Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
Pith reviewed 2026-06-28 15:12 UTC · model grok-4.3
The pith
On-policy distillation improves when low-quality trajectories are filtered first and informative tokens are then softly reweighted inside them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
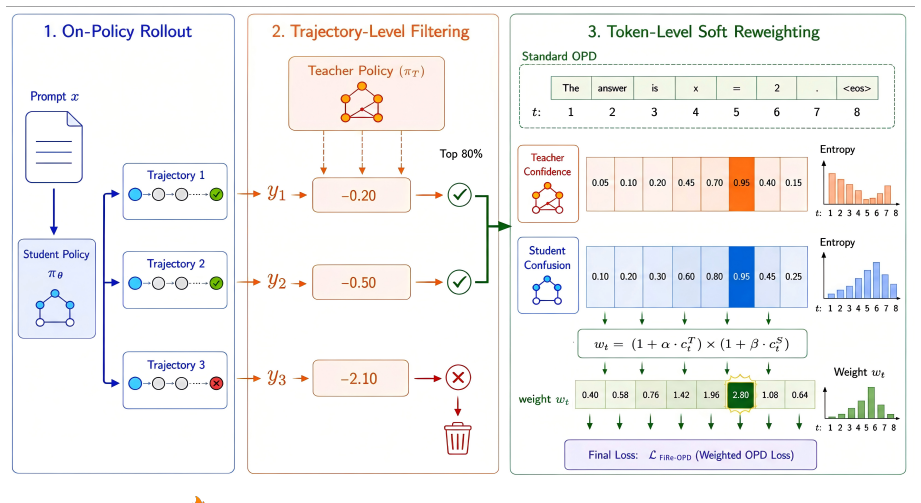
FiRe-OPD first filters trajectories to remove low-quality rollout samples, and then applies soft reweighting within the retained trajectories to emphasize informative tokens. Compared with hard token selection, FiRe-OPD leverages a soft-weighting mechanism to effectively mitigate information loss and enhance optimization stability, thereby achieving finer-grained OPD optimization. The method is validated across strong-to-weak, single-teacher, and multi-teacher settings and outperforms recent token-level OPD baselines.
What carries the argument
FiRe-OPD, the two-stage procedure that performs trajectory-level filtering followed by token-level soft reweighting.
If this is right
- Produces measurable gains over prior token-level OPD methods in strong-to-weak distillation (+6.25 on AIME 2024).
- Delivers larger gains in multi-teacher settings (+18.81 on Miner).
- Maintains effectiveness in both single-teacher and multi-teacher configurations.
- Uses soft rather than hard weighting to reduce information loss while keeping optimization stable.
Where Pith is reading between the lines
- The filter-then-reweight pattern could be tested in other on-policy methods such as preference optimization to see whether the same granularity split helps.
- Focusing supervision on fewer but higher-quality trajectories may lower the total number of rollouts needed, reducing sampling cost.
- The soft-weighting step might be replaced by a learned weighting network that adapts the emphasis per task.
- Applying the same stages to non-reasoning domains would test whether the reported gains depend on the math-heavy benchmarks used.
Load-bearing premise
The chosen filtering criterion and soft-weighting function preserve the most useful supervision signal without introducing systematic bias or instability that would not appear in the reported benchmarks.
What would settle it
If removing the filtering step or switching to hard token weights produces equal or higher accuracy on the same benchmarks with no increase in variance, the claim that the two-stage process yields finer-grained and more stable optimization would be falsified.
Figures


read the original abstract
On-Policy distillation (OPD) in large language models is shifting from full-trace KL supervision toward more selective training paradigms. Recent OPD methods increasingly focus on selecting which trajectories to learn from, which tokens are most informative, and which supervision signals are most reliable. Motivated by this trend, we rethink optimization granularity of OPD and propose \fireicon\ FiRe-OPD (Filter, then Reweight), which jointly adjusts supervision signals at both trajectory and token levels. In details, FiRe-OPD first filters trajectories to remove low-quality rollout samples, and then applies soft reweighting within the retained trajectories to emphasize informative tokens. Compared with hard token selection, FiRe-OPD leverages a soft-weighting mechanism to effectively mitigate information loss and enhance optimization stability, thereby achieving finer-grained OPD optimization. We validate the effectiveness of FiRe-OPD across strong-to-weak, single-teacher, and multi-teacher settings, and demonstrate its superiority over recent token-level OPD methods ( (e.g., +6.25 on AIME 2024 in strong-to-weak, +18.81 on Miner in multi-teacher). Our code is available at https://github.com/YuYingLi0/FiRe-OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FiRe-OPD for on-policy distillation (OPD) in LLMs: it first filters trajectories to discard low-quality rollout samples, then applies soft reweighting inside the retained trajectories to emphasize informative tokens. The central claim is that this two-stage procedure yields finer-grained, more stable optimization than hard token selection, with reported gains of +6.25 on AIME 2024 (strong-to-weak) and +18.81 on Miner (multi-teacher) across single-teacher, strong-to-weak, and multi-teacher settings. Code is released at the cited GitHub repository.
Significance. If the empirical superiority holds under controlled conditions, the method supplies a practical, multi-granularity alternative to existing hard-selection OPD techniques and could influence how future work balances information retention against optimization stability. The public code release is a clear strength for reproducibility.
major comments (3)
- [Abstract / Results] Abstract and results: the reported numerical gains (+6.25 AIME, +18.81 Miner) are presented without standard deviations, number of runs, or statistical significance tests; this makes it impossible to determine whether the claimed superiority over prior token-level OPD methods is robust or could be explained by experimental variance.
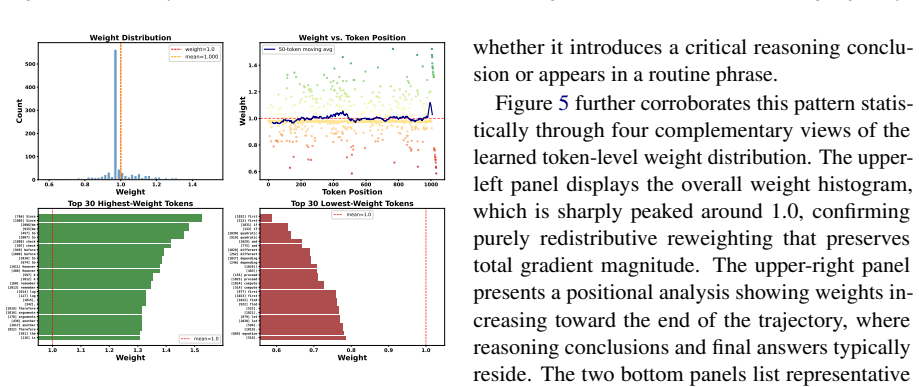
- [Method] Method description: the filtering criterion used to remove low-quality trajectories and the precise form of the soft-weighting function are not specified with equations or pseudocode; without these definitions it is unclear whether the procedure is parameter-free or introduces new hyperparameters that could affect the reported gains.
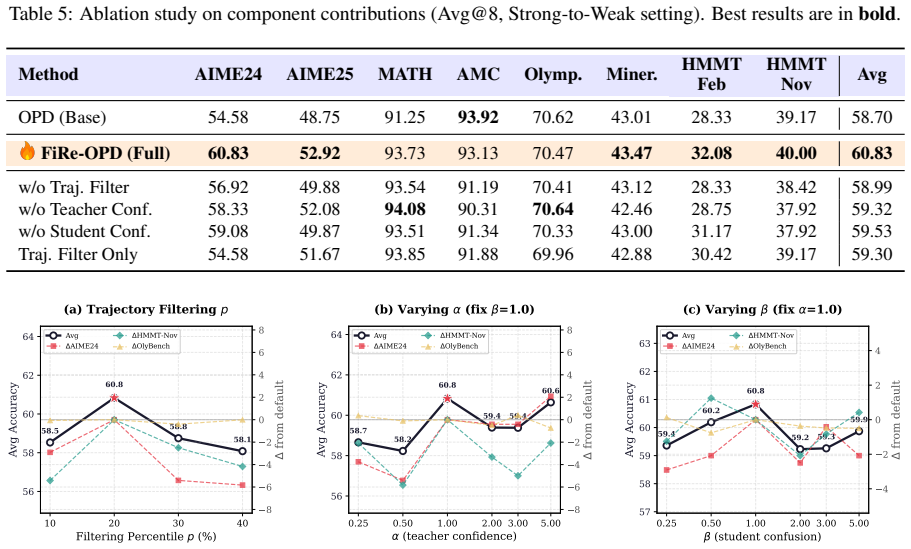
- [Experiments] Experiments: no ablation tables isolate the contribution of trajectory filtering versus token-level soft reweighting, nor compare against a pure hard-selection baseline under identical rollout conditions; such controls are load-bearing for the claim that the two-stage soft approach is superior to hard token selection.
minor comments (1)
- [Abstract] The abstract states the method is validated 'across strong-to-weak, single-teacher, and multi-teacher settings' but does not list the concrete model pairs or datasets used in each case.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each of the major comments point-by-point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the reported numerical gains (+6.25 AIME, +18.81 Miner) are presented without standard deviations, number of runs, or statistical significance tests; this makes it impossible to determine whether the claimed superiority over prior token-level OPD methods is robust or could be explained by experimental variance.
Authors: We agree that the absence of standard deviations, run counts, and significance tests limits the ability to assess robustness. In the revised version, we will rerun the experiments with multiple seeds, report means and standard deviations, and include statistical significance tests comparing against baselines. revision: yes
-
Referee: [Method] Method description: the filtering criterion used to remove low-quality trajectories and the precise form of the soft-weighting function are not specified with equations or pseudocode; without these definitions it is unclear whether the procedure is parameter-free or introduces new hyperparameters that could affect the reported gains.
Authors: We acknowledge that formalizing the filtering criterion and soft-weighting function with equations and pseudocode would improve clarity. The revised manuscript will include explicit mathematical definitions and an algorithm box detailing the two-stage procedure, including any hyperparameters. revision: yes
-
Referee: [Experiments] Experiments: no ablation tables isolate the contribution of trajectory filtering versus token-level soft reweighting, nor compare against a pure hard-selection baseline under identical rollout conditions; such controls are load-bearing for the claim that the two-stage soft approach is superior to hard token selection.
Authors: We agree that dedicated ablations are necessary to substantiate the claims. We will add ablation experiments in the revised paper that isolate the effects of filtering and reweighting, and directly compare the soft reweighting approach to hard token selection under matched rollout conditions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents FiRe-OPD as an empirical two-stage procedure (trajectory filtering then soft token reweighting) whose effectiveness is measured on external benchmarks such as AIME 2024 and Miner. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or description that would reduce the claimed gains to a construction from the method's own inputs. The central claim remains an independent empirical proposal rather than a tautological re-expression of its assumptions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Blockwise Policy-Drift Gating for On-Policy Distillation
Blockwise policy-drift gating raises mean pass@8 from 0.4978 to 0.5160 on four math benchmarks by reweighting OPD losses with detached mean-normalized gates from student policy drift over 64-token blocks.
-
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
A survey creates a taxonomy for on-policy distillation in LLMs that separates temporal credit assignment from vocabulary-level probability routing.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[2]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Sequence-level knowledge distillation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[3]
International Conference on Learning Representations , volume=
Minillm: Knowledge distillation of large language models , author=. International Conference on Learning Representations , volume=
-
[4]
International Conference on Machine Learning , pages=
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[5]
Forty-second International Conference on Machine Learning , year=
DA-KD: difficulty-aware knowledge distillation for efficient large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Ddk: Distilling domain knowledge for efficient large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[8]
arXiv preprint arXiv:2603.24596 , year=
X-opd: Cross-modal on-policy distillation for capability alignment in speech llms , author=. arXiv preprint arXiv:2603.24596 , year=
-
[9]
arXiv preprint arXiv:2605.08063 , year=
Flow-OPD: On-Policy Distillation for Flow Matching Models , author=. arXiv preprint arXiv:2605.08063 , year=
-
[10]
arXiv preprint arXiv:2602.15260 , year=
Fast and effective on-policy distillation from reasoning prefixes , author=. arXiv preprint arXiv:2602.15260 , year=
-
[11]
arXiv preprint arXiv:2603.11178 , year=
PACED: Distillation and on-policy self-distillation at the frontier of student competence , author=. arXiv preprint arXiv:2603.11178 , year=
-
[12]
arXiv preprint arXiv:2604.08527 , year=
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models , author=. arXiv preprint arXiv:2604.08527 , year=
-
[13]
arXiv preprint arXiv:2605.03677 , year=
Uni-OPD: Unifying on-policy distillation with a dual-perspective recipe , author=. arXiv preprint arXiv:2605.03677 , year=
-
[14]
arXiv preprint arXiv:2603.11137 , year=
Scaling reasoning efficiently via relaxed on-policy distillation , author=. arXiv preprint arXiv:2603.11137 , year=
-
[15]
arXiv preprint arXiv:2603.07079 , year=
Entropy-Aware On-Policy Distillation of Language Models , author=. arXiv preprint arXiv:2603.07079 , year=
-
[16]
arXiv preprint arXiv:2604.14084 , year=
Tip: Token importance in on-policy distillation , author=. arXiv preprint arXiv:2604.14084 , year=
-
[17]
arXiv preprint arXiv:2604.10688 , year=
Scope: Signal-calibrated on-policy distillation enhancement with dual-path adaptive weighting , author=. arXiv preprint arXiv:2604.10688 , year=
-
[18]
arXiv preprint arXiv:2604.13016 , year=
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe , author=. arXiv preprint arXiv:2604.13016 , year=
-
[19]
arXiv preprint arXiv:2602.12125 , year=
Learning beyond teacher: Generalized on-policy distillation with reward extrapolation , author=. arXiv preprint arXiv:2602.12125 , year=
-
[20]
arXiv preprint arXiv:2604.00626 , year=
A survey of on-policy distillation for large language models , author=. arXiv preprint arXiv:2604.00626 , year=
-
[21]
arXiv preprint arXiv:2603.25562 , year=
Revisiting on-policy distillation: Empirical failure modes and simple fixes , author=. arXiv preprint arXiv:2603.25562 , year=
-
[22]
arXiv preprint arXiv:2504.11456 , year=
Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning , author=. arXiv preprint arXiv:2504.11456 , year=
-
[23]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[24]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[27]
URL https://matharena
Matharena: Evaluating llms on uncontaminated math competitions, February 2025 , author=. URL https://matharena. ai , volume=
2025
-
[28]
Advances in neural information processing systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in neural information processing systems , volume=
-
[29]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[30]
arXiv preprint arXiv:2604.13010 , year=
Lightning opd: Efficient post-training for large reasoning models with offline on-policy distillation , author=. arXiv preprint arXiv:2604.13010 , year=
-
[31]
arXiv preprint arXiv:2601.07155 , year=
Stable On-Policy Distillation through Adaptive Target Reformulation , author=. arXiv preprint arXiv:2601.07155 , year=
-
[32]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[33]
arXiv preprint arXiv:2604.10674 , year=
Skill-Conditioned Self-Distillation for Multi-turn LLM Agents , author=. arXiv preprint arXiv:2604.10674 , year=
-
[34]
arXiv preprint arXiv:2603.24472 , year=
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. arXiv preprint arXiv:2603.24472 , year=
-
[35]
arXiv preprint arXiv:2604.17535 , year=
Opsdl: On-policy self-distillation for long-context language models , author=. arXiv preprint arXiv:2604.17535 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Learning to reason under off-policy guidance , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2601.20802 , year=
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
-
[38]
arXiv preprint arXiv:2602.22495 , year=
Reinforcement-aware knowledge distillation for LLM reasoning , author=. arXiv preprint arXiv:2602.22495 , year=
-
[39]
arXiv preprint arXiv:2603.23871 , year=
Hdpo: Hybrid distillation policy optimization via privileged self-distillation , author=. arXiv preprint arXiv:2603.23871 , year=
-
[40]
arXiv preprint arXiv:2604.03128 , year=
Self-distilled rlvr , author=. arXiv preprint arXiv:2604.03128 , year=
-
[41]
arXiv preprint arXiv:2602.02994 , year=
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation , author=. arXiv preprint arXiv:2602.02994 , year=
-
[42]
arXiv preprint arXiv:2602.12222 , year=
Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training , author=. arXiv preprint arXiv:2602.12222 , year=
-
[43]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Self-distillation bridges distribution gap in language model fine-tuning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
arXiv preprint arXiv:2510.14974 , year=
pi-flow: Policy-based few-step generation via imitation distillation , author=. arXiv preprint arXiv:2510.14974 , year=
-
[45]
arXiv preprint arXiv:2510.23497 , year=
VOLD: Reasoning Transfer from LLMs to Vision-Language Models via On-Policy Distillation , author=. arXiv preprint arXiv:2510.23497 , year=
-
[46]
arXiv preprint arXiv:2603.26666 , year=
VLA-OPD: Bridging Offline SFT and Online RL for Vision-Language-Action Models via On-Policy Distillation , author=. arXiv preprint arXiv:2603.26666 , year=
-
[47]
arXiv preprint arXiv:2604.24005 , year=
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents , author=. arXiv preprint arXiv:2604.24005 , year=
-
[48]
arXiv preprint arXiv:2604.20244 , year=
Hybrid Policy Distillation for LLMs , author=. arXiv preprint arXiv:2604.20244 , year=
-
[49]
arXiv preprint arXiv:2602.12275 , year=
On-policy context distillation for language models , author=. arXiv preprint arXiv:2602.12275 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.