Recognition: unknown
Measure Twice, Click Once: Co-evolving Proposer and Visual Critic via Reinforcement Learning for GUI Grounding
Pith reviewed 2026-05-09 23:02 UTC · model grok-4.3
The pith
A model learns to critique its own rendered location proposals to improve GUI grounding precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Propose-then-Critic framework, optimized through a maturity-aware adaptive co-evolutionary reinforcement learning paradigm, jointly improves a model's ability to propose candidate pixel coordinates for natural language instructions and to select the correct one by critiquing rendered versions of those proposals on the screenshot. The paradigm dynamically balances the two objectives so that proposal diversity strengthens critic robustness while improving discrimination encourages the proposer to explore more locations, producing mutual reinforcement that supports generalizability across diverse and complex layouts.
What carries the argument
The maturity-aware adaptive co-evolutionary reinforcement learning paradigm, which dynamically balances training objectives for the proposer and critic to enable their mutual improvement.
If this is right
- Grounding accuracy increases on benchmarks containing visually homogeneous elements and dense layouts.
- The critic component gains reliability at selecting correct targets from spatially dispersed candidate predictions.
- The combined system generalizes to a wider range of complex interface layouts.
- Proposal diversity and critique capability reinforce each other during training rather than one remaining limited.
Where Pith is reading between the lines
- Learned visual critics may replace geometric clustering methods in other tasks that require precise localization from dispersed model outputs.
- The adaptive balancing mechanism offers a template for stabilizing training when one sub-skill in a composite model starts weaker than the other.
- Reduced dependence on multiple sampling passes at test time could lower computational cost for deployed interface agents.
Load-bearing premise
The significant disparity between the model's grounding and critiquing capabilities can be reliably bridged by this co-evolutionary reinforcement learning process without causing instability or overfitting to the training interfaces.
What would settle it
A held-out evaluation on GUI layouts absent from training where the co-evolved model's grounding accuracy shows no improvement over a baseline that applies static geometric clustering to the same number of proposals.
Figures









read the original abstract
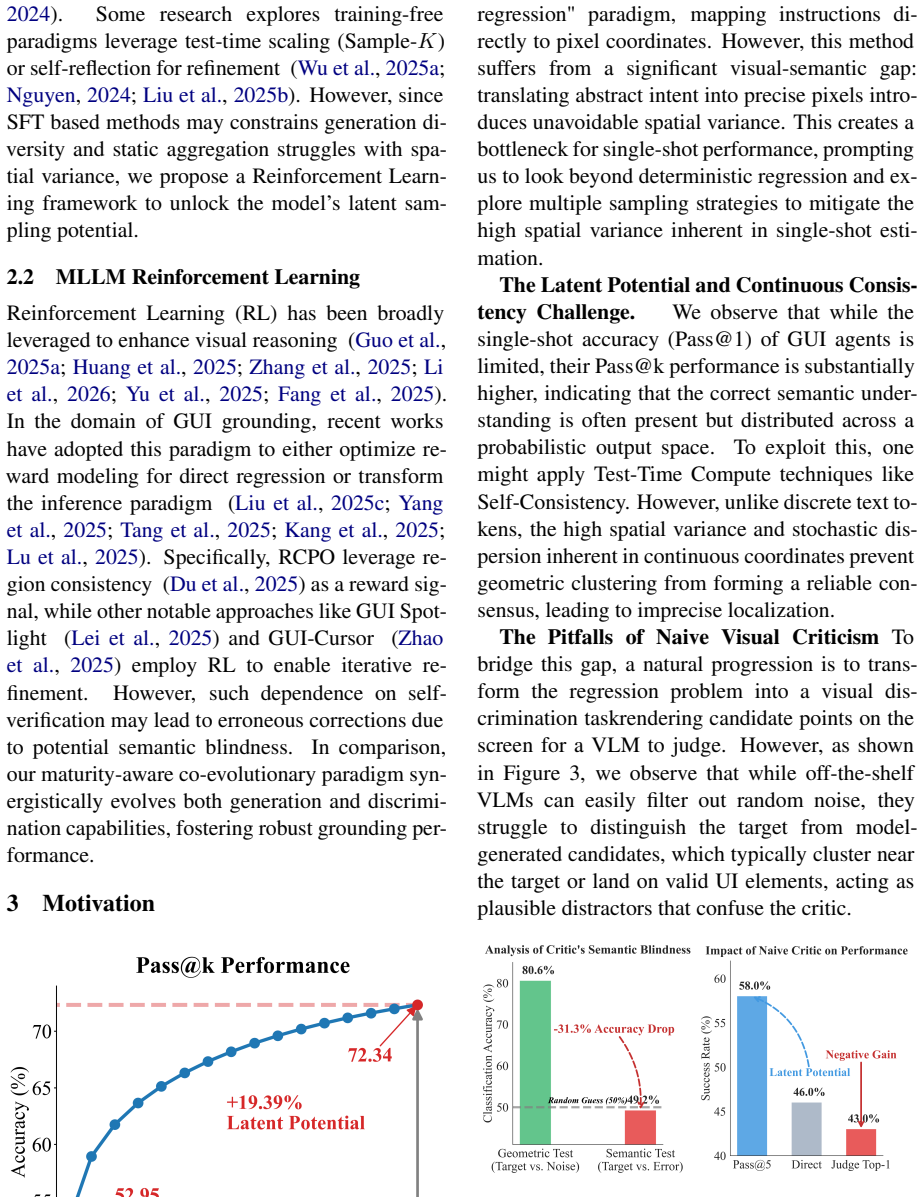
Graphical User Interface (GUI) grounding requires mapping natural language instructions to precise pixel coordinates. However, due to visually homogeneous elements and dense layouts, models typically grasp semantic intent yet struggle with achieving precise localization. While scaling sampling attempts (Pass@k) reveals potential gains, static self-consistency strategies derived from geometric clustering often yield limited improvements, as the model's predictions tend to be spatially dispersed. In this paper, we propose replacing static consistency strategies with a learnable selection mechanism that selects the optimal target by critiquing its own proposals rendered on the screenshot. Given the significant disparity between the model's grounding and critiquing capabilities, we propose a co-evolving Propose-then-Critic framework. To jointly optimize these, we introduce a maturity-aware adaptive co-evolutionary reinforcement learning paradigm. This approach dynamically balances the training objectives of proposer and critic, where the diversity of the proposer's outputs enhances critic robustness, while the critic's maturing discrimination capability conversely unlocks the proposer's potential for extensive spatial exploration, fostering the mutual reinforcement and co-evolution of both capabilities, thereby ensuring generalizability to adapt to diverse and complex interface layouts. Extensive experiments over 6 benchmarks show that our method significantly enhances both grounding accuracy and critic reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GUI grounding suffers from imprecise localization despite semantic understanding, and that static self-consistency methods are limited. It proposes a Propose-then-Critic framework in which the model critiques its own rendered proposals, trained via a maturity-aware adaptive co-evolutionary reinforcement learning paradigm that balances proposer diversity and critic discrimination to achieve mutual reinforcement and better generalizability across interface layouts. Extensive experiments on 6 benchmarks are reported to yield significant gains in both grounding accuracy and critic reliability.
Significance. If the empirical gains and stability of the co-evolution hold, the work could advance GUI agent systems by replacing heuristic consistency checks with a learnable, self-improving critique loop, offering a pathway to more robust spatial reasoning in dense visual interfaces and potentially generalizing to other multimodal grounding tasks.
major comments (2)
- Abstract: the central claim that the maturity-aware adaptive co-evolutionary RL paradigm produces 'mutual reinforcement' and 'significant' improvements rests on an unstated maturity metric and adaptation rule; without these definitions or evidence that they prevent divergence when initial grounding-critic disparity is large, the headline result cannot be evaluated.
- Abstract and experimental section: no quantitative results, baselines, ablations, or error analysis are supplied to support the reported gains on 6 benchmarks or the assertion that proposer diversity enhances critic robustness (and vice versa), rendering the soundness of the co-evolution claim impossible to assess from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies important gaps in clarity and supporting evidence. We will revise the manuscript to explicitly define key components of the co-evolutionary framework and to strengthen the presentation of empirical results.
read point-by-point responses
-
Referee: Abstract: the central claim that the maturity-aware adaptive co-evolutionary RL paradigm produces 'mutual reinforcement' and 'significant' improvements rests on an unstated maturity metric and adaptation rule; without these definitions or evidence that they prevent divergence when initial grounding-critic disparity is large, the headline result cannot be evaluated.
Authors: We agree the abstract is overly concise and leaves the maturity metric and adaptation rule undefined. The full manuscript defines maturity as the normalized gap in success rate between proposer and critic (Section 3.2) and uses an adaptive weighting rule that increases critic emphasis as maturity grows to stabilize co-training. We will add a one-sentence definition of both to the abstract and include a short stability analysis (new panel in Figure 4) showing that training remains convergent even under large initial disparities. revision: yes
-
Referee: Abstract and experimental section: no quantitative results, baselines, ablations, or error analysis are supplied to support the reported gains on 6 benchmarks or the assertion that proposer diversity enhances critic robustness (and vice versa), rendering the soundness of the co-evolution claim impossible to assess from the manuscript.
Authors: The experimental section reports results on the six benchmarks with baseline comparisons and component ablations, yet we acknowledge that the abstract contains no numeric values and the discussion of mutual reinforcement is brief. We will update the abstract with the main accuracy gains and add a dedicated error-analysis subsection plus diversity-robustness correlation plots to make the co-evolution claim directly verifiable. revision: yes
Circularity Check
No circularity: empirical RL training procedure with no derivations or self-referential reductions
full rationale
The paper describes an empirical co-evolving Propose-then-Critic framework trained via a maturity-aware adaptive RL paradigm. No equations, closed-form derivations, or mathematical claims are present in the abstract or method description. The central claims rest on experimental results across 6 benchmarks rather than any chain that reduces predictions or uniqueness to fitted inputs or self-citations. The mutual reinforcement between proposer diversity and critic discrimination is presented as an observed outcome of the training procedure, not a self-definitional or fitted-input prediction. This is the standard case of a self-contained empirical method with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A learnable critic can reliably distinguish correct from incorrect proposals when both are rendered on the same screenshot.
- domain assumption Diversity in proposer outputs improves critic robustness and vice versa under adaptive balancing.
Forward citations
Cited by 2 Pith papers
-
Learn where to Click from Yourself: On-Policy Self-Distillation for GUI Grounding
GUI-SD is the first on-policy self-distillation framework for GUI grounding that adds privileged bounding-box context and entropy-guided weighting to outperform GRPO methods on six benchmarks in accuracy and efficiency.
-
Learn where to Click from Yourself: On-Policy Self-Distillation for GUI Grounding
GUI-SD introduces on-policy self-distillation with visually enriched privileged context and entropy-guided weighting, outperforming GRPO and naive OPSD on six GUI grounding benchmarks while improving training efficiency.
Reference graph
Works this paper leans on
-
[1]
Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization , author=. arXiv preprint arXiv:2508.05731 , year=
-
[2]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2010.04295 , year=
Widget captioning: Generating natural language description for mobile user interface elements , author=. arXiv preprint arXiv:2010.04295 , year=
-
[4]
European Conference on Computer Vision , pages=
Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Guicourse: From general vision language model to versatile gui agent , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
NeurIPS 2024 Workshop on Open-World Agents , volume=
Showui: One vision-language-action model for generalist gui agent , author=. NeurIPS 2024 Workshop on Open-World Agents , volume=
2024
-
[7]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Mapping Natural Language Instructions to Mobile UI Action Sequences , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[8]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Os-atlas: A foundation action model for generalist gui agents , author=. arXiv preprint arXiv:2410.23218 , year=
work page internal anchor Pith review arXiv
-
[9]
Mmbench-gui: Hierarchical multi-platform evaluation framework for gui agents , author=. arXiv preprint arXiv:2507.19478 , year=
-
[10]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Screenspot-pro: Gui grounding for professional high-resolution computer use , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[11]
Ui-vision: A desktop-centric gui benchmark for visual perception and interaction , author=. arXiv preprint arXiv:2503.15661 , year=
-
[12]
arXiv preprint arXiv:2504.11257 , year=
Ui-e2i-synth: Advancing gui grounding with large-scale instruction synthesis , author=. arXiv preprint arXiv:2504.11257 , year=
-
[13]
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis , author=. arXiv preprint arXiv:2505.13227 , year=
-
[14]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms , author=. arXiv preprint arXiv:2402.14740 , year=
work page internal anchor Pith review arXiv
-
[16]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
work page internal anchor Pith review arXiv
-
[18]
Self-critiquing models for assisting human evaluators
Self-critiquing models for assisting human evaluators , author=. arXiv preprint arXiv:2206.05802 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Recursive introspection: Teaching language model agents how to self-improve , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Refiner: Reasoning feedback on intermediate representations
Refiner: Reasoning feedback on intermediate representations , author=. arXiv preprint arXiv:2304.01904 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[23]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal chain-of-thought reasoning in language models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review arXiv
-
[24]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey , author=. arXiv preprint arXiv:2404.18930 , year=
work page internal anchor Pith review arXiv
-
[25]
arXiv preprint arXiv:2211.00053 , year=
Generating sequences by learning to self-correct , author=. arXiv preprint arXiv:2211.00053 , year=
-
[26]
Small language models need strong verifiers to self-correct reasoning
Small language models need strong verifiers to self-correct reasoning , author=. arXiv preprint arXiv:2404.17140 , year=
-
[27]
Visual hallucinations of multi-modal large language models.arXiv preprint arXiv:2402.14683, 2024
Visual hallucinations of multi-modal large language models , author=. arXiv preprint arXiv:2402.14683 , year=
-
[28]
arXiv preprint arXiv:2502.12118 , year=
Scaling test-time compute without verification or rl is suboptimal , author=. arXiv preprint arXiv:2502.12118 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Teaching large language models to reason with reinforcement learning , author=. arXiv preprint arXiv:2403.04642 , year=
-
[31]
arXiv preprint arXiv:2502.18770 , year=
Reward shaping to mitigate reward hacking in rlhf , author=. arXiv preprint arXiv:2502.18770 , year=
-
[32]
Visual-RFT: Visual Reinforcement Fine-Tuning
Visual-rft: Visual reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.01785 , year=
work page internal anchor Pith review arXiv
-
[33]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2305.08844 , year=
Rl4f: Generating natural language feedback with reinforcement learning for repairing model outputs , author=. arXiv preprint arXiv:2305.08844 , year=
-
[35]
arXiv preprint arXiv:2409.12917 , year=
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[36]
Large Language Models Cannot Self-Correct Reasoning Yet
Large language models cannot self-correct reasoning yet, 2024 , author=. arXiv preprint arXiv:2310.01798 , year=
work page internal anchor Pith review arXiv 2024
-
[37]
Enhancing reasoning through process supervision with monte carlo tree search, 2025 a
Enhancing reasoning through process supervision with monte carlo tree search , author=. arXiv preprint arXiv:2501.01478 , year=
-
[38]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Improve mathematical reasoning in language models by automated process supervision, 2024 , author=. URL https://arxiv. org/abs/2406.06592 , year=
work page internal anchor Pith review arXiv 2024
-
[39]
arXiv preprint arXiv:2410.04055 , year=
Self-correction is more than refinement: A learning framework for visual and language reasoning tasks , author=. arXiv preprint arXiv:2410.04055 , year=
-
[40]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Teaching Large Language Models to Self-Debug
Teaching large language models to self-debug , author=. arXiv preprint arXiv:2304.05128 , year=
work page internal anchor Pith review arXiv
-
[42]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark , author=. arXiv preprint arXiv:2409.02813 , year=
work page internal anchor Pith review arXiv
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. arXiv preprint arXiv:2310.02255 , year=
work page internal anchor Pith review arXiv
-
[46]
We-math: Does your large multimodal model achieve human-like mathematical reasoning?, 2024
We-math: Does your large multimodal model achieve human-like mathematical reasoning? , author=. arXiv preprint arXiv:2407.01284 , year=
-
[47]
European Conference on Computer Vision , pages=
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[48]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[49]
2016 , eprint=
A Diagram Is Worth A Dozen Images , author=. 2016 , eprint=
2016
-
[50]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
arXiv preprint arXiv:2411.10442 , year=
Enhancing the reasoning ability of multimodal large language models via mixed preference optimization , author=. arXiv preprint arXiv:2411.10442 , year=
-
[56]
Openvlthinker: An early exploration to complex vision-language reasoning via iterative self-improvement , author=. arXiv preprint arXiv:2503.17352 , year=
-
[57]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2503.07365 , year=
-
[58]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review arXiv
-
[60]
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review arXiv
-
[61]
Seed1. 5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review arXiv
-
[62]
Developing Computer Use , year =
-
[63]
Aguvis: Unified pure vision agents for autonomous gui interaction , author=. arXiv preprint arXiv:2412.04454 , year=
-
[64]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review arXiv
-
[65]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu
Navigating the digital world as humans do: Universal visual grounding for gui agents , author=. arXiv preprint arXiv:2410.05243 , year=
-
[66]
GUI-G2: Gaussian reward modeling for gui grounding.arXiv preprint arXiv:2507.15846, 2025
GUI-G ^2 : Gaussian Reward Modeling for GUI Grounding , author=. arXiv preprint arXiv:2507.15846 , year=
-
[67]
arXiv preprint arXiv:2510.04039 , year=
textsc \ GUI-Spotlight \ : Adaptive Iterative Focus Refinement for Enhanced GUI Visual Grounding , author=. arXiv preprint arXiv:2510.04039 , year=
-
[68]
arXiv preprint arXiv:2509.21552 , year=
Learning gui grounding with spatial reasoning from visual feedback , author=. arXiv preprint arXiv:2509.21552 , year=
-
[69]
SE-GUI: Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning , author=
- [70]
-
[71]
Ponder & press: Advancing visual gui agent towards general computer control, 2024b , author=
-
[72]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[73]
2025 , institution =
Claude 3.7 Sonnet System Card , author =. 2025 , institution =
2025
-
[74]
R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization , author=. arXiv preprint arXiv:2503.12937 , year=
-
[75]
arXiv preprint arXiv:2506.03143 , year=
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents , author=. arXiv preprint arXiv:2506.03143 , year=
-
[76]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Attention-driven gui grounding: Leveraging pretrained multimodal large language models without fine-tuning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[77]
arXiv preprint arXiv:2505.00684 , year=
Visual test-time scaling for gui agent grounding , author=. arXiv preprint arXiv:2505.00684 , year=
-
[78]
arXiv preprint arXiv:2411.13591 , year=
Improved gui grounding via iterative narrowing , author=. arXiv preprint arXiv:2411.13591 , year=
-
[79]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
WebEvolver: Enhancing Web Agent Self-Improvement with Co-evolving World Model , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[80]
Guided self-evolving llms with minimal human supervision.arXiv preprint arXiv:2512.02472,
Guided self-evolving llms with minimal human supervision , author=. arXiv preprint arXiv:2512.02472 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.