Unsupervised Skill Discovery for Agentic Data Analysis
Pith reviewed 2026-06-28 01:10 UTC · model grok-4.3
The pith
DataCOPE discovers reusable data-analysis skills from unlabeled trajectories by extracting verifier signals that indicate relative quality or agreement, then distilling them contrastively to improve agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
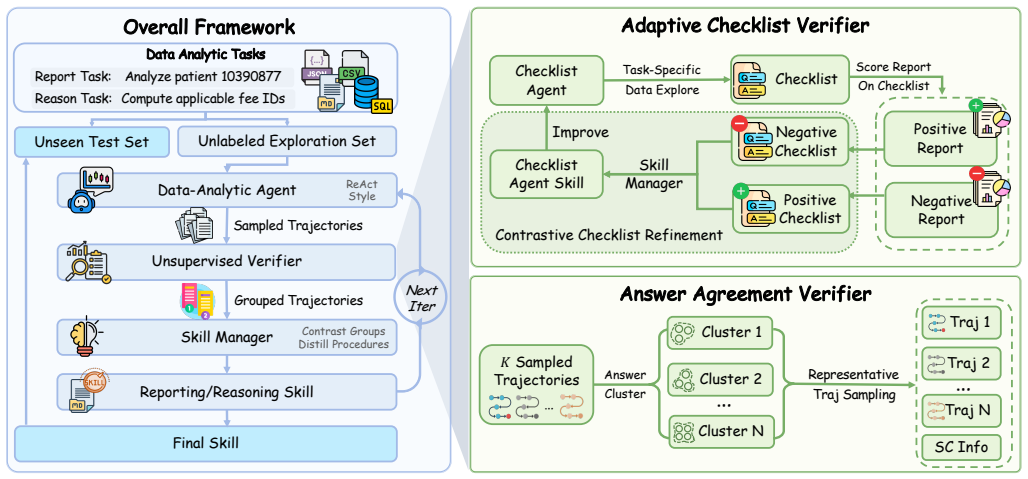
DataCOPE derives verifier signals from the exploration trajectories and uses them to characterize relative quality or agreement among trajectories. It iteratively coordinates a Data-Analytic Agent for trajectory generation, an Unsupervised Verifier for signal extraction, and a Skill Manager for contrastive skill distillation. For report-style analysis the verifier is instantiated as an Adaptive Checklist Verifier that derives task-specific criteria, scores reports by verifiable coverage, and iteratively refines the checklist. For reasoning-style analysis it is instantiated as an Answer Agreement Verifier that groups trajectories by answer agreement and uses self-consistency as an auxiliary s
What carries the argument
The unsupervised verifier (Adaptive Checklist Verifier or Answer Agreement Verifier) that extracts relative-quality or agreement signals from unlabeled trajectories to drive contrastive skill distillation.
If this is right
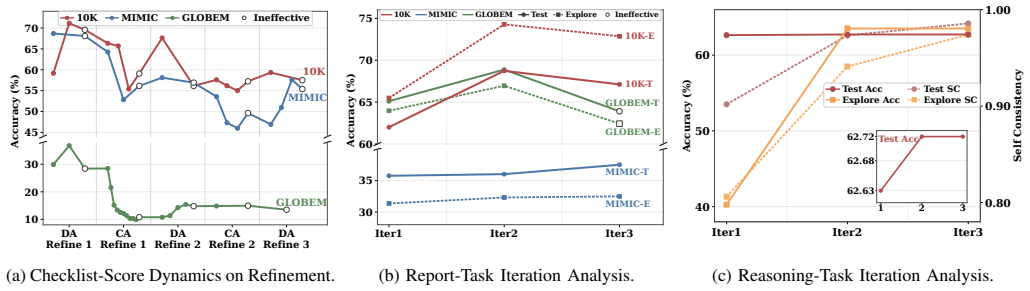
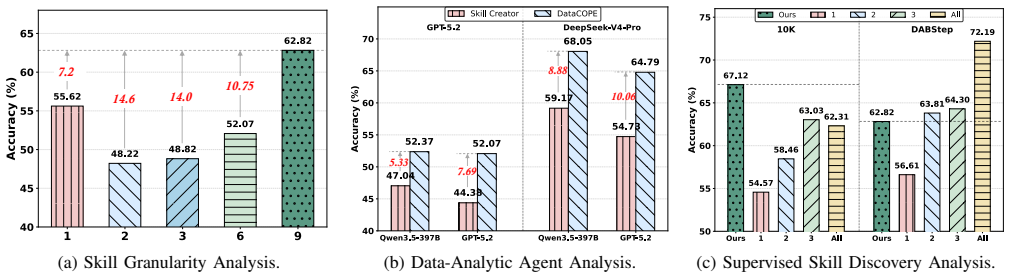
- Averaged across four model settings, DataCOPE raises mean score by 9.71 percent on report-style tasks.
- Averaged across four model settings, DataCOPE raises mean score by 32.30 percent on reasoning-style tasks.
- The same iterative loop of agent, verifier, and skill manager improves held-out performance over baselines in both analysis formats.
- Skills are acquired without updating model parameters, remaining usable at inference time.
Where Pith is reading between the lines
- The same signal-extraction loop could be applied to other agent domains that produce long, variable-quality trajectories.
- If the verifiers prove reliable, the approach could lower the cost of curating training data for agentic systems.
- Discovered skills might transfer across datasets that share similar analytical structure even if surface features differ.
Load-bearing premise
Signals extracted by the unsupervised verifier from exploration trajectories reliably indicate relative quality or agreement without any external supervision or task-specific labels.
What would settle it
A controlled run in which skills distilled using the verifier signals produce no improvement or a performance drop on held-out tasks compared with the base agent.
Figures

read the original abstract
Inference-time skill augmentation provides a lightweight way to improve data-analytic agents by injecting reusable procedural knowledge without updating model parameters. However, discovering effective skills for data analysis remains challenging, as reliable supervision is expensive and success criteria vary across analytical formats. This raises the key question of how to discover reusable data-analysis skills from unlabeled exploration alone. We propose DataCOPE, an unsupervised verifier-guided skill discovery framework for data-analytic agents. DataCOPE derives verifier signals from the exploration trajectories and uses them to characterize relative quality or aggreement among trajectories. It iteratively coordinates a Data-Analytic Agent for trajectory generation, an Unsupervised Verifier for signal extraction, and a Skill Manager for contrastive skill distillation. For report-style analysis, we instantiate the verifier as an Adaptive Checklist Verifier that derives task-specific criteria, scores reports by verifiable coverage, and iteratively refines the checklist. For reasoning-style analysis, we instantiate it as an Answer Agreement Verifier that groups trajectories by answer agreement and uses self-consistency as an auxiliary signal. We evaluate DataCOPE on report-style analysis from Deep Data Research and reasoning-style analysis from DABStep. Across both settings, DataCOPE consistently improves held-out performance over baselines. Averaged across four model settings, DataCOPE improves the mean score by 9.71% and 32.30% on report-style and reasoning-style tasks respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DataCOPE, an unsupervised verifier-guided framework for skill discovery in data-analytic agents. It coordinates a Data-Analytic Agent to generate exploration trajectories, an Unsupervised Verifier (instantiated as Adaptive Checklist Verifier for report-style tasks or Answer Agreement Verifier for reasoning-style tasks) to extract relative quality or agreement signals, and a Skill Manager for contrastive skill distillation. The central empirical claim is that DataCOPE yields average held-out performance gains of 9.71% on report-style tasks (Deep Data Research) and 32.30% on reasoning-style tasks (DABStep) across four model settings, outperforming baselines.
Significance. If the verifier-derived signals reliably rank trajectories by substantive quality rather than surface artifacts, the method would offer a practical route to label-free skill acquisition for agentic data analysis, lowering supervision costs while improving generalization on held-out tasks. The iterative coordination loop and dual verifier instantiations represent a concrete advance over purely supervised or heuristic skill-discovery approaches in this domain.
major comments (2)
- [Evaluation] Evaluation section: The reported mean improvements (9.71% and 32.30%) are stated without accompanying details on the number of runs, standard deviations, statistical significance tests, or data-exclusion criteria, preventing assessment of whether the gains are robust or attributable to the method rather than experimental variance.
- [Unsupervised Verifier] Unsupervised Verifier subsection (Adaptive Checklist Verifier and Answer Agreement Verifier): No correlation analysis, ablation, or human validation is presented showing that the extracted signals (checklist coverage scores or answer-agreement/self-consistency) track actual trajectory quality or correctness on held-out data, rather than proxies such as trajectory length or answer frequency. Because skill distillation and all downstream coordination inherit rankings directly from these signals, this assumption is load-bearing for the performance claims.
minor comments (2)
- [Abstract] Abstract contains the typo "aggreement" (should be "agreement").
- [Abstract] The phrase "consistently outperforming baselines on held-out performance" is imprecise; it should specify the exact metrics and held-out splits used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported mean improvements (9.71% and 32.30%) are stated without accompanying details on the number of runs, standard deviations, statistical significance tests, or data-exclusion criteria, preventing assessment of whether the gains are robust or attributable to the method rather than experimental variance.
Authors: We agree that these statistical details are necessary. In the revised manuscript we will report results from 5 independent runs per model-task setting, include standard deviations, conduct paired t-tests against baselines with p-values, and explicitly state data-exclusion criteria (none were applied beyond standard formatting filters). The updated tables and text will appear in Section 4. revision: yes
-
Referee: [Unsupervised Verifier] Unsupervised Verifier subsection (Adaptive Checklist Verifier and Answer Agreement Verifier): No correlation analysis, ablation, or human validation is presented showing that the extracted signals (checklist coverage scores or answer-agreement/self-consistency) track actual trajectory quality or correctness on held-out data, rather than proxies such as trajectory length or answer frequency. Because skill distillation and all downstream coordination inherit rankings directly from these signals, this assumption is load-bearing for the performance claims.
Authors: We acknowledge the load-bearing nature of this assumption. We will add (i) Pearson correlations between verifier scores and trajectory length / answer frequency to rule out surface artifacts, (ii) an ablation that replaces the learned verifier with random or length-based ranking, and (iii) a small-scale human validation study (n=50 trajectories per verifier type) measuring agreement with expert quality judgments on held-out data. These analyses will be reported in a new subsection of Section 3 and the appendix. revision: yes
Circularity Check
No significant circularity; framework relies on empirical held-out evaluation without self-referential reductions
full rationale
The paper describes an empirical framework (DataCOPE) that generates trajectories, extracts unsupervised verifier signals (Adaptive Checklist Verifier or Answer Agreement Verifier), and distills skills via contrastive learning, then reports mean gains on held-out tasks from Deep Data Research and DABStep. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on external benchmark improvements rather than any derivation that reduces to its own inputs by construction. The unsupervised verifier assumption is a methodological hypothesis subject to falsification on held-out data, not a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of data agents: Emerging paradigm or overstated hype?
Y . Zhu, L. Wang, C. Yang, X. Lin, B. Li, W. Zhou, X. Liu, Z. Peng, T. Luo, Y . Li, C. Chai, C. Chen, S. Di, J. Fan, J. Sun, N. Tang, F. Tsung, J. Wang, C. Wu, Y . Xu, S. Zhang, Y . Zhang, X. Zhou, G. Li, and Y . Luo, “A survey of data agents: Emerging paradigm or overstated hype?”CoRR, vol. abs/2510.23587, 2025. [Online]. Available: https://doi.org/10.48...
-
[2]
Large language model-based data science agent: A survey,
P. Wang, Y . Yu, K. Chen, X. Zhan, and H. Wang, “Large language model-based data science agent: A survey,”CoRR, vol. abs/2508.02744,
-
[3]
Available: https://doi.org/10.48550/arXiv.2508.02744
[Online]. Available: https://doi.org/10.48550/arXiv.2508.02744
-
[4]
Deep research: A survey of autonomous research agents,
W. Zhang, X. Li, Y . Zhang, P. Jia, Y . Wang, H. Guo, Y . Liu, and X. Zhao, “Deep research: A survey of autonomous research agents,”CoRR, vol. abs/2508.12752, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.12752
-
[5]
Data interpreter: An LLM agent for data science,
S. Hong, Y . Lin, B. Liu, B. Liu, B. Wu, C. Zhang, D. Li, J. Chen, J. Zhang, J. Wang, L. Zhang, L. Zhang, M. Yang, M. Zhuge, T. Guo, T. Zhou, W. Tao, R. Tang, X. Lu, X. Zheng, X. Liang, Y . Fei, Y . Cheng, Y . Ni, Z. Gou, Z. Xu, Y . Luo, and C. Wu, “Data interpreter: An LLM agent for data science,” inFindings of the Association for Computational Linguisti...
2025
-
[6]
Agenticdata: An agentic data analytics system for heterogeneous data,
J. Sun, G. Li, P. Zhou, Y . Ma, J. Xu, and Y . Li, “Agenticdata: An agentic data analytics system for heterogeneous data,”CoRR, vol. abs/2508.05002, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.05002
-
[7]
DS-STAR: data science agent via iterative planning and verification,
J. Nam, J. Yoon, J. Chen, and T. Pfister, “DS-STAR: data science agent via iterative planning and verification,”CoRR, vol. abs/2509.21825,
-
[8]
Available: https://doi.org/10.48550/arXiv.2509.21825
[Online]. Available: https://doi.org/10.48550/arXiv.2509.21825
-
[9]
Agentada: Skill-adaptive data analytics for tailored insight discovery,
A. Abaskohi, A. V . Ramesh, S. Nanisetty, C. Goel, D. V ´azquez, C. Pal, S. Gella, G. Carenini, and I. H. Laradji, “Agentada: Skill-adaptive data analytics for tailored insight discovery,”CoRR, vol. abs/2504.07421,
-
[10]
Available: https://doi.org/10.48550/arXiv.2504.07421
[Online]. Available: https://doi.org/10.48550/arXiv.2504.07421
-
[11]
Datawiseagent: A notebook-centric LLM agent framework for automated data science,
Z. You, Y . Zhang, D. Xu, Y . Lou, Y . Yan, W. Wang, H. Zhang, and Y . Huang, “Datawiseagent: A notebook-centric LLM agent framework for automated data science,”CoRR, vol. abs/2503.07044, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.07044
-
[12]
Data-copilot: Bridging billions of data and humans with autonomous workflow,
W. Zhang, Y . Shen, W. Lu, and Y . Zhuang, “Data-copilot: Bridging billions of data and humans with autonomous workflow,”CoRR, vol. abs/2306.07209, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2306.07209
-
[13]
Dagent: A relational database-driven data analysis report generation agent,
W. Xu, Y . Mao, X. Zhang, C. Zhang, X. Dong, M. Zhang, and Y . Gao, “Dagent: A relational database-driven data analysis report generation agent,”CoRR, vol. abs/2503.13269, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.13269
-
[14]
Scaling generalist data- analytic agents,
S. Qiao, Y . Zhao, Z. Qiu, X. Wang, J. Zhang, Z. Bin, N. Zhang, Y . Jiang, P. Xie, F. Huang, and H. Chen, “Scaling generalist data- analytic agents,”CoRR, vol. abs/2509.25084, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.25084
-
[15]
Deepanalyze: Agentic large language models for autonomous data science,
S. Zhang, J. Fan, M. Fan, G. Li, and X. Du, “Deepanalyze: Agentic large language models for autonomous data science,”CoRR, vol. abs/2510.16872, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.16872
-
[16]
Anthropic, “What are skills?” Claude Help Cen- ter, 2026, accessed: 2026-05-03. [Online]. Available: https://support.claude.com/en/articles/12512176-what-are-skills
arXiv 2026
-
[17]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Y . Jiang, D. Li, H. Deng, B. Ma, X. Wang, Q. Wang, and G. Yu, “Sok: Agentic skills - beyond tool use in LLM agents,”CoRR, vol. abs/2602.20867, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.20867
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.20867 2026
-
[18]
G. F. Ling, S. Zhong, and R. L. Huang, “Agent skills: A data- driven analysis of claude skills for extending large language model functionality,”ArXiv, vol. abs/2602.08004, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:285453033
arXiv 2026
-
[19]
Skillx: Automatically constructing skill knowledge bases for agents,
C. Wang, Z. Yu, X. Xie, W. Yao, R. Fang, S. Qiao, K. Cao, G. Zheng, X. Qi, P. Zhang, and S. Deng, “Skillx: Automatically constructing skill knowledge bases for agents,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287204111
2026
-
[20]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
J. Ni, Y . Liu, X. Liu, Y . Sun, M. Zhou, P. Cheng, D. Wang, E. Zhao, X. Jiang, and G. Jiang, “Trace2skill: Distill trajectory-local lessons into transferable agent skills,”CoRR, vol. abs/2603.25158, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.25158
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.25158 2026
-
[21]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
S. Alzubi, N. Provenzano, J. Bingham, W. Chen, and T. Vu, “Evoskill: Automated skill discovery for multi-agent systems,”CoRR, vol. abs/2603.02766, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.02766
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.02766 2026
-
[22]
Coevoskills: Self- evolving agent skills via co-evolutionary verification,
H. Zhang, S. Fan, H. P. Zou, Y . Chen, Z. Wang, J. Zhou, C. Li, W.-C. Huang, Y . Yao, K. Zheng, X. Liu, X. Li, and P. S. Yu, “Coevoskills: Self- evolving agent skills via co-evolutionary verification,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287071917
2026
-
[23]
Skillopt: Executive strategy for self-evolving agent skills,
Y . Yang, Z. Gong, W. Huang, Q. Yang, Z. Zhou, Z. Huang, Y . Li, X. Gao, Q. Dai, B. Liu, K. Qiu, Y . Yang, D. Chen, X.-T. Yang, and C. Luo, “Skillopt: Executive strategy for self-evolving agent skills,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:288652900
2026
-
[24]
Skillclaw: Let skills evolve collectively with agentic evolver,
Z. Ma, S. Yang, Y . Ji, X. Wang, Y . Wang, Y . Hu, T. Huang, and X. Chu, “Skillclaw: Let skills evolve collectively with agentic evolver,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287256390
2026
-
[25]
Skillos: Learning skill curation for self-evolving agents,
S. Ouyang, J. Yan, Y . Chen, R. Han, Z. Wang, B. Dalvi, R. Meng, C.-L. Li, Y . Jiao, K. Zha, M. Shen, V . Tirumalashetty, G. Lee, J. Han, T. Pfister, and C.-Y . Lee, “Skillos: Learning skill curation for self-evolving agents,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:288014414
2026
-
[26]
Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models
W. Liu, P. Yu, M. Orini, Y . Du, and Y . He, “Hunt instead of wait: Evaluating deep data research on large language models,”CoRR, vol. abs/2602.02039, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.02039
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02039 2026
-
[27]
Dabstep: Data agent benchmark for multi-step reasoning,
A. Egg, M. I. Goyanes, F. Kingma, A. Mora, L. von Werra, and T. Wolf, “Dabstep: Data agent benchmark for multi-step reasoning,”CoRR, vol. abs/2506.23719, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.23719
-
[28]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[29]
OpenAI, “Openai GPT-5 system card,”CoRR, vol. abs/2601.03267,
-
[30]
[Online]. Available: https://doi.org/10.48550/arXiv.2601.03267
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267
-
[31]
Skill Creator,
Anthropic, “Skill Creator,” 2026, accessed: 2026-06-03. [Online]. Available: https://github.com/anthropics/skills/blob/main/skills/skill- creator/SKILL.md
2026
-
[32]
System Card: Claude Sonnet 4.6,
——, “System Card: Claude Sonnet 4.6,” Anthropic Model System Cards, 2026, accessed: 2026-06-03. [Online]. Available: https://www- cdn.anthropic.com/bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf
2026
-
[33]
System Card: Claude Sonnet 4.5,
——, “System Card: Claude Sonnet 4.5,” Anthropic Model System Cards, 2025, accessed: 2026-05-17. [Online]. Available: https://www- cdn.anthropic.com/963373e433e489a87a10c823c52a0a013e9172dd.pdf
2025
-
[34]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[35]
Qwen3.5: Accelerating productivity with native multimodal agents,
Q. Team, “Qwen3.5: Accelerating productivity with native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[36]
Dsgym: A holistic framework for evaluating and training data science agents,
F. Nie, J. Wang, H. Hua, F. Bianchi, Y . Kwon, Z. Qi, O. Queen, S. Zhu, and J. Zou, “Dsgym: A holistic framework for evaluating and training data science agents,”CoRR, vol. abs/2601.16344, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.16344
-
[37]
Kramabench: A benchmark for AI systems on data-to-insight pipelines over data lakes,
E. Lai, G. Vitagliano, Z. Zhang, S. Sudhir, O. Chabra, A. Zeng, A. A. Zabreyko, C. Li, F. Kossmann, J. Ding, J. Chen, M. Markakis, M. Russo, W. Wang, Z. Wu, M. J. Cafarella, L. Cao, S. Madden, and T. Kraska, “Kramabench: A benchmark for AI systems on data-to-insight pipelines over data lakes,”CoRR, vol. abs/2506.06541,
-
[38]
Available: https://doi.org/10.48550/arXiv.2506.06541
[Online]. Available: https://doi.org/10.48550/arXiv.2506.06541
-
[39]
Sanity checks for agentic data science,
Z. T. Rewolinski, A. Zane, H. Huang, C. Singh, C. Wang, J. Gao, and B. Yu, “Sanity checks for agentic data science,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287433410
2026
-
[40]
Matplotagent: Method and evaluation for llm-based agentic scientific data visualization,
Z. Yang, Z. Zhou, S. Wang, X. Cong, X. Han, Y . Yan, Z. Liu, Z. Tan, P. Liu, D. Yu, Z. Liu, X. Shi, and M. Sun, “Matplotagent: Method and evaluation for llm-based agentic scientific data visualization,” inFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, L. Ku, A. Martins, and V...
-
[41]
Insightpilot: An llm-empowered automated data exploration system,
P. Ma, R. Ding, S. Wang, S. Han, and D. Zhang, “Insightpilot: An llm-empowered automated data exploration system,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023 - System Demonstrations, Singapore, December 6-10, 2023, Y . Feng and E. Lefever, Eds. Association for Computational Linguistics, 2023, pp. 3...
-
[42]
Datastorm: Deep research on large-scale databases using exploratory data analysis and data storytelling,
S. Liu, Y . Jiang, S. Farook, C. N. Sanchez, D. F. C. Pena, and M. S. Lam, “Datastorm: Deep research on large-scale databases using exploratory data analysis and data storytelling,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287248168
2026
-
[43]
Datacross: A unified benchmark and agent framework for cross-modal heterogeneous data analysis,
R. Qi, Z. Liu, and W. Zhang, “Datacross: A unified benchmark and agent framework for cross-modal heterogeneous data analysis,”ArXiv, vol. abs/2601.21403, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:285140426
arXiv 2026
-
[44]
DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework
B. Li, C. Chen, Z. Xue, Y . Mei, and Y . Luo, “Deepeye-sql: A software-engineering-inspired text-to-sql frame- work,”CoRR, vol. abs/2510.17586, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.17586
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.17586 2025
-
[45]
Why do open-source llms struggle with data analysis? A systematic empirical study,
Y . Zhu, Y . Zhong, J. Zhang, Z. Zhang, S. Qiao, Y . Luo, L. Du, D. Zheng, H. Chen, and N. Zhang, “Why do open-source llms struggle with data analysis? A systematic empirical study,”CoRR, vol. abs/2506.19794,
-
[46]
Available: https://doi.org/10.48550/arXiv.2506.19794
[Online]. Available: https://doi.org/10.48550/arXiv.2506.19794
-
[47]
Welcome to the era of experience
D. Silver and R. Sutton, “Welcome to the era of experience.” [Online]. Available: https://api.semanticscholar.org/CorpusID:277919528
-
[48]
Agent skills for large language models: Architecture, acquisition, security, and the path forward,
R. Xu and Y . Yan, “Agent skills for large language models: Architecture, acquisition, security, and the path forward,”CoRR, vol. abs/2602.12430,
-
[49]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
[Online]. Available: https://doi.org/10.48550/arXiv.2602.12430
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12430
-
[50]
Inducing programmatic skills for agentic tasks,
Z. Z. Wang, A. Gandhi, G. Neubig, and D. Fried, “Inducing programmatic skills for agentic tasks,”CoRR, vol. abs/2504.06821,
-
[51]
arXiv preprint arXiv:2504.06821 , year=
[Online]. Available: https://doi.org/10.48550/arXiv.2504.06821
-
[52]
Reinforcement Learning for Self-Improving Agent with Skill Library
J. Wang, Q. Yan, Y . Wang, Y . Tian, S. S. Mishra, Z. Xu, M. Gandhi, P. Xu, and L. L. Cheong, “Reinforcement learning for self-improving agent with skill library,”CoRR, vol. abs/2512.17102, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2512.17102
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.17102 2025
-
[53]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
H. Zhang, Q. Long, J. Bao, T. Feng, W. Zhang, H. Yue, and W. Wang, “Memskill: Learning and evolving memory skills for self-evolving agents,”CoRR, vol. abs/2602.02474, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.02474
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02474 2026
-
[54]
Memp: Exploring Agent Procedural Memory
R. Fang, Y . Liang, X. Wang, J. Wu, S. Qiao, P. Xie, F. Huang, H. Chen, and N. Zhang, “Memp: Exploring agent procedural memory,”CoRR, vol. abs/2508.06433, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.06433
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.06433 2025
-
[55]
Thinking with Reasoning Skills: Fewer Tokens, More Accuracy
G. Zhao, Q. Shi, X. Xiao, X. Zhang, T. Yang, and L. Sun, “Thinking with reasoning skills: Fewer tokens, more accuracy,”CoRR, vol. abs/2604.21764, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2604.21764
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.21764 2026
-
[56]
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning,
P. Xia, J. Chen, H. Wang, J. Liu, K. Zeng, Y . Wang, S. Han, Y . Zhou, X. Zhao, H. Chen, Z. Zheng, C. Xie, and H. Yao, “Skillrl: Evolving agents via recursive skill-augmented reinforcement learning,”ArXiv, vol. abs/2602.08234, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:285452037
Pith/arXiv arXiv 2026
-
[57]
Skillforge: Forging domain-specific, self-evolving agent skills in cloud technical support,
X. Liu, X. Luo, L. Li, G. Huang, J. Liu, and H. Qiao, “Skillforge: Forging domain-specific, self-evolving agent skills in cloud technical support,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287351631
2026
-
[58]
Memento-skills: Let agents design agents,
H. Zhou, S. Guo, A. Liu, Z. Yu, Z. Gong, B. Zhao, Z. Chen, M. Zhang, Y . Chen, J. Li, R. Yang, Q. Liu, X. Yu, J. Zhou, N. Wang, C. Sun, and J. Wang, “Memento-skills: Let agents design agents,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:286673350
2026
-
[59]
Autoskill: Experience-driven lifelong learning via skill self- evolution,
Y . Yang, J. Li, Q. Pan, B. Zhan, Y . Cai, L. Du, J. Zhou, K. Chen, Q. Chen, X. Li, B. Zhang, and L. He, “Autoskill: Experience-driven lifelong learning via skill self- evolution,”ArXiv, vol. abs/2603.01145, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:286224498
arXiv 2026
-
[60]
From context to skills: Can language models learn from context skillfully?
S. Si, H. Zhao, Y . Lei, Q. Wang, D. Chen, Z. Wang, Z. Wang, K. Luo, Z. Wang, G. Chen, F. Qi, M. Zhang, and M. Sun, “From context to skills: Can language models learn from context skillfully?” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:287915777
2026
-
[61]
Mmskills: Towards multimodal skills for general visual agents,
K. Zhang, S. Shao, Q. Li, J. Lin, L. Fu, S. Wang, W. Jiao, Y . Lu, W. Liu, W. Zhang, and Y . Yu, “Mmskills: Towards multimodal skills for general visual agents,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:288254572
2026
-
[62]
Skillsvote: Lifecycle governance of agent skills from collection, recommendation to evolution,
H. Liu, H. Yang, T. Jiang, B. Tang, F. Xiong, and Z. Li, “Skillsvote: Lifecycle governance of agent skills from collection, recommendation to evolution,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:288651284
2026
-
[63]
arXiv preprint arXiv:2603.04448 , year=
Y . Liang, R. Zhong, H. Xu, C. Jiang, Y . Zhong, R. Fang, J. Gu, S. Deng, Y . Yao, M. Wang, S. Qiao, X. Xu, T. Wu, K. Wang, Y . Liu, Z. Bi, J. Lou, Y . E. Jiang, H. Zhu, G. Yu, H. Hong, L. Huang, H. Xue, C. Wang, Y . Wang, Z. Shan, X. Chen, Z. Tu, F. Xiong, X. Xie, P. Zhang, Z. Gui, L. Liang, J. Zhou, C. Wu, J. Shang, Y . Gong, J. Lin, C. Xu, H. Deng, W. ...
-
[64]
Skillrouter: Skill routing for llm agents at scale,
Y . Zheng, Z. Zhang, C. Ma, Y . Yu, J. Zhu, Y . Wu, T. Xu, B. Dong, H. Zhu, R. Huang, and G. Yu, “Skillrouter: Skill routing for llm agents at scale,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:286770530
2026
-
[65]
Organizing, orchestrating, and benchmarking agent skills at ecosystem scale,
H. Li, C. Mu, J. Chen, S. Ren, Z. Cui, Y . Zhang, L. Bai, and S. Hu, “Organizing, orchestrating, and benchmarking agent skills at ecosystem scale,” 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:286222444
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.