SkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories
Pith reviewed 2026-06-28 17:13 UTC · model grok-4.3
The pith
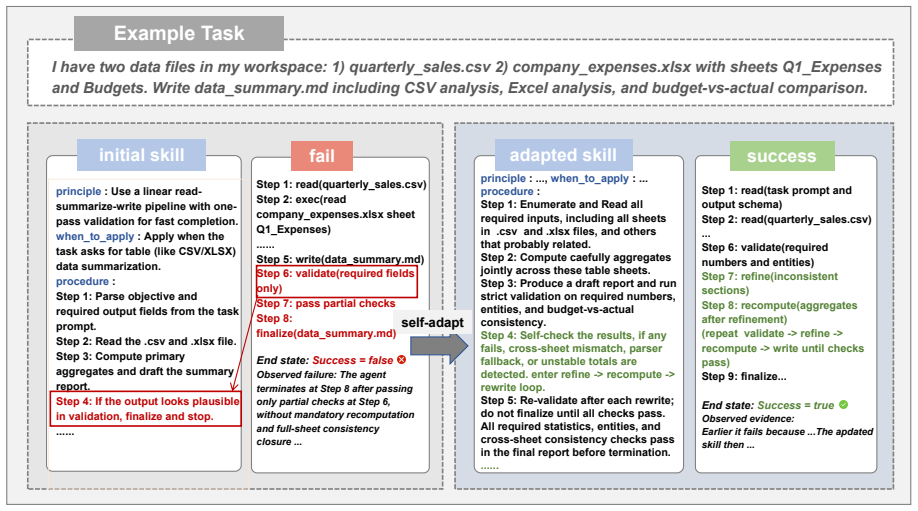
SkillAdaptor locates the first fault step in a trajectory to revise only the responsible skills in LLM agents while leaving the model frozen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
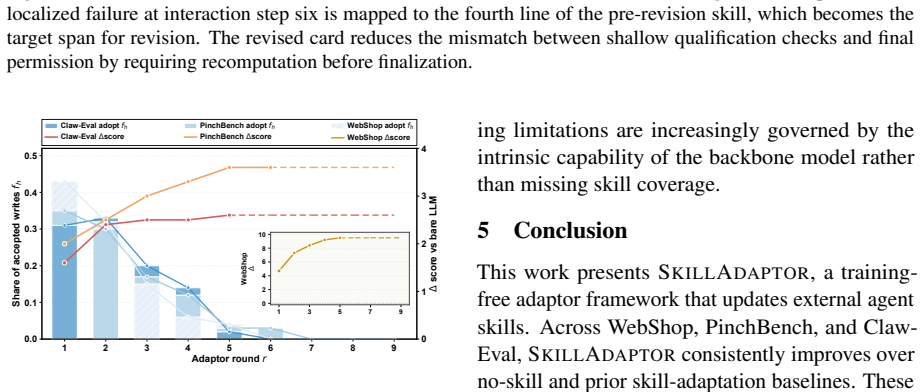
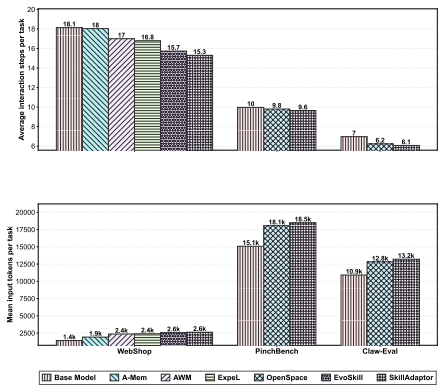
SkillAdaptor is a training-free step-level skill adaptation framework that, given a failed trajectory, identifies a first actionable fault step, links responsibility to candidate skills, and applies targeted updates under explicit acceptance checks while keeping the backbone frozen. When tested on WebShop, PinchBench, and Claw-Eval with several frontier LLMs, the method outperforms both no-skill baselines and prior skill-adaptation baselines.
What carries the argument
Step-level failure attribution that isolates the first actionable fault and assigns it to specific skills before any revision occurs.
Load-bearing premise
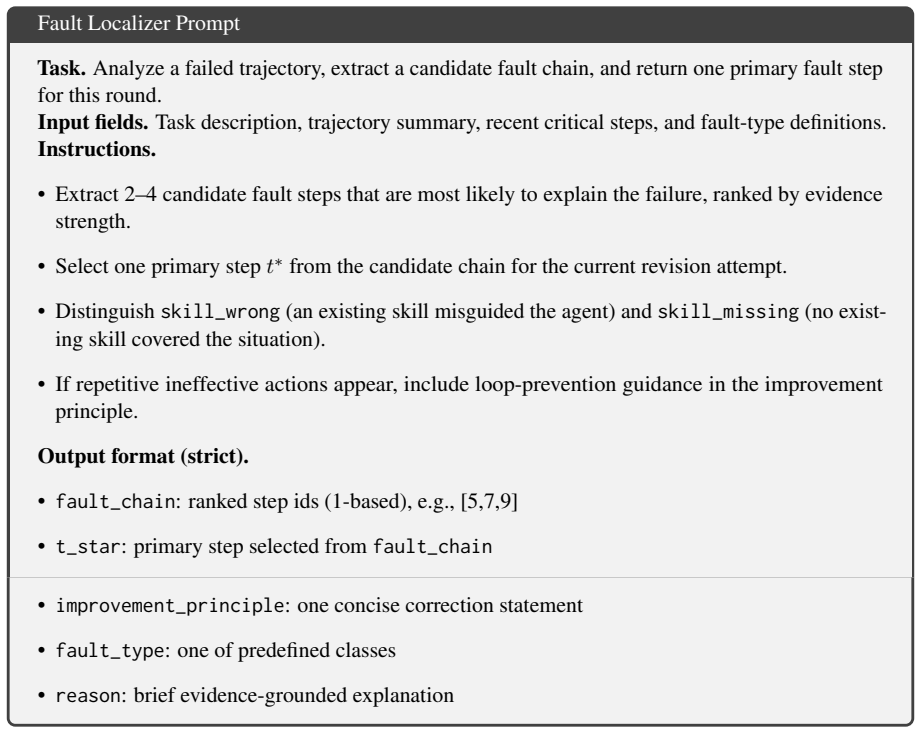
The method assumes that an accurate first actionable fault step can be identified from the trajectory and that responsibility can be correctly linked to specific skills without introducing new errors.
What would settle it
A set of trajectories on which the identified fault step is wrong, so that the resulting skill updates produce no gain or a drop in task success rate compared with the original skills.
Figures





read the original abstract
Large language model (LLM) agents increasingly rely on reusable external skills to solve long-horizon interactive tasks. Existing training-free skill adaptation pipelines usually update skills from full trajectories or session-level feedback, which makes failure attribution coarse and often produces unstable or overly broad revisions. We propose SkillAdaptor, a training-free step-level skill adaptation framework with explicit failure attribution, and it can plug into OpenClaw-class agent harnesses. Given a failed trajectory, SkillAdaptor identifies a first actionable fault step, links responsibility to candidate skills, and applies targeted updates under explicit acceptance checks while keeping the backbone frozen. We evaluate on WebShop, PinchBench, and Claw-Eval with Kimi-K2.5, GLM-5, and GPT-5.2. SkillAdaptor improves over no-skill and skill-adaptation baselines on all three suites, with the largest single-metric improvements of +1.5 points on PinchBench Avg Score%, +1.8 on Claw-Eval Avg Score, and +1.7 on WebShop success rate. These results indicate that step-level attribution supports more stable and auditable training-free skill maintenance\footnote{The code will be released at https://github.com/zjunlp/SkillAdaptor.}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillAdaptor, a training-free step-level skill adaptation framework for LLM agents. Given a failed trajectory, it identifies a first actionable fault step, links responsibility to candidate skills, applies targeted updates under explicit acceptance checks while keeping the backbone frozen, and plugs into OpenClaw-class harnesses. Evaluations on WebShop, PinchBench, and Claw-Eval with Kimi-K2.5, GLM-5, and GPT-5.2 report improvements over no-skill and skill-adaptation baselines, with largest gains of +1.5 on PinchBench Avg Score%, +1.8 on Claw-Eval Avg Score, and +1.7 on WebShop success rate. The work emphasizes more stable and auditable maintenance via step-level attribution.
Significance. If the attribution and update mechanisms prove reliable, the approach offers a practical way to maintain reusable external skills for long-horizon tasks without retraining or broad revisions, potentially improving auditability over session-level methods. The training-free design, explicit acceptance checks, and planned code release are notable strengths that support reproducibility and targeted adaptation claims.
major comments (2)
- [Abstract] Abstract: The mechanism for identifying the 'first actionable fault step' and linking responsibility to specific skills is described only at a high level with no prompt templates, heuristics, validation procedure, or acceptance criteria supplied. This is load-bearing for the central claim because the entire pipeline is training-free and relies on the same LLM class for attribution; errors here can introduce new failures rather than resolve them, directly affecting the stability and auditability assertions.
- [Abstract] Abstract and evaluation description: No error analysis, ablation on attribution accuracy, or controls for misattribution are reported despite the explicit claim that step-level attribution supports more stable adaptations. Without these, the reported metric gains (+1.5, +1.8, +1.7) cannot be confidently attributed to the proposed targeted updates versus baseline effects or lucky attribution.
minor comments (2)
- [Abstract] The footnote promises code release at a GitHub link; confirming this in the camera-ready version would strengthen reproducibility claims.
- [Abstract] Model names (Kimi-K2.5, GLM-5, GPT-5.2) appear non-standard; clarifying exact versions or checkpoints used would aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity and provide additional supporting analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The mechanism for identifying the 'first actionable fault step' and linking responsibility to specific skills is described only at a high level with no prompt templates, heuristics, validation procedure, or acceptance criteria supplied. This is load-bearing for the central claim because the entire pipeline is training-free and relies on the same LLM class for attribution; errors here can introduce new failures rather than resolve them, directly affecting the stability and auditability assertions.
Authors: We agree that the abstract presents the attribution mechanism at a high level, as is typical for abstracts. The detailed procedure—including the exact prompt template for identifying the first actionable fault step, the heuristics for linking responsibility to candidate skills, the validation steps, and the explicit acceptance criteria—is fully specified in Section 3.2 of the main text, with complete prompt templates and pseudocode in Appendix B. To directly address the concern, we will revise the abstract to include a concise sentence summarizing these components and their role in the training-free pipeline. This will make the load-bearing elements more visible while preserving the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No error analysis, ablation on attribution accuracy, or controls for misattribution are reported despite the explicit claim that step-level attribution supports more stable adaptations. Without these, the reported metric gains (+1.5, +1.8, +1.7) cannot be confidently attributed to the proposed targeted updates versus baseline effects or lucky attribution.
Authors: We acknowledge that the current evaluation lacks explicit error analysis or ablations on attribution accuracy, which would strengthen the stability claims. In the revised manuscript we will add a new subsection (likely in Section 4.3) containing: (i) a qualitative error analysis of attribution failures across the three benchmarks, (ii) an ablation that measures end-to-end performance when using oracle versus predicted attribution, and (iii) controls that quantify the effect of misattribution on final metrics. These additions will allow readers to assess how much of the reported gains (+1.5, +1.8, +1.7) can be attributed to the targeted step-level updates versus other factors. revision: yes
Circularity Check
No circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper presents SkillAdaptor as a training-free framework that identifies fault steps and updates skills via LLM-based attribution, evaluated empirically on WebShop, PinchBench, and Claw-Eval. No equations, parameters fitted to subsets, or derivations appear in the provided text. Claims rest on benchmark performance numbers rather than quantities defined from the method itself. The load-bearing assumption about accurate fault identification is an external modeling choice, not a self-definition or self-citation chain that reduces the result to its inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[2]
OpenClaw: Personal
Steinberger, Peter , howpublished=. OpenClaw: Personal
-
[3]
PinchBench: Real-World Benchmarks for
-
[4]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents , author=
-
[5]
A-Mem: Agentic Memory for
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , booktitle=. A-Mem: Agentic Memory for. 2025 , url=
2025
-
[6]
Proceedings of the 42nd International Conference on Machine Learning , series=
Agent Workflow Memory , author=. Proceedings of the 42nd International Conference on Machine Learning , series=. 2025 , url=
2025
-
[7]
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , booktitle=. ExpeL:. 2024 , url=
2024
-
[11]
2026 , eprint=
Yang, Yifan and Gong, Ziyang and Huang, Weiquan and Yang, Qihao and Zhou, Ziwei and Huang, Zisu and Li, Yan and Gao, Xuemei and Dai, Qi and Liu, Bei and Qiu, Kai and Yang, Yuqing and Chen, Dongdong and Yang, Xue and Luo, Chong , journal=. 2026 , eprint=
2026
-
[13]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[16]
How Well Do Agentic Skills Work in the Wild: Benchmarking
Liu, Yujian and Ji, Jiabao and An, Li and Jaakkola, Tommi and Zhang, Yang and Chang, Shiyu , journal=. How Well Do Agentic Skills Work in the Wild: Benchmarking. 2026 , url=
2026
-
[18]
arXiv preprint arXiv:2504.06188 , year=
SkillFlow: Scalable and Efficient Agent Skill Retrieval System , author=. arXiv preprint arXiv:2504.06188 , year=
-
[20]
Ouyang, Siru and Yan, Jun and Chen, Yanfei and Han, Rujun and Wang, Zifeng and Dalvi Mishra, Bhavana and Meng, Rui and Li, Chun-Liang and Jiao, Yizhu and Zha, Kaiwen and Shen, Maohao and Tirumalashetty, Vishy and Lee, George and Han, Jiawei and Pfister, Tomas and Lee, Chen-Yu , journal=. Skill. 2026 , url=
2026
-
[21]
Wang, Chenxi and Yu, Zhuoyun and Xie, Xin and Yao, Wuguannan and Fang, Runnan and Qiao, Shuofei and Cao, Kexin and Zheng, Guozhou and Qi, Xiang and Zhang, Peng and Deng, Shumin , journal=. Skill. 2026 , url=
2026
-
[22]
arXiv preprint arXiv:2603.04448 , year=
SkillNet: Create, Evaluate, and Connect AI Skills , author=. arXiv preprint arXiv:2603.04448 , year=
-
[23]
2026 , note=
Designing, Refining, and Maintaining Agent Skills at. 2026 , note=
2026
-
[24]
and Cai, Carrie J
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , series =. 2023 , publisher =
2023
-
[25]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[27]
Advances in Neural Information Processing Systems , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. Advances in Neural Information Processing Systems , year=
-
[28]
The Twelfth International Conference on Learning Representations , year=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , booktitle=. SWE-bench: Can Language Models Resolve Real-World. 2024 , url=
2024
-
[30]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[31]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle=. ToolLLM: Facilitating Large Language Models to...
2024
-
[32]
API-Bank: A Comprehensive Benchmark for Tool-Augmented
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , booktitle=. API-Bank: A Comprehensive Benchmark for Tool-Augmented. 2023 , address=
2023
-
[33]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal=. MemGPT: Towards. 2024 , url=
2024
-
[35]
2026 , url=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , url=
2026
-
[36]
2026 , url=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , url=
2026
-
[40]
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. 2026. https://arxiv.org/abs/2603.02766 Evoskill: Automated skill discovery for multi-agent systems . arXiv preprint arXiv:2603.02766
Pith/arXiv arXiv 2026
-
[41]
HKUDS . 2026. Openspace. https://github.com/HKUDS/OpenSpace. Repository-only baseline (no archival paper at the time of writing)
2026
-
[42]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J \"u rgen Schmidhuber. 2024. https://arxiv.org/abs/2308.00352 Metagpt: Meta programming for a multi-agent collaborative framework . In The Twelfth International C...
Pith/arXiv arXiv 2024
-
[43]
Zisu Huang, Jingwen Xu, Yifan Yang, Ziyang Gong, Qihao Yang, Muzhao Tian, Xiaohua Wang, Changze Lv, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Xue Yang, Dongdong Chen, Xiaoqing Zheng, and Chong Luo. 2026. https://arxiv.org/abs/2605.23899 From raw experience to skill consumption: A systematic study of model-generated agent skills . arXiv preprint arXiv:2605.23899
Pith/arXiv arXiv 2026
-
[44]
Yeonsung Jung, Trilok Padhi, Sina Shaham, Dipika Khullar, Joonhyun Jeong, Ninareh Mehrabi, and Eunho Yang. 2025. https://arxiv.org/abs/2511.22254 Co-evolving agents: Learning from failures as hard negatives . arXiv preprint arXiv:2511.22254
arXiv 2025
-
[45]
Kilo Code . 2026. Pinchbench: Real-world benchmarks for OpenClaw agents. https://github.com/pinchbench/skill. Benchmark skill repository, task definitions, and scoring scripts; leaderboard at https://pinchbench.com/
2026
-
[46]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
Pith/arXiv arXiv 2026
-
[47]
Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Zhiheng Xi, Xuanjing Huang, Hang Yan, Zhenhua Han, Tao Gui, and Yu-Gang Jiang. 2026. https://arxiv.org/abs/2604.25850 Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses . arXiv preprint arXiv:2604.25850
Pith/arXiv arXiv 2026
-
[48]
Hongyi Liu, Haoyan Yang, Tao Jiang, Bo Tang, Feiyu Xiong, and Zhiyu Li. 2026 a . https://arxiv.org/abs/2605.18401 Skillsvote: Lifecycle governance of agent skills from collection, recommendation to evolution . arXiv preprint arXiv:2605.18401
Pith/arXiv arXiv 2026
-
[49]
Xingyan Liu, Xiyue Luo, Linyu Li, Ganghong Huang, Jianfeng Liu, and Honglin Qiao. 2026 b . https://doi.org/10.1145/3805712.3808466 Skillforge: Forging domain-specific, self-evolving agent skills in cloud technical support . arXiv preprint arXiv:2604.08618
-
[50]
Yujian Liu, Jiabao Ji, Li An, Tommi Jaakkola, Yang Zhang, and Shiyu Chang. 2026 c . https://arxiv.org/abs/2604.04323 How well do agentic skills work in the wild: Benchmarking LLM skill usage in realistic settings . arXiv preprint arXiv:2604.04323
Pith/arXiv arXiv 2026
-
[51]
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. 2026. https://arxiv.org/abs/2604.08377 Skillclaw: Let skills evolve collectively with agentic evolver . arXiv preprint arXiv:2604.08377
Pith/arXiv arXiv 2026
-
[52]
Siru Ouyang, Jun Yan, Yanfei Chen, Rujun Han, Zifeng Wang, Bhavana Dalvi Mishra, Rui Meng, Chun-Liang Li, Yizhu Jiao, Kaiwen Zha, Maohao Shen, Vishy Tirumalashetty, George Lee, Jiawei Han, Tomas Pfister, and Chen-Yu Lee. 2026. https://arxiv.org/abs/2605.06614 Skill OS : Learning skill curation for self-evolving agents . arXiv preprint arXiv:2605.06614
Pith/arXiv arXiv 2026
-
[53]
In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. https://doi.org/10.1145/3586183.3606763 Generative agents: Interactive simulacra of human behavior . In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST '23. Association for Computing Machinery
-
[54]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. https://arxiv.org/abs/2305.15334 Gorilla: Large language model connected with massive apis . In Advances in Neural Information Processing Systems
Pith/arXiv arXiv 2024
-
[55]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. https://arxiv.org/abs/2302.04761 Toolformer: Language models can teach themselves to use tools . In Advances in Neural Information Processing Systems, volume 36
Pith/arXiv arXiv 2023
-
[56]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://arxiv.org/abs/2303.11366 Reflexion: Language agents with verbal reinforcement learning . In Advances in Neural Information Processing Systems, volume 36
Pith/arXiv arXiv 2023
-
[57]
Shuzheng Si, Haozhe Zhao, Yu Lei, Qingyi Wang, Dingwei Chen, Zhitong Wang, Zhenhailong Wang, Kangyang Luo, Zheng Wang, Gang Chen, Fanchao Qi, Minjia Zhang, and Maosong Sun. 2026. https://arxiv.org/abs/2604.27660 From context to skills: Can language models learn from context skillfully? arXiv preprint arXiv:2604.27660
Pith/arXiv arXiv 2026
-
[58]
Peter Steinberger. 2026. Openclaw: Personal AI assistant. https://github.com/openclaw/openclaw
2026
-
[59]
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, and Shumin Deng. 2026. https://arxiv.org/abs/2604.04804 Skill X : Automatically constructing skill knowledge bases for agents . arXiv preprint arXiv:2604.04804
Pith/arXiv arXiv 2026
-
[60]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. https://arxiv.org/abs/2305.16291 Voyager: An open-ended embodied agent with large language models . arXiv preprint arXiv:2305.16291
Pith/arXiv arXiv 2023
-
[61]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. 2025. https://arxiv.org/abs/2409.07429 Agent workflow memory . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 63897--63911
Pith/arXiv arXiv 2025
-
[62]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. https://arxiv.org/abs/2502.12110 A-mem: Agentic memory for LLM agents . In Advances in Neural Information Processing Systems
Pith/arXiv arXiv 2025
-
[63]
Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Yuqing Yang, Dongdong Chen, Xue Yang, and Chong Luo. 2026. https://arxiv.org/abs/2605.23904 SkillOpt : Executive strategy for self-evolving agent skills . arXiv preprint arXiv:2605.23904
Pith/arXiv arXiv 2026
-
[64]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. https://arxiv.org/abs/2207.01206 Webshop: Towards scalable real-world web interaction with grounded language agents . In Advances in Neural Information Processing Systems, volume 35
arXiv 2022
-
[65]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. https://arxiv.org/abs/2210.03629 React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Representations
Pith/arXiv arXiv 2023
-
[66]
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, Qi Liu, Zhifang Sui, and Tong Yang. 2026. https://arxiv.org/abs/2604.06132 Claw-eval: Towards trustworthy evaluation of autonomous agents . arXiv preprint arXiv:2604.06132
Pith/arXiv arXiv 2026
-
[67]
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, Xue Liu, Xiaoxiao Li, and Philip S. Yu. 2026 a . https://arxiv.org/abs/2604.01687 Coevoskills: Self-evolving agent skills via co-evolutionary verification . arXiv preprint arXiv:2604.01687
Pith/arXiv arXiv 2026
-
[68]
Xing Zhang, Yanwei Cui, Guanghui Wang, Ziyuan Li, Wei Qiu, Bing Zhu, and Peiyang He. 2026 b . https://arxiv.org/abs/2605.19576 Library drift: Diagnosing and fixing a silent failure mode in self-evolving LLM skill libraries . Preprint, arXiv:2605.19576
Pith/arXiv arXiv 2026
-
[69]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. https://doi.org/10.1609/aaai.v38i17.29936 Expel: LLM agents are experiential learners . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632--19642
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.