Tool-Schema Compression Enables Agentic RAG Under Constrained Context Budgets
Pith reviewed 2026-06-29 23:21 UTC · model grok-4.3
The pith
Tool-schema compression restores agentic RAG at 8K context budgets where uncompressed schemas overflow entirely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
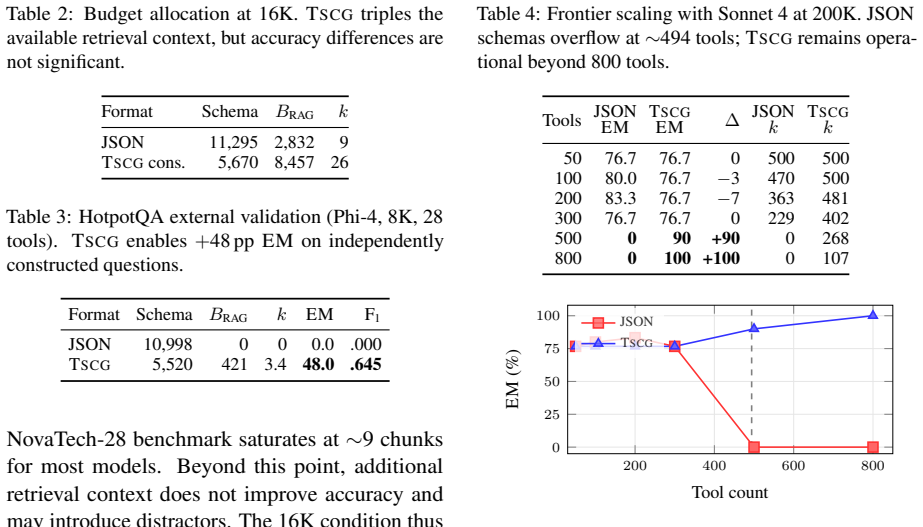
Applying TSCG conservative-profile compression to JSON tool schemas produces 44-50 percent token savings. At an 8K-token budget the uncompressed schemas overflow the window and yield only 2.6 percent average exact match, while the compressed versions restore functionality with a 20.5-point average lift across eight models. At 32K tokens the two formats produce statistically identical results, showing the benefit is strictly budget-driven. The same compression also raises the number of operable tools from roughly 494 to more than 800 before overflow occurs.
What carries the argument
TSCG conservative-profile compression, a method that reduces the token count of JSON tool schemas by 44-50 percent while keeping the information required for correct tool interpretation and invocation.
If this is right
- At any context budget where uncompressed schemas overflow, the compressed versions restore RAG functionality.
- When the budget is large enough for both formats, performance remains essentially unchanged.
- The same compression extends the operable tool count from approximately 494 to beyond 800.
- External checks on multi-hop questions confirm a 48-point exact-match gain under the overflow condition.
Where Pith is reading between the lines
- The same compression technique could be applied to any agent system that must keep large numbers of tool or API definitions inside a fixed context window.
- Hardware platforms with smaller native context lengths become viable for tool-augmented agents once schemas are compressed.
- Further gains might appear if compression is combined with retrieval methods that also prune irrelevant tool descriptions.
Load-bearing premise
The compression must preserve every detail the model needs to select and call the right tools without introducing new errors or capability loss.
What would settle it
A controlled run at 8K tokens in which models given the compressed schemas produce lower exact-match scores than models given the uncompressed schemas because they misinterpret or fail to invoke the tools.
Figures

read the original abstract
Agentic RAG systems that equip language models with dozens to hundreds of tool definitions face a critical resource conflict: tool schemas consume the same context window needed for retrieval-augmented generation. We present the first systematic study of this tool-context trade-off, evaluating 14 models spanning 1.5B-32B local models plus one frontier API model across 6,566 controlled API calls at three context budgets (8K, 16K, 32K) with 28 tool definitions. Applying TSCG conservative-profile compression (44-50% schema token savings), we observe a binary enablement effect: at 8K tokens, JSON-schema tool definitions overflow the context window entirely, yielding near-zero EM (2.6% average), while compressed schemas restore RAG functionality with +20.5 pp average exact-match lift across all eight models (+24.7 pp among the six exhibiting full enablement). At 32K -- where both formats fit -- four of five tested models show delta <= 1 pp, confirming the effect is purely budget-driven. External validation on HotpotQA (50 multi-hop questions) shows +48 pp EM under the same overflow scenario. Frontier scaling tests demonstrate that JSON schemas overflow at ~494 tools while compressed schemas remain operational beyond 800 tools. Our results establish tool-schema compression as a necessary infrastructure layer for agentic RAG in constrained-context deployments. All code, data, and checkpoints are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Tool-Schema Compression (TSCG) with conservative-profile compression achieves 44-50% token savings on JSON tool schemas, producing a binary enablement effect for agentic RAG: at 8K context, uncompressed schemas overflow and yield near-zero exact-match (2.6% average), while compressed schemas restore functionality with +20.5 pp average EM lift (and +24.7 pp on the six models showing full enablement). The effect is isolated as budget-driven by 32K controls (delta <=1 pp on four of five models), external HotpotQA validation (+48 pp), and scaling tests (JSON overflows at ~494 tools; compressed remains operational beyond 800). Results rest on 6,566 controlled calls across 14 models (1.5B-32B plus one frontier) with 28 tool definitions; all code, data, and checkpoints are public.
Significance. If the semantic-preservation claim holds, the work supplies the first systematic quantification of the tool-context trade-off and demonstrates a practical, low-overhead mitigation that is directly actionable for constrained deployments. Strengths include the large-scale controlled design, public artifacts, and the 32K control that falsifies information-loss explanations for the 8K lift.
minor comments (3)
- [Abstract] Abstract: the text states evaluation of 14 models yet reports the main enablement statistics on eight models; explicitly identify the eight-model subset and the selection criterion.
- [Abstract] Abstract: the phrase 'across all eight models' for the +20.5 pp lift should be accompanied by the per-model breakdown or at least the range to allow readers to assess uniformity.
- The manuscript should state the precise token counts used for the 8K/16K/32K budgets and confirm whether they are measured after compression or before.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity; purely empirical measurements
full rationale
The paper reports controlled experiments measuring token savings from TSCG compression and exact-match lifts at fixed context budgets (8K/16K/32K) across 14 models and 6,566 calls. No derivations, equations, fitted parameters, or predictions appear; the enablement effect is isolated by direct comparison (overflow vs. fit) and 32K control showing near-zero delta. External validations (HotpotQA, scaling to 800+ tools) are independent tests. No self-citation chains, ansatzes, or self-definitional steps are present. This is a standard empirical result with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conservative compression of tool schemas preserves sufficient semantic information for correct model interpretation and tool use.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic . 2024. Introducing the Model Context Protocol . https://www.anthropic.com/news/model-context-protocol. Open standard for connecting AI assistants to data sources. Accessed: 2026-04-28
2024
-
[4]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self- RAG : Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations (ICLR). ArXiv:2310.11511
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Atlassian Labs . 2026. mcp-compressor: An MCP server wrapper for reducing tokens consumed by MCP tools . https://github.com/atlassian-labs/mcp-compressor. Accessed: 2026-04-28
2026
-
[6]
Jacob Cohen. 1988. Statistical Power Analysis for the Behavioral Sciences, 2nd edition. Lawrence Erlbaum Associates, Hillsdale, NJ
1988
-
[7]
Lutfi Eren Erdogan, Nicholas Lee, Siddharth Jha, Sehoon Kim, Ryan Tabrizi, Suhong Moon, Coleman Richard Charles Hooper, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. 2024. https://doi.org/10.18653/v1/2024.emnlp-demo.9 T iny A gent: Function calling at the edge . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Proces...
-
[8]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2024. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997. V2, comprehensive RAG survey
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. In Journal of Machine Learning Research, volume 24, pages 1--43. ArXiv:2208.03299
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [10]
- [11]
-
[12]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459--9474. ArXi...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023. https://aclanthology.org/2023.emnlp-main.391/ Compressing context to enhance inference efficiency of large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342--6353. Association for Computational Linguistics
2023
-
[14]
Lahoti, A., Li, K., Chen, B., Wang, C., Bick, A., Kolter, J
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the ACL, 12:157--173. ArXiv:2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
arXiv preprint arXiv:2403.12968 , year=
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor R \"u hle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. 2024. LLMLingua-2 : Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of ACL 2024, pages 963--981. ArXiv:2403.12968
-
[16]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. The Berkeley Function Calling Leaderboard (BFCL) : From tool use to agentic evaluation of large language models. In Proceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 of Proceedings of Machine Learn...
2025
-
[17]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. Gorilla: Large language model connected with massive API s. In Advances in Neural Information Processing Systems, volume 37. ArXiv:2305.15334
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ToolLLM : Facilitating large language models to master 16000+ real-world API s. In The Twelfth International Conference on...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Furkan Sakizli. 2026. https://doi.org/10.48550/arXiv.2605.04107 TSCG : Deterministic tool-schema compilation for agentic LLM deployments . arXiv preprint arXiv:2605.04107. Companion paper (Paper 1)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.04107 2026
-
[20]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2024. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36. ArXiv:2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345. ArXiv:2308.11432
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Frank Wilcoxon. 1945. Individual comparisons by ranking methods. Biometrics Bulletin, 1(6):80--83
1945
-
[23]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/v1/D18-1259 H otpot QA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380
-
[24]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. The Eleventh International Conference on Learning Representations (ICLR). ArXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.