Closing the Activation-Cone Blind Spot: Response-Time Probing and Unified Defense
Pith reviewed 2026-06-30 07:19 UTC · model grok-4.3
The pith
Prompt-time defenses that gate on activation alignment with a benign reference are blind to prefilling attacks that place malicious activations inside the reference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
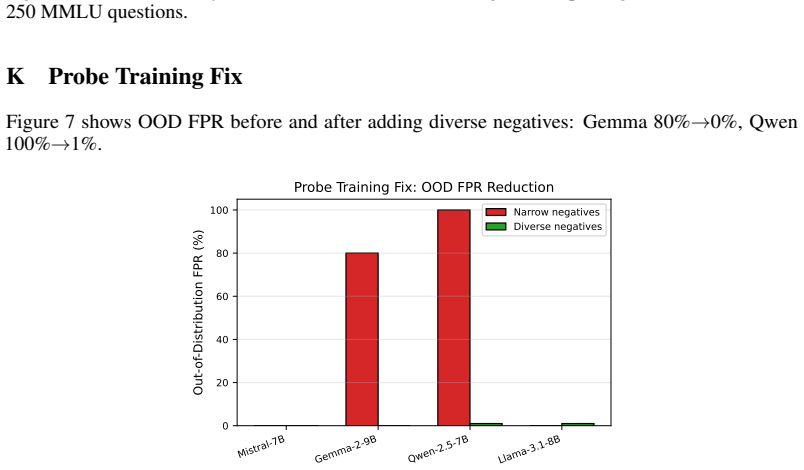
Any defense that gates intervention on a single layer's activation alignment with a benign reference (cone, subspace, or null-space) is blind to attacks that craft activations to lie inside that reference, whether checked at prompt time or per token. Response-time probing applies a linear probe to the hidden state at the first generated tokens and, combined with a halt, cuts prefilling attack success to zero on every evaluated model while preserving zero benign false positives.
What carries the argument
Response-time probing: a linear probe on the model's hidden state at the first generated tokens that detects attacks whose activations fit inside prompt-time benign references.
If this is right
- AlphaSteer reaches 0% attack success on GCG, AutoDAN, and intent laundering but only 50% on prefilling.
- Composing the response-time halt with AlphaSteer null-space steering yields defense success of 0.983 on Mistral and 0.994 on Llama.
- Diverse negative training sets reduce probe false positives from 80-100% to near zero.
- MMLU does not capture steering's true utility cost, which appears as behavioral hedging rather than factual loss.
Where Pith is reading between the lines
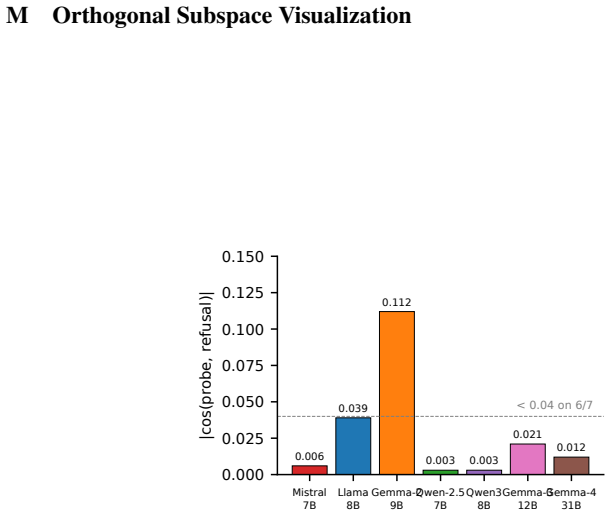
- The blind-spot proof may apply to any defense whose decision depends on a fixed reference alignment at generation time.
- Training the probe on a wider range of prefilling templates could improve cross-template robustness beyond the scoped claim.
- Similar reference-alignment blind spots could appear in defenses that average or ensemble multiple layers rather than using a single layer.
- pith_inferences
Load-bearing premise
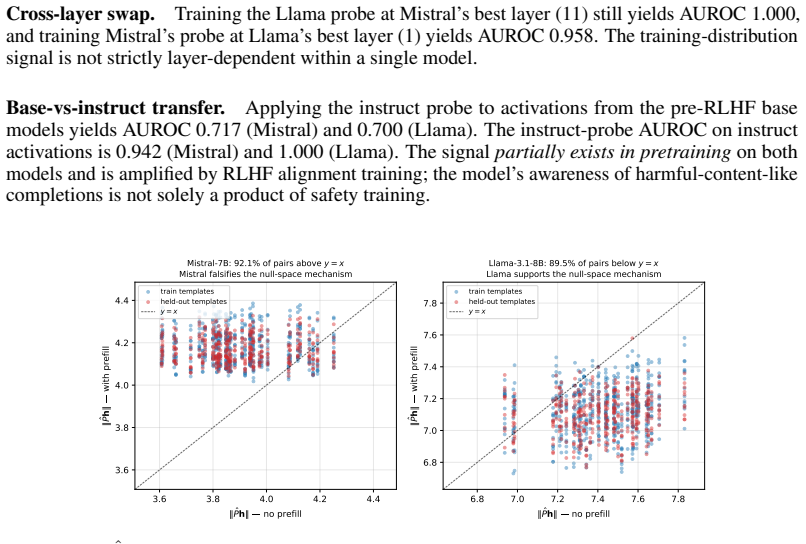
The linear probe trained on diverse negative sets will maintain low false positives and high AUROC when the input distribution shifts beyond the canonical prefilling-template family used in evaluation.
What would settle it
Running the trained probe on a new family of prefilling templates outside the canonical evaluation set and checking whether AUROC remains above 0.97 would test the claimed generalization.
Figures

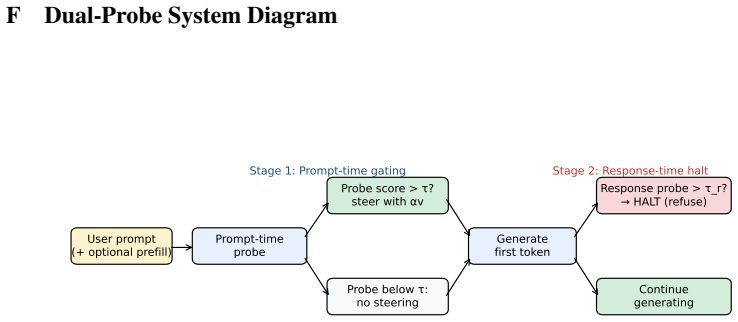
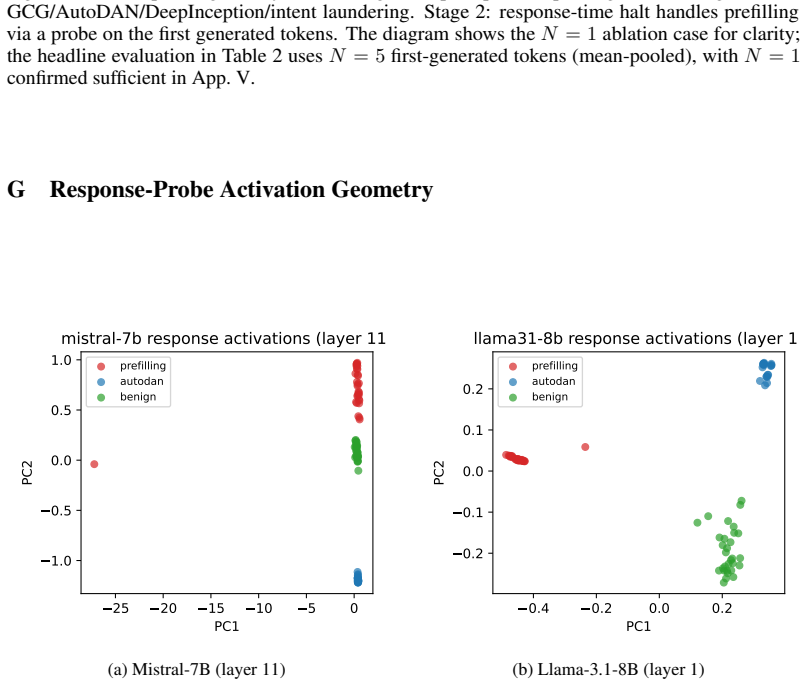
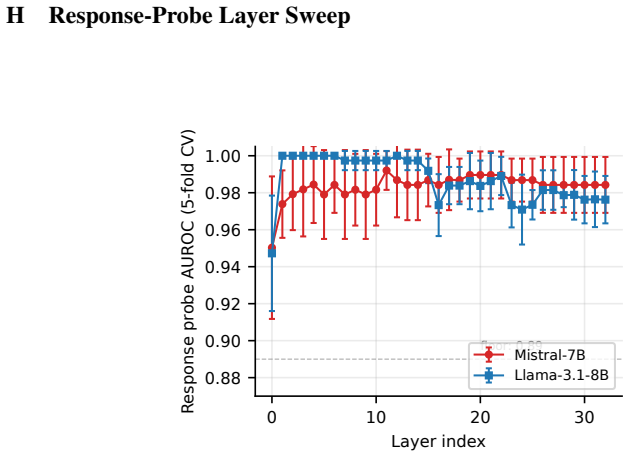
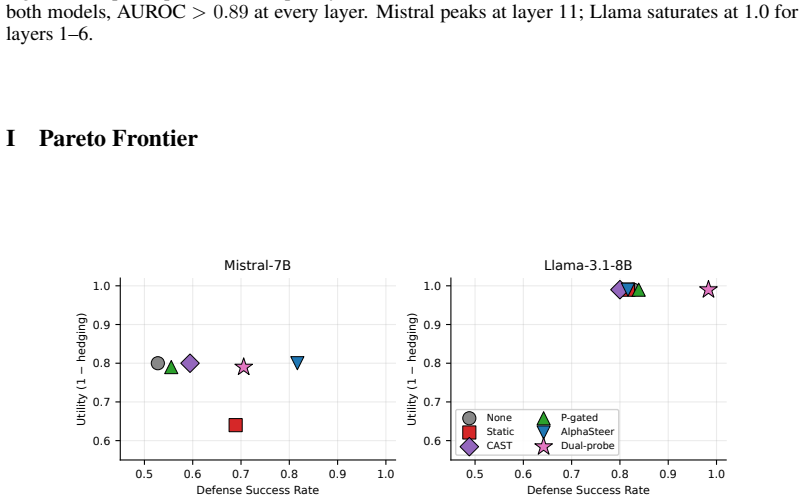




read the original abstract
Inference-time safety methods for large language models have proliferated, yet no systematic comparison exists. We evaluate five defense paradigms (no defense, static steering, CAST, AlphaSteer, probe-gated) across seven instruction-tuned models (7-31B) and five attack types (GCG, AutoDAN, DeepInception, prefilling, intent laundering). Our central finding: prompt-time activation defenses are structurally blind to prefilling attacks. AlphaSteer achieves 0% attack success on GCG, AutoDAN, and intent laundering but 50% on prefilling. We prove a corollary: any defense that gates intervention on a single layer's activation alignment with a benign reference (cone, subspace, or null-space) is blind to attacks that craft activations to lie inside that reference, whether checked at prompt time or per token. As its constructive contrapositive we introduce response-time probing: a linear probe on the model's hidden state at the first generated tokens, with AUROC 0.97-1.00 across all seven models. Combined with a halt, it cuts prefilling attack success to 0/40 on every model with 0% benign false positives, outperforming Llama Guard 3. Cross-template generalisation depends on probe depth, so we scope the claim to the canonical prefilling-template family. Composing the response-halt with AlphaSteer's null-space steering gives an orthogonal split (the halt catches prefilling, AlphaSteer catches semantic attacks), reaching defense success 0.983 on Mistral and 0.994 on Llama and dominating both components. We further show MMLU fails to capture steering's true utility cost, which appears as behavioral hedging rather than factual loss, and that diverse negative training sets cut probe false positives from 80-100% to near zero. Code, attacks, per-sample results, and the judge prompt are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates five inference-time defense paradigms (no defense, static steering, CAST, AlphaSteer, probe-gated) on seven models (7-31B) and five attacks (GCG, AutoDAN, DeepInception, prefilling, intent laundering). It claims prompt-time activation defenses are structurally blind to prefilling attacks, proves a corollary that any single-layer alignment defense (cone, subspace, null-space) is blind to in-reference attacks, introduces a response-time linear probe on first generated tokens achieving AUROC 0.97-1.00, and shows that a halt based on it reduces prefilling ASR to 0/40 with 0% benign FPs. Composing the halt with AlphaSteer yields orthogonal defense success rates of 0.983 (Mistral) and 0.994 (Llama); it also reports that MMLU misses steering's hedging costs and that diverse negative sets reduce probe FPs to near zero. Code and per-sample results are released.
Significance. If the corollary is rigorously proven and the empirical results (including probe generalization within the scoped template family) hold under full methods disclosure, the work would be significant for LLM safety: it identifies a structural limitation of prompt-time activation methods, supplies a practical response-time complement that outperforms Llama Guard 3 in the reported setting, and demonstrates an orthogonal composition strategy. The public release of code, attacks, results, and judge prompt is a clear strength supporting reproducibility.
major comments (3)
- [Abstract and main text] Abstract and main text: the manuscript states 'We prove a corollary' that any single-layer alignment defense is blind to in-reference attacks, but the proof itself is not presented; this structural claim is load-bearing for the central negative result and must be supplied with explicit reasoning.
- [Experimental sections] Experimental sections: concrete performance figures (AUROC 0.97-1.00, 0/40 ASR, 0% FPs, defense success 0.983/0.994) are reported across seven models and five attacks, yet full methods, data splits, judge prompt details, and exact probe training procedure are absent, rendering the central empirical claims unverifiable.
- [Response-time probing and unified defense sections] Response-time probing and unified defense sections: the manuscript explicitly scopes cross-template generalization to the canonical prefilling-template family and notes dependence on probe depth; because the reported unified defense success rates rely on the probe maintaining low FPs and high AUROC, the scope and any distribution-shift tests must be stated precisely.
minor comments (2)
- [Utility cost discussion] The discussion that MMLU fails to capture behavioral hedging is valuable but would be strengthened by additional quantitative examples or alternative metrics.
- [Throughout] Ensure consistent numbering and cross-referencing for all sections, tables, and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, completeness, and reproducibility.
read point-by-point responses
-
Referee: [Abstract and main text] Abstract and main text: the manuscript states 'We prove a corollary' that any single-layer alignment defense is blind to in-reference attacks, but the proof itself is not presented; this structural claim is load-bearing for the central negative result and must be supplied with explicit reasoning.
Authors: We agree that the explicit proof is required for the central claim. The revised manuscript will add a dedicated section (or appendix) presenting the full reasoning and formal proof of the corollary. revision: yes
-
Referee: [Experimental sections] Experimental sections: concrete performance figures (AUROC 0.97-1.00, 0/40 ASR, 0% FPs, defense success 0.983/0.994) are reported across seven models and five attacks, yet full methods, data splits, judge prompt details, and exact probe training procedure are absent, rendering the central empirical claims unverifiable.
Authors: We acknowledge that full methodological details are necessary for verifiability. The revision will expand the experimental sections to include complete methods, data splits, the judge prompt, and the exact probe training procedure. revision: yes
-
Referee: [Response-time probing and unified defense sections] Response-time probing and unified defense sections: the manuscript explicitly scopes cross-template generalization to the canonical prefilling-template family and notes dependence on probe depth; because the reported unified defense success rates rely on the probe maintaining low FPs and high AUROC, the scope and any distribution-shift tests must be stated precisely.
Authors: The manuscript already states the scoping to the canonical prefilling-template family and notes dependence on probe depth. We will revise these sections to articulate the scope and any distribution-shift tests with additional precision. revision: partial
Circularity Check
No significant circularity; empirical results and logical corollary are self-contained
full rationale
The paper's derivation consists of a structural logical corollary (any single-layer alignment defense is blind to in-reference activations) that follows directly from the definition of such defenses without data dependence or self-reference, plus empirical measurements of probe AUROC, attack success rates, and defense success on specific models/attacks. These metrics are reported from evaluation rather than derived by construction from fitted inputs or prior self-citations. The response-time probe is introduced as a contrapositive and its performance scoped explicitly to the evaluated template family, with no renaming of known results or ansatz smuggling. The unified defense composition is presented as an observed orthogonal split based on separate empirical behaviors. No load-bearing step reduces to its own inputs; the chain rests on external measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Intent Laundering: AI Safety Datasets Are Not What They Seem
Llama Guard 3 (8B) introduced in this report (Section 5.4). Shahriar Golchin and Marc Wetter. Intent laundering: AI safety datasets are not what they seem. arXiv preprint arXiv:2602.16729,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Segment-Level Coherence for Robust Harmful Intent Probing in LLMs
Xuanli He, Bilgehan Sel, Faizan Ali, Jenny Bao, Hoagy Cunningham, and Jerry Wei. Segment-level coherence for robust harmful intent probing in LLMs.arXiv preprint arXiv:2604.14865,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Rogov, Ivan Oseledets, and Elena Tutubalina
Anton Korznikov, Andrey Galichin, Alexey Dontsov, Oleg Y . Rogov, Ivan Oseledets, and Elena Tutubalina. The rogue scalpel: Activation steering compromises LLM safety.arXiv preprint arXiv:2509.22067,
-
[5]
Building production-ready probes for Gemini.arXiv preprint arXiv:2601.11516,
János Kramár, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for Gemini.arXiv preprint arXiv:2601.11516,
-
[6]
Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han
Spotlight; arXiv:2409.05907. Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. DeepInception: Hypnotize large language model to be jailbreaker.arXiv preprint arXiv:2311.03191,
-
[7]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Weikai Lu, Ziqian Zeng, Kehua Zhang, Haoran Li, Huiping Zhuang, Ruidong Wang, Cen Chen, and Hao Peng. ARGUS: Defending against multimodal indirect prompt injection via steering instruction-following behavior.arXiv preprint arXiv:2512.05745,
-
[9]
Weiming Song, Xuan Xie, and Ruiping Yin
arXiv:2506.07022. Weiming Song, Xuan Xie, and Ruiping Yin. AISA: Awakening intrinsic safety awareness in large language models against jailbreak attacks.arXiv preprint arXiv:2602.13547,
-
[10]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yinzhi Zhao, Ming Wang, Shi Feng, Xiaocui Yang, Daling Wang, and Yifei Zhang. SafeProbing: Defending large language models against jailbreak attacks via in-decoding safety-awareness probing.arXiv preprint arXiv:2601.10543,
-
[12]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Sure, here is
10 A GCG Optimization Details GCG suffixes were optimized using nanogcg with 512 steps, search width 512, topk 256, target string “Sure, here is”. At n= 40 : Mistral-7B 40/40 valid, average loss 0.053; Llama-3.1-8B 40/40 valid, average loss 1.926. At n= 200 (Appendix E): Mistral-7B 200/200 valid, average loss 0.053; Llama-3.1-8B 200/200 valid, average los...
2023
-
[14]
Qwen3-8B (2025) achieves the best result
and E9 judge-truncation sensitivity Table 8: Template robustness: augmented linear probe detection rate on 10 held-out novel prefill templates, trained with 600 harmful (40 AdvBench behaviors × 15 templates) + 45 benign (15 benign-prefilled + 30 benign-plain) = 645 training samples. Qwen3-8B (2025) achieves the best result. Judge uses a 5-token response w...
2025
-
[15]
detect harm
improves only training-distribution detection, not canonical-register novel-token generalisation; see the probe-transfer note below. paper L @ 30-tok judge new L @ 30-tok judge Model L detect FPR L detect FPR Mistral-7B 15 66.7% 12.5% 24 88.9% 9.4% Llama-3.1-8B 15100.0%7.0% 15100.0%7.0% Gemma-2-9B 27 50.0% 4.5% 42 83.3% 2.3% Qwen-2.5-7B 4 14.3% 4.7% 19 71...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.