Recognition: 2 theorem links
· Lean TheoremDreamAvoid: Critical-Phase Test-Time Dreaming to Avoid Failures in VLA Policies
Pith reviewed 2026-05-13 05:54 UTC · model grok-4.3
The pith
A test-time dreaming method lets VLA robots foresee and avoid failures during delicate manipulation steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
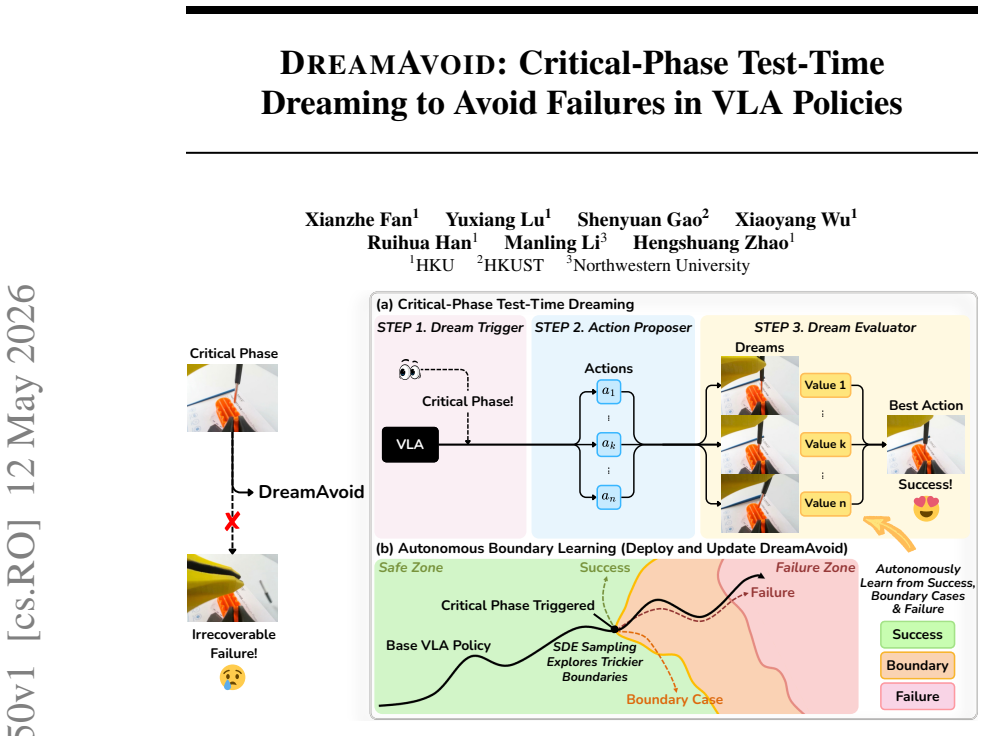
DreamAvoid is a critical-phase test-time dreaming framework for VLA policies. It uses a Dream Trigger to detect when the robot enters a delicate phase, samples candidate action chunks via an Action Proposer, and employs a Dream Evaluator trained on mixed success, failure, and boundary data to dream short-horizon futures, evaluate their values, and select the optimal action, thereby preventing irrecoverable failures.
What carries the argument
The DreamAvoid framework, which combines a Dream Trigger to identify critical phases, an Action Proposer to generate candidate action chunks, and a Dream Evaluator that predicts and scores short-horizon futures of those actions using mixed training data.
If this is right
- VLA policies achieve higher task success rates on real-world manipulation tasks and simulation benchmarks without retraining.
- The approach gives VLA models explicit awareness of failure modes during critical phases.
- Autonomous boundary learning refines the distinction between success and failure in subtle cases.
- Test-time selection among candidate actions reduces escalation of minor errors into total failures.
Where Pith is reading between the lines
- The same test-time dreaming pattern could extend to other sequential robot tasks where timing of decisions is decisive.
- Boundary learning from mixed data might improve initial VLA training in addition to test-time use.
- If dreaming horizons were lengthened, the method could support planning over more extended action sequences.
Load-bearing premise
The Dream Evaluator can accurately predict short-horizon futures for candidate actions from mixed success-failure-boundary data, and the Dream Trigger reliably spots critical phases without too many false triggers or missed ones.
What would settle it
A head-to-head comparison on the same manipulation tasks where the success rate with DreamAvoid equals or falls below the plain VLA baseline, or where the evaluator's predicted futures consistently mismatch the actual robot outcomes.
Figures






read the original abstract
Vision-Language-Action (VLA) models are often brittle in fine-grained manipulation, where minor action errors during the critical phases can rapidly escalate into irrecoverable failures. Since existing VLA models rely predominantly on successful demonstrations for training, they lack an explicit awareness of failure during these critical phases. To address this, we propose DreamAvoid, a critical-phase test-time dreaming framework that enables VLA models to anticipate and avoid failures. We also introduce an autonomous boundary learning paradigm to refine the system's understanding of the subtle boundary between success and failure. Specifically, we (1) utilize a Dream Trigger to determine whether the execution has entered a critical phase, (2) sample multiple candidate action chunks from the VLA via an Action Proposer, and (3) employ a Dream Evaluator, jointly trained on mixed data (success, failure, and boundary cases), to "dream" the short-horizon futures corresponding to the candidate actions, evaluate their values, and select the optimal action. We conduct extensive evaluations on real-world manipulation tasks and simulation benchmarks. The results demonstrate that DreamAvoid can effectively avoid failures, thereby improving the overall task success rate. Our code is available at https://github.com/XianzheFan/DreamAvoid.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DreamAvoid, a critical-phase test-time dreaming framework for Vision-Language-Action (VLA) policies. It detects critical phases via a Dream Trigger, samples candidate action chunks with an Action Proposer, and uses a Dream Evaluator (jointly trained on success/failure/boundary data) to predict short-horizon futures and select the optimal action. The central claim is that this enables VLA models to anticipate and avoid failures in fine-grained manipulation, improving overall task success rates on real-world tasks and simulation benchmarks, supported by an autonomous boundary learning paradigm.
Significance. If the empirical claims hold, the work could meaningfully advance VLA robustness by addressing failure awareness at test time rather than through retraining. The open-sourced code at the provided GitHub link is a clear strength for reproducibility. The autonomous boundary learning idea is conceptually interesting for handling subtle success/failure transitions.
major comments (2)
- [§4] §4 (Experiments): The abstract asserts improved success rates on real-world and simulation tasks, yet supplies no quantitative numbers, baselines, error bars, ablation studies, or experimental protocol details. This prevents any assessment of the magnitude, statistical significance, or reliability of the claimed failure avoidance.
- [§3.2] §3.2 (Dream Evaluator): The selection step relies on the evaluator correctly ranking short-horizon futures of candidate actions, but no metrics are reported on its prediction accuracy, ranking correlation with actual outcomes, or generalization beyond the mixed training distribution. This is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract and §3: The framework introduces multiple new components (Dream Trigger, Action Proposer, Dream Evaluator) with only high-level descriptions; adding a concise algorithmic outline or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive review, the recognition of the conceptual interest in autonomous boundary learning, and the positive note on code availability for reproducibility. We address each major comment point-by-point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The abstract asserts improved success rates on real-world and simulation tasks, yet supplies no quantitative numbers, baselines, error bars, ablation studies, or experimental protocol details. This prevents any assessment of the magnitude, statistical significance, or reliability of the claimed failure avoidance.
Authors: We agree that the abstract, constrained by length, presents only a high-level claim without specific numbers or details. Section 4 of the manuscript contains the full quantitative results, including task success rates with baseline comparisons, error bars from repeated trials, ablation studies on the Dream Trigger, Action Proposer, and Dream Evaluator, and complete experimental protocols for both real-world and simulation settings. To address the concern directly, we will revise the abstract to include key quantitative highlights such as the observed improvements in success rates. revision: yes
-
Referee: [§3.2] §3.2 (Dream Evaluator): The selection step relies on the evaluator correctly ranking short-horizon futures of candidate actions, but no metrics are reported on its prediction accuracy, ranking correlation with actual outcomes, or generalization beyond the mixed training distribution. This is load-bearing for the central claim.
Authors: We acknowledge that direct validation of the Dream Evaluator's ranking and prediction quality is important for supporting the core mechanism. While the manuscript reports the end-to-end benefits through task success rates in Section 4, we agree that explicit metrics would strengthen the presentation. We will add to Section 3.2 (or a new subsection in Section 4) an analysis reporting the evaluator's prediction accuracy on held-out data, ranking correlation with ground-truth outcomes, and generalization results beyond the mixed success/failure/boundary training distribution. revision: yes
Circularity Check
No circularity: empirical test-time framework with no derivations or self-referential reductions
full rationale
The paper presents DreamAvoid as a practical test-time procedure (Dream Trigger to detect critical phases, Action Proposer to sample chunks, Dream Evaluator trained on mixed success/failure/boundary data to rank short-horizon futures). No equations, first-principles derivations, or mathematical claims appear in the provided text. Success-rate improvements are asserted solely from experimental results on real-world and simulation tasks, with no reduction of any 'prediction' to fitted inputs or self-citations. The Dream Evaluator's training is described as standard supervised learning on external data categories; its accuracy is an empirical question evaluated outside the method definition itself. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A Dream Evaluator trained jointly on success, failure, and boundary cases can produce reliable value estimates for short-horizon futures of candidate actions.
invented entities (3)
-
Dream Trigger
no independent evidence
-
Action Proposer
no independent evidence
-
Dream Evaluator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose DREAMAVOID, a critical-phase test-time dreaming framework... Dream Trigger... Action Proposer... Dream Evaluator... autonomous boundary learning paradigm
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dream Evaluator... jointly trained on mixed data (success, failure, and boundary cases)... value of a candidate action chunk as the real progress delta
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
work page 2025
-
[2]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
work page 2025
-
[3]
π0: A vision-language-action flow model for general robot control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. InProceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[4]
RL Token: Bootstrapping Online RL with Vision-Language-Action Models
Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, and Liyiming Ke. Rl token: Bootstrapping online rl with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Heng Zhang, Rui Dai, Gokhan Solak, Pokuang Zhou, Yu She, and Arash Ajoudani. Safe learning for contact-rich robot tasks: A survey from classical learning-based methods to safe foundation models.arXiv preprint arXiv:2512.11908, 2025
-
[6]
Songqiao Hu, Zeyi Liu, Shuang Liu, Jun Cen, Zihan Meng, and Xiao He. Vlsa: Vision-language- action models with plug-and-play safety constraint layer.arXiv preprint arXiv:2512.11891, 2025
-
[7]
Yujiro Onishi, Ryo Takizawa, Yoshiyuki Ohmura, and Yasuo Kuniyoshi. Exploration-assisted bottleneck transition toward robust and data-efficient deformable object manipulation.arXiv preprint arXiv:2603.13756, 2026
-
[8]
arXiv preprint arXiv:2602.06949 , year=
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
-
[9]
Robomonkey: Scaling test-time sampling and verification for vision-language-action models
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Foutter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models. InConference on Robot Learning, pages 3200–3217. PMLR, 2025
work page 2025
-
[10]
Han Qi, Haocheng Yin, Aris Zhu, Yilun Du, and Heng Yang. Inference-time enhancement of generative robot policies via predictive world modeling.IEEE Robotics and Automation Letters, 2026
work page 2026
-
[11]
Deep visual foresight for planning robot motion
Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In2017 IEEE international conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
work page 2017
-
[12]
Wenkai Guo, Guanxing Lu, Haoyuan Deng, Zhenyu Wu, Yansong Tang, and Ziwei Wang. Vla-reasoner: Empowering vision-language-action models with reasoning via online monte carlo tree search.arXiv preprint arXiv:2509.22643, 2025
-
[13]
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, Wei-Chuan Tsai, Jiafei Duan, Dieter Fox, and Ranjay Krishna. RECURRENT-DEPTH VLA: IMPLICIT TEST-TIME COMPUTE SCALING OF VISION–LANGUAGE–ACTION MODELS VIA LATENT ITERATIVE REASONING. InWorkshop on Latent & Implicit Thinking – Going Beyond CoT Reasoning, 2026. URL https://openreview.net/forum?id=hsIm52gD9p. 10
work page 2026
-
[14]
Yanting Yang, Shenyuan Gao, Qingwen Bu, Li Chen, and Dimitris N Metaxas. Seeing farther and smarter: Value-guided multi-path reflection for vlm policy optimization.arXiv preprint arXiv:2602.19372, 2026
-
[15]
Learning from imperfect demonstrations with self-supervision for robotic manipulation
Kun Wu, Ning Liu, Zhen Zhao, Di Qiu, Jinming Li, Zhengping Che, Zhiyuan Xu, and Jian Tang. Learning from imperfect demonstrations with self-supervision for robotic manipulation. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16899–16906. IEEE, 2025
work page 2025
-
[16]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[17]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning, pages 3705–3728. PMLR, 2025
work page 2025
-
[18]
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Changyu Liu, Yiyang Liu, Taowen Wang, Qiao Zhuang, James Chenhao Liang, Wenhao Yang, Renjing Xu, Qifan Wang, Dongfang Liu, and Cheng Han. On-the-fly vla adaptation via test-time reinforcement learning.arXiv preprint arXiv:2601.06748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Zechen Bai, Chen Gao, and Mike Zheng Shou. Evolve-vla: Test-time training from environment feedback for vision-language-action models.arXiv preprint arXiv:2512.14666, 2025
-
[20]
Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation
Yunhai Feng, Jiaming Han, Zhuoran Yang, Xiangyu Yue, Sergey Levine, and Jianlan Luo. Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation. InConference on Robot Learning, pages 2038–2062. PMLR, 2025
work page 2038
-
[21]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[22]
Gemini 3.1 pro: A smarter model for your most com- plex tasks
The Gemini Team. Gemini 3.1 pro: A smarter model for your most com- plex tasks. https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, 2026
work page 2026
-
[23]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[24]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Quanlu Zhang, Zhaofei Yu, Guoliang Fan, et al. πrl: Online rl fine-tuning for flow-based vision- language-action models.arXiv preprint arXiv:2510.25889, 2025
-
[26]
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S Huang, Luke Zettlemoyer, Dieter Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
work page internal anchor Pith review arXiv 2026
-
[27]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992
work page 1992
-
[28]
Yanjiang Guo, Tony Lee, Lucy Xiaoyang Shi, Jianyu Chen, Percy Liang, and Chelsea Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model.arXiv preprint arXiv:2602.12063, 2026
-
[29]
PlayWorld: Learning Robot World Models from Autonomous Play
Tenny Yin, Zhiting Mei, Zhonghe Zheng, Miyu Yamane, David Wang, Jade Sceats, Samuel M Bateman, Lihan Zha, Apurva Badithela, Ola Shorinwa, et al. Playworld: Learning robot world models from autonomous play.arXiv preprint arXiv:2603.09030, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2410.00371 , year=
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation.arXiv preprint arXiv:2410.00371, 2024
-
[32]
Reflect: Summarizing robot experiences for failure explanation and correction
Zeyi Liu, Arpit Bahety, and Shuran Song. Reflect: Summarizing robot experiences for failure explanation and correction. InConference on Robot Learning, pages 3468–3484. PMLR, 2023
work page 2023
-
[33]
SAFE: Multitask failure detection for vision-language-action models
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. SAFE: Multitask failure detection for vision-language-action models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=XPyAukgsFf
work page 2025
-
[34]
Huanyu Li, Kun Lei, Sheng Zang, Kaizhe Hu, Yongyuan Liang, Bo An, Xiaoli Li, and Huazhe Xu. Failure-aware rl: Reliable offline-to-online reinforcement learning with self-recovery for real-world manipulation.arXiv preprint arXiv:2601.07821, 2026
-
[35]
World action models are zero-shot policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies. InICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling, 2026
work page 2026
-
[36]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. A Extended Related Work Failure Detection.Handling failures is typically viewed as a reactive process: the system must first detect the occurrence of an error and subsequentl...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
as the backbone for Dream Trigger. First, we perform frame-by-frame feature encoding on the images from each camera feed (which include sparsely sampled historical observations and the current frame) and execute average pooling along the temporal dimension. Subsequently, the aggregated single- or multi-camera visual features are concatenated with the curr...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.