Recognition: 3 theorem links
· Lean TheoremNautilus: From One Prompt to Plug-and-Play Robot Learning
Pith reviewed 2026-05-13 01:02 UTC · model grok-4.3
The pith
Nautilus converts one user prompt into ready-to-use robot learning pipelines by automatically generating adapters that connect policies, benchmarks, and robots through uniform interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
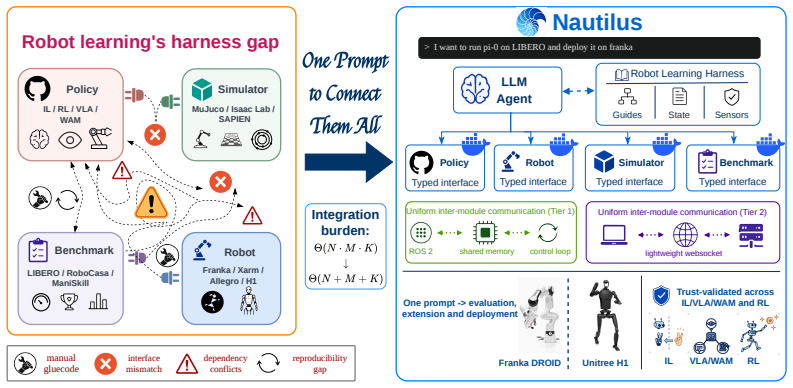
Nautilus is an open-source harness that turns a single user prompt into reproduction, evaluation, fine-tuning, and deployment workflows by automatically generating the required adapters and containers for existing implementations and wrapping new or user-provided policies, simulators, benchmarks, and robots, all connected via a uniform interface with explicit automated validation at each step.
What carries the argument
The Nautilus harness, which supplies typed contracts among policies, simulators, and robots together with an agentic coding workflow that generates and validates adapters and execution environments from a prompt.
If this is right
- Any existing policy implementation can be evaluated on previously incompatible benchmarks without writing new integration code.
- User-provided simulators or real robots can be onboarded and connected to multiple policy families through the same uniform interface.
- Reproduction and fine-tuning workflows become prompt-driven rather than requiring per-setup engineering.
- Cross-family validation coverage grows by extending the harness rather than by curating additional hand-written bridges.
Where Pith is reading between the lines
- If the uniform interface holds, researchers could treat the entire ecosystem of policies and benchmarks as interchangeable modules rather than isolated silos.
- The chambered scaling model suggests future extensions could add support for new modalities such as multi-robot coordination without redesigning the core contracts.
- Automated validation at each milestone reduces the risk that generated adapters silently alter policy behavior or benchmark conditions.
Load-bearing premise
That typed contracts and unified interfaces can be maintained across the diverse and rapidly evolving space of policies, simulators, and real robots without requiring substantial ongoing custom engineering or breaking existing implementations.
What would settle it
A new policy or robot hardware whose interface cannot be wrapped and validated by the agent without manual code changes or contract violations.
Figures




read the original abstract
Robot learning research is fragmented across policy families, benchmark suites, and real robots; each implementation is entangled with the others in a complex combination matrix, making it an engineering nightmare to port any single element. General-purpose coding agents may occasionally bridge specific setups, but cannot close this gap at scale because they lack the procedural priors and validation practices that characterize robotics research workflows. We propose NAUTILUS, an open-source harness that turns a single user prompt -- for example, "Evaluate policy A with benchmark B" -- into ready-to-use reproduction, evaluation, fine-tuning, and deployment workflows. NAUTILUS provides: plug-and-play agent skill sets with distilled priors from robotics research; typed contracts among policies, simulators/benchmarks, and real-world robots; unified interfaces and execution environments; and a trustworthy agentic coding workflow with explicit, automated validation, and testing at each milestone. NAUTILUS can not only automatically generate the required adapters and containers for existing implementations, but also wrap and onboard new or user-provided policies, simulators/benchmarks, and robots, all connected via a uniform interface. This expands cross-validation coverage without hand-written glue code. Like a nautilus shell that grows by adding chambers, NAUTILUS scales by extending its execution in chambered units, making it a research harness for scalability rather than a hand-curated framework, and aiming to reduce the engineering burden of cross-family reproduction and evaluation in the ever-growing robot learning ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NAUTILUS, an open-source harness that converts a single user prompt (e.g., 'Evaluate policy A with benchmark B') into ready-to-use reproduction, evaluation, fine-tuning, and deployment workflows for robot learning. It supplies distilled robotics priors via agent skill sets, typed contracts among policies/simulators/robots, unified interfaces, chambered execution units, and an agentic coding workflow with automated validation at each step. The central claim is that NAUTILUS can automatically generate adapters/containers for existing implementations and wrap/onboard arbitrary new or user-provided policies, simulators/benchmarks, and robots via a uniform interface, thereby expanding cross-validation coverage without hand-written glue code.
Significance. If the automated adapter generation and typed-contract maintenance actually succeed at scale, the system would meaningfully lower the engineering barrier to cross-family reproduction and evaluation in robot learning, where current fragmentation across policy families, benchmarks, and hardware makes integration costly. The open-source intent and emphasis on procedural priors from the field are positive elements.
major comments (3)
- [Abstract and §1] Abstract and §1: The claim that 'NAUTILUS can automatically generate the required adapters and containers for existing implementations' and 'wrap and onboard new or user-provided policies, simulators/benchmarks, and robots' is presented without any implementation details, pseudocode, or concrete examples of the typed contracts, validation suite, or agentic workflow. This absence makes it impossible to assess whether the system can detect semantic mismatches (observation spaces, action rates, timing constraints) or remain stable under API evolution.
- [Abstract] Abstract: The assertion that the approach 'expands cross-validation coverage without hand-written glue code' relies on an untested assumption that procedural priors plus automated validation suffice for arbitrary components. No failure-mode analysis, coverage metrics, or effort comparisons (e.g., lines of glue code avoided) are supplied, leaving the plug-and-play guarantee unsupported.
- [Abstract] The manuscript supplies no case studies, ablation results, or quantitative evidence on success rate for onboarding previously unseen components, which is load-bearing for the central contribution.
minor comments (1)
- [Abstract] The 'chambered execution units' metaphor is introduced but never operationalized with concrete architecture diagrams or execution semantics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript would benefit from greater specificity and supporting evidence. We address each major comment below and commit to substantial revisions that incorporate the requested details, examples, and preliminary results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The claim that 'NAUTILUS can automatically generate the required adapters and containers for existing implementations' and 'wrap and onboard new or user-provided policies, simulators/benchmarks, and robots' is presented without any implementation details, pseudocode, or concrete examples of the typed contracts, validation suite, or agentic workflow. This absence makes it impossible to assess whether the system can detect semantic mismatches (observation spaces, action rates, timing constraints) or remain stable under API evolution.
Authors: We agree that the current manuscript presents these capabilities at a high level without sufficient implementation specifics. In the revised version we will add a dedicated subsection in §2 (or a new §3) that includes: (1) pseudocode for the agentic workflow and chambered execution, (2) concrete examples of typed contracts (e.g., schema definitions for observation spaces, action rates, and timing constraints), and (3) the structure of the automated validation suite. We will explicitly describe how semantic mismatches are detected via contract checking and how the system handles API evolution through versioned interfaces and fallback adapters. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the approach 'expands cross-validation coverage without hand-written glue code' relies on an untested assumption that procedural priors plus automated validation suffice for arbitrary components. No failure-mode analysis, coverage metrics, or effort comparisons (e.g., lines of glue code avoided) are supplied, leaving the plug-and-play guarantee unsupported.
Authors: The manuscript frames NAUTILUS as a design that leverages robotics priors and validation to reduce manual integration. We acknowledge that this claim currently lacks supporting analysis. In revision we will add a new subsection discussing failure modes (e.g., when priors are insufficient for highly novel components or when validation cannot resolve timing mismatches), preliminary coverage metrics from our development tests, and effort comparisons (lines of code and time) between manual adapter writing and NAUTILUS-assisted onboarding. revision: yes
-
Referee: [Abstract] The manuscript supplies no case studies, ablation results, or quantitative evidence on success rate for onboarding previously unseen components, which is load-bearing for the central contribution.
Authors: We recognize that the absence of empirical results makes it difficult to evaluate the practical effectiveness of the approach. The revised manuscript will include a new experiments section with case studies on onboarding previously unseen policies, benchmarks, and robots. These will report success rates, ablation results isolating the contribution of the priors and validation steps, and quantitative comparisons against baseline manual integration efforts. revision: yes
Circularity Check
No circularity: system proposal lacks derivation chain
full rationale
The manuscript describes an engineering harness and agentic coding workflow for unifying robot learning components. It contains no equations, fitted parameters, uniqueness theorems, or self-citations that serve as load-bearing premises for any claimed result. All assertions about adapters, typed contracts, and plug-and-play onboarding are presented as design choices and implementation features rather than derivations that reduce to their own inputs by construction. The work is therefore self-contained as a software-system proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robotics research workflows share consistent procedural priors and validation practices that can be captured in agent skill sets and typed contracts.
invented entities (1)
-
NAUTILUS harness with chambered execution units
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35 (2):1–72, 2026
work page 2026
-
[2]
Yihong Dong, Xue Jiang, Jiaru Qian, Tian Wang, Kechi Zhang, Zhi Jin, and Ge Li. A survey on code generation with llm-based agents.arXiv preprint arXiv:2508.00083, 2025
-
[3]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
work page 2023
-
[4]
Eureka: Human-level reward design via coding large language models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=IEduRUO55F
work page 2024
-
[5]
Qianyu Meng, Yanan Wang, Liyi Chen, Wei Wu, Yihang Li, Wenyuan Jiang, Qimeng Wang, Chengqiang Lu, Yan Gao, Yi Wu, and Yao Hu. Agent harness for large language model agents: A survey. 2026. doi: 10.20944/preprints202604.0428.v2. URL https://www.preprints. org/manuscript/202604.0428/v2
- [6]
-
[7]
Natural-Language Agent Harnesses
Linyue Pan, Lexiao Zou, Shuo Guo, Jingchen Ni, and Hai-Tao Zheng. Natural-language agent harnesses, 2026. URLhttps://arxiv.org/abs/2603.25723
-
[8]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/ abs/2603.28052
work page internal anchor Pith review arXiv 2026
-
[9]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[10]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse-kai Chan, et al. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.arXiv preprint arXiv:2410.00425, 2024
-
[12]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Lerobot: An open-source library for end-to-end robot learning.arXiv preprint arXiv:2602.22818, 2026
Remi Cadene, Simon Alibert, Francesco Capuano, Michel Aractingi, Adil Zouitine, Pepijn Kooijmans, Jade Choghari, Martino Russi, Caroline Pascal, Steven Palma, Mustafa Shukor, Jess Moss, Alexander Soare, Dana Aubakirova, Quentin Lhoest, Quentin Gallouédec, and Thomas Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe Fourteenth Inte...
-
[14]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Anto- nio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Soroush Nasiriany, Yifeng Zhu, and Kevin Lin. robosuite: A modular simulation framework and benchmark for robot learning. InarXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
Claude code: An agentic coding tool
Anthropic. Claude code: An agentic coding tool. GitHub, 2025. 2025b
work page 2025
-
[17]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for AI soft...
work page 2025
-
[18]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=mXpq6ut8J3
work page 2024
-
[19]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Qiwei Liang, Zixuan Li, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
work page 2021
-
[21]
Isaac lab-arena: Composable environment cre- ation and policy evaluation for robotics, 2025
NVIDIA Isaac Lab-Arena Contributors. Isaac lab-arena: Composable environment cre- ation and policy evaluation for robotics, 2025. URL https://github.com/isaac-sim/ IsaacLab-Arena
work page 2025
-
[22]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[23]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[24]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=Yacmpz84TH
work page 2023
-
[25]
Holistic agent leaderboard: The missing infrastructure for AI agent evaluation
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, 12 Kangheng Liu, Botao Yu, Amit Arora, Dongyoon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang,...
work page 2026
-
[26]
Towards a science of ai agent reliability, 2026
Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. Towards a science of ai agent reliability, 2026. URL https://arxiv.org/abs/ 2602.16666
-
[27]
The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems
Leon Staufer, Kevin Feng, Kevin Wei, Luke Bailey, Yawen Duan, Mick Yang, A. Pinar Ozisik, Stephen Casper, and Noam Kolt. The 2025 ai agent index: Documenting technical and safety features of deployed agentic ai systems, 2026. URL https://arxiv.org/abs/2602.17753
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. InConference on robot learning, pages 158–168. PMLR, 2022
work page 2022
-
[29]
Xiaogang Jia, Qian Wang, Anrui Wang, Han A. Wang, Balázs Gyenes, Emiliyan Gospodinov, Xinkai Jiang, Ge Li, Hongyi Zhou, Weiran Liao, Xi Huang, Maximilian Beck, Moritz Reuss, Rudolf Lioutikov, and Gerhard Neumann. Pointmappolicy: Structured point cloud processing for multi-modal imitation learning. InThe Thirty-ninth Annual Conference on Neural Information...
work page 2026
-
[30]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[31]
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. Mobile ALOHA: Learning bimanual mobile manipulation using low-cost whole-body teleoperation. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=FO6tePGRZj
work page 2024
-
[32]
Universal manipula- tion interface: In-the-wild robot teaching without in-the- wild robots,
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
-
[33]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024
work page 2024
-
[34]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherl...
work page 2024
-
[35]
Baku: An efficient transformer for multi-task policy learning.arXiv preprint arXiv:2406.07539, 2024
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. Baku: An efficient transformer for multi-task policy learning.arXiv preprint arXiv:2406.07539, 2024
-
[36]
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, and Yuntao Chen. Dita: Scaling diffusion transformer for generalist vision-language-action policy.arXiv preprint arXiv:2503.19757, 2025
-
[37]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. URL https://arxiv.org/abs/1801.01290
work page internal anchor Pith review arXiv 2018
-
[39]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018. 13
work page 2018
-
[40]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research, 22(268):1–8, 2021. URL http://jmlr.org/papers/v22/ 20-1364.html
work page 2021
-
[41]
Isaac gym: High performance GPU based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance GPU based physics simulation for robot learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2...
work page 2021
-
[42]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, De...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alex Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, et al. Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
-
[51]
Helix: A vision-language-action model for generalist humanoid control.Figure AI News, 2024
AI Figure. Helix: A vision-language-action model for generalist humanoid control.Figure AI News, 2024
work page 2024
-
[52]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Tinyvla: To- wards fast, data-efficient vision-language-action models for robotic manipulation, 2024
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.arXiv preprint arXiv:2409.12514, 2024
-
[55]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review arXiv 2024
-
[56]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
FLOWER: Democratizing generalist robot policies with efficient vision-language- flow models
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. FLOWER: Democratizing generalist robot policies with efficient vision-language- flow models. In9th Annual Conference on Robot Learning, 2025. URL https://openreview. net/forum?id=JeppaebLRD
work page 2025
-
[58]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page Pith review arXiv 2025
-
[60]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model, 2025
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, and Feifei Feng. Chatvla: Unified multimodal understanding and robot control with vision-language-action model, 2025. URL https:// arxiv.org/abs/2502.14420
-
[61]
Hengtao Li, Pengxiang Ding, Runze Suo, Yihao Wang, Zirui Ge, Dongyuan Zang, Kexian Yu, Mingyang Sun, Hongyin Zhang, Donglin Wang, et al. Vla-rft: Vision-language-action reinforce- ment fine-tuning with verified rewards in world simulators.arXiv preprint arXiv:2510.00406, 2025
-
[62]
What can RL bring to VLA generalization? an empirical study
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can RL bring to VLA generalization? an empirical study. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=qmBMPInbZC
work page 2026
-
[63]
World action models are zero-shot policies,
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
-
[64]
URLhttps://arxiv.org/abs/2602.15922. 15
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[66]
Day- dreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Day- dreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
work page 2023
-
[67]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[69]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[70]
ivideogpt: Interactive videogpts are scalable world models
Jialong Wu, Shaofeng Yin, Ningya Feng, Xu He, Dong Li, Jianye Hao, and Mingsheng Long. ivideogpt: Interactive videogpts are scalable world models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[71]
Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
-
[72]
arXiv preprint arXiv:2602.06949 , year=
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Yuqi Xie, Ruijie Zheng, Dantong Niu, You Liang Tan, K.R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter Abbeel,...
-
[73]
Ctrl-world: A controllable generative world model for robot manipulation
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=748bHL2BAv
work page 2026
-
[74]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model, 2025. URL https://arxiv.org/abs/2512.13030
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, Min Cao, Peng Li, Qiuping Deng, Wenjun Mei, Xiaofeng Wang, Xinze Chen, Xinyu Zhou, Yang Wang, Yifan Chang, Yifan Li, Yukun Zhou, Yun Ye, Zhichao Liu, and Zheng Zhu. Gigaworld-policy: An efficient action-centered world-action model.arXiv preprint...
-
[76]
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation.arXiv preprint arXiv:2311.01455, 2023
-
[77]
V ox- poser: Composable 3d value maps for robotic manipulation with language models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V ox- poser: Composable 3d value maps for robotic manipulation with language models. In7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id= 9_8LF30mOC
work page 2023
-
[78]
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[79]
Xiaogang Jia, Atalay Donat, Xi Huang, Xuan Zhao, Denis Blessing, Hongyi Zhou, Han A Wang, Hanyi Zhang, Qian Wang, Rudolf Lioutikov, et al. X-il: Exploring the design space of imitation learning policies.arXiv preprint arXiv:2502.12330, 2025. 16
-
[80]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id=dk-2R1f_LR
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.