Recognition: no theorem link
MIST: Multimodal Interactive Speech-based Tool-calling Conversational Assistants for Smart Homes
Pith reviewed 2026-05-11 01:10 UTC · model grok-4.3
The pith
MIST dataset exposes gaps between open- and closed-weight multimodal LLMs on voice-driven IoT tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
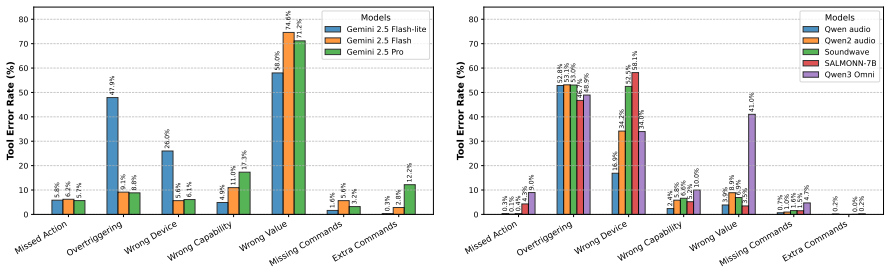
MIST is presented as a synthetic multi-turn, voice-driven code generation task over IoT devices that incorporates spatiotemporal constraints with speech inputs, dynamic state tracking, and mixed-initiative interaction patterns. On this benchmark, open-weight multimodal LLMs lag significantly behind closed-weight ones, while even frontier closed-weight models retain substantial headroom.
What carries the argument
MIST, the Multimodal Interactive Speech-based Tool-calling Dataset, functions as the central benchmark by simulating voice-based tool calling that must reason over changing device states and physical constraints in smart homes.
If this is right
- Multimodal LLMs require better integration of speech with reasoning about physical device states and locations.
- Mixed-initiative dialogue handling becomes essential for voice assistants to manage ongoing smart home interactions.
- Open-weight models need specific advances to narrow the observed performance gap with closed models.
- The provided data generation framework supports creation of additional datasets for related physical interaction scenarios.
Where Pith is reading between the lines
- Training on MIST-style data could improve voice assistants' ability to track device states across multiple turns in real homes.
- Future benchmarks might add visual sensors from smart home cameras to test richer multimodal reasoning.
- Deployment tests on physical IoT setups could identify gaps between synthetic benchmark performance and actual user experience.
Load-bearing premise
The synthetic multi-turn voice-driven code generation tasks over IoT devices accurately reflect real-world smart home challenges such as spatiotemporal constraints, dynamic state tracking, and mixed-initiative patterns.
What would settle it
An experiment in which models that score highly on MIST are tested in live user sessions with actual IoT hardware and show no corresponding improvement in handling state changes or user interruptions, or the reverse where low-scoring models succeed in practice.
Figures


read the original abstract
The rise of Internet of Things (IoT) devices in the physical world necessitates voice-based interfaces capable of handling complex user experiences. While modern Large Language Models (LLMs) already demonstrate strong tool-usage capabilities, modeling real-world IoT devices presents a difficult, understudied challenge which combines modeling spatiotemporal constraints with speech inputs, dynamic state tracking, and mixed-initiative interaction patterns. We introduce MIST (the Multimodal Interactive Speech-based Tool-calling Dataset), a synthetic multi-turn, voice-driven code generation task that operates over IoT devices. We find that there is a significant gap between open- and closed-weight multimodal LLMs on MIST, and that even frontier closed-weight LLMs have substantial headroom. We release MIST and an extensible data generation framework to build related datasets in order to facilitate research on mixed-initiative voice assistants which reason about physical world constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MIST, a synthetic multi-turn dataset for voice-driven tool-calling and code generation over IoT device schemas in smart-home settings. The task requires models to handle spatiotemporal constraints, dynamic state tracking, and mixed-initiative dialogue while producing executable code. The central empirical result is a reported performance gap between open- and closed-weight multimodal LLMs together with substantial remaining headroom even for frontier closed models. The authors release the dataset and an extensible procedural generation framework.
Significance. A well-validated benchmark that isolates the combination of speech input, physical-world constraints, and multi-turn tool use would be a useful addition to the evaluation landscape for conversational agents. The release of both the data and the generation code is a clear positive. However, the significance of the headline gap finding is currently limited by the absence of any reported metrics, model list, statistical tests, or controls for synthetic artifacts, so the result cannot yet be treated as a reliable signal about model capabilities.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of a 'significant gap' between open- and closed-weight multimodal LLMs and 'substantial headroom' for frontier models is asserted without any accompanying metrics, model identifiers, evaluation protocol, or statistical significance tests, rendering the central empirical contribution unassessable from the manuscript.
- [§3] §3 (Dataset Construction): the procedural generation from fixed IoT schemas and templated multi-turn scripts is described at a high level, but no ablation or sensitivity analysis is provided to test whether the observed open/closed gap persists under varied generation rules or when realistic noise (ASR errors, underspecified goals) is injected; this directly bears on whether the gap reflects genuine reasoning differences or synthetic artifacts.
- [§4] §4 (Experiments): no information is given on how the synthetic dialogues were validated against real device behavior or user interaction patterns, leaving the weakest assumption—that the task faithfully captures spatiotemporal constraints and mixed-initiative dynamics—unsupported.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the exact metrics used (e.g., exact-match code accuracy, state-tracking F1) and the set of models evaluated.
- [Figures and Tables] Figure captions and table headers should clarify whether results are averaged over multiple seeds or single runs.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and describe the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of a 'significant gap' between open- and closed-weight multimodal LLMs and 'substantial headroom' for frontier models is asserted without any accompanying metrics, model identifiers, evaluation protocol, or statistical significance tests, rendering the central empirical contribution unassessable from the manuscript.
Authors: We agree that the abstract and experimental section would benefit from greater explicitness. In the revised manuscript we will update the abstract to report key quantitative metrics (e.g., exact success rates for representative open- and closed-weight models) and will expand §4 to list all model identifiers, describe the complete evaluation protocol, present the precise performance numbers, and include statistical significance tests supporting the reported gap and headroom. revision: yes
-
Referee: [§3] §3 (Dataset Construction): the procedural generation from fixed IoT schemas and templated multi-turn scripts is described at a high level, but no ablation or sensitivity analysis is provided to test whether the observed open/closed gap persists under varied generation rules or when realistic noise (ASR errors, underspecified goals) is injected; this directly bears on whether the gap reflects genuine reasoning differences or synthetic artifacts.
Authors: We acknowledge that sensitivity analyses would help confirm robustness. Because the full generation code is released, such experiments are straightforward for the community. In the revision we will expand §3 with a more detailed account of the generation rules and add a discussion of potential artifacts together with a limited sensitivity check on core parameters (e.g., script length and constraint density). We maintain that the gap arises from genuine differences in reasoning over spatiotemporal and state-tracking constraints rather than artifacts, given the deterministic, schema-grounded nature of the data. revision: partial
-
Referee: [§4] §4 (Experiments): no information is given on how the synthetic dialogues were validated against real device behavior or user interaction patterns, leaving the weakest assumption—that the task faithfully captures spatiotemporal constraints and mixed-initiative dynamics—unsupported.
Authors: The dialogues are generated directly from realistic IoT device schemas and multi-turn scripts that explicitly encode spatiotemporal constraints and mixed-initiative turns. In the revised §4 we will add a paragraph describing our internal validation procedure, which consisted of manual inspection of a representative sample of dialogues to verify schema compliance and presence of the target dynamics. We note that large-scale real-user or physical-device studies were outside the scope of this work but are enabled by the released framework; we will clarify this limitation while emphasizing the controlled, reproducible nature of the current benchmark. revision: yes
Circularity Check
No circularity: empirical dataset creation and benchmarking with no derivations or fitted predictions
full rationale
The paper introduces the MIST synthetic dataset for multimodal IoT tool-calling and reports empirical benchmarks on existing open- and closed-weight LLMs. No mathematical derivations, parameter fitting, or predictions are claimed; the core results are direct performance measurements on the new task. No self-citations are used to justify uniqueness theorems or ansatzes, and the generation process is described as procedural from fixed schemas without reducing any output to prior fitted quantities by construction. The reader's assessment of score 1.0 aligns with this being a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geng, Xinyang and Liu, Hao , title =
-
[2]
RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset , month = April, year = 2023, url =
work page 2023
-
[3]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Chen, Maximillian and Papangelis, Alexandros and Tao, Chenyang and Kim, Seokhwan and Rosenbaum, Andy and Liu, Yang and Yu, Zhou and Hakkani-Tur, Dilek , booktitle=
-
[5]
Kim, Hyunwoo and Hessel, Jack and Jiang, Liwei and Lu, Ximing and Yu, Youngjae and Zhou, Pei and Bras, Ronan Le and Alikhani, Malihe and Kim, Gunhee and Sap, Maarten and others , journal=
-
[6]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[7]
LARD : Large-scale Artificial Disfluency Generation
Passali, Tatiana and Mavropoulos, Thanassis and Tsoumakas, Grigorios and Meditskos, Georgios and Vrochidis, Stefanos. LARD : Large-scale Artificial Disfluency Generation. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
work page 2022
-
[8]
Advances in Neural Information Processing Systems , volume=
Neural program generation modulo static analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Controllable mixed-initiative dialogue generation through prompting , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year=
-
[10]
NeurIPS 2022 Workshop on Synthetic Data for Empowering ML Research , year=
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding , author=. NeurIPS 2022 Workshop on Synthetic Data for Empowering ML Research , year=
work page 2022
-
[11]
Advances in Neural Information Processing Systems , volume=
Generating training data with language models: Towards zero-shot language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi DQ and Li, Junnan and Hoi, Steven CH , journal=. Code
-
[13]
Erik Nijkamp and Tian Xie and Hiroaki Hayashi and Bo Pang and Congying Xia and Chen Xing and Jesse Vig and Semih Yavuz and Philippe Laban and Ben Krause and Senthil Purushwalkam and Tong Niu and Wojciech Kryscinski and Lidiya Murakhovs'ka and Prafulla Kumar Choubey and Alex Fabbri and Ye Liu and Rui Meng and Lifu Tu and Meghana Bhat and Chien-Sheng Wu and...
work page 2023
-
[14]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
MultiWOZ-A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2018
-
[15]
Goel, Rahul and Ammar, Waleed and Gupta, Aditya and Vashishtha, Siddharth and Sano, Motoki and Surani, Faiz and Chang, Max and Choe, HyunJeong and Greene, David and He, Kyle and others , journal=
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Controllable Dialogue Simulation with In-context Learning , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
work page 2022
-
[18]
Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
work page 2022
-
[19]
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations , pages=
work page 2021
-
[20]
OpenAI: Introducing ChatGPT , year =
OpenAI , howpublished =. OpenAI: Introducing ChatGPT , year =
-
[21]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[22]
Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces , author=. arXiv preprint arXiv:1805.10190 , year=
-
[23]
The ATIS spoken language systems pilot corpus , author=. Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27, 1990 , year=
work page 1990
-
[24]
Cross-lingual Transfer Learning for Multilingual Task Oriented Dialog , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
work page 2019
-
[25]
Zero-Shot Dialog Generation with Cross-Domain Latent Actions , author=. SIGDIAL , year=
-
[26]
Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
AuGPT: Auxiliary Tasks and Data Augmentation for End-To-End Dialogue with Pre-Trained Language Models , author=. Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
-
[27]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Paraphrase Augmented Task-Oriented Dialog Generation , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[28]
Mehri, Shikib and Altun, Yasemin and Eskenazi, Maxine , booktitle=
-
[29]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
N-Shot Learning for Augmenting Task-Oriented Dialogue State Tracking , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
work page 2022
-
[30]
The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only , author=. arXiv preprint arXiv:2306.01116 , year=
work page internal anchor Pith review arXiv
-
[31]
IoT market forecast to 2030: connections by region and vertical , author=. 2024 , url=
work page 2030
-
[32]
A Textual Dataset for Situated Proactive Response Selection
Otani, Naoki and Araki, Jun and Kim, HyeongSik and Hovy, Eduard. A Textual Dataset for Situated Proactive Response Selection. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
work page 2023
-
[33]
arXiv preprint arXiv:2304.12026 , year=
SocialDial: A Benchmark for Socially-Aware Dialogue Systems , author=. arXiv preprint arXiv:2304.12026 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
A simple language model for task-oriented dialogue , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
As AI Spreads, Experts Predict the Best and Worst Changes in Digital Life by 2035 , author=. 2023 , publisher=
work page 2035
-
[36]
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
work page 2020
-
[37]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[38]
DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI , author=. 2023 , eprint=
work page 2023
-
[39]
Bottom-Up Synthesis of Knowledge-Grounded Task-Oriented Dialogues with Iteratively Self-Refined Prompts , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
work page 2025
-
[40]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. ICLR , year=
-
[41]
IEEE Internet of Things Journal , year=
Aiot smart home via autonomous llm agents , author=. IEEE Internet of Things Journal , year=
-
[42]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Data-centric improvements for enhancing multi-modal understanding in spoken conversation modeling , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[43]
CIRP journal of manufacturing science and technology , volume=
Characterising the Digital Twin: A systematic literature review , author=. CIRP journal of manufacturing science and technology , volume=. 2020 , publisher=
work page 2020
-
[44]
Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training , author=. 2025 , booktitle=
work page 2025
-
[45]
GrounDialog: A dataset for repair and grounding in task-oriented spoken dialogues for language learning , author=. Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) , pages=
work page 2023
-
[46]
Advances in Neural Information Processing Systems , volume=
Spokenwoz: A large-scale speech-text benchmark for spoken task-oriented dialogue agents , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
SD-QA: Spoken dialectal question answering for the real world , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
work page 2021
-
[48]
Spoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension , author=. Proc. Interspeech 2018 , pages=
work page 2018
-
[49]
Findings of the association for computational linguistics: NAACL 2022 , pages=
End-to-end spoken conversational question answering: Task, dataset and model , author=. Findings of the association for computational linguistics: NAACL 2022 , pages=
work page 2022
-
[50]
Proceedings of the 6th Workshop on NLP for Conversational AI (NLP4ConvAI 2024) , pages=
Faithful persona-based conversational dataset generation with large language models , author=. Proceedings of the 6th Workshop on NLP for Conversational AI (NLP4ConvAI 2024) , pages=
work page 2024
-
[51]
Iot-llm: Enhancing real-world iot task reasoning with large language models , author=
-
[52]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models , author=. arXiv preprint arXiv:2311.07919 , year=
work page internal anchor Pith review arXiv
-
[53]
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
work page internal anchor Pith review arXiv
-
[54]
Soundwave: Less is more for speech-text alignment in llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Anticipation?
SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Prediction? , author=. arXiv preprint arXiv:2602.00327 , year=
work page internal anchor Pith review arXiv
-
[58]
Voicebench: Benchmarking llm-based voice assistants , author=. arXiv preprint arXiv:2410.17196 , year=
-
[59]
arXiv preprint arXiv:2510.15406 , year=
VocalBench-DF: A Benchmark for Evaluating Speech LLM Robustness to Disfluency , author=. arXiv preprint arXiv:2510.15406 , year=
- [60]
-
[61]
Speechr: A bench- mark for speech reasoning in large audio-language models,
Speechr: A benchmark for speech reasoning in large audio-language models , author=. arXiv preprint arXiv:2508.02018 , year=
-
[62]
Decision support systems , volume=
Digital Twin: Generalization, characterization and implementation , author=. Decision support systems , volume=. 2021 , publisher=
work page 2021
-
[63]
Cosql: A conversational text-to-sql challenge towards cross-domain natural language interfaces to databases , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[64]
Doctoral dissertation, University of California at Berkeley , year=
Preliminaries to a theory of speech disfluencies , author=. Doctoral dissertation, University of California at Berkeley , year=
-
[65]
The Future of Smart Homes: Top Technology Trends in 2025 , howpublished =. 2025 , month =
work page 2025
- [66]
-
[67]
Must-Have Smart Home Devices for 2025 , howpublished =. 2025 , month =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.