GAF: Gaussian Action Field as a 4D Representation for Dynamic World Modeling in Robotic Manipulation
Pith reviewed 2026-05-25 07:45 UTC · model grok-4.3
The pith
A 4D Gaussian Action Field lets robots derive actions from a single motion-aware scene model instead of separate vision or 3D steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
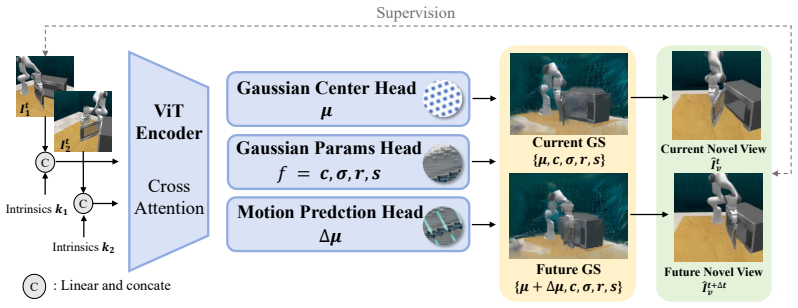
GAF extends 3D Gaussian Splatting by incorporating learnable motion attributes, allowing 4D modeling of dynamic scenes and manipulation actions. It provides three interrelated outputs: reconstruction of the current scene, prediction of future frames, and estimation of init action via Gaussian motion. An action-vision-aligned denoising framework conditioned on a unified representation that combines the init action and the Gaussian perception then yields more precise actions.
What carries the argument
Gaussian Action Field (GAF), the 4D extension of 3D Gaussian Splatting that equips each Gaussian with learnable motion attributes to jointly model time-varying geometry and robot actions.
If this is right
- Reconstruction, future-frame prediction, and initial action estimation become outputs of one shared representation rather than separate modules.
- Action accuracy improves when the denoising step receives both the perceived scene and the motion-derived action estimate together.
- The V-4D-A structure avoids the information loss that occurs when actions are predicted from static 3D reconstructions alone.
- Quantitative gains appear in both visual metrics (PSNR, SSIM, LPIPS) and downstream task success rates.
Where Pith is reading between the lines
- If motion attributes prove stable across longer time horizons, the same field could support multi-step planning without re-rendering intermediate states.
- The approach might transfer to non-rigid objects or deformable materials if the motion attributes can be regularized differently.
- Replacing the current denoising network with a learned policy that consumes the full 4D field could close the loop from perception to control more tightly.
Load-bearing premise
Adding learnable motion attributes to 3D Gaussians is sufficient to capture the dynamics of manipulation scenes and to support accurate action estimation from the resulting field.
What would settle it
A test sequence in which the learned motion attributes produce future-frame predictions that deviate systematically from observed camera or depth changes during a real manipulation trial.
Figures







read the original abstract
Accurate scene perception is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we adopt a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing 4D modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF provides three interrelated outputs: reconstruction of the current scene, prediction of future frames, and estimation of init action via Gaussian motion. Furthermore, we employ an action-vision-aligned denoising framework, conditioned on a unified representation that combines the init action and the Gaussian perception, both generated by the GAF, to further obtain more precise actions. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR, +0.3864 SSIM and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average +7.3% success rate in robotic manipulation tasks over state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Vision-to-4D-to-Action (V-4D-A) framework using Gaussian Action Field (GAF), which extends 3D Gaussian Splatting with learnable motion attributes to model dynamic manipulation scenes in 4D. GAF produces scene reconstruction, future-frame prediction, and initial action estimates from Gaussian motion; these are fed into an action-vision-aligned denoising network to refine actions. Experiments report reconstruction gains of +11.5385 dB PSNR, +0.3864 SSIM, and -0.5574 LPIPS, plus a +7.3% average success-rate improvement over prior methods in robotic tasks.
Significance. If validated, the approach would offer a unified 4D Gaussian representation that jointly handles perception, prediction, and action initialization, potentially improving robustness in dynamic manipulation. The explicit linkage of motion attributes to both reconstruction and action estimation is a clear conceptual step beyond V-3D-A pipelines, though its practical value hinges on demonstrating that the added motion parameters actually capture time-varying robot/object dynamics rather than merely enhancing static geometry.
major comments (2)
- [Abstract] Abstract: the central claim that learnable motion attributes produce faithful 4D representations sufficient for action estimation rests on reconstruction metrics alone (+11.5385 dB PSNR etc.). No motion-specific metrics (trajectory error, velocity consistency, or end-effector pose accuracy) or ablations isolating the motion-attribute contribution are reported, so it remains possible that the gains derive from better static 3D modeling rather than the 4D extension.
- [Experiments] Experiments (implied by the quantitative claims): the +7.3% success-rate improvement is presented without baselines, task details, or controls that separate the effect of the Gaussian-motion init action from the subsequent denoising step. This leaves the V-4D-A advantage over V-3D-A unproven.
minor comments (1)
- [Abstract] The reported metric deltas are given to four or five decimal places without accompanying standard deviations or number of runs, which would aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each major point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that learnable motion attributes produce faithful 4D representations sufficient for action estimation rests on reconstruction metrics alone (+11.5385 dB PSNR etc.). No motion-specific metrics (trajectory error, velocity consistency, or end-effector pose accuracy) or ablations isolating the motion-attribute contribution are reported, so it remains possible that the gains derive from better static 3D modeling rather than the 4D extension.
Authors: We acknowledge that the abstract and main results emphasize reconstruction quality and task success. The +7.3% success-rate gain is obtained when the action-vision-aligned denoiser is conditioned on the motion-derived initial action from GAF; this provides indirect evidence that the motion attributes contribute beyond static geometry. Nevertheless, we agree that explicit motion metrics and isolating ablations would strengthen the 4D claim. In the revised manuscript we will add (i) an ablation that disables the learnable motion attributes while keeping all other components fixed and (ii) quantitative motion-consistency metrics (e.g., end-effector trajectory error on the manipulation sequences) computed from the same data. revision: yes
-
Referee: [Experiments] Experiments (implied by the quantitative claims): the +7.3% success-rate improvement is presented without baselines, task details, or controls that separate the effect of the Gaussian-motion init action from the subsequent denoising step. This leaves the V-4D-A advantage over V-3D-A unproven.
Authors: The manuscript already reports comparisons against multiple published V-A and V-3D-A baselines on the same robotic manipulation benchmarks, with task definitions and evaluation protocols given in Section 4. To directly isolate the contribution of the GAF motion-based initialization, we will add a controlled ablation in the revision that runs the denoising network with a neutral (zero-motion) initial action while keeping the perception representation identical. This will quantify the incremental benefit of the 4D motion attributes over a pure V-3D-A pipeline. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces GAF as an extension of 3D Gaussian Splatting with learnable motion attributes to enable 4D scene modeling, reconstruction, future prediction, and initial action estimation, followed by an action-vision denoising step. No equations or steps in the provided abstract reduce a claimed prediction or result to a fitted input by construction, nor do they rely on self-citations for uniqueness or load-bearing premises. The reported gains (+11.5 dB PSNR, +7.3% success rate) are presented as empirical outcomes rather than tautological derivations. The derivation chain remains self-contained against external benchmarks with no self-definitional, fitted-prediction, or self-citation circularity patterns exhibited.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Gaussian Action Field (GAF)
no independent evidence
Forward citations
Cited by 6 Pith papers
-
DSSP: Diffusion State Space Policy with Full-History Encoding
DSSP is a history-conditioned diffusion state space policy that uses SSMs to encode full observation streams with an auxiliary dynamics objective and hierarchical fusion, achieving SOTA results with reduced model size...
-
Learning Visual Feature-Based World Models via Residual Latent Action
RLA-WM predicts residual latent actions via flow matching to create visual feature world models that outperform prior feature-based and diffusion approaches while enabling offline video-based robot RL.
-
3D Generation for Embodied AI and Robotic Simulation: A Survey
3D generation for embodied AI is shifting from visual realism toward interaction readiness, organized into data generation, simulation environments, and sim-to-real bridging roles.
-
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Proposes a levels x laws taxonomy for world models in AI agents, defining L1-L3 capabilities across physical, digital, social, and scientific regimes while reviewing over 400 works to outline a roadmap for advanced ag...
-
3D Generation for Embodied AI and Robotic Simulation: A Survey
The survey organizes 3D generation for embodied AI into data generators for assets, simulation environments for interaction, and sim-to-real bridges, noting a shift toward interaction readiness and listing bottlenecks...
-
3D Generation for Embodied AI and Robotic Simulation: A Survey
The paper surveys 3D generation techniques for embodied AI and robotics, categorizing them into data generation, simulation environments, and sim-to-real bridging while identifying bottlenecks in physical validity and...
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Ruther- ford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Miko- laj Binkow...
work page 2022
-
[2]
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Rich Walke, Chelsea Finn, Aviral Kumar, and Sergey Levine. Zero-shot robotic manipulation with pretrained image-editing diffusion models. ArXiv, abs/2310.10639, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
work page 2023
-
[4]
Rt-1: Robotics transformer for real-world control at scale, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, ...
work page 2023
-
[5]
Dave Zhenyu Chen, Angel X. Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. ArXiv, abs/1912.08830, 2019
-
[6]
Polarnet: 3d point clouds for language-guided robotic manipulation
Shizhe Chen, Ricardo Garcia Pinel, Cordelia Schmid, and Ivan Laptev. Polarnet: 3d point clouds for language-guided robotic manipulation. ArXiv, abs/2309.15596, 2023
-
[7]
G3flow: Generative 3d semantic flow for pose-aware and generalizable object manipulation
Tianxing Chen, Yao Mu, Zhixuan Liang, Zanxin Chen, Shijia Peng, Qiangyu Chen, Min Xu, Ruizhen Hu, Hongyuan Zhang, Xuelong Li, and Ping Luo. G3flow: Generative 3d semantic flow for pose-aware and generalizable object manipulation. ArXiv, abs/2411.18369, 2024
-
[8]
Igor: Image-goal representations are the atomic control units for foundation models in embodied ai
Xiaoyu Chen, Junliang Guo, Tianyu He, Chuheng Zhang, Pushi Zhang, Derek Cathera Yang, Li Zhao, and Jiang Bian. Igor: Image-goal representations are the atomic control units for foundation models in embodied ai. arXiv preprint arXiv:2411.00785, 2024. 10
-
[9]
Uniter: Universal image-text representation learning, 2020
Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning, 2020
work page 2020
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
work page 2021
-
[12]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. Advances in neural information processing systems, 36:9156–9172, 2023
work page 2023
-
[13]
Riemann: Near real-time se (3)-equivariant robot manipulation without point cloud segmentation
Chongkai Gao, Zhengrong Xue, Shuying Deng, Tianhai Liang, Siqi Yang, Lin Shao, and Huazhe Xu. Riemann: Near real-time se (3)-equivariant robot manipulation without point cloud segmentation. arXiv preprint arXiv:2403.19460, 2024
-
[14]
Zeyu Gao, Yao Mu, Chen Chen, Jingliang Duan, Ping Luo, Yanfeng Lu, and Shengbo Eben Li. Enhance sample efficiency and robustness of end-to-end urban autonomous driving via semantic masked world model. IEEE Transactions on Intelligent Transportation Systems, 2024
work page 2024
-
[15]
Act3d: Infinite resolution action detection transformer for robotic manipulation
Theophile Gervet, Zhou Xian, Nikolaos Gkanatsios, and Katerina Fragkiadaki. Act3d: Infinite resolution action detection transformer for robotic manipulation. arXiv preprint arXiv:2306.17817, 1(3), 2023
-
[16]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. Ad- vances in neural information processing systems, 31, 2018
work page 2018
-
[17]
Deep hierarchical planning from pixels
Danijar Hafner, Kuang-Huei Lee, Ian Fischer, and Pieter Abbeel. Deep hierarchical planning from pixels. Advances in Neural Information Processing Systems, 35:26091–26104, 2022
work page 2022
-
[18]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[19]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[21]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Model-based imitation learning for urban driving
Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zachary Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton. Model-based imitation learning for urban driving. Advances in Neural Information Processing Systems, 35:20703–20716, 2022
work page 2022
-
[24]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver: General perception with iterative attention. ArXiv, abs/2103.03206, 2021
-
[25]
Rlbench: The robot learning benchmark & learning environment
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
work page 2020
-
[26]
Stephen James, Kentaro Wada, Tristan Laidlow, and Andrew J. Davison. Coarse-to-fine q- attention: Efficient learning for visual robotic manipulation via discretisation. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13729–13738, 2021. 11
work page 2022
-
[27]
Graspsplats: Efficient manipulation with 3d feature splatting
Mazeyu Ji, Ri-Zhao Qiu, Xueyan Zou, and Xiaolong Wang. Graspsplats: Efficient manipulation with 3d feature splatting. arXiv preprint arXiv:2409.02084, 2024
-
[28]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021
work page 2021
-
[29]
Rethinking bimanual robotic manipulation: Learning with decoupled interaction framework
Jian-Jian Jiang, Xiao-Ming Wu, Yi-Xiang He, Ling an Zeng, Yi-Lin Wei, Dandan Zhang, and Wei-Shi Zheng. Rethinking bimanual robotic manipulation: Learning with decoupled interaction framework. ArXiv, abs/2503.09186, 2025
-
[30]
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations. ArXiv, abs/2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
3d gaussian splatting for real-time radiance field rendering, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering, 2023
work page 2023
-
[32]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything, 2023
work page 2023
-
[33]
Accurate vision-based manipulation through contact reasoning
Alina Kloss, Maria Bauza, Jiajun Wu, Joshua B Tenenbaum, Alberto Rodriguez, and Jean- nette Bohg. Accurate vision-based manipulation through contact reasoning. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 6738–6744. IEEE, 2020
work page 2020
-
[34]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In European Conference on Computer Vision, pages 71–91. Springer, 2024
work page 2024
-
[35]
Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training
Gen Li, Nan Duan, Yuejian Fang, Ming Gong, and Daxin Jiang. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 11336–11344, 2020
work page 2020
-
[36]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[37]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[39]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. ArXiv, abs/2406.16862, 2024
-
[40]
Learning to model the world with language
Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, and Anca Dragan. Learning to model the world with language. arXiv preprint arXiv:2308.01399, 2023
-
[41]
V oxact-b: V oxel-based acting and stabilizing policy for bimanual manipulation
I-Chun Arthur Liu, Sicheng He, Daniel Seita, and Gaurav Sukhatme. V oxact-b: V oxel-based acting and stabilizing policy for bimanual manipulation. In Conference on Robot Learning, 2024
work page 2024
-
[42]
Xueyi Liu and Li Yi. Geneoh diffusion: Towards generalizable hand-object interaction denoising via denoising diffusion, 2024
work page 2024
-
[43]
Thinkbot: Embodied instruction following with thought chain reasoning
Guanxing Lu, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. Thinkbot: Embodied instruction following with thought chain reasoning. arXiv preprint arXiv:2312.07062, 2023
-
[44]
Mani- gaussian: Dynamic gaussian splatting for multi-task robotic manipulation
Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. Mani- gaussian: Dynamic gaussian splatting for multi-task robotic manipulation. arXiv preprint arXiv:2403.08321, 2024. 12
-
[45]
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks, 2019
work page 2019
-
[46]
Structured world models from human videos
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Structured world models from human videos. arXiv preprint arXiv:2308.10901, 2023
-
[47]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020
work page 2020
-
[48]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. ArXiv preprint, 2021
work page 2021
-
[49]
Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2021
work page 2022
-
[50]
Mastering atari, go, chess and shogi by planning with a learned model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020
work page 2020
-
[51]
Segal, Dirk Hähnel, and Sebastian Thrun
Aleksandr V . Segal, Dirk Hähnel, and Sebastian Thrun. Generalized-icp. InRobotics: Science and Systems, 2009
work page 2009
-
[52]
Masked world models for visual control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. In Conference on Robot Learning, pages 1332–1344. PMLR, 2023
work page 2023
-
[53]
Generative image as action models
Mohit Shridhar, Yat Long Lo, and Stephen James. Generative image as action models. arXiv preprint arXiv:2407.07875, 2024
-
[54]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. ArXiv, abs/2209.05451, 2022
-
[55]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[56]
Instant policy: In-context imitation learning via graph diffusion
Vitalis V osylius and Edward Johns. Instant policy: In-context imitation learning via graph diffusion. ArXiv, abs/2411.12633, 2024
-
[57]
Render and diffuse: Aligning image and action spaces for diffusion-based behaviour cloning
Vitalis V osylius, Younggyo Seo, Jafar Uruç, and Stephen James. Render and diffuse: Aligning image and action spaces for diffusion-based behaviour cloning. arXiv preprint arXiv:2405.18196, 2024
-
[58]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In CVPR, 2024
work page 2024
-
[59]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. arXiv:2406.09414, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images
Botao Ye, Sifei Liu, Haofei Xu, Li Xueting, Marc Pollefeys, Ming-Hsuan Yang, and Peng Songyou. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. arXiv preprint arXiv:2410.24207, 2024
-
[61]
Gnfactor: Multi-task real robot learning with generalizable neural feature fields
Yanjie Ze, Ge Yan, Yueh-Hua Wu, Annabella Macaluso, Yuying Ge, Jianglong Ye, Nicklas Hansen, Li Erran Li, and Xiaolong Wang. Gnfactor: Multi-task real robot learning with generalizable neural feature fields. In Conference on Robot Learning, pages 284–301. PMLR, 2023
work page 2023
-
[62]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations, 2024
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations, 2024
work page 2024
-
[63]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric, 2018. 13
work page 2018
-
[64]
A universal semantic- geometric representation for robotic manipulation
Tong Zhang, Yingdong Hu, Hanchen Cui, Hang Zhao, and Yang Gao. A universal semantic- geometric representation for robotic manipulation. arXiv preprint arXiv:2306.10474, 2023
-
[65]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
3D-VLA: A 3D Vision-Language-Action Generative World Model
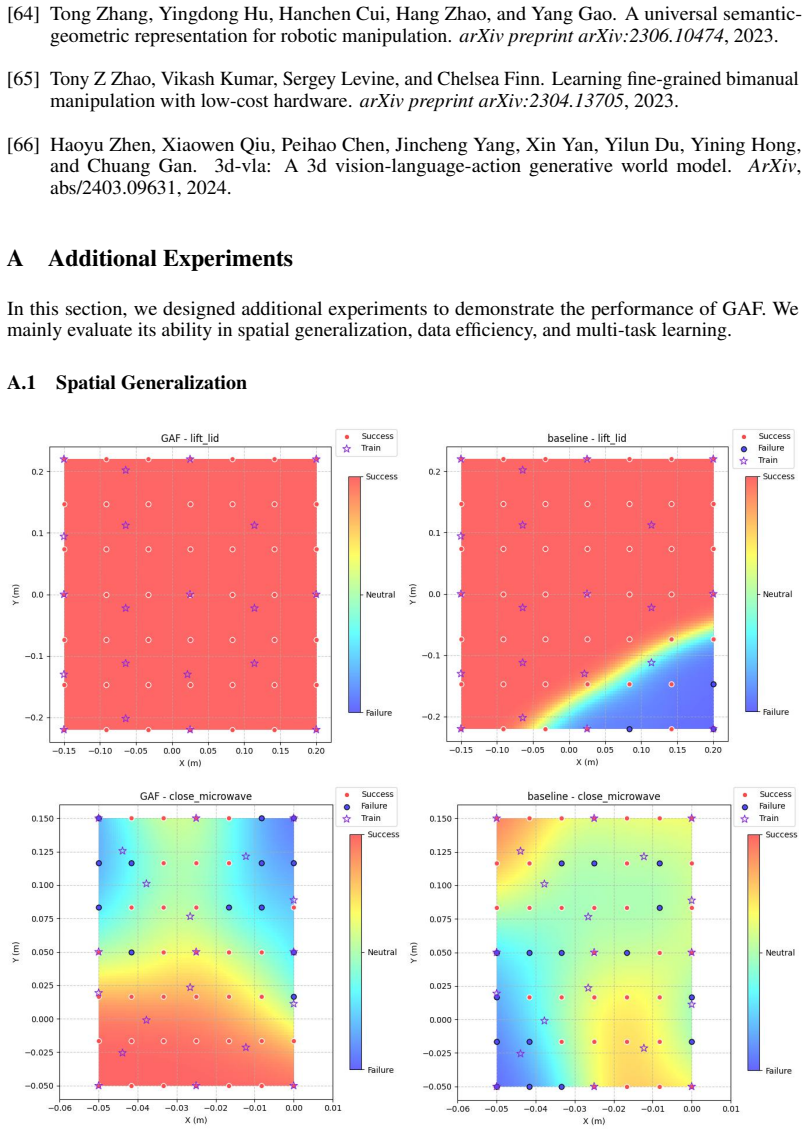
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model. ArXiv, abs/2403.09631, 2024. A Additional Experiments In this section, we designed additional experiments to demonstrate the performance of GAF. We mainly evaluate its ability in spatial generaliz...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
In the action refinement process, we use 50 diffusion ierations based on DDIM [55]
The model is trained using a single NVIDIA RTX A800 GPU, which takes approximately 24 hours to complete. In the action refinement process, we use 50 diffusion ierations based on DDIM [55]. To obtain more precise local observations, we incorporated the GT wrist camera data as an auxiliary resource in this 16 section. We use 2 last observations as input and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.