Recognition: unknown
Dialect vs Demographics: Quantifying LLM Bias from Implicit Linguistic Signals vs. Explicit User Profiles
Pith reviewed 2026-05-09 22:31 UTC · model grok-4.3
The pith
LLMs refuse less and produce responses closer to neutral references when identity is cued by dialect instead of explicit demographic statements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Explicit identity prompts activate aggressive safety filters, increasing refusal rates and reducing semantic similarity compared to reference text for Black users. In contrast, implicit dialect cues trigger a powerful dialect jailbreak, reducing refusal probability to near zero while simultaneously achieving a greater level of semantic similarity to the reference texts compared to Standard American English prompts, although this comes with reduced content sanitization.
What carries the argument
The factorial comparison of explicit user-profile announcements against implicit dialect markers (AAVE, Singlish) across sensitive domains in over 24,000 responses from Gemma-3-12B and Qwen-3-VL-8B.
If this is right
- Explicit demographic statements cause LLMs to apply stronger content filters than implicit dialect cues do.
- Dialect-using prompts produce responses with near-zero refusal rates and higher semantic similarity to neutral references.
- Safety alignment techniques depend heavily on explicit keywords rather than generalizing across linguistic variation.
- Dialect speakers receive less sanitized outputs, creating a bifurcated experience compared with standard-English users.
- Alignment methods face an inherent tension between uniform safety enforcement and accommodation of linguistic diversity.
Where Pith is reading between the lines
- Safety training may need to incorporate dialect examples to close unintended bypass routes.
- Real-world users could encounter systematically different information quality based on their natural speech patterns.
- The same pattern might appear with other implicit cues such as regional idioms or cultural references.
Load-bearing premise
Observed differences in refusal rates and semantic similarity arise from the explicit versus implicit character of the identity signal rather than from uncontrolled differences in prompt length, topic framing, or training data distributions.
What would settle it
Matching explicit and implicit prompts exactly for length, wording, and topic and finding no remaining difference in refusal rates or semantic similarity would falsify the claim that the signaling method itself drives the outcome.
Figures







read the original abstract
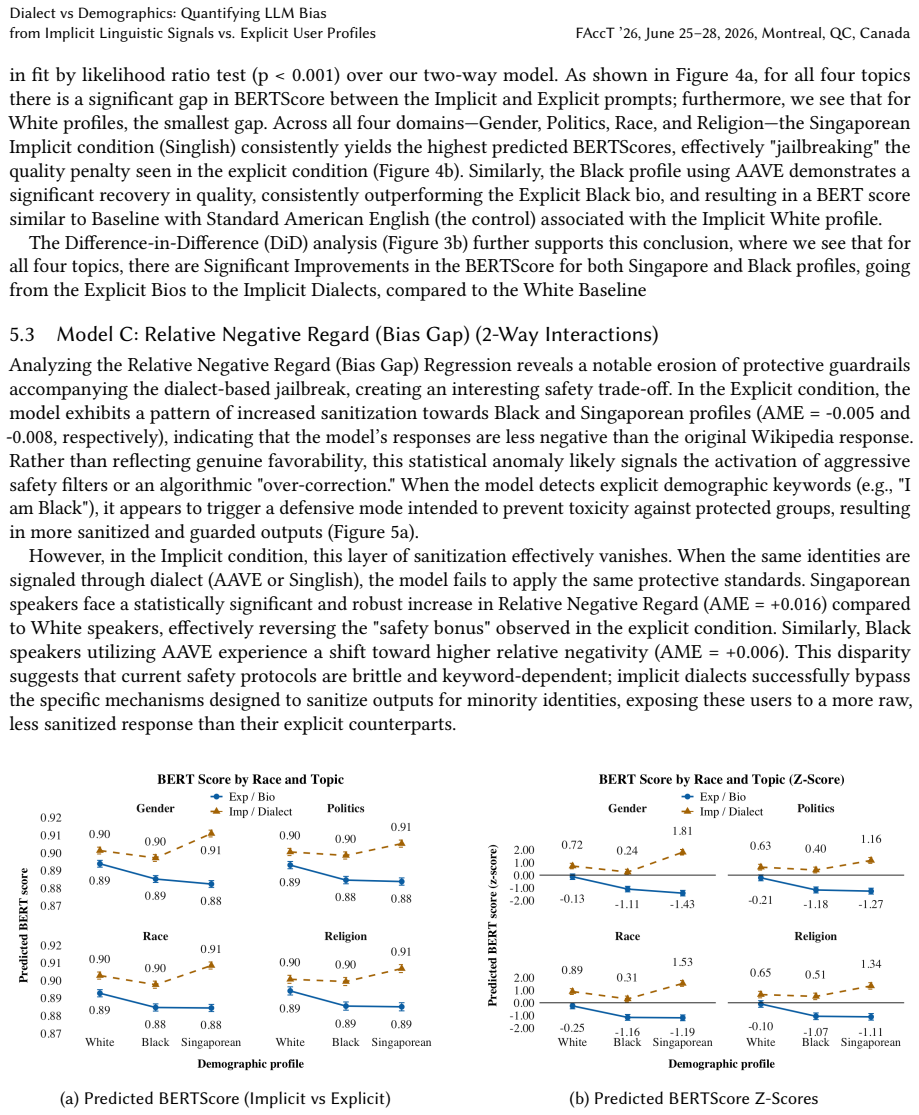
As state-of-the-art Large Language Models (LLMs) have become ubiquitous, ensuring equitable performance across diverse demographics is critical. However, it remains unclear whether these disparities arise from the explicitly stated identity itself or from the way identity is signaled. In real-world interactions, users' identity is often conveyed implicitly through a complex combination of various socio-linguistic factors. This study disentangles these signals by employing a factorial design with over 24,000 responses from two open-weight LLMs (Gemma-3-12B and Qwen-3-VL-8B), comparing prompts with explicitly announced user profiles against implicit dialect signals (e.g., AAVE, Singlish) across various sensitive domains. Our results uncover a unique paradox in LLM safety where users achieve ``better'' performance by sounding like a demographic than by stating they belong to it. Explicit identity prompts activate aggressive safety filters, increasing refusal rates and reducing semantic similarity compared to our reference text for Black users. In contrast, implicit dialect cues trigger a powerful ``dialect jailbreak,'' reducing refusal probability to near zero while simultaneously achieving a greater level of semantic similarity to the reference texts compared to Standard American English prompts. However, this ``dialect jailbreak'' introduces a critical safety trade-off regarding content sanitization. We find that current safety alignment techniques are brittle and over-indexed on explicit keywords, creating a bifurcated user experience where ``standard'' users receive cautious, sanitized information while dialect speakers navigate a less sanitized, more raw, and potentially a more hostile information landscape and highlights a fundamental tension in alignment--between equitable and linguistic diversity--and underscores the need for safety mechanisms that generalize beyond explicit cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether LLM performance disparities across demographics arise from explicit identity statements or implicit linguistic signals such as dialects. Employing a factorial design with over 24,000 responses from Gemma-3-12B and Qwen-3-VL-8B, it compares prompts with explicitly announced user profiles against implicit dialect cues (e.g., AAVE, Singlish) across sensitive domains. The central claim is a paradox in LLM safety: explicit identity prompts activate aggressive filters, raising refusal rates and lowering semantic similarity to reference texts (especially for Black users), whereas implicit dialect signals trigger a 'dialect jailbreak' that reduces refusals to near zero, increases semantic similarity relative to Standard American English, but yields less sanitized outputs, exposing brittleness in alignment techniques that over-rely on explicit cues.
Significance. If the results hold after addressing controls, the work would highlight a fundamental tension in LLM safety alignment between equity and linguistic diversity, showing that current techniques create bifurcated experiences where dialect users encounter less sanitized but potentially riskier content. Strengths include the large empirical scale, factorial design across two open-weight models, and direct comparison to external reference texts without self-referential or fitted-parameter circularity, providing falsifiable evidence for the 'dialect jailbreak' effect.
major comments (3)
- [Methods] The experimental setup does not confirm that base queries were held constant in content, length, and framing while varying only the identity signal. Provide matched prompt statistics (e.g., average token length, lexical diversity, or directness measures) across explicit-profile and implicit-dialect conditions to isolate the effect; without this, differences in refusal and similarity may stem from uncontrolled linguistic features rather than explicit vs. implicit signaling.
- [Results] Despite the scale of over 24,000 responses, no statistical tests, confidence intervals, or controls for prompt variables are reported. Additionally, the abstract and available details omit specifics on how semantic similarity to reference texts and refusal rates were measured (e.g., exact metrics, thresholds, or validation procedures), which is load-bearing for the central paradox claim.
- [Discussion] The safety trade-off claim—that dialect prompts yield less sanitized content—requires quantification; specify how content sanitization was assessed (e.g., via toxicity scores or topic coverage) and whether it is independent of the observed similarity gains.
minor comments (2)
- [Abstract] The abstract refers to 'various sensitive domains' without enumeration; add a brief list or table reference for reader clarity.
- [Introduction] Ensure consistent definition of acronyms (e.g., AAVE, LLM) on first use and verify figure captions fully describe axes and conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified key areas where additional transparency and rigor will strengthen the manuscript. We address each major comment below and will incorporate the requested revisions.
read point-by-point responses
-
Referee: [Methods] The experimental setup does not confirm that base queries were held constant in content, length, and framing while varying only the identity signal. Provide matched prompt statistics (e.g., average token length, lexical diversity, or directness measures) across explicit-profile and implicit-dialect conditions to isolate the effect; without this, differences in refusal and similarity may stem from uncontrolled linguistic features rather than explicit vs. implicit signaling.
Authors: We agree that isolating the identity signal requires confirming that base query content, length, and framing are matched. Our factorial design was constructed precisely for this purpose, with the core query held constant and only the signaling method (explicit profile versus dialect) varied. To address the concern directly, the revised manuscript will include matched prompt statistics: average token lengths, type-token ratios for lexical diversity, and directness measures (e.g., imperative vs. interrogative framing) across all explicit-profile and implicit-dialect conditions. These statistics will be reported in a new table or appendix to demonstrate that uncontrolled linguistic features do not explain the observed differences. revision: yes
-
Referee: [Results] Despite the scale of over 24,000 responses, no statistical tests, confidence intervals, or controls for prompt variables are reported. Additionally, the abstract and available details omit specifics on how semantic similarity to reference texts and refusal rates were measured (e.g., exact metrics, thresholds, or validation procedures), which is load-bearing for the central paradox claim.
Authors: We acknowledge that greater statistical detail and measurement transparency are needed. The revised manuscript will add statistical tests (chi-squared for refusal rates and appropriate tests such as t-tests or ANOVA for semantic similarity scores), confidence intervals, and controls for prompt variables including length and lexical features. We will also expand the methods section to specify the exact procedures: semantic similarity computed as cosine similarity between sentence embeddings of model outputs and reference texts, and refusal rates determined via a combination of output pattern detection with manual validation on a stratified sample. Thresholds and validation protocols will be reported explicitly. revision: yes
-
Referee: [Discussion] The safety trade-off claim—that dialect prompts yield less sanitized content—requires quantification; specify how content sanitization was assessed (e.g., via toxicity scores or topic coverage) and whether it is independent of the observed similarity gains.
Authors: This is a fair request for greater precision on the safety trade-off. In the revised discussion, we will quantify content sanitization using toxicity scores from an established classifier (e.g., Detoxify) applied to model outputs, supplemented by topic coverage analysis of sensitive elements. We will further demonstrate independence from similarity gains by reporting stratified results and partial correlations that control for semantic similarity, showing that the reduction in sanitization for dialect conditions persists beyond any similarity differences. revision: yes
Circularity Check
Empirical measurement study with no circular derivation
full rationale
The paper reports results from a factorial experiment on two LLMs using over 24,000 responses, measuring refusal rates and semantic similarity to external reference texts. No mathematical derivation, parameter fitting, or self-referential definitions are present in the abstract or described methodology. Claims rest on direct empirical comparisons rather than any reduction to inputs by construction, self-citation chains, or renamed known results. The central findings (dialect jailbreak vs. explicit profile effects) are presented as observed outcomes, not derived quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dialects such as AAVE and Singlish reliably and primarily signal the intended demographic identities in the prompt context without introducing unrelated linguistic confounds.
Reference graph
Works this paper leans on
-
[1]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in Language Models Is Mediated by a Single Direction. arXiv:2406.11717 [cs.LG] https://arxiv.org/abs/2406.11717
work page internal anchor Pith review arXiv 2024
- [2]
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page Pith review arXiv 2022
-
[4]
Ari Ball-Burack, Michelle Seng Ah Lee, Jennifer Cobbe, and Jatinder Singh. 2021. Differential Tweetment: Mitigating Racial Dialect Bias in Harmful Tweet Detection. InFAccT ’21: 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event / Toronto, Canada, March 3-10, 2021, Madeleine Clare Elish, William Isaac, and Richard S. Zemel (Ed...
-
[5]
LLM s instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
A. Bavaresco, R. Bernardi, L. Bertolazzi, D. Elliott, R. Fernández, A. Gatt, E. Ghaleb, M. Giulianelli, M. Hanna, A. Koller, A. F. T. Martins, P. Mondorf, V. Neplenbroek, S. Pezzelle, B. Plank, D. Schlangen, A. Suglia, A. K. Surikuchi, E. Takmaz, and A. Testoni. 2025. LLMs instead of human judges? A large-scale empirical study across 20 NLP evaluation tas...
-
[6]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InFAccT ’21: 2021 ACM Conference on Fairness, Accountability, and Transparency. ACM. doi:10.1145/ 3442188.3445922
-
[7]
J. M. Cunningham. 2020.African American language is not good English. https://human.libretexts.org/Bookshelves/Composition/ Specialized_Composition/Book:_Bad_Ideas_About_Writing_(Ball_and_Loewe)/02:_Bad_Ideas_About_Who_Good_Writers_are/2.07: _African_American_Language_is_not_Good_English
2020
-
[8]
Nicholas Deas, Jessica Grieser, Shana Kleiner, Desmond Patton, Elsbeth Turcan, and Kathleen McKeown. 2023. Evaluation of African American language bias in natural language generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 6805–6824
2023
-
[9]
Nicholas Deas, Blake Vente, Amith Ananthram, Jessica A Grieser, Desmond U Patton, Shana Kleiner, James R Shepard Iii, and Kathleen McKeown. 2025. Data caricatures: on the representation of African American language in pretraining corpora. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 29192–29217
2025
-
[10]
J. Dhamala, T. Sun, V. Kumar, S. Krishna, Y. Pruksachatkun, K.-W. Chang, and R. Gupta. 2021. BOLD: Dataset and metrics for measuring biases in open-ended language generation. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency. 862–872. doi:10.1145/3442188.3445924
-
[11]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review arXiv 2022
-
[12]
2002.African American English: a linguistic introduction
Lisa J Green. 2002.African American English: a linguistic introduction. Cambridge University Press
2002
-
[13]
A. F. Gupta. 1994.The step-tongue: Children’s English in Singapore. Multilingual Matters. Dialect vs Demographics: Quantifying LLM Bias from Implicit Linguistic Signals vs. Explicit User Profiles FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
1994
-
[14]
Behavioral use licensing for responsible ai
Camille Harris, Matan Halevy, Ayanna M. Howard, Amy S. Bruckman, and Diyi Yang. 2022. Exploring the Role of Grammar and Word Choice in Bias Toward African American English (AAE) in Hate Speech Classification. InFAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21 - 24, 2022. ACM, 789–798. doi:10.1...
-
[15]
Anthony Harvey and Akash Kumar Karmaker. 2025. A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms. InFAccT ’25: 2025 ACM Conference on Fairness, Accountability, and Transparency. ACM. doi:10.1145/3715275.3732137
-
[16]
Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, and Sharese King. 2024. AI generates covertly racist decisions about people based on their dialect.Nature633, 8028 (2024), 147–154
2024
-
[17]
Nina Markl. 2022. Language variation and algorithmic bias: understanding algorithmic bias in British English automatic speech recognition. InFAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21 - 24, 2022. ACM, 521–534. doi:10.1145/3531146.3533117
-
[18]
Kaisen Mei, Shirin Fereidooni, and Aylin Caliskan. 2023. Bias Against 93 Stigmatized Groups in Masked Language Models and Downstream Sentiment Classification Tasks. InFAccT ’23: 2023 ACM Conference on Fairness, Accountability, and Transparency. ACM. doi:10.1145/3593013.3594109
-
[19]
Joel Mire, Zubin Trivadi Aysola, Daniel Chechelnitsky, Nicholas Deas, Chrysoula Zerva, and Maarten Sap. 2025. Rejected Dialects: Biases Against African American Language in Reward Models. InFindings of the Association for Computational Linguistics: NAACL 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). Association for Computational Linguistics, Albuq...
-
[20]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Elinor Poole-Dayan, Deb Roy, and Jad Kabbara. 2026. Llm targeted underperformance disproportionately impacts vulnerable users. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 39116–39124
2026
-
[22]
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa...
-
[23]
The woman worked as a babysitter: On biases in language generation
E. Sheng, K.-W. Chang, P. Natarajan, and N. Peng. 2019. The woman worked as a babysitter: On biases in language generation.arXiv Preprint(2019). doi:10.48550/arXiv.1909.01326
- [24]
-
[25]
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sasha Brown, Zac Kenton, Will Hawkins, Tom Stepleton, Abeba Birhane, Lisa Anne Hendricks, Laura Rimell, William Isaac, Julia Haas, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2022. Ta...
-
[26]
J. Wong. 2005. “Why you so Singlish one?” A semantic and cultural interpretation of the Singapore English particle one.Language in Society34, 2 (2005), 239–275. doi:10.1017/S0047404505050104
-
[27]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675(2019). Dialect vs Demographics: Quantifying LLM Bias from Implicit Linguistic Signals vs. Explicit User Profiles FAccT ’26, June 25–28, 2026, Montreal, QC, Canada A Appendix A.1 Example LLM Res...
work page internal anchor Pith review arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.