Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey
Pith reviewed 2026-05-22 13:29 UTC · model grok-4.3
The pith
A four-dimension taxonomy organizes benchmarks for evaluating large audio-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
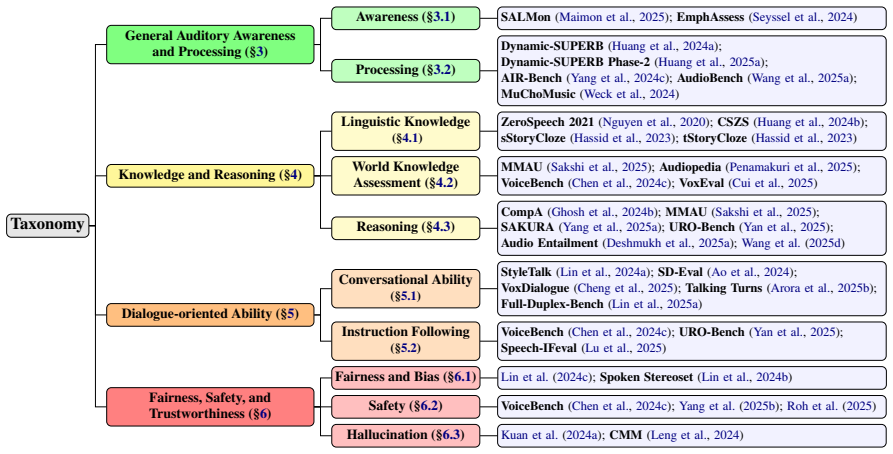
This survey proposes a systematic taxonomy for LALM evaluations, categorizing them into four dimensions based on their objectives: (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness. It provides detailed overviews within each category, highlights challenges, and offers insights into promising future directions, establishing the first dedicated survey focused on LALM evaluations.
What carries the argument
The proposed taxonomy of four dimensions based on evaluation objectives, which categorizes benchmarks to provide community guidelines for assessing LALMs.
If this is right
- Benchmarks receive structured placement into the four categories for clearer comparison.
- Challenges in current LALM evaluation practices become more visible.
- Insights guide development of evaluations that address gaps across dimensions.
- A maintained collection of surveyed papers supports ongoing community work.
Where Pith is reading between the lines
- Adopting the taxonomy could encourage creation of new benchmarks that balance coverage across all four dimensions.
- The structure may highlight which evaluation areas, such as safety, receive less attention than others.
- It could serve as a starting point for similar taxonomies in other multimodal model evaluations.
Load-bearing premise
Existing benchmarks can be partitioned into the four proposed dimensions with minimal overlap or missing categories that would require a different organizing principle.
What would settle it
Discovery of many benchmarks that cannot be assigned to any of the four dimensions or that demand a substantially different organizing structure would challenge the taxonomy.
Figures


read the original abstract
With advancements in large audio-language models (LALMs), which enhance large language models (LLMs) with auditory capabilities, these models are expected to demonstrate universal proficiency across various auditory tasks. While numerous benchmarks have emerged to assess LALMs' performance, they remain fragmented and lack a structured taxonomy. To bridge this gap, we conduct a comprehensive survey and propose a systematic taxonomy for LALM evaluations, categorizing them into four dimensions based on their objectives: (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness. We provide detailed overviews within each category and highlight challenges in this field, offering insights into promising future directions. To the best of our knowledge, this is the first survey specifically focused on the evaluations of LALMs, providing clear guidelines for the community. We will release the collection of the surveyed papers and actively maintain it to support ongoing advancements in the field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a literature survey on evaluation benchmarks for Large Audio-Language Models (LALMs). It proposes a four-dimensional taxonomy organized by evaluation objectives—(1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness—provides overviews of benchmarks within each dimension, identifies challenges, and outlines future directions. The authors position the work as the first survey specifically focused on LALM evaluations and claim it supplies clear guidelines for the community via the taxonomy.
Significance. If the taxonomy can be shown to partition existing benchmarks with acceptable overlap and coverage, the survey would offer a useful organizing framework for an emerging area where evaluation methods are currently fragmented. The planned release of the surveyed paper collection would further increase its practical value to the community.
major comments (2)
- [Abstract and Introduction] Abstract and Introduction: No explicit search strategy, inclusion/exclusion criteria, date range, or total count of surveyed papers is stated, which directly affects verifiability of the claim that the taxonomy provides comprehensive coverage of LALM evaluations.
- [Taxonomy section] Taxonomy presentation (likely §3): The four dimensions are introduced without boundary definitions, assignment rules, or an explicit audit for overlaps; in particular, the boundary between 'Knowledge and Reasoning' and 'Dialogue-oriented Ability' is not addressed even though dialogue tasks routinely embed reasoning over auditory input, weakening the assertion that the taxonomy supplies 'clear guidelines' with minimal overlap.
minor comments (2)
- [Taxonomy and benchmark overview sections] A summary table listing representative benchmarks per dimension (with brief notes on their primary assignment) would improve readability and allow readers to assess the taxonomy's application directly.
- [Abstract and Conclusion] The statement that the collection of surveyed papers 'will be released' should include a concrete URL, repository link, or timeline in the current version.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address the two major comments below and will incorporate clarifications to improve verifiability and taxonomy rigor.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and Introduction: No explicit search strategy, inclusion/exclusion criteria, date range, or total count of surveyed papers is stated, which directly affects verifiability of the claim that the taxonomy provides comprehensive coverage of LALM evaluations.
Authors: We agree that an explicit description of the survey methodology is needed for verifiability. In the revised manuscript we will add a new subsection (likely in the Introduction) that states the search strategy (keywords such as 'large audio-language model' AND 'benchmark' or 'evaluation', databases including arXiv, ACL Anthology, and Google Scholar), inclusion criteria (benchmarks specifically targeting LALMs or audio-augmented LLMs, published or posted 2023–2025), exclusion criteria (purely text-based LLM evaluations, non-benchmark papers), date range, and the final count of surveyed papers and benchmarks. This addition will directly support the claim of comprehensive coverage. revision: yes
-
Referee: [Taxonomy section] Taxonomy presentation (likely §3): The four dimensions are introduced without boundary definitions, assignment rules, or an explicit audit for overlaps; in particular, the boundary between 'Knowledge and Reasoning' and 'Dialogue-oriented Ability' is not addressed even though dialogue tasks routinely embed reasoning over auditory input, weakening the assertion that the taxonomy supplies 'clear guidelines' with minimal overlap.
Authors: We accept that the current presentation lacks explicit boundary definitions and overlap analysis. We will revise the taxonomy section to include (1) concise definitions for each dimension, (2) assignment rules based on the primary evaluation objective, and (3) a dedicated paragraph discussing potential overlaps, with specific attention to the boundary between Knowledge and Reasoning and Dialogue-oriented Ability. We will illustrate classification decisions with examples (e.g., a dialogue task whose main goal is multi-turn interaction versus one whose main goal is auditory reasoning) and note that the taxonomy is intended to be pragmatic rather than perfectly disjoint. These additions will strengthen the claim that the taxonomy provides clear guidelines. revision: yes
Circularity Check
No circularity: survey taxonomy is independent synthesis of external benchmarks
full rationale
This paper is a literature survey with no mathematical derivations, equations, fitted parameters, or predictions. It proposes a four-dimension taxonomy by categorizing existing benchmarks according to evaluation objectives, presented as an independent synthesis drawn from external literature. The claim of being the first such survey does not rely on load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. No step reduces by construction to the paper's own inputs; the structure is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing LALM benchmarks can be systematically grouped into four objective-based dimensions without substantial overlap or omission.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We organize the surveyed works into four categories by evaluation objectives: (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
some benchmarks are listed under multiple categories due to their multifaceted design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Voice, Bias, and Coreference: An Interpretability Study of Gender in Speech Translation
ST models override masculine ILM biases with acoustic input, using first-person pronouns to link terms to the speaker and accessing gender cues across the full frequency spectrum rather than pitch alone.
-
Game-Time: Evaluating Temporal Dynamics in Spoken Language Models
Game-Time Benchmark shows spoken language models handle basic tasks but degrade sharply under temporal constraints like tempo adherence and synchronized responses.
-
Synchronization and Turn-Taking in Full-Duplex Speech Dialogue Models
Full-duplex SDMs show strong representational synchronization that peaks near zero lag and degrades with noise, with internal states encoding anticipatory turn-taking cues detectable ahead of time.
-
When Silence Matters: The Impact of Irrelevant Audio on Text Reasoning in Large Audio-Language Models
Irrelevant audio including silence reduces accuracy and increases volatility in text reasoning for large audio-language models, with effects worsening at longer durations, higher amplitudes, and higher temperatures.
Reference graph
Works this paper leans on
-
[1]
V oxeval: Benchmarking the knowledge under- standing capabilities of end-to-end spoken language models.arXiv preprint arXiv:2501.04962. Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, and Ir- win King. 2024. Recent advances in speech language models: A survey.arXiv preprint arXiv:2410.03751. Michaël Defferrard, K...
-
[2]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594. Isha Gupta, David Khachaturov, and Robert Mullins
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
" i am bad": Interpreting stealthy, universal and robust audio jailbreaks in audio-language models. arXiv preprint arXiv:2502.00718. Michael Hassid, Tal Remez, Tu Anh Nguyen, Itai Gat, Alexis Conneau, Felix Kreuk, Jade Copet, Alexan- dre Defossez, Gabriel Synnaeve, Emmanuel Dupoux, and 1 others. 2023. Textually pretrained speech lan- guage models.Advances...
-
[4]
IEEE. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
-
[5]
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel- rahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio,...
-
[6]
Low resource asr: The surprising effectiveness of high resource transliteration. InProc. Interspeech 2021, pages 1529–1533. Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. AudioCaps: Generating cap- tions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational L...
-
[7]
IEEE. Kushal Lakhotia, Eugene Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-Anh Nguyen, Jade Copet, Alexei Baevski, Abdelrahman Mohamed, and 1 others. 2021. On generative spo- ken language modeling from raw audio.Transac- tions of the Association for Computational Linguis- tics, 9:1336–1354. Marvin Lavechin, Yaya Sy, Hadrien Titeux,...
work page 2021
-
[8]
Language model personalization for speech recognition: A clustered federated learning approach with adaptive weight average.IEEE Signal Process- ing Letters, 31:2710–2714. Sicong Leng, Yun Xing, Zesen Cheng, Yang Zhou, Hang Zhang, Xin Li, Deli Zhao, Shijian Lu, Chun- yan Miao, and Lidong Bing. 2024. The curse of multi-modalities: Evaluating hallucinations...
-
[9]
In2024 IEEE Spo- ken Language Technology Workshop (SLT), pages 1115–1122
Whisma: A speech-llm to perform zero-shot spoken language understanding. In2024 IEEE Spo- ken Language Technology Workshop (SLT), pages 1115–1122. IEEE. Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao MA, Chenghua Lin, Xingran Chen, Anton Ragni, Hanzhi Yin, Zhijie Hu, Haoyu He, and 1 others. 2022. Map- music2vec: A simple and effective baseline for self- supervi...
-
[10]
Jan Melechovsky, Abhinaba Roy, and Dorien Herre- mans
Empathic voice assistants: Enhancing con- sumer responses in voice commerce.Journal of Busi- ness Research, 175:114566. Jan Melechovsky, Abhinaba Roy, and Dorien Herre- mans. 2024. Midicaps: A large-scale midi dataset with text captions. InProceedings of the 25th In- ternational Society for Music Information Retrieval Conference, pages 858–865. ISMIR. Nas...
work page 2024
-
[11]
InNeuRIPS Workshop on Self- Supervised Learning for Speech and Audio Process- ing
The zero resource speech benchmark 2021: Metrics and baselines for unsupervised spoken lan- guage modeling. InNeuRIPS Workshop on Self- Supervised Learning for Speech and Audio Process- ing. James D Orcutt and Lynn Kenneth Harvey. 1985. De- viance, rule-breaking and male dominance in conver- sation.Symbolic Interaction, 8(1):15–32. Vassil Panayotov, Guogu...
-
[12]
ACM Press. Karol J Piczak. 2015b. Esc: Dataset for environmental sound classification. InProceedings of the 23rd ACM international conference on Multimedia, pages 1015– 1018. Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. Mls: A large- scale multilingual dataset for speech research. In Proc. Interspeech 2020, page...
work page 2020
-
[13]
Harvey Sacks, Emanuel A Schegloff, and Gail Jefferson
Multilingual and multi-accent jailbreaking of audio llms.arXiv preprint arXiv:2504.01094. Harvey Sacks, Emanuel A Schegloff, and Gail Jefferson
-
[14]
A simplest systematics for the organization of turn-taking for conversation.language, 50(4):696– 735. Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. Utmos: Utokyo-sarulab system for voicemos challenge 2022. InProceedings of the An- nual Conference of the International Speech Commu- nication As...
-
[15]
InInterspeech 2021, pages 2247–2251
Covost 2 and massively multilingual speech translation. InInterspeech 2021, pages 2247–2251. Siyin Wang, Wenyi Yu, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Yu Tsao, Junichi Yamagishi, Yuxuan Wang, and Chao Zhang. 2025c. Qualispeech: A speech quality assessment dataset with natural lan- guage reasoning and descriptions.arXiv preprint arXiv:2503.20290. Yingz...
-
[16]
InPro- ceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR)
Muchomusic: Evaluating music understand- ing in multimodal audio-language models. InPro- ceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR). Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large l...
-
[17]
Uro-bench: A comprehensive benchmark for end-to-end spoken dialogue models.arXiv preprint arXiv:2502.17810. Chih-Kai Yang, Yu-Kuan Fu, Chen-An Li, Yi-Cheng Lin, Yu-Xiang Lin, Wei-Chih Chen, Ho Lam Chung, Chun-Yi Kuan, Wei-Ping Huang, Ke-Han Lu, and 1 others. 2024a. Building a taiwanese mandarin spo- ken language model: A first attempt.arXiv preprint arXiv...
-
[18]
is a fundamental aspect of conversational or- ganization, where speakers alternate turns to speak, ensuring only one person talks at a time. This pro- cess is complex, involving various behaviors that help facilitate smooth transitions between speakers. Dataset # of Benchmarks Using the Dataset AudioCaps 6 Clotho 5 ESC-50 3 AudioSet 8 V ocalSound 2 LibriS...
work page 1972
-
[19]
has been increasingly adopted to provide flexible, criterion-driven evaluations tailored to re- searchers’ specific needs. J Information on AI Assistance We acknowledge the assistance of GPT-4.1-mini in refining the paper and improving its clarity. Benchmark Real Data Synthetic Data SALMon (Maimon et al., 2025) ✓ ✓ EmphAssess (Seyssel et al., 2024) ✓ Dyna...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.