SURGE: Approximation-free Training Free Particle Filter for Diffusion Surrogate
Pith reviewed 2026-05-20 07:46 UTC · model grok-4.3
pith:YGQREDCW Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{YGQREDCW}
Prints a linked pith:YGQREDCW badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
URGE performs unbiased path-wise resampling for diffusion guidance by attaching Girsanov multiplicative weights to trajectories and resampling periodically without any score or gradient evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that path-wise importance reweighting via the Girsanov change of measure is equivalent to particle-wise sequential Monte Carlo for diffusion processes: the Girsanov path weight admits a backward conditional expectation that recovers the previous particle-level weights exactly, so that both schemes produce the same unbiased terminal law. This equivalence underpins URGE, which requires no score, Hessian, or PDE evaluation and is implemented by attaching multiplicative weights to trajectories followed by periodic resampling.
What carries the argument
The Girsanov path weight under a change of measure on diffusion trajectories, which supplies multiplicative importance weights that admit a backward conditional expectation recovering particle weights.
If this is right
- URGE produces the same unbiased terminal distribution as gradient-based particle filters while requiring only trajectory simulation and simple multiplicative weighting.
- No score, Hessian, or PDE solves are needed at inference time, removing the main sources of bias and overhead in prior guidance methods.
- The method applies to any diffusion satisfying the regularity conditions and can be combined with mixture-of-experts or drift adjustments for task-specific objectives.
- Empirical tests show improved generation quality over existing inference-time baselines on both synthetic tasks and standard diffusion-model benchmarks.
Where Pith is reading between the lines
- The equivalence may allow swapping path-wise and particle-wise implementations interchangeably in other stochastic sampling settings where Girsanov weights can be computed.
- Because the method is fully gradient-free, it could be integrated into black-box simulators or non-differentiable forward models that still admit a Girsanov representation.
- Extensions could explore whether approximate Girsanov weights (e.g., via learned estimators) preserve unbiasedness up to controllable error in high dimensions.
Load-bearing premise
The diffusion process and the Girsanov change of measure must satisfy regularity conditions such as the Novikov condition so that the path weights are well-defined and the backward conditional expectation recovers the particle weights exactly.
What would settle it
Running both URGE and a standard particle-wise SMC sampler on the same diffusion model and target objective, then checking whether their empirical terminal distributions differ in total variation or in any moment that the theory predicts must match.
Figures


















read the original abstract
Diffusion-based generative models increasingly rely on inference-time guidance, adding a drift term or reweighting mixture of experts, to improve sample quality on task-specific objectives. However, most existing techniques require repeated score or gradient evaluations, introducing bias, high computational overhead, or both. We introduce \texttt{URGE}, Unbiased Resampling via Girsanov Estimation, a derivative-free inference-time scaling algorithm that performs path-wise importance reweighting via a Girsanov change of measure. Instead of computing gradient-based particle weights in previous work, \texttt{URGE} attaches a simple multiplicative weight to each simulated trajectory and periodically resamples. No score, no Hessian, and no PDE evaluation is required. We establish an equivalence between path-wise and particle-wise SMC: the Girsanov path weight admits a backward conditional expectation that recovers the previous particle-level weights, guaranteeing that both schemes produce the same unbiased terminal law. Empirically, \texttt{URGE} outperforms existing inference-time guidance baselines on synthetic tests and diffusion-model benchmarks, achieving better generation quality, while being significantly simpler to implement and fully gradient-free.
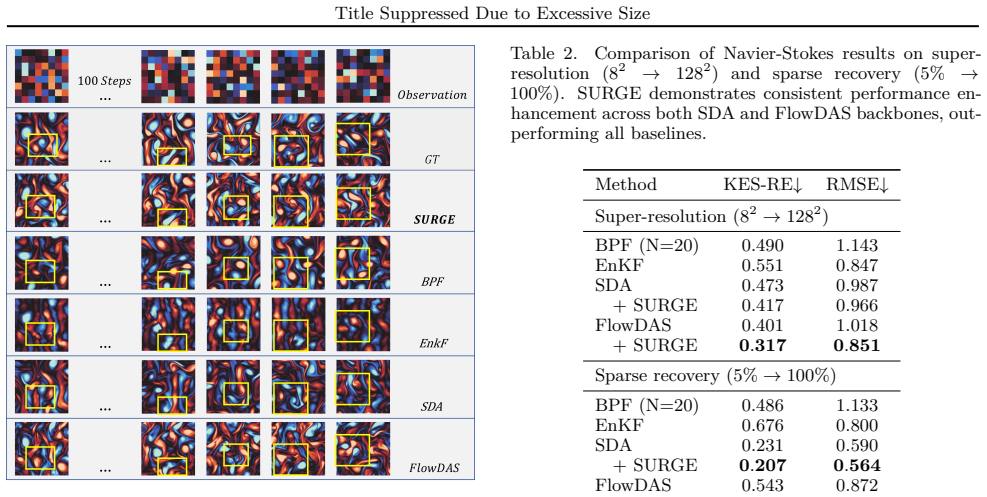
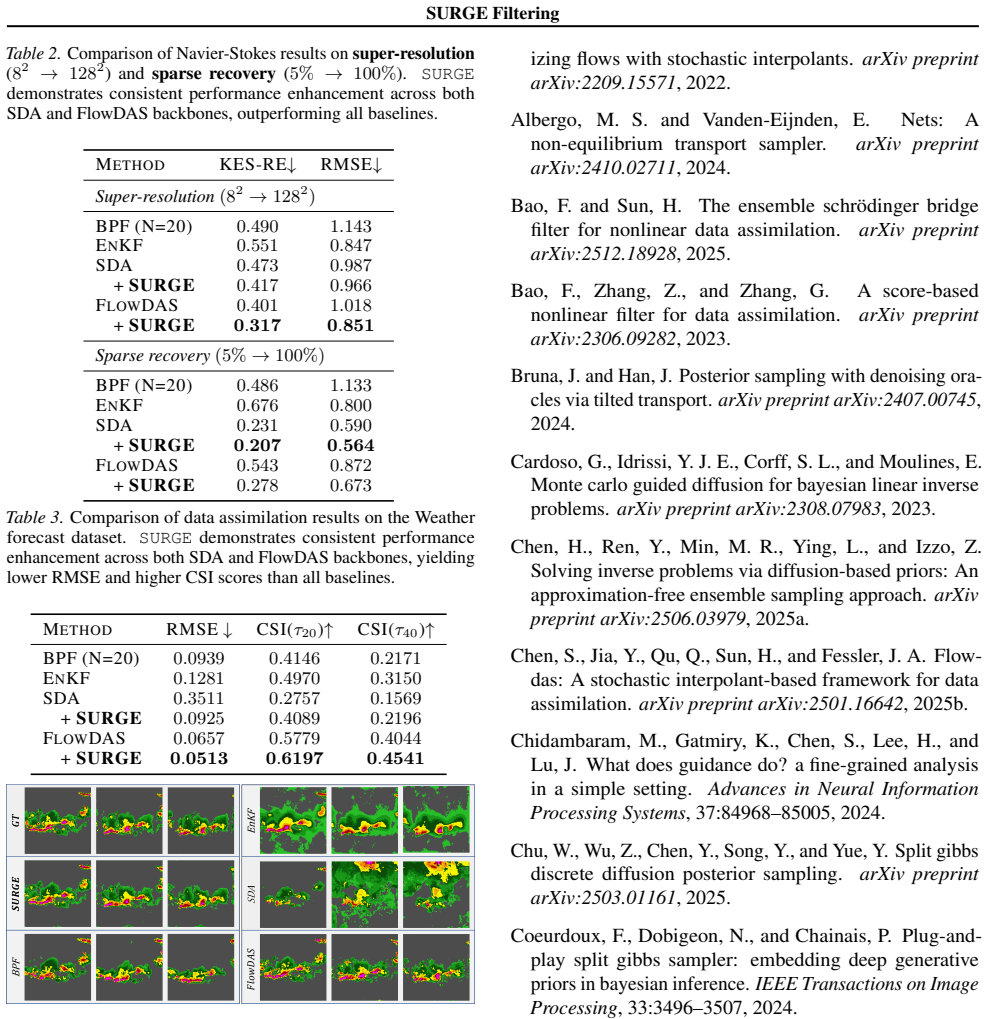
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SURGE (also referred to as URGE), an approximation-free, training-free particle filter for diffusion surrogates. It performs path-wise importance reweighting via a Girsanov change of measure, attaching multiplicative weights to simulated trajectories and resampling periodically without any score, gradient, or PDE evaluations. The central claim is an equivalence between path-wise and particle-wise SMC: the Girsanov path weight admits a backward conditional expectation that recovers the previous particle-level weights, guaranteeing both schemes produce the same unbiased terminal law. Empirical results show outperformance over existing inference-time guidance baselines on synthetic tests and diffusion-model benchmarks.
Significance. If the equivalence holds, the work provides a simple gradient-free alternative for inference-time scaling in diffusion models, eliminating bias and overhead from repeated score evaluations. The derivation from established stochastic calculus and the empirical gains are strengths that could influence practical generative modeling pipelines.
major comments (1)
- [Theoretical equivalence derivation (continuous-time Girsanov application)] The equivalence between Girsanov path weights and particle-wise SMC weights is derived in the continuous-time semimartingale setting. Diffusion sampling uses discrete-time schemes (Euler–Maruyama or similar) with finite steps; the manuscript does not show that the discrete Radon–Nikodym derivative equals the backward conditional expectation of the continuous Girsanov exponential or bound the resulting O(Δt) discrepancy. This is load-bearing for the exact unbiasedness and approximation-free claims.
minor comments (2)
- [Title and abstract] Title uses SURGE while abstract introduces URGE; ensure acronym consistency and expand it on first use.
- [Abstract and introduction] Hyphenate 'Training Free' as 'training-free' and check for similar compound-adjective issues throughout.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. Below we address the single major comment point by point, with a commitment to strengthen the presentation of the discrete-time case.
read point-by-point responses
-
Referee: [Theoretical equivalence derivation (continuous-time Girsanov application)] The equivalence between Girsanov path weights and particle-wise SMC weights is derived in the continuous-time semimartingale setting. Diffusion sampling uses discrete-time schemes (Euler–Maruyama or similar) with finite steps; the manuscript does not show that the discrete Radon–Nikodym derivative equals the backward conditional expectation of the continuous Girsanov exponential or bound the resulting O(Δt) discrepancy. This is load-bearing for the exact unbiasedness and approximation-free claims.
Authors: We appreciate the referee identifying this important clarification. The continuous-time derivation is presented to exploit standard results from stochastic calculus and to make the connection to Girsanov’s theorem transparent. In the discrete-time setting actually used for sampling, the path-wise weight is exactly the product, over Euler–Maruyama steps, of the Radon–Nikodym derivatives between the two Gaussian transition kernels. This product is the natural discrete counterpart of the continuous Girsanov exponential. By the tower property of conditional expectation, the backward conditional expectation of these discrete weights recovers the particle-wise weights exactly (no additional approximation). The only O(Δt) discrepancy appears when one compares the discrete weights to their continuous-time limit; however, because the underlying diffusion sampler itself is already an O(Δt) approximation, the terminal measure produced by URGE remains unbiased relative to the discrete particle filter that would be obtained by direct particle-wise reweighting. We will add a short subsection (or appendix paragraph) that (i) states the discrete Radon–Nikodym form explicitly, (ii) verifies the tower-property equivalence in discrete time, and (iii) notes that any remaining discretization error is of the same order as the numerical scheme already employed by all competing methods. This revision will be included in the next manuscript version. revision: yes
Circularity Check
No circularity: equivalence derived from external Girsanov theorem and conditional expectation identity
full rationale
The paper's central derivation establishes an equivalence between path-wise Girsanov reweighting and particle-wise SMC by invoking the standard Girsanov change of measure and a backward conditional expectation that recovers prior particle weights. This step relies on established stochastic calculus results (Girsanov theorem under Novikov-type regularity) rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations reduce the claimed unbiased terminal law to the paper's own inputs by construction; the argument is self-contained against external mathematical benchmarks and does not smuggle ansatzes or rename known empirical patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The underlying stochastic differential equation satisfies the regularity conditions required for Girsanov's theorem to define a valid change of measure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the Girsanov path weight admits a backward conditional expectation that recovers the previous particle-level weights, guaranteeing that both schemes produce the same unbiased terminal law
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Euler–Maruyama scheme for the computation of the integrals in (6)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Albergo, M. S. and Vanden-Eijnden, E. Building nor- malizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
The Ensemble Schr{\"o}dinger Bridge filter for Nonlinear Data Assimilation
Bao, F. and Sun, H. The ensemble schrödinger bridge filter for nonlinear data assimilation. arXiv preprint arXiv:2512.18928,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A score-based non- linear filter for data assimilation
Bao, F., Zhang, Z., and Zhang, G. A score-based non- linear filter for data assimilation. arXiv preprint arXiv:2306.09282,
-
[5]
Bruna, J. and Han, J. Posterior sampling with de- noising oracles via tilted transport. arXiv preprint arXiv:2407.00745,
- [6]
-
[7]
Chen, H., Ren, Y., Min, M. R., Ying, L., and Izzo, Z. Solving inverse problems via diffusion-based priors: An approximation-free ensemble sampling approach. arXiv preprint arXiv:2506.03979, 2025a. Chen, S., Jia, Y., Qu, Q., Sun, H., and Fessler, J. A. Flowdas: A stochastic interpolant-based framework for data assimilation. arXiv preprint arXiv:2501.16642,...
-
[8]
Split gibbs discrete diffusion posterior sampling
Chu, W., Wu, Z., Chen, Y., Song, Y., and Yue, Y. Split gibbs discrete diffusion posterior sampling. arXiv preprint arXiv:2503.01161,
- [9]
-
[10]
Discrete feynman-kac correctors
Hasan, M., Ohanesian, V., Gazizov, A., Bengio, Y., Aspuru-Guzik, A., Bondesan, R., Skreta, M., and Neklyudov, K. Discrete feynman-kac correctors. arXiv preprint arXiv:2601.10403,
-
[11]
Havens, A., Miller, B. K., Yan, B., Domingo-Enrich, C., Sriram, A., Wood, B., Levine, D., Hu, B., Amos, B., Karrer, B., et al. Adjoint sampling: Highly scal- able diffusion samplers via adjoint matching. arXiv preprint arXiv:2504.11713,
-
[12]
RNE: plug-and-play diffusion inference-time control and energy-based training
He, J., Hernández-Lobato, J. M., Du, Y., and Vargas, F. Rne: a plug-and-play framework for diffusion density estimation and inference-time control. arXiv preprint arXiv:2506.05668, 2025a. 10 Title Suppressed Due to Excessive Size He, J., Jeha, P., Potaptchik, P., Zhang, L., Hernández- Lobato, J. M., Du, Y., Syed, S., and Vargas, F. Crepe: Controlling diff...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Liu, G.-H., Choi, J., Chen, Y., Miller, B. K., and Chen, R. T. Adjoint schr \” odinger bridge sampler. arXiv preprint arXiv:2506.22565,
-
[15]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://journals.ametsoc.org/view/journals/ atsc/20/2/1520-0469_1963_020_0130_dnf_2_0_ co_2.xml
doi: 10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2. URL https://journals.ametsoc.org/view/journals/ atsc/20/2/1520-0469_1963_020_0130_dnf_2_0_ co_2.xml. Ma, N., Tong, S., Jia, H., Hu, H., Su, Y.-C., Zhang, M., Yang, X., Li, Y., Jaakkola, T., Jia, X., et al. Inference-time scaling for diffusion mod- els beyond scaling denoising steps. arXiv preprint arXiv:2...
-
[17]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., and Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J.-R., and Li, C. Large language diffusion models. arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Ren, Y., Gao, W., Ying, L., Rotskoff, G. M., and Han, J. Driftlite: Lightweight drift control for inference- time scaling of diffusion models. arXiv preprint arXiv:2509.21655, 2025a. Ren, Y., Rotskoff, G. M., and Ying, L. A unified ap- proach to analysis and design of denoising markov models. arXiv preprint arXiv:2504.01938, 2025b. Robinson, M., Evans, J....
-
[20]
S., Domingo-Enrich, C., Boffi, N
Sabour, A., Albergo, M. S., Domingo-Enrich, C., Boffi, N. M., Fidler, S., Kreis, K., and Vanden-Eijnden, E. Test-time scaling of diffusions with flow maps. arXiv preprint arXiv:2511.22688,
-
[21]
A general frame- work for inference-time scaling and steering of diffu- sion models
Singhal, R., Horvitz, Z., Teehan, R., Ren, M., Yu, Z., McKeown, K., and Ranganath, R. A general frame- work for inference-time scaling and steering of diffu- sion models. arXiv preprint arXiv:2501.06848,
-
[22]
Feynman-kac correctors in diffusion: Annealing, guidance, and product of experts
Skreta, M., Akhound-Sadegh, T., Ohanesian, V., Bondesan, R., Aspuru-Guzik, A., Doucet, A., Brekelmans, R., Tong, A., and Neklyudov, K. Feynman-kac correctors in diffusion: Annealing, guidance, and product of experts. arXiv preprint arXiv:2503.02819,
-
[23]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[24]
Improving and generalizing flow-based generative models with minibatch optimal transport
Tong, A., Fatras, K., Malkin, N., Huguet, G., Zhang, Y., Rector-Brooks, J., Wolf, G., and Bengio, Y. Im- proving and generalizing flow-based generative mod- els with minibatch optimal transport. arXiv preprint arXiv:2302.00482,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review
Uehara, M., Zhao, Y., Wang, C., Li, X., Regev, A., Levine, S., and Biancalani, T. Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review. arXiv preprint arXiv:2501.09685,
-
[26]
Training-free adaptation of diffusion mod- els via doob’s h-transform
Zhu, Q., Ye, Z., Liu, H., Wang, Z., and Chen, M. Training-free adaptation of diffusion mod- els via doob’s h-transform. arXiv preprint arXiv:2602.16198,
- [27]
-
[28]
Let { ˜X (i)}N i=1 be obtained by multinomial resampling from P i ˜w(i)δX (i) and assigning equal weights 1/N. Then for any integrable test function ϕ, E " 1 N NX i=1 ϕ( ˜X (i)) {(X (j), ˜w(j))}N j=1 # = NX j=1 ˜w(j) ϕ(X (j)). Proof. Conditioned on the current weighted particles, the resampling indices are i.i.d. with P(A(i) = j) = ˜w(j) and ˜X (i) = X (A...
work page 1963
-
[29]
SURGE consistently improves both SDA and FlowDAS backbones
Full results on the Lorenz 1963 experiment. SURGE consistently improves both SDA and FlowDAS backbones. Method RMSE ↓ W1 ↓ BPF (N=20) 0.0625 0 .0448 DM 0.0766 0 .0549 EnKF 0.0624 0 .0448 SDA 0.0589 0 .0426 + SURGE 0.0555 0 .0396 FlowDAS 0.0545 0 .0388 FlowDAS A VG 0.0923 0 .0698 + SURGE 0.0502 0 .0363 Here, E(k) represents the kinetic energy spectrum, cal...
work page 1963
-
[30]
Diffusion Model (DM) refers to a plain diffusion sampler that generates trajectories from the learned prior without observation guidance, included to isolate the contribution of guidance. Ensemble Kalman Filter (EnKF) maintains a finite ensemble and applies a Kalman-style update under a Gaussian approximation of the forecast distribution( Evensen, 2003). ...
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.