Skill or Skip? Learning Selective Skill Invocation in Agentic Tasks via Dual-Granularity Preference Learning
Pith reviewed 2026-06-28 19:08 UTC · model grok-4.3
The pith
SelSkill teaches agents to treat skill use as a skill-or-skip choice and learn the right decision from dual-granularity preferences on shared trajectory prefixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
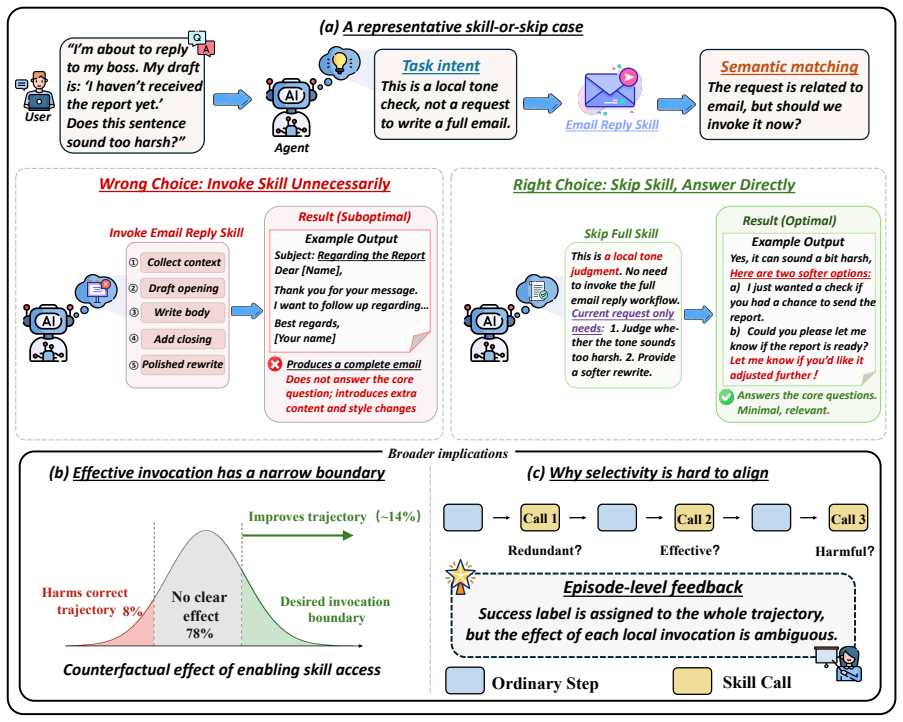
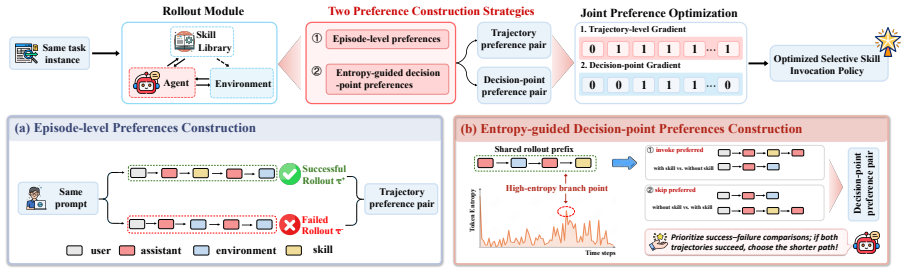
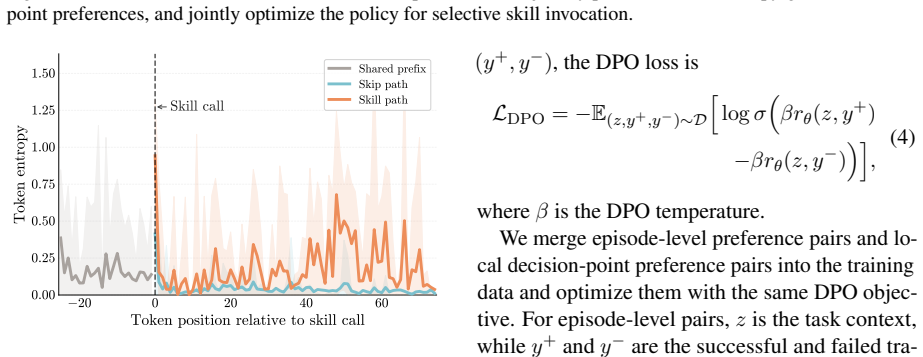
SelSkill formulates skill use as a skill-or-skip decision, uses predictive uncertainty to prioritize candidate decision points, and constructs controlled invoke-skip preference pairs from shared trajectory prefixes. It further combines episode-level outcome preferences with step-level invocation preferences to capture both overall trajectory quality and the local effectiveness of skill invocation.
What carries the argument
Dual-granularity preference pairs that compare invoke versus skip actions on identical trajectory prefixes while jointly optimizing episode outcome and local invocation quality.
If this is right
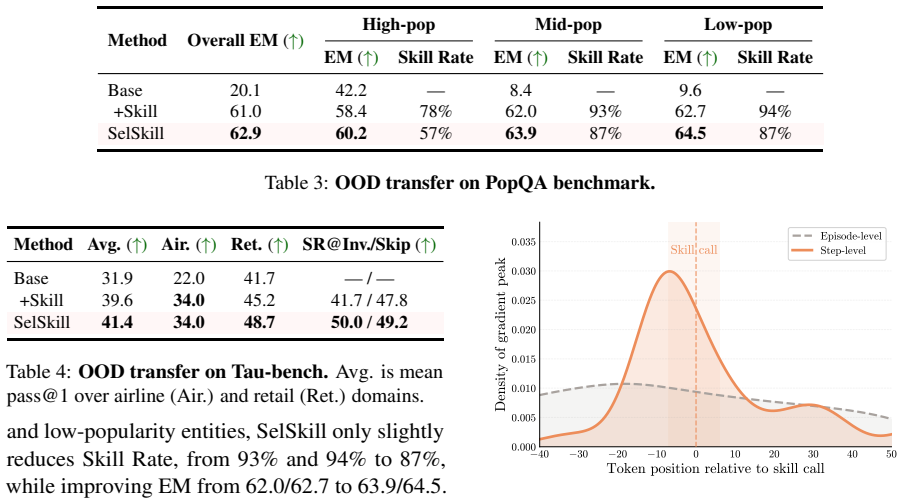
- Task success rates rise on ALFWorld and BFCL when agents learn to skip unhelpful invocations.
- Execution precision increases by roughly thirty percentage points in both environments.
- The learned invocation policy transfers zero-shot to new domains that contain previously unseen skills.
- Agents avoid injecting irrelevant context that would otherwise disrupt an otherwise correct execution process.
Where Pith is reading between the lines
- The same prefix-controlled preference construction could be applied to other conditional actions in agent workflows, such as tool calls or memory writes.
- Uncertainty-driven selection of decision points offers a practical way to focus preference data collection on moments that matter most.
- Co-training the invocation policy together with the underlying skills themselves may further improve results once the skip decision is treated as first-class.
Load-bearing premise
That preference pairs built from shared trajectory prefixes isolate the causal effect of the invocation decision itself without confounding from later steps or trajectory quality.
What would settle it
An ablation that replaces shared-prefix pairs with pairs drawn from trajectories that already differ before the decision point and measures whether the reported gains on success and precision disappear.
Figures
read the original abstract
Agent skills are callable procedural modules that provide reusable knowledge and execution policies for complex agentic tasks. However, existing methods mainly focus on selecting relevant skills or improving the skills themselves, while overlooking whether a relevant skill should actually be invoked at the current decision point. Unhelpful invocations may introduce irrelevant context and disrupt an otherwise correct execution process. To address this issue, we propose SelSkill, a dual-granularity preference-learning framework for selective skill invocation. SelSkill formulates skill use as a skill-or-skip decision, uses predictive uncertainty to prioritize candidate decision points, and constructs controlled invoke-skip preference pairs from shared trajectory prefixes. It further combines episode-level outcome preferences with step-level invocation preferences to capture both overall trajectory quality and the local effectiveness of skill invocation. On ALFWorld with Qwen3-8B, SelSkill improves task success by 10.9 percentage points and execution precision by 29.1 percentage points. On BFCL, it improves task success by 5.7 percentage points and execution precision by 29.5 percentage points. Zero-shot results on Tau-bench and PopQA further suggest that the learned invocation policy transfers to new domains with previously unseen skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SelSkill, a dual-granularity preference-learning framework for selective skill invocation in agentic tasks. It formulates invocation as a skill-or-skip decision, uses predictive uncertainty to prioritize points, constructs invoke-skip pairs from shared trajectory prefixes, and combines episode-level outcome preferences with step-level invocation preferences via DPO. Reported results include +10.9 pp task success and +29.1 pp execution precision on ALFWorld with Qwen3-8B, +5.7 pp and +29.5 pp on BFCL, plus zero-shot transfer to Tau-bench and PopQA.
Significance. If the shared-prefix construction isolates the causal effect of the invocation decision, the work addresses a practically important gap in agent skill use by learning when not to invoke. The scale of the reported gains on two benchmarks would be notable for agent reliability, but the absence of verification that downstream state changes do not confound the preference signal limits the strength of the central claim.
major comments (1)
- [Method (preference pair construction)] The shared-prefix preference pair construction (described in the method) assumes the only systematic difference between invoke and skip continuations is the binary invocation choice. In ALFWorld and similar environments, however, a skill call injects new observations and updates the belief state, so post-decision trajectories are unlikely to remain matched. No check is reported that any divergence is orthogonal to the reward signal; therefore the learned policy may attribute downstream trajectory quality to the local decision rather than isolating the invocation effect. This assumption is load-bearing for the claim that dual-granularity DPO yields a clean skill-or-skip policy.
minor comments (2)
- [Experiments] Abstract and results sections report point improvements but omit number of runs, standard deviations, statistical tests, and full baseline comparisons; these details are needed to assess whether the gains are robust.
- [Method] Notation for the two granularity levels (episode vs. step) and how the combined loss is formed should be stated explicitly with an equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment raises a valid methodological point about potential confounding in our preference pair construction. We address it below and outline planned revisions.
read point-by-point responses
-
Referee: [Method (preference pair construction)] The shared-prefix preference pair construction (described in the method) assumes the only systematic difference between invoke and skip continuations is the binary invocation choice. In ALFWorld and similar environments, however, a skill call injects new observations and updates the belief state, so post-decision trajectories are unlikely to remain matched. No check is reported that any divergence is orthogonal to the reward signal; therefore the learned policy may attribute downstream trajectory quality to the local decision rather than isolating the invocation effect. This assumption is load-bearing for the claim that dual-granularity DPO yields a clean skill-or-skip policy.
Authors: We agree that the shared-prefix construction controls the state only up to the decision point and that skill invocation necessarily alters subsequent observations and belief state. The preference signal is derived from comparing final outcomes (episode-level) or immediate step rewards (invocation-level) after the choice, which is intended to attribute quality to the invocation decision itself. However, no explicit verification that post-decision divergences are orthogonal to the reward is reported in the current manuscript. To address this, we will add an analysis section in the revision that quantifies state divergence (e.g., via embedding similarity or observation overlap) between invoke and skip branches and checks its correlation with the preference label independent of the invocation choice. This will strengthen the isolation claim while preserving the dual-granularity DPO framework. revision: yes
Circularity Check
No circularity; empirical benchmark results independent of fitted inputs or self-referential definitions
full rationale
The paper reports task success and execution precision gains on ALFWorld and BFCL benchmarks using a dual-granularity preference learning approach that constructs invoke-skip pairs from shared prefixes and combines episode- and step-level DPO. These are external empirical outcomes with no equations, predictions, or first-principles claims that reduce by construction to the paper's own fitted parameters, self-citations, or input definitions. The method is self-contained against held-out benchmarks and zero-shot transfer tasks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Predictive uncertainty can be used to prioritize decision points where skill invocation matters.
- domain assumption Preference pairs from shared trajectory prefixes isolate the local effect of invocation versus skip.
Reference graph
Works this paper leans on
-
[1]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu and Zhiyuan Yao and Jinyang Wu and Chengcheng Han and Qi Gu and Xunliang Cai and Weiming Lu and Jun Xiao and Yueting Zhuang and Yongliang Shen , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.02268 , eprinttype =. 2604.02268 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.02268 2026
-
[2]
2026 , eprint=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Dynamic Dual-Granularity Skill Bank for Agentic RL , author=. 2026 , eprint=
2026
-
[4]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni and Yihao Liu and Xinpeng Liu and Yutao Sun and Mengyu Zhou and Pengyu Cheng and Dexin Wang and Erchao Zhao and Xiaoxi Jiang and Guanjun Jiang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.25158 , eprinttype =. 2603.25158 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.25158 2026
-
[5]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Agent skills for large language models: Architecture, acquisition, security, and the path forward , author=. arXiv preprint arXiv:2602.12430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2603.02176 , year=
Organizing, Orchestrating, and Benchmarking Agent Skills at Ecosystem Scale , author=. arXiv preprint arXiv:2603.02176 , year=
-
[7]
arXiv preprint arXiv:2509.23285 , year=
Yifei Chen and Guanting Dong and Zhicheng Dou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.23285 , eprinttype =. 2509.23285 , timestamp =
-
[8]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[9]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the ACM on Web Conference 2025 , pages=
Tool learning in the wild: Empowering language models as automatic tool agents , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[11]
arXiv preprint arXiv:2509.26490 , year=
Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications , author=. arXiv preprint arXiv:2509.26490 , year=
-
[12]
arXiv preprint arXiv:2508.04865 , year=
Agnostics: Learning to code in any programming language via reinforcement with a universal learning environment , author=. arXiv preprint arXiv:2508.04865 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Agent laboratory: Using llm agents as research assistants , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=. 2025 , publisher=
2025
-
[16]
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Yong. ExpeL:. Thirty-Eighth. 2024 , url =. doi:10.1609/AAAI.V38I17.29936 , timestamp =
-
[17]
Advances in neural information processing systems , volume=
Hindsight credit assignment , author=. Advances in neural information processing systems , volume=
-
[18]
arXiv preprint arXiv:2511.12159 , year=
Criticsearch: Fine-grained credit assignment for search agents via a retrospective critic , author=. arXiv preprint arXiv:2511.12159 , year=
-
[19]
Proceedings of the AAAI conference on artificial intelligence , volume=
The option-critic architecture , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[20]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[21]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[22]
arXiv preprint arXiv:2511.10395 , year=
Agentevolver: Towards efficient self-evolving agent system , author=. arXiv preprint arXiv:2511.10395 , year=
-
[23]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[24]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , booktitle =
Mohit Shridhar and Xingdi Yuan and Marc. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , booktitle =. 2021 , url =
2021
-
[25]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
SimpleMem: Efficient Lifelong Memory for LLM Agents
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[30]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Yanna Jiang and Delong Li and Haiyu Deng and Baihe Ma and Xu Wang and Qin Wang and Guangsheng Yu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.20867 , eprinttype =. 2602.20867 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.20867 2026
-
[31]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Chenxi Wang and Zhuoyun Yu and Xin Xie and Wuguannan Yao and Runnan Fang and Shuofei Qiao and Kexin Cao and Guozhou Zheng and Xiang Qi and Peng Zhang and Shumin Deng , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.04804 , eprinttype =. 2604.04804 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04804 2026
-
[32]
Yanzhao Zheng and ZhenTao Zhang and Chao Ma and YuanQiang Yu and JiHuai Zhu and Yong Wu and Tianze Xu and Baohua Dong and Hangcheng Zhu and Ruohui Huang and Gang Yu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.22455 , eprinttype =. 2603.22455 , timestamp =
-
[33]
arXiv preprint arXiv:2603.04448 , year=
Yuan Liang and Ruobin Zhong and Haoming Xu and Chen Jiang and Yi Zhong and Runnan Fang and Jia. SkillNet: Create, Evaluate, and Connect. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.04448 , eprinttype =. 2603.04448 , timestamp =
-
[34]
arXiv preprint arXiv:2601.21123 , year=
Cua-skill: Develop skills for computer using agent , author=. arXiv preprint arXiv:2601.21123 , year=
-
[35]
2026 , eprint=
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents , author=. 2026 , eprint=
2026
-
[36]
Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle =
Timo Schick and Jane Dwivedi. Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle =. 2023 , url =
2023
-
[37]
Patil and Tianjun Zhang and Xin Wang and Joseph E
Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , editor =. Gorilla: Large Language Model Connected with Massive APIs , booktitle =. 2024 , url =
2024
-
[38]
Shiqi Chen and Jingze Gai and Ruochen Zhou and Jinghan Zhang and Tongyao Zhu and Junlong Li and Kangrui Wang and Zihan Wang and Zhengyu Chen and Klara Kaleb and Ning Miao and Siyang Gao and Cong Lu and Manling Li and Junxian He and Yee Whye Teh , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.00718 , eprinttype =. 2603.00718 , timestamp =
-
[39]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Dawei Liu and Zongxia Li and Hongyang Du and Xiyang Wu and Shihang Gui and Yongbei Kuang and Lichao Sun , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.05333 , eprinttype =. 2604.05333 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05333 2026
-
[40]
Yutao Yang and Junsong Li and Qianjun Pan and Bihao Zhan and Yuxuan Cai and Lin Du and Jie Zhou and Kai Chen and Qin Chen and Xin Li and Bo Zhang and Liang He , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.01145 , eprinttype =. 2603.01145 , timestamp =
-
[41]
2026 , eprint=
SkillOS: Learning Skill Curation for Self-Evolving Agents , author=. 2026 , eprint=
2026
-
[42]
Skill Retrieval Augmentation for Agentic AI
Weihang Su and Jianming Long and Qingyao Ai and Yichen Tang and Changyue Wang and Yiteng Tu and Yiqun Liu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.24594 , eprinttype =. 2604.24594 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.24594 2026
-
[43]
arXiv preprint arXiv:2509.23285 , year=
Toward Effective Tool-Integrated Reasoning via Self-Evolved Preference Learning , author=. arXiv preprint arXiv:2509.23285 , year=
-
[44]
When2Call: When (not) to Call Tools , booktitle =
Hayley Ross and Ameya Sunil Mahabaleshwarkar and Yoshi Suhara , editor =. When2Call: When (not) to Call Tools , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.174 , timestamp =
-
[45]
Yi. Enhancing Function-Calling Capabilities in LLMs: Strategies for Prompt Formats, Data Integration, and Multilingual Translation , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-INDUSTRY.9 , timestamp =
-
[46]
Alignment for Efficient Tool Calling of Large Language Models , booktitle =
Hongshen Xu and Zihan Wang and Zichen Zhu and Lei Pan and Xingyu Chen and Shuai Fan and Lu Chen and Kai Yu , editor =. Alignment for Efficient Tool Calling of Large Language Models , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.898 , timestamp =
-
[47]
2025 , eprint=
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior , author=. 2025 , eprint=
2025
-
[48]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2212.03533 , eprinttype =. 2212.03533 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.03533 2022
-
[49]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[50]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
2023
-
[51]
2026 , eprint=
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[52]
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety. arXiv e-prints , keywords =. doi:10.48550/arXiv.2505.20065 , archivePrefix =. 2505.20065 , primaryClass =
-
[53]
Uni-DPO: A Unified Paradigm for Dynamic Preference Optimization of LLMs
Uni-DPO: A Unified Paradigm for Dynamic Preference Optimization of LLMs. arXiv e-prints , keywords =. doi:10.48550/arXiv.2506.10054 , archivePrefix =. 2506.10054 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.10054
-
[54]
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author=. arXiv preprint arXiv:2605.07358 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Agentic Reinforced Policy Optimization
Guanting Dong and Hangyu Mao and Kai Ma and Licheng Bao and Yifei Chen and Zhongyuan Wang and Zhongxia Chen and Jiazhen Du and Huiyang Wang and Fuzheng Zhang and Guorui Zhou and Yutao Zhu and Ji. Agentic Reinforced Policy Optimization , journal =. 2025 , url =. doi:10.48550/ARXIV.2507.19849 , eprinttype =. 2507.19849 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19849 2025
-
[56]
George Ling and Shanshan Zhong and Richard Huang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.08004 , eprinttype =. 2602.08004 , timestamp =
-
[57]
arXiv preprint arXiv:2504.06821 , year=
Zora Zhiruo Wang and Apurva Gandhi and Graham Neubig and Daniel Fried , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.06821 , eprinttype =. 2504.06821 , timestamp =
-
[58]
Agent Workflow Memory , booktitle =
Zora Zhiruo Wang and Jiayuan Mao and Daniel Fried and Graham Neubig , editor =. Agent Workflow Memory , booktitle =. 2025 , url =
2025
-
[59]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo and Weizhi Zhang and Ye Yuan and Yusheng Zhao and Junwei Yang and Yiyang Gu and Bohan Wu and Binqi Chen and Ziyue Qiao and Qingqing Long and Rongcheng Tu and Xiao Luo and Wei Ju and Zhiping Xiao and Yifan Wang and Meng Xiao and Chenwu Liu and Jingyang Yuan and Shichang Zhang and Yiqiao Jin and Fan Zhang and Xian Wu and Hanqing Zhao and Dacheng T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.21460 2025
-
[60]
Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng
Shishir G. Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng. The Berkeley Function Calling Leaderboard. Forty-second International Conference on Machine Learning,. 2025 , url =
2025
-
[61]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik Narasimhan , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2406.12045 , eprinttype =. 2406.12045 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045 2024
-
[62]
Alex Mallen and Akari Asai and Victor Zhong and Rajarshi Das and Daniel Khashabi and Hannaneh Hajishirzi , editor =. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.546 , timestamp =
-
[63]
Yuxuan Cai and Jie Zhou and Qin Chen and Liang He , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.20572 , eprinttype =. 2604.20572 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.20572 2026
-
[64]
2026 , eprint=
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.