured memory construction for llm agents.arXiv preprint arXiv:2604.23069,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Concise and precise context compression for tool-using language models
Yang Xu, Yunlong Feng, Honglin Mu, Yutai Hou, Yitong Li, Xinghao Wang, Wanjun Zhong, Zhongyang Li, Dandan Tu, Qingfu Zhu, et al. Concise and precise context compression for tool-using language models. In Findings of the Association for Computational Linguistics: ACL 2024, pp. 16430–16441,
2024
-
[38]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Sch¨utze, V olker Tresp, and Yunpu Ma. Memory-R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[40]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
12 Chenchen Zhang. From reasoning to agentic: Credit assignment in reinforcement learning for large language models.arXiv preprint arXiv:2604.09459,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang. Memory as action: Au- tonomous context curation for long-horizon agentic tasks.arXiv preprint arXiv:2510.12635,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
Haotian Zhao, Songlin Zhou, Yuxin Zhang, Stephen S.-T. Yau, Wenyu Zhang, Lun Tian, Tianshu Zhu, Yifeng Huang, Yucheng Zeng, Jingnan Gu, Daxiang Dong, and Jianmin Wu. AEM: Adaptive entropy modulation for multi-turn agentic reinforcement learning.arXiv preprint arXiv:2605.00425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deep- Researcher: Scaling deep research via reinforcement learning in real-world environments.arXiv preprint arXiv:2504.03160,
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents. arXiv preprint arXiv:2506.15841,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
The top pipeline shows the rollout loop, where the policy generates tool calls, receives observations, and triggers reconstruction once history exceeds the budget
13 A CONTEXTRECONSTRUCTIONSTRATEGIES Figure 6 compares context reconstruction strategies under bounded-context agentic RL. The top pipeline shows the rollout loop, where the policy generates tool calls, receives observations, and triggers reconstruction once history exceeds the budget. The lower panels show how different methods reconstruct the next polic...
2025
-
[47]
CodeGym frames tasks as synthetic interactive environments where agents invoke problem-specific APIs, together withobserve()anddone(), rather than writing raw code
and LoCoBench-Agent (Qiu et al., 2025). CodeGym frames tasks as synthetic interactive environments where agents invoke problem-specific APIs, together withobserve()anddone(), rather than writing raw code. Since many CodeGym tasks are either too easy or too difficult for meaningful comparison, we construct a medium- difficulty subset using the originalQwen...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.