LatentUMM: Dual Latent Alignment for Unified Multimodal Models
Pith reviewed 2026-05-20 12:35 UTC · model grok-4.3
The pith
Unified multimodal models reduce functional inconsistency by explicitly aligning transformations into and out of their shared latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that functional inconsistency between generation and re-encoding in unified multimodal models stems from the absence of explicit alignment between the transformations mapping into and out of the shared latent space. LatentUMM addresses this by first applying dual latent alignment at modality level through cross-modal semantics from a stronger embedding model and at capacity level for bidirectional consistency under generation and re-encoding, then applying latent dynamics stabilization with stochastic latent rollouts and preference optimization to favor consistent trajectories. Experiments indicate this yields improved cross-modal consistency across diverse architectures
What carries the argument
Dual latent alignment, which enforces consistency at the modality level using structured cross-modal semantics and at the capacity level for bidirectional generation and re-encoding.
If this is right
- Generation and re-encoding follow more consistent trajectories that preserve semantic content across modality changes.
- Cross-modal alignment imposes structured semantics that strengthen the shared latent space without new training data.
- Bidirectional capacity alignment reduces drift in both directions between generation and understanding.
- Stochastic rollouts combined with preference optimization favor trajectories that maintain consistency.
Where Pith is reading between the lines
- The same alignment principle could extend to models handling more than two modalities at once.
- Similar stabilization steps might reduce drift in sequential tasks such as video captioning followed by re-generation.
- Applying the method to larger-scale unified models would show whether the gains remain architecture-agnostic.
Load-bearing premise
That the inconsistency arises mainly from unaligned input and output transformations in the latent space rather than from other training factors or insufficient shared representations.
What would settle it
Running the dual alignment stage on a model and then measuring whether generation-re-encoding consistency improves only when the stronger embedding model is used for cross-modal alignment would test the claim directly.
Figures


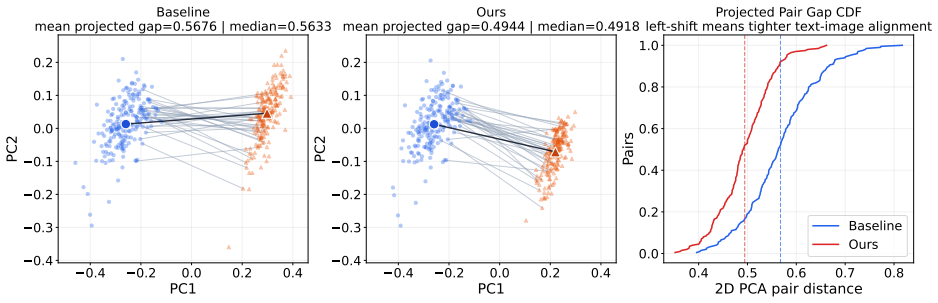
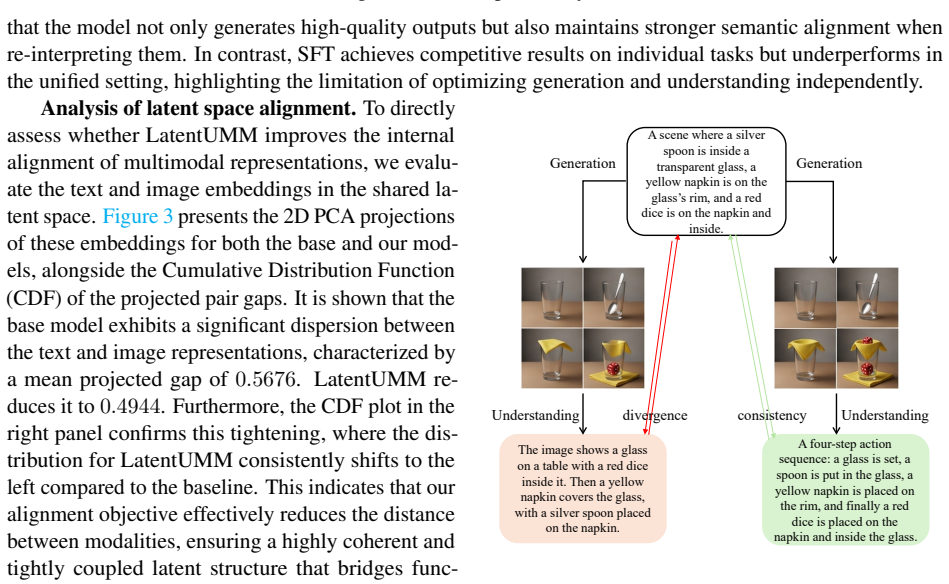



read the original abstract
Unified multimodal models (UMMs) achieve strong performance in both understanding and generation by learning a shared latent space, yet they often exhibit functional inconsistency between these two capabilities. We observe that this issue does not stem from a lack of shared representations, but from the absence of explicit alignment between the transformations that map into and out of the latent space. As a result, generation and re-encoding can follow inconsistent trajectories, leading to semantic drift under modality transitions. In this work, we propose LatentUMM, a framework that constructs an enhanced shared latent space to explicitly align these transformations and improve cross-modal consistency. LatentUMM consists of two stages. First, dual latent alignment enforces consistency at both the modality and capacity levels: cross-modal alignment uses a stronger embedding model to impose structured cross-modal semantics, while dual capacity alignment enforces bidirectional consistency under generation and re-encoding. Second, latent dynamics stabilization improves robustness via stochastic latent rollouts and preference optimization, favoring trajectories that better preserve semantic consistency. Experiments show that LatentUMM consistently improves multimodal consistency across diverse architectures. Code is available at: https://github.com/AIFrontierLab/TorchUMM/tree/main/src/umm/post_training/LatentUMM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LatentUMM, a two-stage post-training framework for unified multimodal models (UMMs) that addresses functional inconsistency between generation and understanding tasks. It claims this inconsistency arises specifically from unaligned in/out transformations of the shared latent space rather than insufficient shared representations. Stage 1 performs dual latent alignment (cross-modal alignment via a stronger embedding model plus dual-capacity bidirectional consistency enforcement); Stage 2 applies latent dynamics stabilization through stochastic rollouts and preference optimization. Experiments are reported to show consistent gains in cross-modal consistency across diverse UMM architectures, with code released.
Significance. If the central attribution holds and the gains are isolated from confounds, the work could offer a lightweight, architecture-agnostic way to reduce semantic drift in existing UMMs, which would be practically useful. The public code release is a positive factor for reproducibility. The significance is tempered by the need to confirm that observed improvements stem from the proposed explicit alignment rather than auxiliary factors such as embedding model capacity.
major comments (2)
- [Abstract / §1] Abstract and §1 (motivation): the claim that inconsistency 'does not stem from a lack of shared representations, but from the absence of explicit alignment between the transformations' is load-bearing for the entire framework. No ablation is described that holds representation capacity fixed while varying only the alignment losses, leaving the weakest assumption under-supported.
- [§3] §3 (Dual Latent Alignment, cross-modal component): the method explicitly uses a stronger embedding model to impose structured cross-modal semantics. This creates a direct confound with the central claim, as any consistency gains could be driven by the superior pretraining or capacity of the stronger model rather than the alignment or bidirectional consistency losses. An ablation that applies the same stronger model with and without the proposed alignment objectives is required to isolate the contribution.
minor comments (2)
- [Experiments] The description of 'multimodal consistency' metrics and the exact baselines used in the experiments section would benefit from additional quantitative detail and error bars to allow direct comparison.
- [§2 / §3] Notation for the latent transformations (e.g., the in/out maps) should be introduced with explicit equations early in §2 or §3 to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which help strengthen the empirical support for our central claims. We address each major point below and have revised the manuscript to incorporate the requested ablations.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and §1 (motivation): the claim that inconsistency 'does not stem from a lack of shared representations, but from the absence of explicit alignment between the transformations' is load-bearing for the entire framework. No ablation is described that holds representation capacity fixed while varying only the alignment losses, leaving the weakest assumption under-supported.
Authors: We agree that the load-bearing claim requires an ablation that isolates alignment losses while holding representation capacity fixed. In the revised manuscript we have added this ablation: we train with the base embedding model (fixed capacity) and compare the full dual latent alignment objectives against a variant that removes the alignment losses but retains the same shared latent space and training budget. The results show consistent gains from the alignment terms alone, providing direct support for the claim that the inconsistency arises from unaligned in/out transformations rather than insufficient shared representations. revision: yes
-
Referee: [§3] §3 (Dual Latent Alignment, cross-modal component): the method explicitly uses a stronger embedding model to impose structured cross-modal semantics. This creates a direct confound with the central claim, as any consistency gains could be driven by the superior pretraining or capacity of the stronger model rather than the alignment or bidirectional consistency losses. An ablation that applies the same stronger model with and without the proposed alignment objectives is required to isolate the contribution.
Authors: The referee correctly notes the potential confound introduced by the stronger embedding model. We have added the requested ablation in the revised manuscript: we apply the identical stronger embedding model in two settings—one with our dual latent alignment objectives and one without—while keeping all other training details fixed. The comparison isolates the contribution of the alignment and bidirectional consistency losses, showing that these objectives account for the majority of the observed consistency improvements beyond the capacity of the stronger model alone. revision: yes
Circularity Check
No circularity: framework adds explicit alignment stages as independent construction
full rationale
The paper's derivation begins with an empirical observation that functional inconsistency arises specifically from absent explicit alignment between latent in/out transformations rather than insufficient shared representations. It then introduces LatentUMM as a two-stage construction: dual latent alignment (cross-modal via stronger embedding plus bidirectional capacity consistency) followed by stabilization via stochastic rollouts and preference optimization. No equations, fitted parameters, or self-citations are shown reducing the claimed consistency gains to the original inputs by construction. The central claim remains a novel architectural addition whose validity is tested externally via experiments on diverse architectures, keeping the chain self-contained without self-definitional loops or load-bearing prior-author uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A stronger embedding model imposes structured cross-modal semantics that improve the shared latent space
- domain assumption Bidirectional consistency between generation and re-encoding can be directly enforced by alignment at the capacity level
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual latent alignment enforces consistency at both the modality and capacity levels: cross-modal alignment uses a stronger embedding model to impose structured cross-modal semantics, while dual capacity alignment enforces bidirectional consistency under generation and re-encoding.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models- architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Sihao Chen, Fan Zhang, Kazoo Sone, and Dan Roth. Improving faithfulness in abstractive summa- rization with contrast candidate generation and selection. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5935–5941, 2021
work page 2021
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[4]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yufeng Cui, Honghao Chen, Haoge Deng, Xu Huang, Xinghang Li, Jirong Liu, Yang Liu, Zhuoyan Luo, Jinsheng Wang, Wenxuan Wang, et al. Emu3. 5: Native multimodal models are world learners. arXiv preprint arXiv:2510.26583, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler. Vse++: Improving visual-semantic embeddings with hard negatives.arXiv preprint arXiv:1707.05612, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. Devise: A deep visual-semantic embedding model.Advances in neural information processing systems, 26, 2013
work page 2013
-
[9]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
work page 2019
-
[12]
Yujin Han, Hao Chen, Andi Han, Zhiheng Wang, Xinyu Liu, Yingya Zhang, Shiwei Zhang, and Difan Zou. Turning internal gap into self-improvement: Promoting the generation-understanding unification in mllms.arXiv preprint arXiv:2507.16663, 2025
-
[13]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Interleaving reasoning for better text-to-image generation
Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, et al. Interleaving reasoning for better text-to-image generation.arXiv preprint arXiv:2509.06945, 2025
-
[16]
Hongbo Jiang, Jie Li, Yunhang Shen, Pingyang Dai, Xing Sun, Haoyu Cao, and Liujuan Cao. Can unified generation and understanding models maintain semantic equivalence across different output modalities?arXiv preprint arXiv:2602.23711, 2026
-
[17]
Understanding and constructing latent modality structures in multi-modal representation learning
Qian Jiang, Changyou Chen, Han Zhao, Liqun Chen, Qing Ping, Son Dinh Tran, Yi Xu, Belinda Zeng, and Trishul Chilimbi. Understanding and constructing latent modality structures in multi-modal representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7661–7671, 2023
work page 2023
-
[18]
Jiachun Jin, Zetong Zhou, Xiao Yang, Hao Zhang, Pengfei Liu, Jun Zhu, and Zhijie Deng. Latentum: Unleashing the potential of interleaved cross-modal reasoning via a latent-space unified model.arXiv preprint arXiv:2604.02097, 2026
-
[19]
Weiyang Jin, Yuwei Niu, Jiaqi Liao, Chengqi Duan, Aoxue Li, Shenghua Gao, and Xihui Liu. Srum: Fine-grained self-rewarding for unified multimodal models.arXiv preprint arXiv:2510.12784, 2025
-
[20]
Gemini Embedding: Generalizable Embeddings from Gemini
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gus- tavo Hernández Ábrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, et al. Gemini embedding: Generalizable embeddings from gemini.arXiv preprint arXiv:2503.07891, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Ueval: A benchmark for unified multimodal generation.arXiv preprint arXiv:2601.22155,
Bo Li, Yida Yin, Wenhao Chai, Xingyu Fu, and Zhuang Liu. Ueval: A benchmark for unified multimodal generation.arXiv preprint arXiv:2601.22155, 2026
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[23]
Representation interpretation with spatial encoding and multimodal analytics
Ninghao Liu, Mengnan Du, and Xia Hu. Representation interpretation with spatial encoding and multimodal analytics. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pages 60–68, 2019
work page 2019
-
[24]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[25]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Yinyi Luo, Hrishikesh Gokhale, Marios Savvides, Jindong Wang, and Shengfeng He. Self-corrected image generation with explainable latent rewards.arXiv preprint arXiv:2603.24965, 2026
-
[27]
TorchUMM: A Unified Multimodal Model Codebase for Evaluation, Analysis, and Post-training
Yinyi Luo, Wenwen Wang, Hayes Bai, Hongyu Zhu, Hao Chen, Pan He, Marios Savvides, Sharon Li, and Jindong Wang. Torchumm: A unified multimodal model codebase for evaluation, analysis, and post-training.arXiv preprint arXiv:2604.10784, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai yu, Liang Zhao, Yisong Wang, Jiaying Liu, and Chong Ruan. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation, 2024. 12
work page 2024
-
[29]
Weijia Mao, Zhenheng Yang, and Mike Zheng Shou. Unirl: Self-improving unified multimodal models via supervised and reinforcement learning.arXiv preprint arXiv:2505.23380, 2025
-
[30]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, and Hao Li. Uni-cot: Towards unified chain-of-thought reasoning across text and vision.arXiv preprint arXiv:2508.05606, 2025
-
[32]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[33]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[34]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, 2018
work page 2018
-
[35]
Yang Shi, Yuhao Dong, Yue Ding, Yuran Wang, Xuanyu Zhu, Sheng Zhou, Wenting Liu, Haochen Tian, Rundong Wang, Huanqian Wang, et al. Realunify: Do unified models truly benefit from unification? a comprehensive benchmark.arXiv preprint arXiv:2509.24897, 2025
-
[36]
Unigame: Turning a unified multimodal model into its own adversary
Zhaolong Su, Wang Lu, Hao Chen, Sharon Li, and Jindong Wang. Unigame: Turning a unified multimodal model into its own adversary. InCVPR, 2026
work page 2026
-
[37]
Generation enhances understanding in unified multimodal models via multi-representation generation
Zihan Su, Hongyang Wei, Kangrui Cen, Yong Wang, Guanhua Chen, Chun Yuan, and Xiangxiang Chu. Generation enhances understanding in unified multimodal models via multi-representation generation. arXiv preprint arXiv:2601.21406, 2026
-
[38]
Chenlong Wang, Yuhang Chen, Zhihan Hu, Dongping Chen, Wenhu Chen, Sarah Wiegreffe, and Tianyi Zhou. Quantifying the gap between understanding and generation within unified multimodal models. arXiv preprint arXiv:2602.02140, 2026
-
[39]
Dianyi Wang, Ruihang Li, Feng Han, Chaofan Ma, Wei Song, Siyuan Wang, Yibin Wang, Yi Xin, Hongjian Liu, Zhixiong Zhang, et al. Deepgen 1.0: A lightweight unified multimodal model for advancing image generation and editing.arXiv preprint arXiv:2602.12205, 2026
-
[40]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Zimo Wen, Boxiu Li, Wanbo Zhang, Junxiang Lei, Xiaoyu Chen, Yijia Fan, Qi Zhang, Yujiang Wang, Lili Qiu, Bo Li, et al. Unig2u-bench: Do unified models advance multimodal understanding?arXiv preprint arXiv:2603.03241, 2026
-
[42]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation.arXiv preprint arXiv:2410.13848, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, and Chen Change Loy. Openuni: A simple baseline for unified multimodal understanding and generation.arXiv preprint arXiv:2505.23661, 2025
-
[44]
Harmonizing visual representations for unified multimodal understanding and generation
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Zhonghua Wu, Qingyi Tao, Wentao Liu, Wei Li, and Chen Change Loy. Harmonizing visual representations for unified multimodal understanding and generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17739–17750, 2025
work page 2025
-
[45]
Teng Xiao, Zuchao Li, and Lefei Zhang. Omnibridge: Unified multimodal understanding, generation, and retrieval via latent space alignment.arXiv preprint arXiv:2509.19018, 2025
-
[46]
Reconstruction alignment improves unified multimodal models
Ji Xie, Trevor Darrell, Luke Zettlemoyer, and XuDong Wang. Reconstruction alignment improves unified multimodal models. InICLR, 2026
work page 2026
-
[47]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Zhendong Wang, Hao Liu, Bin Lin, Hao Li, Xue Xu, et al. Can understanding and generation truly benefit together–or just coexist?arXiv e-prints, pages arXiv–2509, 2025
work page 2025
-
[50]
Ling Yang, Xinchen Zhang, Ye Tian, Chenming Shang, Minghao Xu, Wentao Zhang, and Bin Cui. Hermesflow: Seamlessly closing the gap in multimodal understanding and generation.arXiv preprint arXiv:2502.12148, 2025
-
[51]
Songlin Yang, Xianghao Kong, and Anyi Rao. Pseudo-unification: Entropy probing reveals divergent information patterns in unified multimodal models.arXiv preprint arXiv:2604.10949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
work page 2024
-
[54]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
The latent space: Foundation, evolution, mechanism, ability, and outlook
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mechanism, ability, and outlook. arXiv preprint arXiv:2604.02029, 2026
-
[56]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[57]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 14
work page 2023
-
[58]
Shanshan Zhao, Xinjie Zhang, Jintao Guo, Jiakui Hu, Lunhao Duan, Minghao Fu, Yong Xien Chng, Guo-Hua Wang, Qing-Guo Chen, Zhao Xu, et al. Unified multimodal understanding and generation models: Advances, challenges, and opportunities.arXiv preprint arXiv:2505.02567, 2025
-
[59]
Unpaired image-to-image translation using cycle-consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017
work page 2017
-
[60]
Mengdan Zhu, Raasikh Kanjiani, Jiahui Lu, Andrew Choi, Qirui Ye, and Liang Zhao. Latentexplainer: Explaining latent representations in deep generative models with multi-modal foundation models.arXiv preprint arXiv:2406.14862, 2024
-
[61]
Uni-MMMU: A Massive Multi-discipline Multimodal Unified Benchmark
Kai Zou, Ziqi Huang, Yuhao Dong, Shulin Tian, Dian Zheng, Hongbo Liu, Jingwen He, Bin Liu, Yu Qiao, and Ziwei Liu. Uni-mmmu: A massive multi-discipline multimodal unified benchmark.arXiv preprint arXiv:2510.13759, 2025. 15 Appendix Contents 1 Introduction 1 2 Related Work 3 3 Method 3 3.1 Problem Formulation . . . . . . . . . . . . . . . . . . . . . . . ....
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.