Continuous Language Diffusion as a Decoder-Interface Problem
Pith reviewed 2026-06-27 18:25 UTC · model grok-4.3
The pith
Continuous diffusion language models succeed by entering a decoder basin where token recovery becomes simple.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
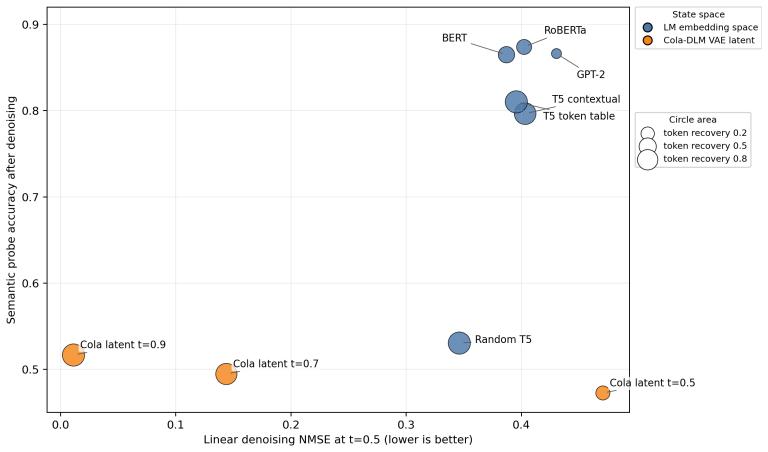
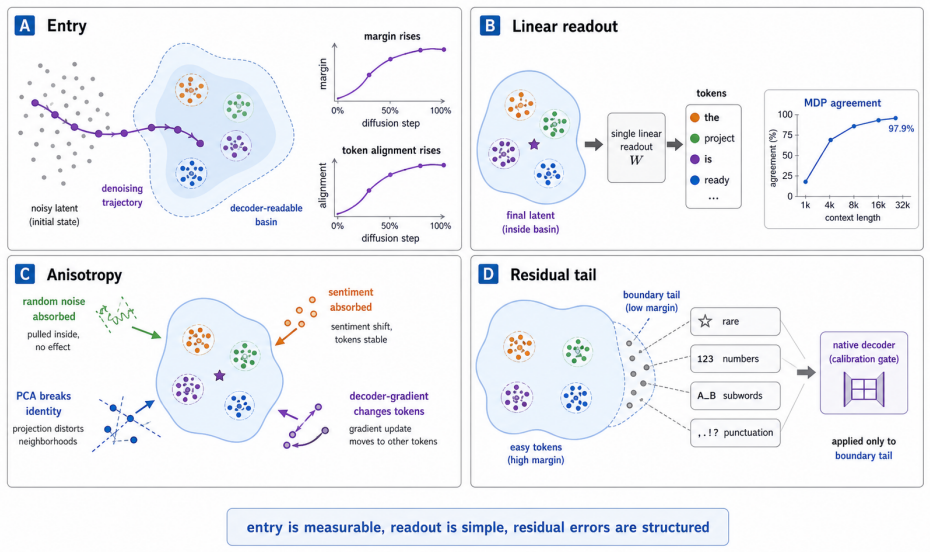
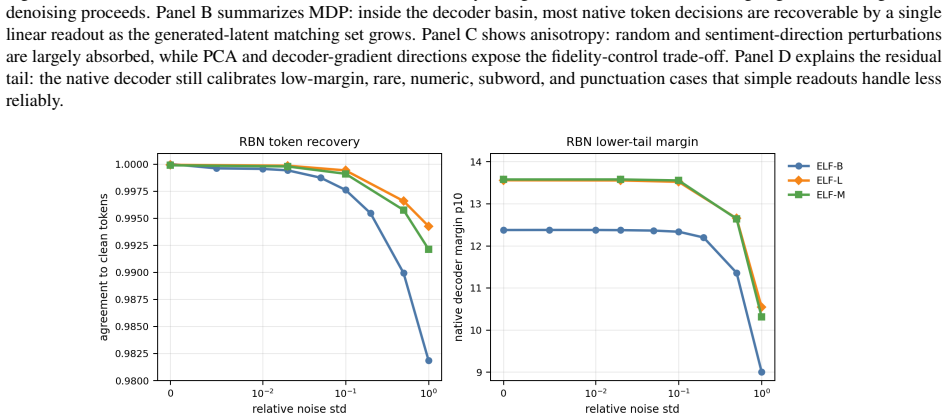
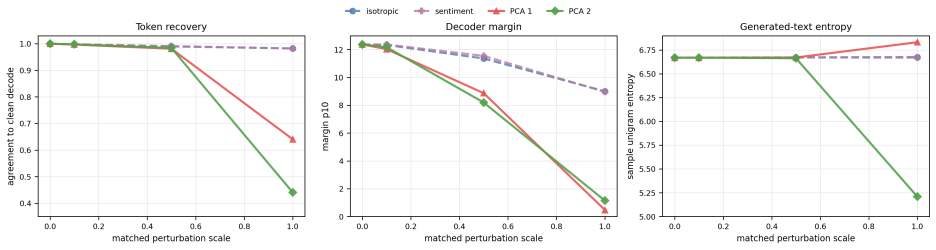
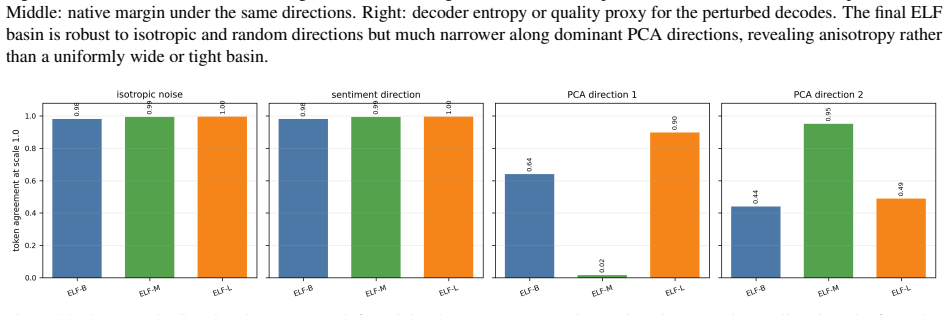
Auditing public ELF checkpoints reveals an interface phase diagram: early predictions are weakly readable, mid-trajectory disagreement marks a competition region, and late predictions enter a high-margin decoder basin. Once inside, token realization is surprisingly simple on generated ELF states: frozen T5 token-embedding lookup recovers 93--96% of native decoder decisions, and a single linear readout reaches 97.9% agreement at 32k samples, leaving an ≈1.1--1.2 perplexity gap in a structured residual tail. A decoder-margin bound explains why token recovery depends on margin and local decoder sensitivity, not latent error alone. Continuous and latent diffusion language models should therefore
What carries the argument
decoder-basin mechanism: latent regions reached during denoising where the native decoder reads stable tokens with high margin
If this is right
- Token recovery depends on margin and local decoder sensitivity rather than latent error magnitude alone.
- An explicit margin rule exits denoising roughly 17--28% earlier under conservative held-out gates.
- Low mean-squared error can discard linguistic content while low perplexity can reflect low-entropy collapse.
- Boundary checks confirm the same interface questions remain meaningful when state objects and decoders change across models.
Where Pith is reading between the lines
- Training objectives could be redesigned to accelerate entry into decoder basins instead of minimizing global latent error.
- Decoder agreement metrics might supplement or replace scalar perplexity in model comparisons.
- Similar basin dynamics could be tested in non-diffusion generative models that map continuous states to discrete tokens.
- Wider decoder basins might allow shorter trajectories and lower compute at inference time.
Load-bearing premise
The diagnostic protocol for denoisability, semantic recoverability, order sensitivity, decoder compatibility, and trajectory reliability accurately isolates the decoder-basin mechanism without bias from the specific choice of public checkpoints, ELF formulation, or T5-based decoder.
What would settle it
A controlled experiment in which trajectories are forced to low latent error without entering a high-margin decoder basin yet still produce fluent text at scale, or conversely enter the basin but fail to generate coherent output.
Figures

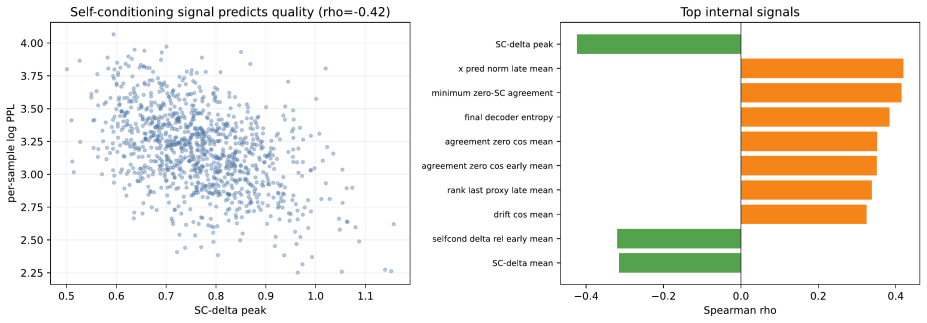
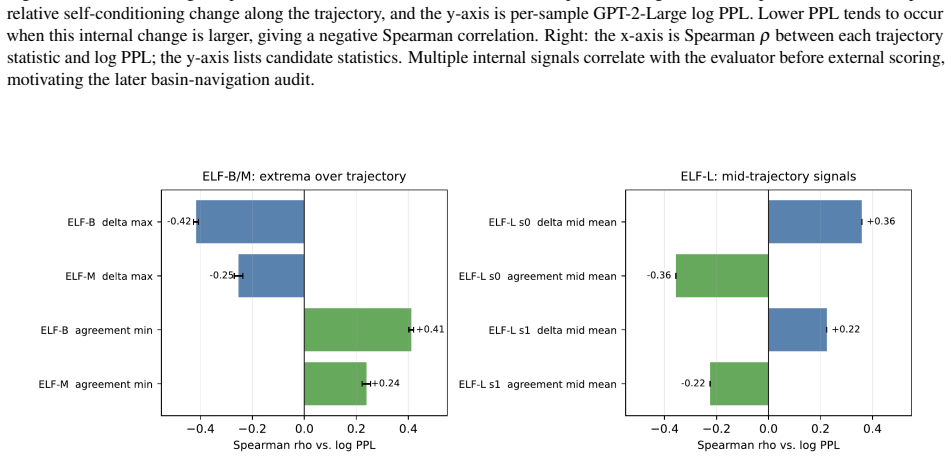
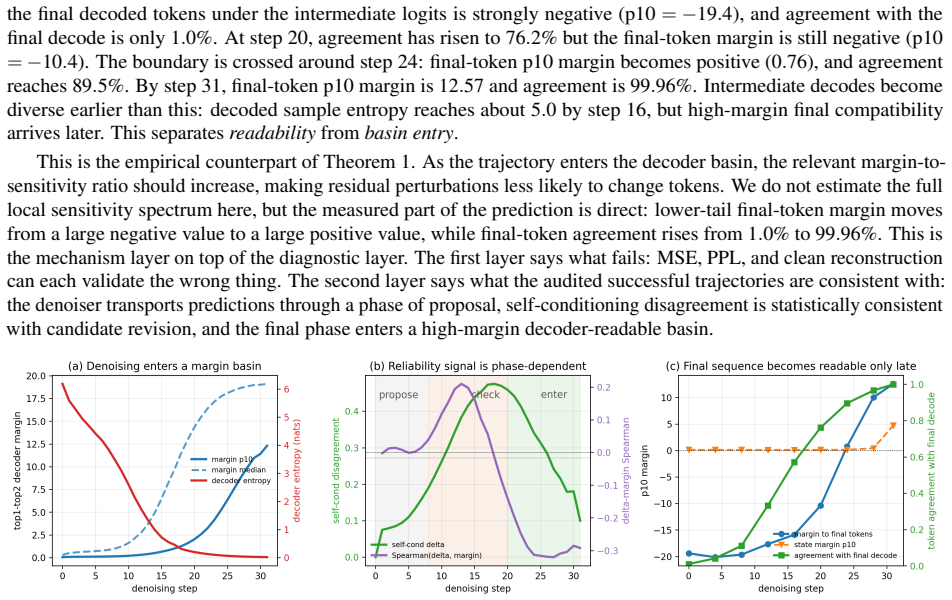
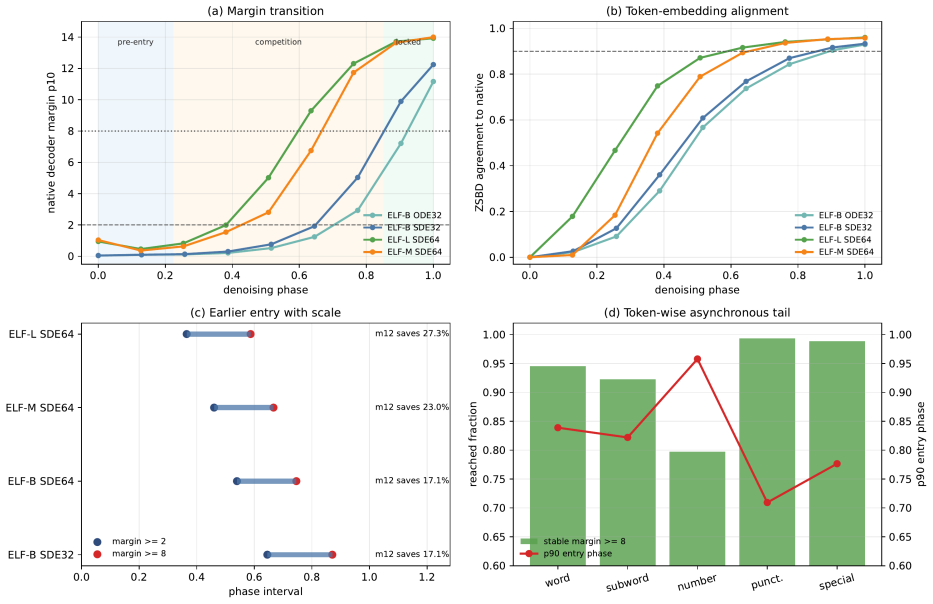
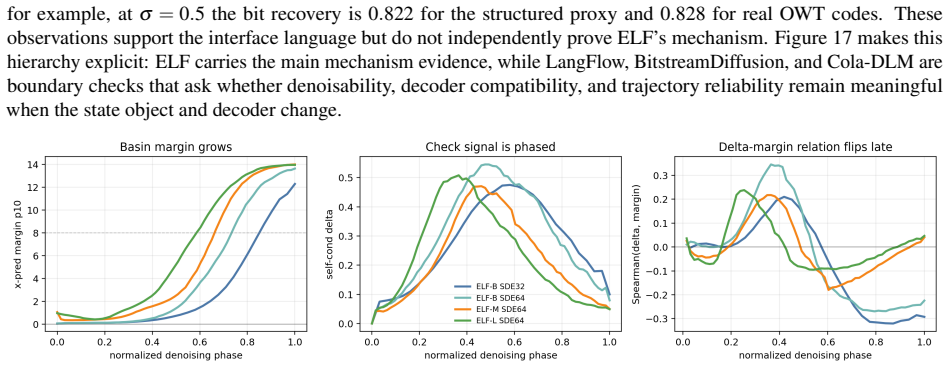
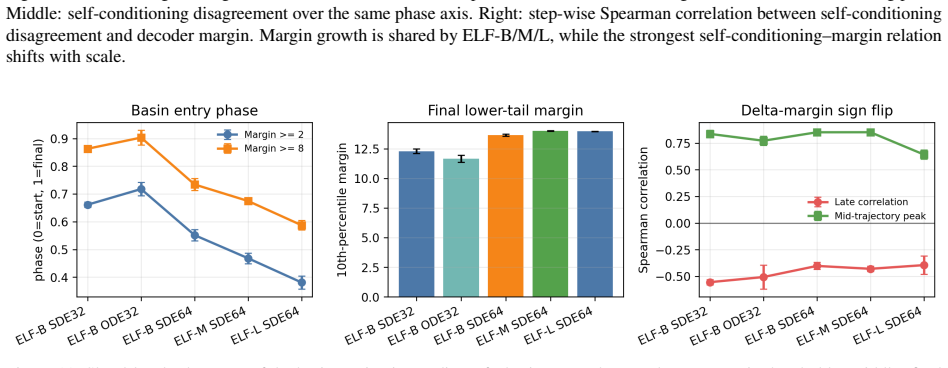
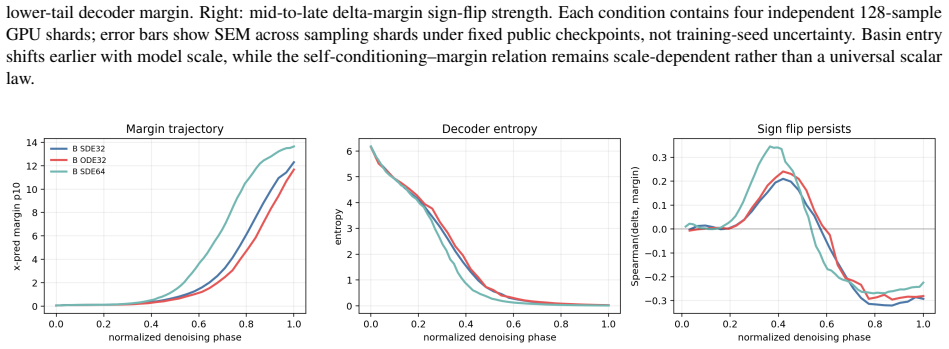





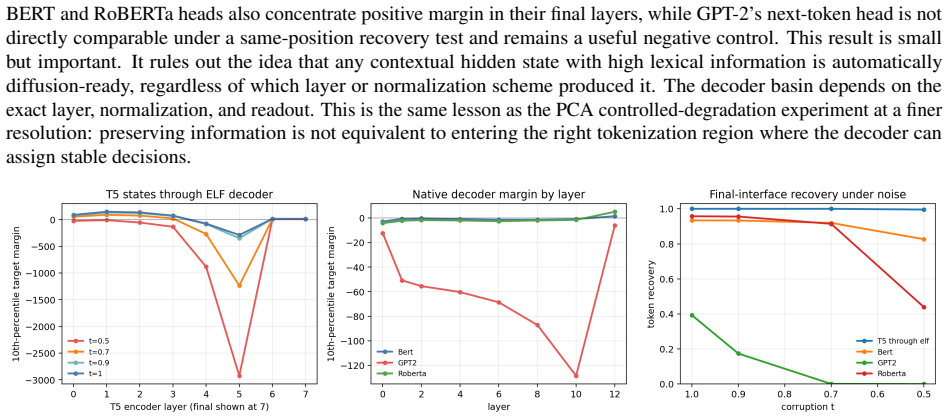

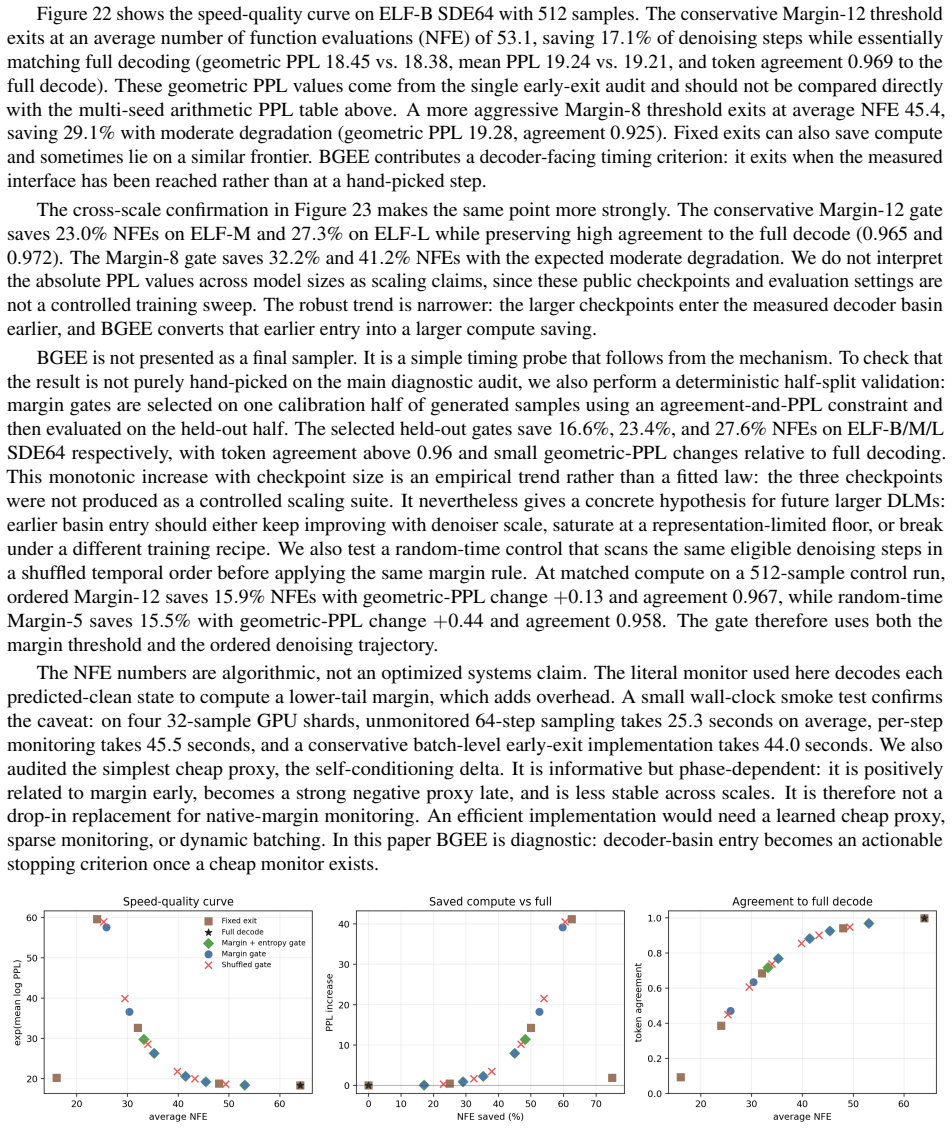
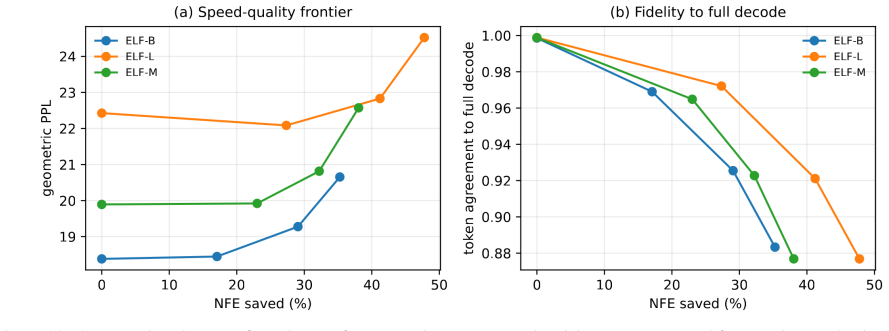


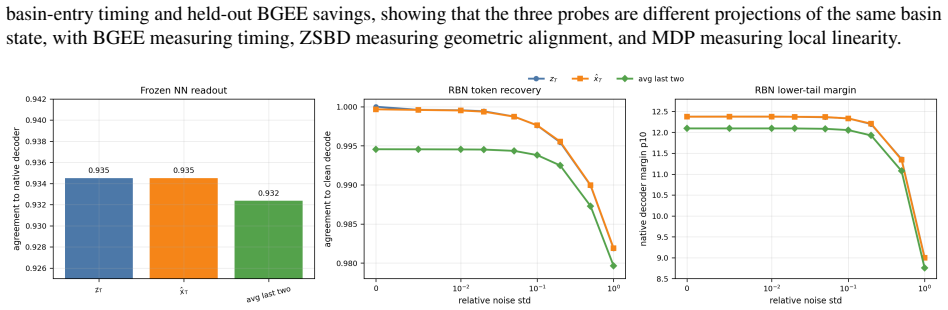
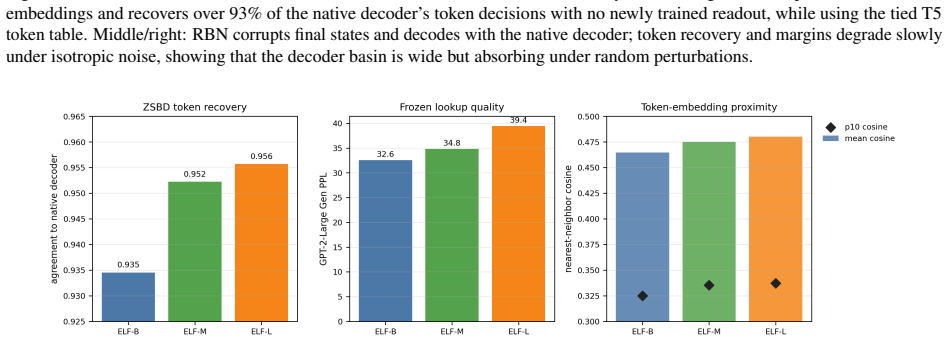
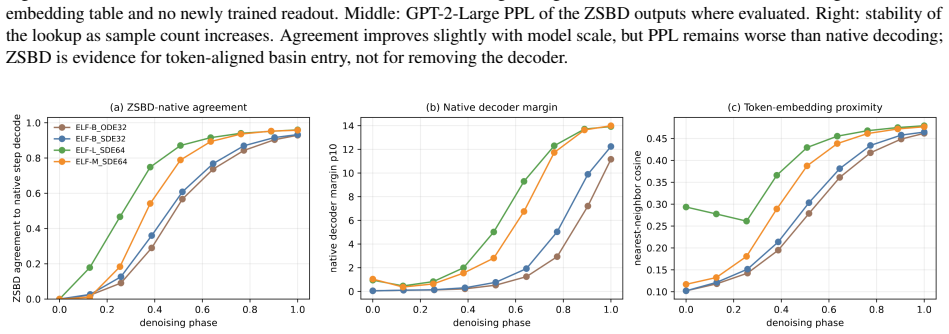
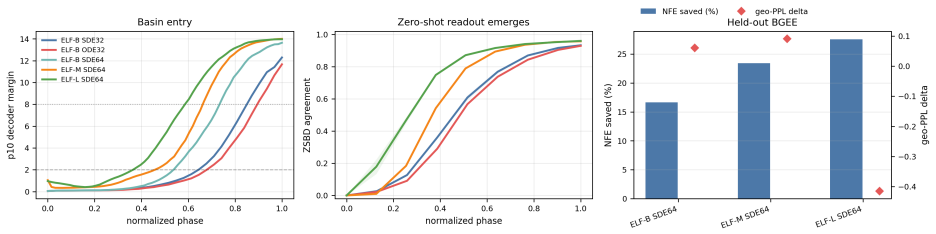


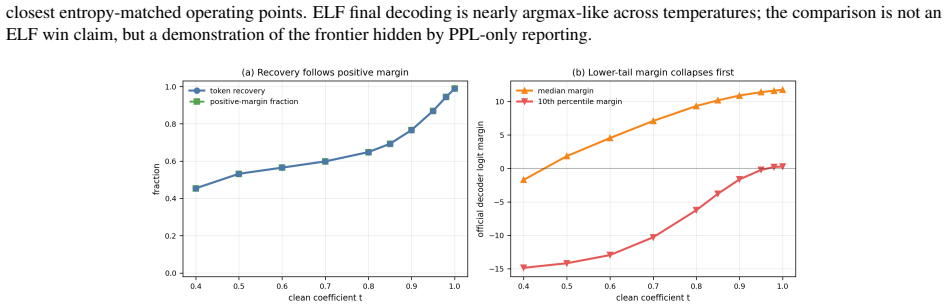
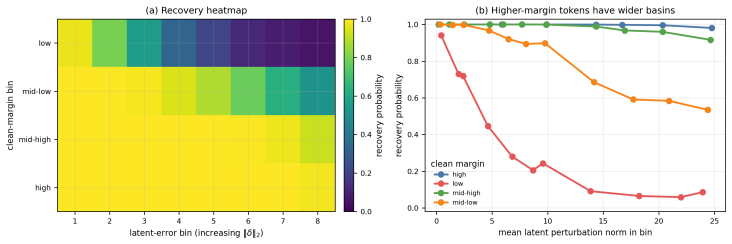
read the original abstract
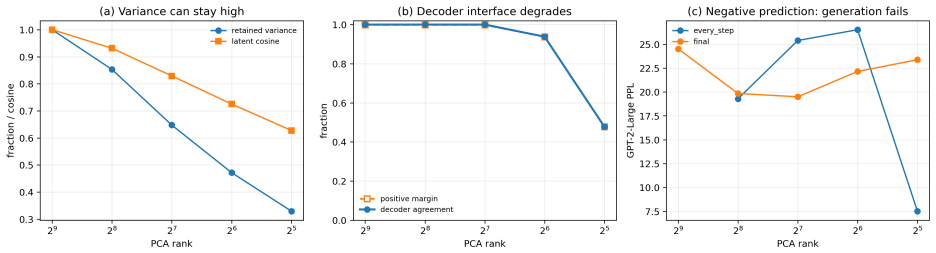
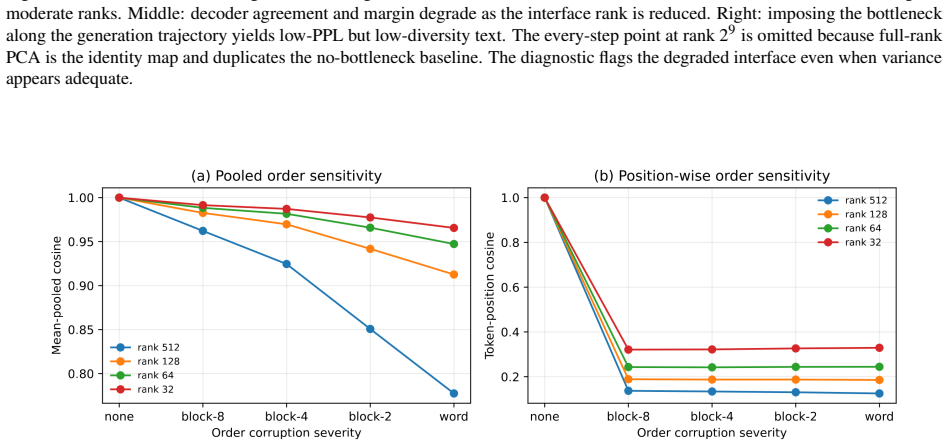
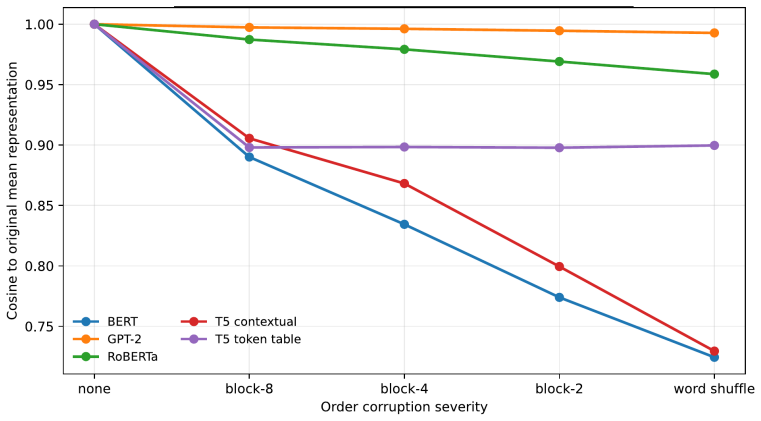
Gaussian-corrupted sentence embeddings have no direct linguistic interpretation, yet continuous diffusion language models can generate fluent text from them. We study this puzzle through Embedded Language Flows (ELF) and identify a decoder-basin mechanism: our evidence suggests that denoising becomes reliable when trajectories reach regions where the native decoder can read stable tokens. We introduce a diagnostic protocol for denoisability, semantic recoverability, order sensitivity, decoder compatibility, and trajectory reliability. It exposes failures hidden by scalar metrics: low mean-squared error can discard linguistic content, low perplexity can reflect low-entropy collapse, and clean latent reconstruction can coexist with a narrow decoder basin. A decoder-margin bound explains why token recovery depends on margin and local decoder sensitivity, not latent error alone. Auditing public ELF checkpoints reveals an interface phase diagram: early predictions are weakly readable, mid-trajectory disagreement marks a competition region, and late predictions enter a high-margin decoder basin. Once inside, token realization is surprisingly simple on generated ELF states: frozen T5 (Text-to-Text Transfer Transformer) token-embedding lookup recovers $93$--$96\%$ of native decoder decisions, and a single linear readout reaches $97.9\%$ agreement at 32k samples, leaving an $\approx1.1$--$1.2$ perplexity gap in a structured residual tail. Under conservative held-out gates, a margin rule exits roughly $17$--$28\%$ earlier in denoising steps under an explicit diagnostic monitor. Boundary checks on LangFlow, BitstreamDiffusion, and the Continuous Latent Diffusion Language Model (Cola-DLM) show that the same interface questions remain meaningful when the state object and decoder change. Continuous and latent diffusion language models should therefore be evaluated as representation-decoder systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that continuous diffusion language models operate through a decoder-basin mechanism: denoising trajectories in Embedded Language Flows (ELF) enter high-margin regions where native decoders can reliably read tokens. This is evidenced by audits of public checkpoints revealing an interface phase diagram (early weak readability, mid-trajectory competition, late high-margin basin), with frozen T5 token-embedding lookup recovering 93-96% of native decisions and a linear readout reaching 97.9% agreement (leaving a 1.1-1.2 perplexity gap). A diagnostic protocol for denoisability, semantic recoverability, order sensitivity, decoder compatibility, and trajectory reliability is introduced to expose limitations of scalar metrics, a decoder-margin bound is proposed, and boundary checks on LangFlow, BitstreamDiffusion, and Cola-DLM are performed to suggest broader relevance. The conclusion is that such models should be evaluated as representation-decoder systems.
Significance. If the decoder-basin mechanism and phase diagram hold under the diagnostic protocol, the work would meaningfully reframe evaluation of continuous and latent diffusion language models by shifting focus from latent reconstruction quality alone to interface properties between representations and decoders. The empirical recovery rates and margin-based early-exit rule could inform more efficient inference, while the critique of scalar metrics (MSE discarding content, low perplexity from collapse) provides a useful diagnostic lens. The boundary checks, though limited, indicate the interface questions are not ELF-specific.
major comments (2)
- [Abstract] Abstract (boundary checks paragraph): The claim that the decoder-basin mechanism is not an artifact of the T5-based ELF formulation rests on boundary checks showing that 'the same interface questions remain meaningful' for LangFlow, BitstreamDiffusion, and Cola-DLM. However, no quantitative token recovery rates, agreement percentages, or phase-diagram statistics are reported for these models (unlike the detailed 93-96% and 97.9% figures for ELF), leaving the generality of the mechanism load-bearing but under-supported.
- [Section describing the diagnostic protocol] Section describing the diagnostic protocol and auditing of public ELF checkpoints: The protocol is presented as isolating the decoder-basin without bias from checkpoint choice or T5 decoder, yet no details are given on quantitative phase definitions (e.g., exact margin thresholds separating early/mid/late), data exclusion rules, or statistical controls for the reported recovery rates and 17-28% earlier exits. This directly affects the reliability of the central empirical claim.
minor comments (1)
- The abstract reports an '≈1.1--1.2 perplexity gap in a structured residual tail' without specifying the base model, vocabulary size, or exact computation (e.g., whether it is conditional or unconditional perplexity), which reduces clarity for readers attempting to interpret the residual tail's significance.
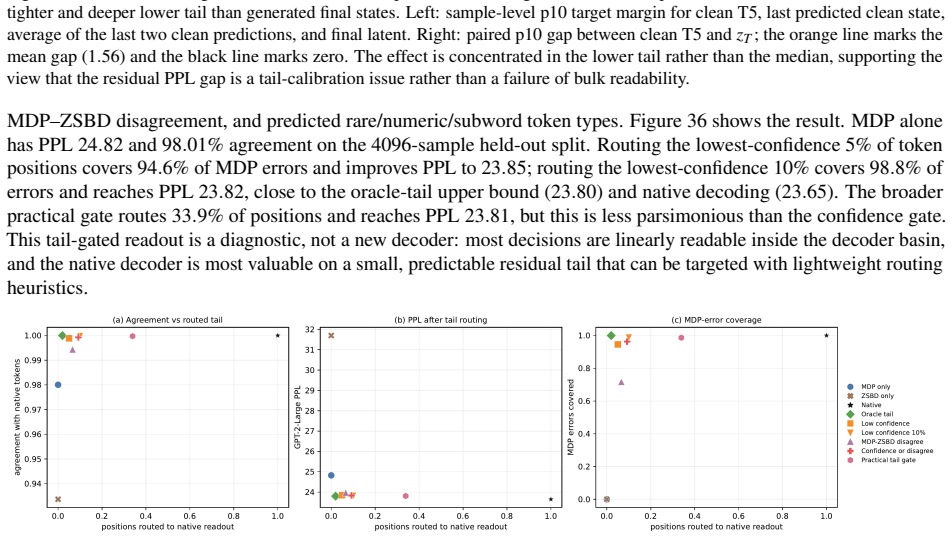
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications and proposed revisions where the manuscript can be strengthened without misrepresentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (boundary checks paragraph): The claim that the decoder-basin mechanism is not an artifact of the T5-based ELF formulation rests on boundary checks showing that 'the same interface questions remain meaningful' for LangFlow, BitstreamDiffusion, and Cola-DLM. However, no quantitative token recovery rates, agreement percentages, or phase-diagram statistics are reported for these models (unlike the detailed 93-96% and 97.9% figures for ELF), leaving the generality of the mechanism load-bearing but under-supported.
Authors: We agree the boundary checks are qualitative and illustrative rather than providing matching quantitative metrics for the other models. The manuscript uses them only to indicate that the diagnostic questions (denoisability, semantic recoverability, decoder compatibility) transfer when state objects and decoders differ, without claiming identical performance. To address the under-support concern, we will revise the abstract and boundary-checks section to explicitly qualify these as preliminary observations and note the limitation that full quantitative audits were not performed on the other models due to checkpoint and implementation differences. revision: yes
-
Referee: [Section describing the diagnostic protocol] Section describing the diagnostic protocol and auditing of public ELF checkpoints: The protocol is presented as isolating the decoder-basin without bias from checkpoint choice or T5 decoder, yet no details are given on quantitative phase definitions (e.g., exact margin thresholds separating early/mid/late), data exclusion rules, or statistical controls for the reported recovery rates and 17-28% earlier exits. This directly affects the reliability of the central empirical claim.
Authors: The referee correctly identifies that the current text describes the phases qualitatively (early weak readability, mid-trajectory competition, late high-margin basin) and reports aggregate recovery and early-exit figures without specifying exact margin thresholds, exclusion criteria, or statistical controls such as variance across checkpoints. We will revise the diagnostic-protocol section to add these details: explicit margin thresholds derived from the decoder-margin bound, sentence-length and quality exclusion rules, and basic statistical reporting (e.g., standard deviation of recovery rates). This directly improves the reliability of the empirical claims. revision: yes
Circularity Check
No circularity: claims rest on empirical audits of public checkpoints
full rationale
The paper presents observational findings from auditing ELF checkpoints, measuring token recovery rates (93-96% with frozen T5 embeddings, 97.9% with linear readout), and describing an interface phase diagram. No mathematical derivation, fitted parameter renamed as prediction, or self-citation chain is present in the text; the decoder-margin bound is invoked descriptively without equations that reduce the result to inputs by construction. Boundary checks on other models are cited to support generality, but the core evidence is direct measurement rather than tautological reduction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- margin threshold for early exit
axioms (1)
- domain assumption Standard assumptions about embedding spaces and decoder behavior in transformer language models
invented entities (2)
-
decoder-basin mechanism
no independent evidence
-
Embedded Language Flows (ELF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Consistent Diffusion Language Models
Hasan Amin, Yuan Gao, Yaser Souri, Subhojit Som, Ming Yin, Rajiv Khanna, and Xia Song. Consistent diffusion language models.arXiv preprint arXiv:2605.00161, 2026. doi: 10.48550/arXiv.2605.00161. URL https://arxiv.org/abs/2605.00161
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.00161 2026
-
[2]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, 50 and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. arXiv preprint arXiv:2503.09573, 2025. doi: 10.48550/arXiv.2503.09573. URL https://arxiv.org/abs/ 2503.09573
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.09573 2025
-
[3]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems, volume 34, pages 17981–17993. Curran Associates, Inc., 2021. URLhttps://proceedings.neurips.cc/paper_files/ paper/2021/file/958c530554f78bcd8e97125b70e697...
2021
-
[4]
Georgios Batzolis, Mark Girolami, and Luca Ambrogioni. Towards closing the autoregressive gap in language modeling via entropy-gated continuous bitstream diffusion.arXiv preprint arXiv:2605.07013, 2026. doi: 10.48550/arXiv.2605.07013. URLhttps://arxiv.org/abs/2605.07013
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07013 2026
-
[5]
Highly compressed tokenizer can generate without training
Lukas Lao Beyer, Tianhong Li, Xinlei Chen, Sertac Karaman, and Kaiming He. Highly compressed tokenizer can generate without training. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 4096–4114. PMLR, 2025. doi: 10.48550/arXiv.2506.08257. URLhttps://arxiv.org/abs/2506.08257
-
[6]
JAX: Composable transformations of python+numpy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, and Skye Wanderman-Milne. JAX: Composable transformations of python+numpy programs, 2018. URL https: //github.com/jax-ml/jax
2018
-
[7]
One billion word benchmark for measuring progress in statistical language modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling. InInterspeech, pages 2635–2639,
-
[8]
URL https://www.isca-archive.org/interspeech_ 2014/chelba14_interspeech.html
doi: 10.21437/INTERSPEECH.2014-564. URL https://www.isca-archive.org/interspeech_ 2014/chelba14_interspeech.html
-
[9]
Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu. Langflow: Continuous diffusion rivals discrete in language modeling.arXiv preprint arXiv:2604.11748, 2026. doi: 10. 48550/arXiv.2604.11748. URLhttps://arxiv.org/abs/2604.11748
Pith/arXiv arXiv 2026
-
[10]
DMax: Aggressive Parallel Decoding for dLLMs
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. DMax: Aggressive parallel decoding for dLLMs.arXiv preprint arXiv:2604.08302, 2026. doi: 10.48550/arXiv.2604.08302. URL https://arxiv. org/abs/2604.08302
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.08302 2026
-
[11]
Oscar Davis, Anastasiia Filippova, Pierre Ablin, Victor Turrisi, Amitis Shidani, Marco Cuturi, and Louis Béthune. Scaling categorical flow maps.arXiv preprint arXiv:2605.07820, 2026. doi: 10.48550/arXiv.2605.07820. URL https://arxiv.org/abs/2605.07820
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07820 2026
-
[12]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026. doi: 10.48550/arXiv.2602.04770. URLhttps://arxiv.org/abs/2602.04770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.04770 2026
-
[13]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volu...
2019
-
[14]
Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology. org/N19-1423/
-
[15]
How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 55–65,
2019
-
[16]
URLhttps://aclanthology.org/D19-1006/
doi: 10.18653/v1/D19-1006. URLhttps://aclanthology.org/D19-1006/
-
[17]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022. URL https: //jmlr.org/papers/v23/21-0998.html. 51
2022
-
[18]
Nemotron- labs-diffusion: A tri-mode language model unifying autoregressive, diffusion, and self-speculation decod- ing
Yonggan Fu, Lexington Whalen, Abhinav Garg, Chengyue Wu, Maksim Khadkevich, Nicolai Oswald, Enze Xie, Daniel Egert, Sharath Turuvekere Sreenivas, Shizhe Diao, Chenhan Yu, Ye Yu, Weijia Chen, Sa- jad Norouzi, Jingyu Liu, Shiyi Lan, Ligeng Zhu, Jin Wang, Jindong Jiang, Morteza Mardani, Mehran Maghoumi, Song Han, Ante Jukic, Nima Tajbakhsh, Jan Kautz, and Pa...
2026
-
[19]
Openwebtext corpus, 2019
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus, 2019. URL https://skylion007.github.io/ OpenWebTextCorpus/
2019
-
[20]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and Lingpeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models. InInternational Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2210.08933. URLhttps://arxiv.org/abs/2210.08933. ICLR 2023 camera ready
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.08933 2023
-
[21]
Continuous latent diffusion language model.arXiv preprint arXiv:2605.06548,
Hongcan Guo, Qinyu Zhao, Yian Zhao, Shen Nie, Rui Zhu, Qiushan Guo, Feng Wang, Tao Yang, Hengshuang Zhao, Guoqiang Wei, and Yan Zeng. Continuous latent diffusion language model.arXiv preprint arXiv:2605.06548,
-
[22]
Continuous Latent Diffusion Language Model
doi: 10.48550/arXiv.2605.06548. URLhttps://arxiv.org/abs/2605.06548
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.06548
-
[23]
SSD-LM: Semi-autoregressive simplex-based diffusion language model for text generation and modular control
Xiaochuang Han, Sachin Kumar, and Yulia Tsvetkov. SSD-LM: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11575–11596, 2023. doi: 10.18653/ v1/2023.acl-long.647. URLhttps://aclantholog...
2023
-
[24]
Locally Coherent Parallel Decoding in Diffusion Language Models
Michael Hersche, Nicolas Menet, Ronan Tanios, and Abbas Rahimi. Locally coherent parallel decoding in diffusion language models.arXiv preprint arXiv:2603.20216, 2026. doi: 10.48550/arXiv.2603.20216. URL https://arxiv.org/abs/2603.20216
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.20216 2026
-
[25]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. doi: 10.48550/arXiv.2207.12598. URLhttps://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.12598 2022
-
[26]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Infor- mation Processing Systems, volume 33, pages 6840–6851, 2020. doi: 10.48550/arXiv.2006.11239. URL https: //proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract. html
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2006.11239 2020
-
[27]
Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, and Kaiming He. ELF: Embedded language flows.arXiv preprint arXiv:2605.10938, 2026. doi: 10.48550/arXiv.2605.10938. URL https://arxiv.org/abs/2605.10938
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.10938 2026
-
[28]
TextLDM: Language Modeling with Continuous Latent Diffusion
Jiaxiu Jiang, Jingjing Ren, Wenbo Li, Bo Wang, Haoze Sun, Yijun Yang, Jianhui Liu, Yanbing Zhang, Shenghe Zheng, Yuan Zhang, Haoyang Huang, Nan Duan, and Wangmeng Zuo. TextLDM: Language modeling with continuous latent diffusion.arXiv preprint arXiv:2605.07748, 2026. doi: 10.48550/arXiv.2605.07748. URL https://arxiv.org/abs/2605.07748
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07748 2026
-
[29]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014. URLhttps://openreview.net/forum?id=33X9fd2-9FyZd
2014
-
[30]
Zahar Kohut, Severyn Shykula, Dmytro Khamula, Mykola Vysotskyi, Taras Rumezhak, and V olodymyr Karpiv. Just on time: Token-level early stopping for diffusion language models.arXiv preprint arXiv:2602.11133, 2026. doi: 10.48550/arXiv.2602.11133. URLhttps://arxiv.org/abs/2602.11133
-
[31]
Where Should Diffusion Enter a Language Model? Geometry-Guided Hidden-State Replacement
Injin Kong, Hyoungjoon Lee, and Yohan Jo. Where should diffusion enter a language model? geometry-guided hidden-state replacement.arXiv preprint arXiv:2605.14368, 2026. doi: 10.48550/arXiv.2605.14368. URL https://arxiv.org/abs/2605.14368
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.14368 2026
-
[32]
Learn from your own latents and not from tokens: A sample-complexity theory
Daniel J. Korchinski, Alessandro Favero, and Matthieu Wyart. Learn from your own latents and not from tokens: A sample-complexity theory.arXiv preprint arXiv:2605.27734, 2026. doi: 10.48550/arXiv.2605.27734. URL https://arxiv.org/abs/2605.27734. 52
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.27734 2026
-
[33]
Similarity of Neural Network Representations Revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019. doi: 10.48550/arXiv.1905.00414. URLhttps://proceedings.mlr.press/v97/kornblit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.00414 2019
-
[34]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Seunghoon Hong, Nicholas M. Boffi, and Jinwoo Kim. Flow map language models: One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813, 2026. doi: 10.48550/arXiv.2602.16813. URL https://arxiv. org/abs/2602.16813
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.16813 2026
-
[35]
DiLaDiff: Distilled Latent-Augmented Diffusion for Language Modeling
Jean-Marie Lemercier, Tomas Geffner, Karsten Kreis, Morteza Mardani, Arash Vahdat, and Ante Juki´c. DiLaDiff: Distilled latent-augmented diffusion for language modeling.arXiv preprint arXiv:2605.23605, 2026. doi: 10.48550/arXiv.2605.23605. URLhttps://arxiv.org/abs/2605.23605
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.23605 2026
-
[36]
A diversity-promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 110–119, 2016. doi: 10.18653/v1/N16-1014. URLhttps://aclantho...
-
[37]
Diffusion Language Models Know the Answer Before Decoding
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Soroush V osoughi, and Shiwei Liu. Diffusion language models know the answer before decoding.arXiv preprint arXiv:2508.19982, 2025. doi: 10.48550/arXiv.2508.19982. URLhttps://arxiv.org/abs/2508.19982
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19982 2025
-
[38]
A Survey on Diffusion Language Models
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025. doi: 10.48550/arXiv.2508.10875. URLhttps://arxiv.org/abs/2508.10875
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10875 2025
-
[39]
Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion- lm improves controllable text generation. InAdvances in Neural Information Processing Systems, 2022. doi: 10.48550/arXiv.2205.14217. URL https://papers.nips.cc/paper_files/paper/2022/hash/ 1be5bc25d50895ee656b8c2d9eb89d6a-Abstract-Conference.html
-
[40]
Xuanchen Li, Tianrui Wang, Yuheng Lu, Zikang Huang, Yu Jiang, Chenghan Lin, Chenrui Cui, Ziyang Ma, Xingyu Ma, Chunyu Qiang, Guochen Yu, Xie Chen, Longbiao Wang, and Jianwu Dang. Speech meets ELF: Audio conditional continuous-target diffusion for speech recognition and translation.arXiv preprint arXiv:2606.10368,
-
[41]
doi: 10.48550/arXiv.2606.10368. URLhttps://arxiv.org/abs/2606.10368
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.10368
-
[42]
J. Lin. Divergence measures based on the shannon entropy.IEEE Transactions on Information Theory, 37(1):145– 151, 1991. doi: 10.1109/18.61115. URLhttps://ieeexplore.ieee.org/abstract/document/61115
-
[43]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky T. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2210.02747. URLhttps://arxiv.org/abs/2210.02747v2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.02747 2023
-
[44]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.arXiv preprint arXiv:1907.11692, 2019. doi: 10.48550/arXiv.1907.11692. URLhttps://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.11692 1907
-
[45]
Justin Lovelace, Varsha Kishore, Chao Wan, Eliot Shekhtman, and Kilian Q. Weinberger. Latent dif- fusion for language generation. InAdvances in Neural Information Processing Systems, 2023. doi: 10.48550/arXiv.2212.09462. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ b2a2bd5d5051ff6af52e1ef60aefd255-Abstract-Conference.html
-
[46]
Measuring Temporal Linguistic Emergence in Diffusion Language Models
Harry Lu. Measuring temporal linguistic emergence in diffusion language models.arXiv preprint arXiv:2604.23235, 2026. doi: 10.48550/arXiv.2604.23235. URLhttps://arxiv.org/abs/2604.23235
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.23235 2026
-
[47]
DAWN: Dependency-aware fast inference for diffusion LLMs.arXiv preprint arXiv:2602.06953, 2026
Lizhuo Luo, Zhuoran Shi, Jiajun Luo, Zhi Wang, Shen Ren, Wenya Wang, and Tianwei Zhang. DAWN: Dependency-aware fast inference for diffusion LLMs.arXiv preprint arXiv:2602.06953, 2026. doi: 10.48550/ arXiv.2602.06953. URLhttps://arxiv.org/abs/2602.06953. 53
arXiv 2026
-
[48]
How to Train Your Latent Diffusion Language Model Jointly With the Latent Space
Viacheslav Meshchaninov, Alexander Shabalin, Egor Chimbulatov, Nikita Gushchin, Ilya Koziev, Alexander Korotin, and Dmitry Vetrov. How to train your latent diffusion language model jointly with the latent space.arXiv preprint arXiv:2605.07933, 2026. doi: 10.48550/arXiv.2605.07933. URL https://arxiv.org/abs/2605. 07933
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07933 2026
-
[49]
Amr Mohamed, Yang Zhang, Michalis Vazirgiannis, and Guokan Shang. Fast-decoding diffusion language models via progress-aware confidence schedules.arXiv preprint arXiv:2512.02892, 2025. doi: 10.48550/arXiv.2512. 02892. URLhttps://arxiv.org/abs/2512.02892
-
[50]
A corpus and cloze evaluation for deeper understanding of commonsense stories
Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. A corpus and cloze evaluation for deeper understanding of commonsense stories. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, p...
-
[51]
Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514, 2024
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514, 2024. doi: 10.48550/arXiv.2410.18514. URLhttps://arxiv.org/abs/2410.18514
-
[53]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-perfo...
2019
-
[54]
Llm layers immediately correct each other
Arjun Patrawala, Jiahai Feng, Erik Jones, and Jacob Steinhardt. Llm layers immediately correct each other. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://neurips.cc/ virtual/2025/poster/119727
2025
-
[55]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. doi: 10.48550/arXiv.2212.09748. URL https://openaccess.thecvf.com/content/ICCV2023/papers/Peebles_Scalable_Diffusion_ Models_with_Transformers_ICCV_2023_paper.pdf
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.09748 2023
-
[56]
Don't Retrain, Align: Adapting Autoregressive LMs to Diffusion LMs via Representation Alignment
Fred Zhangzhi Peng, Alexis Fox, Anru R. Zhang, and Alexander Tong. Don’t retrain, align: Adapting au- toregressive lms to diffusion lms via representation alignment.arXiv preprint arXiv:2605.06885, 2026. doi: 10.48550/arXiv.2605.06885. URLhttps://arxiv.org/abs/2605.06885
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.06885 2026
-
[57]
Mauve scores for generative models: Theory and practice.Journal of Machine Learning Research, 24(356):1–92, 2023
Krishna Pillutla, Lang Liu, John Thickstun, Sean Welleck, Swabha Swayamdipta, Rowan Zellers, Sewoong Oh, Yejin Choi, and Zaid Harchaoui. Mauve scores for generative models: Theory and practice.Journal of Machine Learning Research, 24(356):1–92, 2023. URLhttps://jmlr.org/papers/v24/23-0023.html
2023
-
[58]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019. URL https://cdn.openai.com/ better-language-models/language_models_are_unsupervised_multitask_learners.pdf
2019
-
[59]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020. URLhttps://jmlr.org/papers/v21/20-074.html
2020
-
[60]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992, 2019. doi: 10.18653/v1/D19-1410. URL https://aclanthology.org/D19-1410/. 54
-
[61]
A ConvNet for the 2020s , booktitle =
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. doi: 10.1109/CVPR52688.2022.01042. URL https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_Hi...
-
[62]
Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026
Daan Roos, Oscar Davis, Floor Eijkelboom, Michael Bronstein, Max Welling, ˙Ismail ˙Ilkan Ceylan, Luca Ambrogioni, and Jan-Willem van de Meent. Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026. doi: 10.48550/arXiv.2602.12233. URLhttps://arxiv.org/abs/2602.12233
-
[63]
Chiu, Alexander Rush, and V olodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion lan- guage models. InAdvances in Neural Information Processing Systems, 2024. doi: 10. 48550/arXiv.2406.07524. URL https://proceedings.nips.cc/paper_files/paper/2024/hash/ eb0b1...
arXiv 2024
-
[64]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T. Chiu, and V olodymyr Kuleshov. The diffusion duality. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 52584–52619. PMLR, 2025. doi: 10.48550/ arXiv.2506.10892. URLhttps://proceedings.mlr.pres...
arXiv 2025
-
[65]
Junzhe Shen, Jieru Zhao, Ziwei He, and Zhouhan Lin. CoDAR: Continuous diffusion language models are more powerful than you think.arXiv preprint arXiv:2603.02547, 2026. doi: 10.48550/arXiv.2603.02547. URL https://arxiv.org/abs/2603.02547
-
[66]
Dystruct: Dynamically Structured Diffusion Language Model Decoding via Bayesian Inference
Bian Sun, Kevin Zhai, Mubarak Shah, and Zhenyi Wang. Dystruct: Dynamically structured diffusion language model decoding via bayesian inference.arXiv preprint arXiv:2605.09820, 2026. doi: 10.48550/arXiv.2605.09820. URLhttps://arxiv.org/abs/2605.09820
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.09820 2026
-
[67]
Forward-Free Diffusion Language Models
Haotian Sun, Rushi Qiang, Yuqian Zheng, and Bo Dai. Forward-free diffusion language models.arXiv preprint arXiv:2606.08357, 2026. doi: 10.48550/arXiv.2606.08357. URLhttps://arxiv.org/abs/2606.08357
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.08357 2026
-
[68]
Is noise conditioning necessary for denoising generative models? InInternational Conference on Machine Learning, 2025
Qiao Sun, Zhicheng Jiang, Hanhong Zhao, and Kaiming He. Is noise conditioning necessary for denoising generative models? InInternational Conference on Machine Learning, 2025. URL https://proceedings. mlr.press/v267/sun25g.html
2025
-
[69]
K-Forcing: Joint Next-K-Token Decoding via Push-Forward Language Modeling
Zhiwei Tang, Yuanyu He, Yizheng Han, Wangbo Zhao, Jiasheng Tang, Fan Wang, and Bohan Zhuang. K-Forcing: Joint next-k-token decoding via push-forward language modeling.arXiv preprint arXiv:2606.10820, 2026. doi: 10.48550/arXiv.2606.10820. URLhttps://arxiv.org/abs/2606.10820
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.10820 2026
-
[70]
Entropy Aware Reward Guidance for Diffusion Language Model Alignment
Atula Tejaswi, Litu Rout, Constantine Caramanis, Sanjay Shakkottai, and Sujay Sanghavi. Entropy aware reward guidance for diffusion language model alignment.arXiv preprint arXiv:2602.05000, 2026. doi: 10.48550/arXiv. 2602.05000. URLhttps://arxiv.org/abs/2602.05000
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[71]
Runqian Wang and Kaiming He. Diffuse and disperse: Image generation with representation regularization.arXiv preprint arXiv:2506.09027, 2025. doi: 10.48550/arXiv.2506.09027. URL https://arxiv.org/abs/2506. 09027
-
[72]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAd- vances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022. doi: 10. 48550/arXiv.2201.11903. URL https://proceedings.neurips.cc/paper_files/...
Pith/arXiv arXiv 2022
-
[73]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art...
-
[74]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025. doi: 10.48550/arXiv.2505.22618. URL https://arxiv.org/abs/2505. 22618
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22618 2025
-
[75]
Xiaoyou Wu, Cheng-Jhih Shih, Binfei Ji, Yong Liu, and Yingyan Lin. BlockBatch: Multi-scale consensus decoding for efficient diffusion language model inference.arXiv preprint arXiv:2605.29233, 2026. doi: 10.48550/ arXiv.2605.29233. URLhttps://arxiv.org/abs/2605.29233
Pith/arXiv arXiv 2026
-
[76]
Zhongyu Xiao, Zhiwei Hao, Jianyuan Guo, Yong Luo, Jia Liu, Jie Xu, and Han Hu. Streaming-dllm: Accelerating diffusion LLMs via suffix pruning and dynamic decoding.arXiv preprint arXiv:2601.17917, 2026. doi: 10.48550/ arXiv.2601.17917. URLhttps://arxiv.org/abs/2601.17917
Pith/arXiv arXiv 2026
-
[77]
m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A massively multilingual pre-trained text-to-text transformer. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, 2021. doi: ...
-
[78]
B y T 5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. ByT5: Towards a token-free future with pre-trained byte-to-byte models.Transactions of the Association for Computational Linguistics, 10:291–306, 2022. doi: 10.1162/tacl_a_00461. URL https://aclanthology. org/2022.tacl-1.17/
-
[79]
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
Zhihan Yang, Wei Guo, Shuibai Zhang, Subham Sekhar Sahoo, Yongxin Chen, Arash Vahdat, Morteza Mardani, and John Thickstun. Continuous diffusion scales competitively with discrete diffusion for language.arXiv preprint arXiv:2605.18530, 2026. doi: 10.48550/arXiv.2605.18530. URLhttps://arxiv.org/abs/2605.18530
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.18530 2026
-
[80]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InThe Thirteenth International Conference on Learning Representations, 2025. doi: 10.48550/arXiv.2410.06940. URL https://arxiv.org/abs/2410.06940
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.06940 2025
-
[81]
Roll Out and Roll Back: Diffusion LLMs are Their Own Efficiency Teachers
Fanqin Zeng, Feng Hong, Geng Yu, Huangjie Zheng, Xiaofeng Cao, Ya Zhang, Bo Han, Yanfeng Wang, and Jiangchao Yao. Roll out and roll back: Diffusion LLMs are their own efficiency teachers.arXiv preprint arXiv:2605.16941, 2026. doi: 10.48550/arXiv.2605.16941. URLhttps://arxiv.org/abs/2605.16941
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.16941 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.