Online Safety Monitoring for LLMs
Pith reviewed 2026-07-03 12:50 UTC · model grok-4.3
The pith
A simple threshold on an external verifier signal, calibrated by risk control, matches advanced sequential monitors for LLM safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
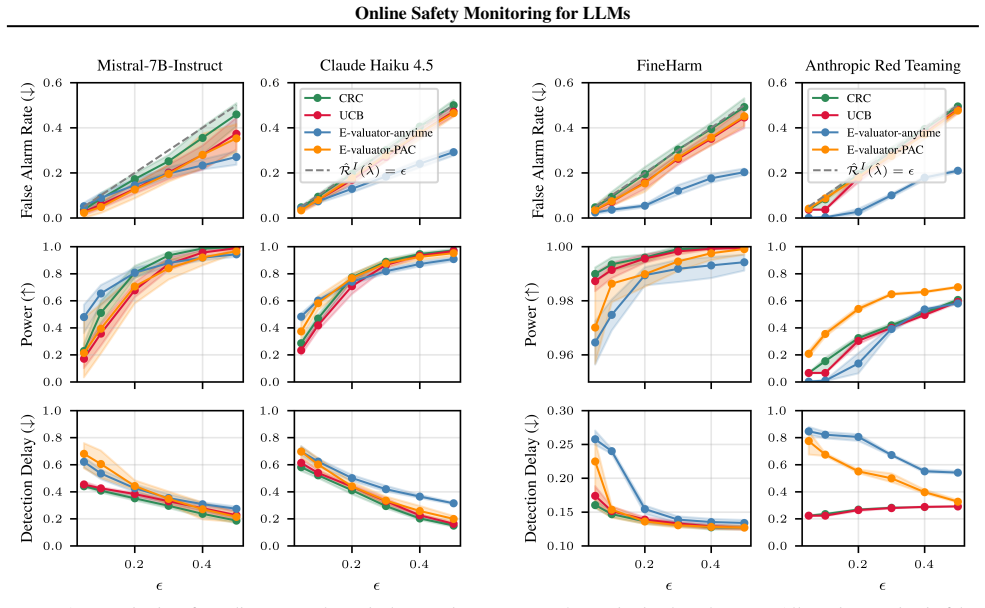
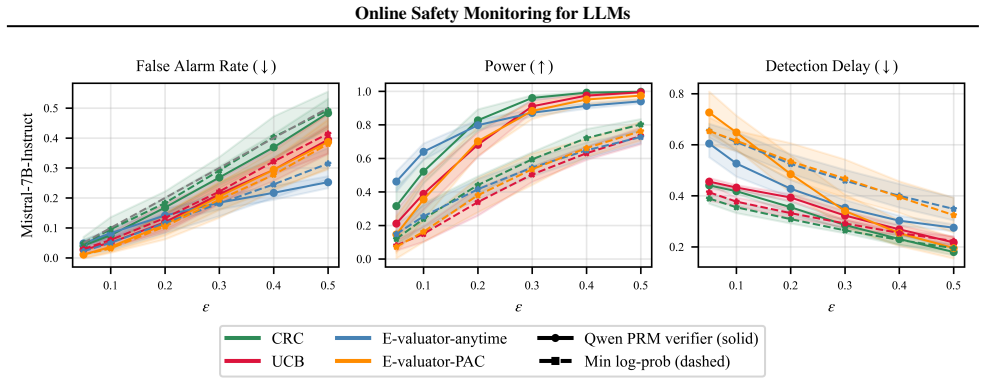
The paper claims that a simple real-time monitor which turns a verifier signal from an external model into an alarm decision by thresholding, with the threshold calibrated via risk control, is competitive with more advanced monitors based on sequential hypothesis testing on mathematical reasoning and red teaming datasets.
What carries the argument
The simple thresholding monitor with risk-control calibration that converts an external verifier signal into an alarm decision.
If this is right
- Simple monitors can achieve comparable safety performance to sequential methods on the tested tasks.
- Risk control offers a practical way to set thresholds for target error rates without complex modeling.
- The approach applies across both mathematical reasoning and adversarial red teaming scenarios.
- Real-time alarm decisions become feasible using only an external signal and a fixed threshold.
Where Pith is reading between the lines
- If the result holds, safety systems could simplify by preferring external verifiers over internal sequential tests.
- The method could extend to other generation domains where an external signal is available but full sequential testing is costly.
- Deployment would require checking whether the verifier signal distribution remains stable over time.
Load-bearing premise
The external verifier model produces a signal whose distribution allows reliable thresholding and risk-control calibration to control alarm error rates in deployment settings.
What would settle it
A new dataset or deployment scenario where the simple threshold monitor produces alarm error rates that exceed those of sequential hypothesis testing methods or fail to meet the risk-control guarantees.
Figures
read the original abstract
Despite alignment training, LLMs remain prone to generating unsafe outputs at deployment time. Monitoring outputs online and raising an alarm when safety can no longer be assumed is therefore critical. We study a simple real-time monitor that turns a verifier signal from an external model into an alarm decision by thresholding, with the threshold calibrated via risk control. In experiments on mathematical reasoning and red teaming datasets, we show that this simple design is competitive with more advanced monitors based on sequential hypothesis testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a simple real-time safety monitor for LLMs that converts a signal from an external verifier model into an alarm via thresholding, with the threshold selected by risk-control calibration. It reports that this monitor is competitive with sequential hypothesis testing monitors on mathematical reasoning and red teaming datasets.
Significance. If the empirical competitiveness holds under the stated calibration, the result would indicate that a lightweight, non-sequential monitor can achieve comparable alarm performance without explicitly modeling temporal structure, which could reduce implementation complexity for online LLM safety systems. The reliance on risk control for finite-sample error-rate bounds is a potential strength if the calibration data satisfy the required assumptions.
major comments (2)
- [Abstract] Abstract: the claim of competitiveness is stated without any quantitative results, error bars, dataset sizes, or calibration details, so the support for the central claim cannot be assessed from the provided information.
- [Methods] Methods (risk-control calibration procedure): the finite-sample guarantee on alarm error rates rests on exchangeability between the calibration set and deployment streams. LLM outputs routinely exhibit topic drift, user-induced shifts, and temporal dependence; the manuscript does not address whether or how these violations are mitigated, which directly affects whether the simple monitor remains competitive with sequential methods that explicitly handle the online regime.
minor comments (1)
- Specify the precise form of the verifier signal (e.g., logit, probability, or binary verdict) and the external model used to produce it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the risk-control assumptions. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of competitiveness is stated without any quantitative results, error bars, dataset sizes, or calibration details, so the support for the central claim cannot be assessed from the provided information.
Authors: We agree that the abstract would be strengthened by including quantitative support. In the revised version we will expand the abstract to report key metrics (e.g., false-alarm rates and detection delays with standard errors), the sizes of the mathematical-reasoning and red-teaming datasets, and the calibration-set size together with the target risk level used for threshold selection. revision: yes
-
Referee: [Methods] Methods (risk-control calibration procedure): the finite-sample guarantee on alarm error rates rests on exchangeability between the calibration set and deployment streams. LLM outputs routinely exhibit topic drift, user-induced shifts, and temporal dependence; the manuscript does not address whether or how these violations are mitigated, which directly affects whether the simple monitor remains competitive with sequential methods that explicitly handle the online regime.
Authors: The referee correctly identifies that the risk-control finite-sample bounds require exchangeability. Our manuscript presents an empirical comparison on the given datasets and does not claim that the bounds continue to hold under arbitrary non-stationarity. We will add an explicit limitations paragraph in the methods and discussion sections that (i) states the exchangeability assumption, (ii) notes that LLM streams can exhibit topic drift and temporal dependence, and (iii) clarifies that the reported competitiveness is an empirical observation rather than a guarantee that survives arbitrary violations. This will also contextualize why sequential methods may retain advantages in strongly non-stationary regimes. revision: yes
Circularity Check
No circularity: empirical comparison with external components
full rationale
The paper presents an empirical study of a simple thresholding monitor calibrated via risk control, compared against sequential hypothesis testing on two datasets. No derivation chain, equations, or self-citations are invoked to derive the main result; the method treats the external verifier signal and risk-control procedure as independent inputs, and competitiveness is shown via direct experiments rather than any reduction to fitted parameters or prior self-citations. The central claim remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Angelopoulos and Stephen Bates and Adam Fisch and Lihua Lei and Tal Schuster , title =
Angelopoulos, A. N., Bates, S., Fisch, A., Lei, L., and Schuster, T. Conformal risk control.arXiv preprint arXiv:2208.02814,
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
URL https://assets. anthropic.com/m/99128ddd009bdcb/ Claude-Haiku-4-5-System-Card.pdf. Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Baker, B., Huizinga, J., Gao, L., Dou, Z., Guan, M. Y ., Madry, A., Zaremba, W., Pachocki, J., and Farhi, D. Mon- itoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosse- lut, A., Brunskill, E., et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Lookback lens: Detecting and mitigat- ing contextual hallucinations in large language models using only attention maps
Chuang, Y .-S., Qiu, L., Hsieh, C.-Y ., Krishna, R., Kim, Y ., and Glass, J. Lookback lens: Detecting and mitigat- ing contextual hallucinations in large language models using only attention maps. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 1419–1436,
2024
-
[6]
Davidov, H., Feldman, S., Freidkin, G., and Romano, Y . Calibrated predictive lower bounds on time-to-unsafe- sampling in llms.arXiv preprint arXiv:2506.13593,
-
[7]
How Many Iterations to Jailbreak? Dynamic Budget Allocation for Multi-Turn LLM Evaluation
Feldman, S. and Romano, Y . How many iterations to jail- break? dynamic budget allocation for multi-turn llm eval- uation.arXiv preprint arXiv:2605.06605,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, D., Lovitt, L., Kernion, J., Askell, A., Bai, Y ., Kadavath, S., Mann, B., Perez, E., Schiefer, N., Ndousse, K., et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
AI control: Improving safety despite intentional subversion.arXiv preprint arXiv:2312.06942, 2024
Greenblatt, R., Shlegeris, B., Sachan, K., and Roger, F. Ai control: Improving safety despite intentional subversion. arXiv preprint arXiv:2312.06942,
-
[10]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
6 Online Safety Monitoring for LLMs Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y ., Tontchev, M., Hu, Q., Fuller, B., Testug- gine, D., et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arxiv.arXiv preprint arXiv:2310.06825, 10:3,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2406.18510 (2024)
URLhttps://arxiv.org/abs/2406.18510. Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., and Han, J. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
- [13]
-
[14]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Korbak, T., Balesni, M., Barnes, E., Bengio, Y ., Benton, J., Bloom, J., Chen, M., Cooney, A., Dafoe, A., Dra- gan, A., et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Kossen, J., Han, J., Razzak, M., Schut, L., Malik, S., and Gal, Y . Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Efficiently controlling multiple risks with pareto test- ing.arXiv preprint arXiv:2210.07913,
Laufer-Goldshtein, B., Fisch, A., Barzilay, R., and Jaakkola, T. Efficiently controlling multiple risks with pareto test- ing.arXiv preprint arXiv:2210.07913,
-
[17]
Li, Y ., Sheng, Q., Yang, Y ., Zhang, X., and Cao, J. From judgment to interference: Early stopping llm harmful outputs via streaming content monitoring.arXiv preprint arXiv:2506.09996,
-
[18]
Let’s verify step by step
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pp. 39578–39601,
2024
-
[19]
Selfcheckgpt: Zero- resource black-box hallucination detection for genera- tive large language models
Manakul, P., Liusie, A., and Gales, M. Selfcheckgpt: Zero- resource black-box hallucination detection for genera- tive large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pp. 9004–9017,
2023
-
[20]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., et al. Harm- bench: A standardized evaluation framework for auto- mated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Mohri, C. and Hashimoto, T. Language models with conformal factuality guarantees.arXiv preprint arXiv:2402.10978,
-
[22]
com/o3-mini-system-card-feb10.pdf
URL https://cdn.openai. com/o3-mini-system-card-feb10.pdf. Podkopaev, A. and Ramdas, A. Tracking the risk of a deployed model and detecting harmful distribution shifts. arXiv preprint arXiv:2110.06177,
-
[23]
Quach, V ., Fisch, A., Schuster, T., Yala, A., Sohn, J. H., Jaakkola, T. S., and Barzilay, R. Conformal language modeling.arXiv preprint arXiv:2306.10193,
-
[24]
E-valuator: Reliable Agent Verifiers with Sequential Hypothesis Testing
Sadhuka, S., Prinster, D., Fannjiang, C., Scalia, G., Regev, A., and Wang, H. E-valuator: Reliable agent veri- fiers with sequential hypothesis testing.arXiv preprint arXiv:2512.03109,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Schirmer, M., Jazbec, M., Naesseth, C. A., and Nalisnick, E. Monitoring risks in test-time adaptation.arXiv preprint arXiv:2507.08721,
-
[26]
Sharma, M., Tong, M., Mu, J., Wei, J., Kruthoff, J., Good- friend, S., Ong, E., Peng, A., Agarwal, R., Anil, C., et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming.arXiv preprint arXiv:2501.18837,
work page internal anchor Pith review Pith/arXiv arXiv
- [27]
-
[28]
Poskitt, Jun Sun, and Jiali Wei
Wang, H., Poskitt, C. M., Sun, J., and Wei, J. Pro2guard: Proactive runtime enforcement of llm agent safety via probabilistic model checking.arXiv preprint arXiv:2508.00500,
-
[29]
Conformal Thinking: Risk Control for Reasoning on a Compute Budget
Wang, X., Suresh, A., Zhang, A., More, R., Jurayj, W., Van Durme, B., Farajtabar, M., Khashabi, D., and Nalis- nick, E. Conformal thinking: Risk control for reasoning on a compute budget.arXiv preprint arXiv:2602.03814,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Ethical and social risks of harm from Language Models
Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.-S., Cheng, M., Glaese, M., Balle, B., Kasirzadeh, A., et al. Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2310.11986 , year=
Weidinger, L., Rauh, M., Marchal, N., Manzini, A., Hen- dricks, L. A., Mateos-Garcia, J., Bergman, S., Kay, J., Griffin, C., Bariach, B., et al. Sociotechnical safety evaluation of generative ai systems.arXiv preprint arXiv:2310.11986,
-
[32]
Thought calibration: Efficient and confident test-time scaling
Wu, M., Zhou, C., Bates, S., and Jaakkola, T. Thought calibration: Efficient and confident test-time scaling. In Proceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pp. 14302–14316,
2025
-
[33]
Zeng, H., Huang, J., Jing, B., Wei, H., and An, B. Pac reasoning: Controlling the performance loss for efficient reasoning.arXiv preprint arXiv:2510.09133,
-
[34]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Zeng, W., Liu, Y ., Mullins, R., Peran, L., Fernandez, J., Harkous, H., Narasimhan, K., Proud, D., Kumar, P., Radharapu, B., et al. Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
The Rise of AI Companions: Interaction with AI Companions and Psychological Well-being
Zhang, Y ., Zhao, D., Hancock, J. T., Kraut, R., and Yang, D. The rise of ai companions: how human- chatbot relationships influence well-being.arXiv preprint arXiv:2506.12605, 2025a. 8 Online Safety Monitoring for LLMs Zhang, Z., Zheng, C., Wu, Y ., Zhang, B., Lin, R., Yu, B., Liu, D., Zhou, J., and Lin, J. The lessons of developing process reward models ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Related Work LLM MonitoringVarious efforts (Weidinger et al., 2021, 2023; Bommasani et al.,
9 Online Safety Monitoring for LLMs A. Related Work LLM MonitoringVarious efforts (Weidinger et al., 2021, 2023; Bommasani et al.,
2021
-
[37]
have stressed the importance of monitoring LLMs at deployment time, for factuality (Manakul et al., 2023; Chuang et al., 2024), content moderation (Inan et al., 2023; Zeng et al.,
2023
-
[38]
or against obfuscation (Korbak et al., 2025; Baker et al., 2025; Greenblatt et al., 2023). For content moderation, for instance, monitoring tools are typically taking the form of safeguard classifiers that predict the harmfulness of a user prompt or an LLM output (Inan et al., 2023; Sharma et al., 2025; Mazeika et al., 2024; Markov et al., 2023). Recent w...
2025
-
[39]
Such oversight models can provide strong signals that can be leveraged within a statistical framework, as we discuss in this work
proposes online monitors that are designed for unfolding output, the setting we consider here. Such oversight models can provide strong signals that can be leveraged within a statistical framework, as we discuss in this work. Statistical Monitoring FrameworksDetecting when a model degrades at inference time or exceeds a pre-defined risk level has traditio...
2021
-
[40]
Relatedly, e-processes (Ramdas et al., 2023; Ramdas & Wang,
labels, as well as under model adaptation (Schirmer et al., 2025; Bar et al., 2024). Relatedly, e-processes (Ramdas et al., 2023; Ramdas & Wang,
2025
-
[41]
have been used to track evidence of risk violations over time (Timans et al., 2025; Prinster et al., 2025). In the context of LLMs, conformal prediction has been used to provide statistical trustworthiness, albeit in a classic offline setting (Cherian et al., 2024; Mohri & Hashimoto, 2024; Quach et al., 2023; Gui et al., 2024). A related line of work on o...
2025
-
[42]
Most closely related to our work are agentic oversight methods (Wang et al., 2025), particularly Sadhuka et al
uses conformal survival analysis to construct PAC-type bounds on the time-to-unsafe-sampling of a given prompt. Most closely related to our work are agentic oversight methods (Wang et al., 2025), particularly Sadhuka et al. (2025), which tackles the same online monitoring setting. B. Missed Detection Risk We complement the false alarm risk of § 3.3 with i...
2025
-
[43]
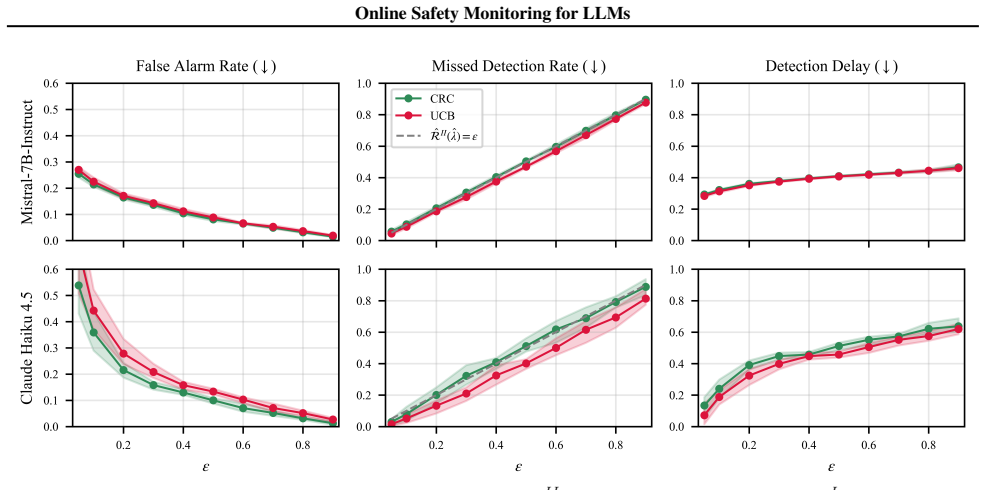
(7)) instead of false alarm risk RI (Eq
For control in expectation, the threshold is ˆλCRC := min λ∈Λ : n0 n0 + 1 ˆRII (λ;D cal) + 1 n0 + 1 ≤ϵ ,(8) 10 Online Safety Monitoring for LLMs Figure 4.Monitoring performance when controlling missed detection risk RII (Eq. (7)) instead of false alarm risk RI (Eq. (2)): CRC and UCB control the risk RII well (second column). E-valuators are excluded from ...
2025
-
[44]
incorrect
, i.e. incorrect. For a new LLM trajectory, the procedure evaluates a statistic Mt online, and rejects the null once Mt crosses a threshold cα. The target guarantee isanytime-validfalse-alarm control, or PH0 ∃t≥1 :M t ≥c α ≤α, meaning that a true successful trajectory is incorrectly flagged at any time with probability at most α, for any unknown sequence ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.