Recognition: no theorem link
OLIVIA: Online Learning via Inference-time Action Adaptation for Decision Making in LLM ReAct Agents
Pith reviewed 2026-05-13 02:20 UTC · model grok-4.3
The pith
OLIVIA models the action-selection step of ReAct LLM agents as a contextual linear bandit over frozen hidden states to enable direct online updates from feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing the LLM's final action-selection layer as a contextual linear bandit whose contexts are frozen hidden states, OLIVIA supplies an explicit decision interface that admits online linear updates from action-level feedback and upper-confidence-bound exploration while preserving the original reasoning trace.
What carries the argument
contextual linear bandit whose contexts are the LLM's frozen hidden states and whose arms are candidate actions, updated online with upper-confidence-bound selection
If this is right
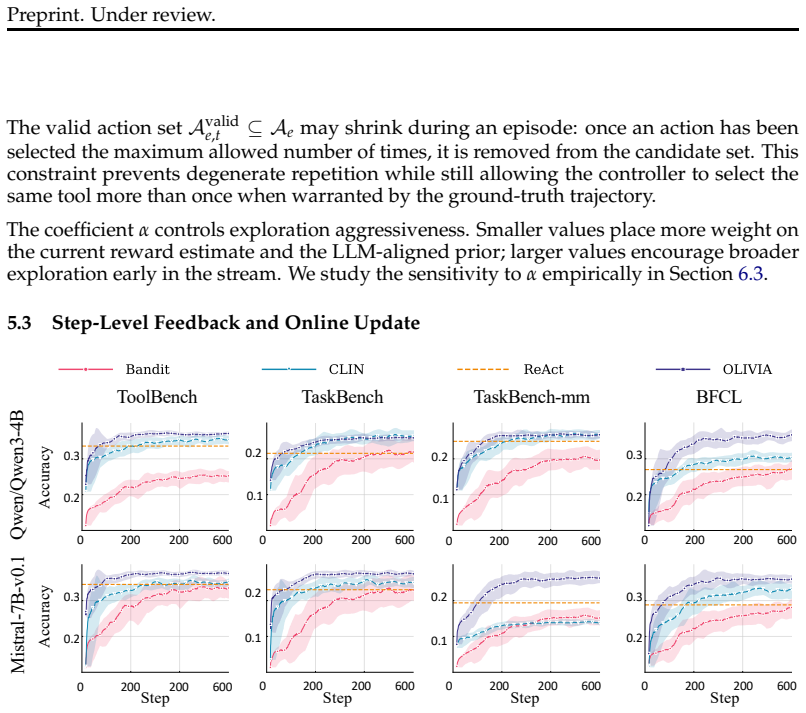
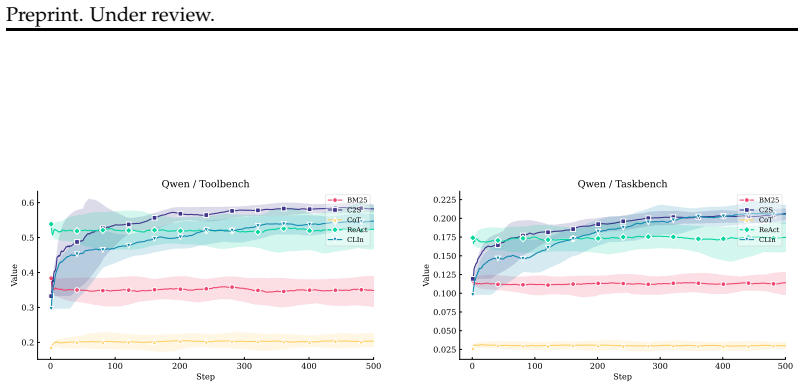
- Task performance improves consistently over static ReAct and prompt-based baselines on four benchmarks.
- Policy updates occur sample-efficiently with only lightweight linear updates and no retraining of the underlying LLM.
- Adaptation remains trackable because each update is an explicit change to the bandit parameters rather than opaque prompt edits.
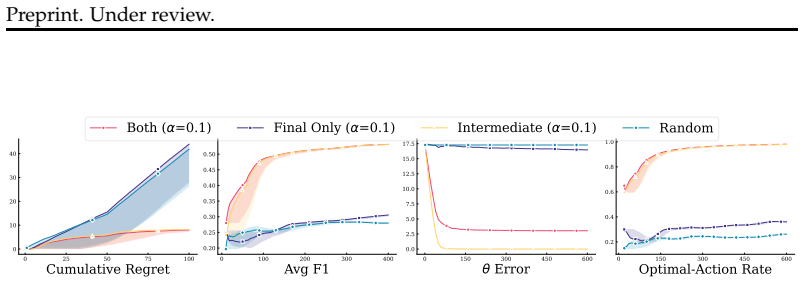
- Uncertainty estimates are available at every action choice because the bandit maintains explicit variance terms.
Where Pith is reading between the lines
- The same frozen-state bandit construction could be attached to other agent scaffolds that expose an action-selection interface.
- If hidden states prove linearly insufficient on harder domains, the framework would naturally motivate richer context features or nonlinear bandits.
- Repeated deployment on related tasks could produce a growing library of bandit parameters that transfer across similar subtasks without prompt engineering.
Load-bearing premise
The frozen hidden states contain enough information for a linear model to recover action values and uncertainty without substantial loss from the preceding reasoning steps.
What would settle it
On any of the four benchmarks, OLIVIA produces success rates or completion times statistically indistinguishable from or worse than the static ReAct baseline when the same prompts and LLM are used.
Figures





read the original abstract
Large language model agents interleave reasoning, action selection, and observation to solve sequential decision-making tasks. In deployed settings where agents repeatedly handle related multi-step tasks, small action-selection errors can accumulate into wasted tool calls, latency, and reduced reliability. Despite this need for deployment-time improvement, existing inference-time adaptation methods for LLM agents mainly rely on prompting or retrieval, which influence behavior indirectly through context manipulation. For ReAct-style agents, such approaches do not expose an explicit decision layer that can score candidate actions, represent uncertainty, or be updated online from action-level feedback. As a result, they provide limited support for trackable, fine-grained, and uncertainty-aware adaptation during deployment. We propose OLIVIA, an inference-time action adaptation framework for ReAct-style agents. OLIVIA models the LLM's final action-selection layer as a contextual linear bandit over candidate actions, with frozen hidden states as decision contexts. This choice is particularly suitable for deployment because it adapts behavior directly at the action-selection interface, preserves the underlying reasoning process, and provides explicit uncertainty estimates and lightweight online updates from action-level feedback. With upper-confidence-bound exploration, OLIVIA improves the policy sample-efficiently with minimal computational overhead. We instantiate OLIVIA on four benchmarks and show that it consistently improves task performance over static ReAct and prompt-based inference-time baselines. Our results suggest that explicit online decision layers provide an effective alternative to purely prompt- or retrieval-based adaptation for LLM agents during deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OLIVIA, an inference-time adaptation method for ReAct-style LLM agents. It treats the final hidden state before action selection as the context vector for a contextual linear bandit over candidate actions, maintains per-action parameters, and applies UCB exploration with online updates from action-level feedback. The central claim is that this yields consistent performance gains on four benchmarks relative to static ReAct and prompt-based inference-time baselines while preserving the original reasoning process and adding explicit uncertainty estimates at low computational cost.
Significance. If the linear-bandit construction on frozen hidden states proves reliable, the work supplies a lightweight, uncertainty-aware, and directly updatable decision layer for deployed LLM agents. This is a meaningful alternative to purely prompt- or retrieval-based adaptation, especially for repeated multi-step tasks where small action errors accumulate. The approach is notable for its explicit modeling of action values and uncertainty rather than indirect context manipulation.
major comments (2)
- [Method description (abstract and §3)] The headline performance claim rests on the assumption that the LLM's final hidden state before action selection encodes all task-relevant information produced by preceding ReAct reasoning steps and that the mapping from this state to expected reward is approximately linear. Neither property is guaranteed: reasoning information may be distributed across the token sequence rather than concentrated in the last token, and LLM representations often require non-linear probes for downstream quantities. If either fails, the bandit receives noisy or biased targets, UCB exploration becomes ineffective, and observed gains could be explained by prompt sensitivity or benchmark idiosyncrasies rather than the adaptation mechanism.
- [Experiments (§5)] The experimental section asserts consistent improvements on four benchmarks but supplies no statistical significance tests, ablation results isolating the bandit component, details on hidden-state extraction or dimensionality, or implementation specifics for the UCB updates and reward signals. Without these, it is impossible to verify that gains are attributable to the proposed online decision layer rather than other factors.
minor comments (2)
- [§3] Notation for the context vector x_t and per-action parameters should be introduced with explicit equations rather than prose description to improve reproducibility.
- [§4] The paper would benefit from a short discussion of how action-level feedback is obtained in each benchmark (e.g., success/failure signals or reward definitions).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment point by point below, providing clarifications and indicating revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The headline performance claim rests on the assumption that the LLM's final hidden state before action selection encodes all task-relevant information produced by preceding ReAct reasoning steps and that the mapping from this state to expected reward is approximately linear. Neither property is guaranteed: reasoning information may be distributed across the token sequence rather than concentrated in the last token, and LLM representations often require non-linear probes for downstream quantities. If either fails, the bandit receives noisy or biased targets, UCB exploration becomes ineffective, and observed gains could be explained by prompt sensitivity or benchmark idiosyncrasies rather than the adaptation mechanism.
Authors: We acknowledge the validity of this concern regarding the assumptions underlying the contextual linear bandit construction. While the final hidden state is not theoretically guaranteed to concentrate all task-relevant information (as reasoning steps may distribute information across tokens), the ReAct paradigm explicitly generates and interleaves reasoning traces immediately prior to action selection, making the last hidden state a natural and commonly used context representation in LLM decision-making literature. We have revised Section 3 to include an expanded discussion of this design choice, its motivations, and potential limitations, along with references to related work employing last-token representations. On linearity, we do not assert it holds universally but note that the linear model enables lightweight, uncertainty-aware updates suitable for deployment; the consistent empirical gains over strong baselines (including prompt-based methods that control for indirect context effects) suggest the approximation is effective in practice. We have also added further controls in the experiments (see response to the second comment) to help attribute gains to the adaptation mechanism rather than idiosyncrasies. revision: partial
-
Referee: [Experiments (§5)] The experimental section asserts consistent improvements on four benchmarks but supplies no statistical significance tests, ablation results isolating the bandit component, details on hidden-state extraction or dimensionality, or implementation specifics for the UCB updates and reward signals. Without these, it is impossible to verify that gains are attributable to the proposed online decision layer rather than other factors.
Authors: We agree that the original experimental section was insufficiently detailed to allow full verification of the source of the reported gains. In the revised manuscript, we have substantially expanded Section 5 and the appendix with the following: statistical significance testing via paired t-tests and bootstrap confidence intervals across multiple random seeds, with p-values reported for all comparisons; ablation studies that isolate the bandit components (e.g., static linear model without UCB exploration, non-updating parameters, and random action selection); explicit details on hidden-state extraction (last token of the final reasoning step prior to action selection, using the model's native hidden dimension such as 4096 for the evaluated LLMs); and full implementation specifics for UCB (exploration coefficient α = 1.0, online ridge-regression updates, and binary reward signals derived from action-level success or task completion). These additions directly address the referee's points and enable readers to confirm that improvements arise from the online decision layer. revision: yes
Circularity Check
No significant circularity; standard contextual bandit applied to LLM states with empirical validation
full rationale
The paper introduces OLIVIA by directly defining the action-selection layer as a contextual linear bandit using frozen hidden states as contexts and applying UCB for online updates from action feedback. This is an application of an existing algorithm (contextual bandits) to new inputs (LLM hidden states), not a derivation that reduces claimed improvements to fitted parameters or self-referential definitions by construction. Performance gains are shown via experiments on four benchmarks against baselines, with no load-bearing self-citations, uniqueness theorems, or ansatzes that collapse the result to its inputs. The chain remains self-contained as a proposed framework plus empirical demonstration.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen LLM hidden states can be treated as contexts for a linear model of action values.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Measuring Chain-of-Thought Monitorability Through Faithfulness and Verbosity , author=. 2025 , eprint=
work page 2025
-
[3]
RCOT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought , author=. 2023 , eprint=
work page 2023
-
[4]
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
work page 2023
-
[5]
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
work page 2023
- [6]
-
[7]
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. 2023 , eprint=
work page 2023
-
[8]
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. 2023 , eprint=
work page 2023
-
[9]
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization , author=. 2024 , eprint=
work page 2024
-
[10]
Test-Time Adaptation for LLM Agents via Environment Interaction , author=. 2026 , eprint=
work page 2026
-
[11]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. 2023 , eprint=
work page 2023
-
[12]
Reasoning with Language Model is Planning with World Model , author=. 2023 , eprint=
work page 2023
-
[13]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models , author=. 2024 , eprint=
work page 2024
- [14]
-
[15]
Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism , author=. 2024 , eprint=
work page 2024
-
[16]
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search , author=. 2025 , eprint=
work page 2025
-
[17]
Active Exploration via Autoregressive Generation of Missing Data , author=. 2025 , eprint=
work page 2025
-
[18]
Contextual Thompson Sampling via Generation of Missing Data , author=. 2025 , eprint=
work page 2025
-
[19]
Regret Bounds for Adversarial Contextual Bandits with General Function Approximation and Delayed Feedback , author=. 2025 , eprint=
work page 2025
-
[20]
CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization , author=. 2023 , eprint=
work page 2023
-
[21]
Li, Lihong and Chu, Wei and Langford, John and Schapire, Robert E. , year=. A contextual-bandit approach to personalized news article recommendation , url=. doi:10.1145/1772690.1772758 , booktitle=
-
[22]
Neural Contextual Bandits for Personalized Recommendation , author=. 2023 , eprint=
work page 2023
-
[23]
On the Tool Manipulation Capability of Open-source Large Language Models , author=. 2023 , eprint=
work page 2023
-
[24]
TaskBench: Benchmarking Large Language Models for Task Automation , author=. 2024 , eprint=
work page 2024
-
[25]
Gorilla: Large Language Model Connected with Massive APIs , author=. 2023 , eprint=
work page 2023
- [26]
- [27]
-
[28]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
work page 2023
-
[29]
Robertson, Stephen and Zaragoza, Hugo , title =. 2009 , issue_date =. doi:10.1561/1500000019 , journal =
-
[30]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[31]
Webwalker: Benchmarking llms in web traversal , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Agent skills for large language models: Architecture, acquisition, security, and the path forward , author=. arXiv preprint arXiv:2602.12430 , year=
work page internal anchor Pith review arXiv
-
[34]
SoK: Agentic skills–beyond tool use in LLM agents.arXiv preprint arXiv:2602.20867, 2026
SoK: Agentic Skills--Beyond Tool Use in LLM Agents , author=. arXiv preprint arXiv:2602.20867 , year=
-
[35]
Cua-skill: Develop skills for computer using agent.arXiv preprint arXiv:2601.21123,
CUA-Skill: Develop Skills for Computer Using Agent , author=. arXiv preprint arXiv:2601.21123 , year=
-
[36]
arXiv preprint arXiv:2507.21046 , year=
A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence , author=. arXiv preprint arXiv:2507.21046 , year=
-
[37]
arXiv preprint arXiv:2508.16153 , year=
Memento: Fine-tuning llm agents without fine-tuning llms , author=. arXiv preprint arXiv:2508.16153 , year=
-
[38]
Memento-skills: Let agents design agents
Memento-Skills: Let Agents Design Agents , author=. arXiv preprint arXiv:2603.18743 , year=
-
[39]
arXiv preprint arXiv:2603.02176 , year=
Organizing, Orchestrating, and Benchmarking Agent Skills at Ecosystem Scale , author=. arXiv preprint arXiv:2603.02176 , year=
-
[40]
arXiv preprint arXiv:2603.00718 , year=
SkillCraft: Can LLM Agents Learn to Use Tools Skillfully? , author=. arXiv preprint arXiv:2603.00718 , year=
-
[41]
arXiv preprint arXiv:2603.12056 (2026)
XSkill: Continual Learning from Experience and Skills in Multimodal Agents , author=. arXiv preprint arXiv:2603.12056 , year=
-
[42]
Spatialagent: An autonomous ai agent for spatial biology.bioRxiv, pp
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
-
[43]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Seagent: Self-evolving computer use agent with autonomous learning from experience , author=. arXiv preprint arXiv:2508.04700 , year=
-
[45]
arXiv preprint arXiv:2602.03025 , year=
RC-GRPO: Reward-Conditioned Group Relative Policy Optimization for Multi-Turn Tool Calling Agents , author=. arXiv preprint arXiv:2602.03025 , year=
-
[46]
Adaptation of Agentic AI: A Survey of Post-Training, Memory, and Skills , author=. 2026 , eprint=
work page 2026
-
[47]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Skills-in-context: Unlocking compositionality in large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[49]
Skillweaver: Web agents can self-improve by discovering and honing skills , author=. arXiv preprint arXiv:2504.07079 , year=
-
[50]
arXiv preprint arXiv:2504.06821 , year=
Inducing programmatic skills for agentic tasks , author=. arXiv preprint arXiv:2504.06821 , year=
-
[51]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
arXiv preprint arXiv:2509.25717 , year=
Importance Sampling for Multi-Negative Multimodal Direct Preference Optimization , author=. arXiv preprint arXiv:2509.25717 , year=
-
[53]
Second Conference on Language Modeling , year=
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models , author=. Second Conference on Language Modeling , year=
-
[54]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[55]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Listwise Preference Diffusion Optimization for User Behavior Trajectories Prediction , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[56]
arXiv preprint arXiv:2506.15757 , year=
Weakly-supervised VLM-guided Partial Contrastive Learning for Visual Language Navigation , author=. arXiv preprint arXiv:2506.15757 , year=
-
[57]
arXiv preprint arXiv:2504.15476 , year=
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System , author=. arXiv preprint arXiv:2504.15476 , year=
-
[58]
arXiv preprint arXiv:2601.05600 , year=
SceneAlign: Aligning Multimodal Reasoning to Scene Graphs in Complex Visual Scenes , author=. arXiv preprint arXiv:2601.05600 , year=
-
[59]
Explainable Chain-of-Thought Reasoning: An Empirical Analysis on State-Aware Reasoning Dynamics
Yu, Sheldon and Xiong, Yuxin and Wu, Junda and Li, Xintong and Yu, Tong and Chen, Xiang and Sinha, Ritwik and Shang, Jingbo and McAuley, Julian. Explainable Chain-of-Thought Reasoning: An Empirical Analysis on State-Aware Reasoning Dynamics. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.904
-
[60]
CTRLS: Chain-of-Thought Reasoning via Latent State-Transition , author=
-
[61]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[62]
Decot: Debiasing chain-of-thought for knowledge-intensive tasks in large language models via causal intervention , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[63]
International Conference on Learning Representations , volume=
Ocean: Offline chain-of-thought evaluation and alignment in large language models , author=. International Conference on Learning Representations , volume=
-
[64]
Doc-react: Multi-page heterogeneous document question-answering , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[65]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
Clustering of conversational bandits for user preference learning and elicitation , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[66]
arXiv preprint arXiv:2509.19333 , year=
Pluralistic Off-policy Evaluation and Alignment , author=. arXiv preprint arXiv:2509.19333 , year=
-
[67]
Dynamics-aware adaptation for reinforcement learning based cross-domain interactive recommendation , author=. Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[68]
Rossi and Tong Yu and Junda Wu and Handong Zhao and Sungchul Kim and Shuai Li , booktitle=
Songwen Hu and Ryan A. Rossi and Tong Yu and Junda Wu and Handong Zhao and Sungchul Kim and Shuai Li , booktitle=. Interactive Visualization Recommendation with Hier-. 2025 , url=
work page 2025
-
[69]
Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
User-regulation deconfounded conversational recommender system with bandit feedback , author=. Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[70]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
SAND: Boosting LLM agents with self-taught action deliberation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[71]
arXiv preprint arXiv:2507.23554 , year=
Dice: Dynamic in-context example selection in llm agents via efficient knowledge transfer , author=. arXiv preprint arXiv:2507.23554 , year=
-
[72]
Active learning for direct preference optimization
Active learning for direct preference optimization , author=. arXiv preprint arXiv:2503.01076 , year=
-
[73]
Image Difference Captioning via Adversarial Preference Optimization
Huang, Zihan and Wu, Junda and Surana, Rohan and Yu, Tong and Arbour, David and Sinha, Ritwik and McAuley, Julian. Image Difference Captioning via Adversarial Preference Optimization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1713
-
[74]
Second Conference on Language Modeling , year=
Traceable and Explainable Multimodal Large Language Models: An Information-Theoretic View , author=. Second Conference on Language Modeling , year=
-
[75]
Thirty-seventh Conference on Neural Information Processing Systems , year=
InfoPrompt: Information-Theoretic Soft Prompt Tuning for Natural Language Understanding , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[76]
Context-aware Information-theoretic Causal De-biasing for Interactive Sequence Labeling
Wu, Junda and Wang, Rui and Yu, Tong and Zhang, Ruiyi and Zhao, Handong and Li, Shuai and Henao, Ricardo and Nenkova, Ani. Context-aware Information-theoretic Causal De-biasing for Interactive Sequence Labeling. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.251
-
[77]
Xia, Yu and Mukherjee, Subhojyoti and Xie, Zhouhang and Wu, Junda and Li, Xintong and Aponte, Ryan and Lyu, Hanjia and Barrow, Joe and Chen, Hongjie and Dernoncourt, Franck and Kveton, Branislav and Yu, Tong and Zhang, Ruiyi and Gu, Jiuxiang and Ahmed, Nesreen K. and Wang, Yu and Chen, Xiang and Deilamsalehy, Hanieh and Kim, Sungchul and Hu, Zhengmian and...
-
[78]
arXiv preprint arXiv:2412.02142 , year=
Personalized multimodal large language models: A survey , author=. arXiv preprint arXiv:2412.02142 , year=
-
[79]
arXiv preprint arXiv:2411.00027 , year=
Personalization of large language models: A survey , author=. arXiv preprint arXiv:2411.00027 , year=
-
[80]
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning , author=. 2026 , eprint=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.