What makes a harness a harness: necessary and sufficient conditions for an agent harness
Pith reviewed 2026-06-27 15:14 UTC · model grok-4.3
The pith
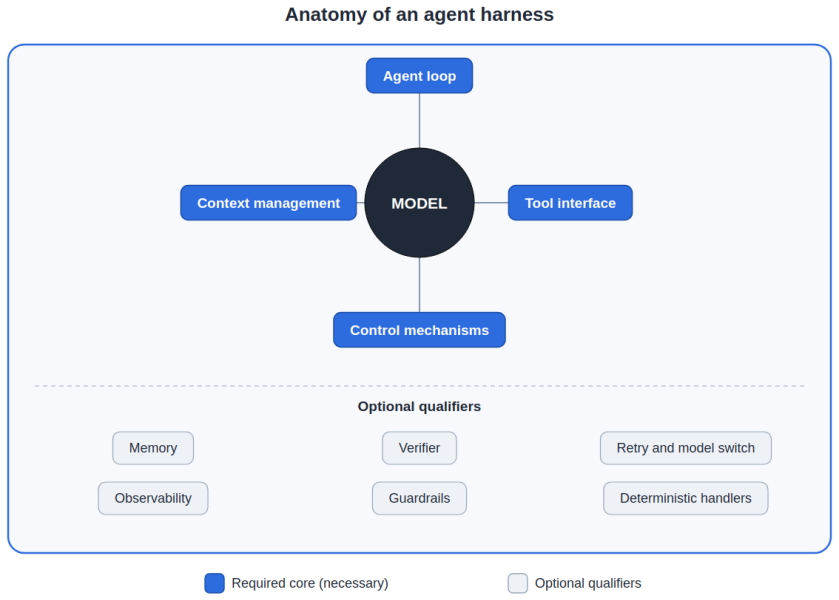
A system is an agent harness exactly when it wraps a language model to enable actions on a code repository under stated inclusion and exclusion rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proposes a constitutive definition that states the necessary and sufficient conditions for a system to be an agent harness, operationalizes it as an inclusion and exclusion test, and shows consistent application to six real harnesses (Claude Code, Codex CLI, Aider, Cline, OpenHands, and SWE-agent) and to deliberate edge cases.
What carries the argument
The constitutive definition that states necessary and sufficient conditions for an agent harness and its operationalization as an inclusion and exclusion test.
If this is right
- The definition draws a boundary against an agent framework, an agent SDK, an IDE plugin, an eval harness, and an orchestrator.
- The test classifies the six examined systems and the edge cases without contradiction.
- The definition supplies a shared vocabulary that can guide engineering practice.
- The definition enables scientific comparison of agentic systems.
- The paper closes with a research agenda organized by design tension axes.
Where Pith is reading between the lines
- The same test could be applied to newly released coding-agent products to decide whether they qualify.
- Teams adopting the definition might standardize how they document tool boundaries in their own documentation.
- The conditions could serve as a starting point for formal specifications of agent interfaces.
Load-bearing premise
The chosen grey-literature sources and persistent-identifier works accurately represent the full range of current usage and supply the right conceptual boundaries.
What would settle it
A widely adopted system labeled an agent harness that fails the inclusion test, or a system never labeled one that passes it, would show the definition does not track actual usage.
Figures




read the original abstract
The term agent harness now circulates widely in software engineering with generative artificial intelligence. It names the layer that wraps a language model and turns it into a coding agent able to act on a repository. The usage is loose and polysemous. Sometimes the term denotes the whole product (Claude Code, Codex CLI); sometimes it denotes the evaluation scaffold that runs an agent against tasks (the SWE-bench harness); sometimes it gets conflated with an agent framework, an SDK, an IDE plugin, or an orchestrator. What is missing is a reference definition that works as an instrument, one that includes and excludes cases consistently. We build that definition through a conceptual analysis that combines works with persistent identifiers and primary grey-literature sources, such as official documentation, glossaries, and engineering reports. We reconstruct the genealogy of the term, from the horse's tack to the classic test harness, to the machine-learning evaluation harness, and finally to the agent harness. We then propose a constitutive definition that states the necessary and sufficient conditions for a system to be an agent harness, we operationalize it as an inclusion and exclusion test, and we draw the boundary of the concept against an agent framework, an agent SDK, an IDE plugin, an eval harness, and an orchestrator. We apply the definition to six real harnesses (Claude Code, Codex CLI, Aider, Cline, OpenHands, and SWE-agent) and to deliberate edge cases; the test includes and excludes consistently. We close with a research agenda organized by design tension axes. The contribution is an operational definition of agent harness, with a shared vocabulary, able to guide engineering practice and the scientific comparison of agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a constitutive definition for an 'agent harness' in generative-AI coding agents. It reconstructs the term's genealogy from horse tack through classic test harnesses and ML evaluation harnesses, derives necessary and sufficient conditions from persistent-identifier works and primary grey-literature sources (official documentation, glossaries, engineering reports), operationalizes the definition as an inclusion/exclusion test, draws boundaries against agent frameworks, SDKs, IDE plugins, eval harnesses and orchestrators, applies the test to six systems (Claude Code, Codex CLI, Aider, Cline, OpenHands, SWE-agent) plus edge cases with consistent results, and closes with a research agenda organized by design-tension axes.
Significance. If the necessary-and-sufficient conditions can be shown to be fixed independently of the six systems, the work would supply a useful shared instrument for standardizing terminology, guiding engineering practice, and enabling scientific comparison of agentic coding systems. The explicit genealogy reconstruction and the attempt at consistent operationalization are strengths that could support reproducible classification if circularity is addressed.
major comments (2)
- [Conceptual Analysis / Source Selection] The conceptual-analysis section relies on primary grey-literature sources that include official documentation and reports of the very systems later classified (Claude Code, Codex CLI, Aider, Cline, OpenHands, SWE-agent). Because the necessary-and-sufficient conditions are extracted from these sources before the inclusion/exclusion test is applied, the reported consistency of the test does not independently establish necessity and sufficiency; it risks confirming a definition fitted to the examples.
- [Boundary Drawing] The boundary-drawing step against frameworks, SDKs, IDE plugins, eval harnesses and orchestrators is presented as following directly from the genealogy and grey-literature analysis, yet no explicit protocol is given showing that the six harnesses were excluded from source selection or boundary calibration. This leaves the central claim that the definition is constitutive and non-circular load-bearing and unverified.
minor comments (2)
- [Genealogy Reconstruction] The genealogy reconstruction paragraph could add a short table mapping each historical stage to the specific persistent-identifier or grey-literature citation used, to make the transition points traceable.
- [Application to Six Harnesses and Edge Cases] In the application section, the edge-case exclusions would be clearer if each decision were cross-referenced to the exact clause of the constitutive definition rather than summarized narratively.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the opportunity to clarify our approach. The comments raise valid points about source independence and protocol transparency in our conceptual analysis. We respond to each major comment below, defending the manuscript's core claims while agreeing to strengthen the presentation with additional methodological detail where it improves rigor without altering the substantive findings.
read point-by-point responses
-
Referee: [Conceptual Analysis / Source Selection] The conceptual-analysis section relies on primary grey-literature sources that include official documentation and reports of the very systems later classified (Claude Code, Codex CLI, Aider, Cline, OpenHands, SWE-agent). Because the necessary-and-sufficient conditions are extracted from these sources before the inclusion/exclusion test is applied, the reported consistency of the test does not independently establish necessity and sufficiency; it risks confirming a definition fitted to the examples.
Authors: The genealogy begins with persistent-identifier works on horse tack, classic test harnesses, and ML evaluation harnesses, from which the necessary and sufficient conditions are first abstracted. Grey-literature sources, including those from the six systems, serve only to illustrate current usage and to demonstrate consistent application of the already-derived conditions; they are not the basis for extracting the conditions themselves. The consistency result therefore functions as external validation rather than self-confirmation. To eliminate any ambiguity about the sequence, the revised manuscript will add an explicit subsection on source-selection chronology and criteria that separates the derivation phase from the application phase. revision: partial
-
Referee: [Boundary Drawing] The boundary-drawing step against frameworks, SDKs, IDE plugins, eval harnesses and orchestrators is presented as following directly from the genealogy and grey-literature analysis, yet no explicit protocol is given showing that the six harnesses were excluded from source selection or boundary calibration. This leaves the central claim that the definition is constitutive and non-circular load-bearing and unverified.
Authors: The boundaries are logical consequences of the necessary-and-sufficient conditions established in the genealogy section, which was completed prior to any examination of the six systems. No iterative calibration against those systems took place. We nevertheless agree that an explicit protocol would make the independence claim easier to verify. The revision will therefore insert a concise protocol subsection that documents the source-selection steps, the exclusion of the six systems from the initial derivation, and the direct derivation of boundaries from the conditions. revision: yes
Circularity Check
No circularity: definition constructed from external sources prior to classification
full rationale
The paper reconstructs a genealogy and constitutive definition from persistent-identifier works plus grey-literature sources, then applies the resulting inclusion/exclusion test to six systems. No quoted step shows the necessary-and-sufficient conditions being defined in terms of the target harnesses themselves, nor any fitted parameter renamed as a prediction, nor a load-bearing self-citation chain. The derivation therefore remains self-contained against the listed external sources.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The genealogy reconstructed from horse tack, test harnesses, ML evaluation harnesses, and current agent documentation supplies the correct conceptual ancestry for the term.
- domain assumption Grey-literature sources (official documentation, glossaries, engineering reports) together with works carrying persistent identifiers are sufficient to ground the definition.
Reference graph
Works this paper leans on
-
[1]
MASAI: Modular Architecture for Software-engineering AI Agents, 2024
Daman Arora, Atharv Sonwane, Nalin Wadhwa, Abhav Mehrotra, Saiteja Utpala, Ramakr- ishna Bairi, Aditya Kanade, and Nagarajan Natarajan. MASAI: Modular Architecture for Software-engineering AI Agents, 2024. Preprint, arXiv. doi:10.48550/arXiv.2406.11638
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073 2022
-
[3]
Identifying and Mitigating the Security Risks of Generative AI, 2023
Clark Barrett, Brad Boyd, Elie Burzstein, Nicholas Carlini, Brad Chen, Jihye Choi, Am- rita Roy Chowdhury, Mihai Christodorescu, Anupam Datta, Soheil Feizi, Kathleen Fisher, Tatsunori Hashimoto, Dan Hendrycks, Somesh Jha, Daniel Kang, Florian Kerschbaum, Eric Mitchell, John Mitchell, Zulfikar Ramzan, Khawaja Shams, Dawn Song, Ankur Taly, and Diyi Yang. Id...
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2020
-
[5]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. Sparks of Artificial General Intelligence: Early experiments with GPT-4, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.12712
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.12712 2023
-
[6]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A Survey on Evaluation of Large Language Models, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.03109. 15
-
[7]
CodeR: Issue Resolving with Multi- Agent and Task Graphs, 2024
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, Jie Wang, Xiao Cheng, Guangtai Liang, Yuchi Ma, Pan Bian, Tao Xie, and Qianxiang Wang. CodeR: Issue Resolving with Multi- Agent and Task Graphs, 2024. Preprint, arXiv. doi:10.48550/arXiv.2406.01304
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mo- hammad Bavari...
-
[9]
Evaluating Large Language Models Trained on Code
Preprint, arXiv. doi:10.48550/arXiv.2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[10]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.10848
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10848 2023
-
[11]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents, 2024. Preprint, arXiv. doi:10.48550/arXiv.2406.13352
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.13352 2024
-
[12]
Mind2Web: Towards a Generalist Agent for the Web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a Generalist Agent for the Web, 2023. Preprint, arXiv. doi:10.48550/arXiv.2306.06070
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.06070 2023
-
[13]
Self-collaboration Code Generation via ChatGPT, 2023
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. Self-collaboration Code Generation via ChatGPT, 2023. Preprint, arXiv. doi:10.48550/arXiv.2304.07590
-
[14]
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang, Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.04468 2024
-
[15]
AgentScope: AFlexible yet Robust Multi-Agent Platform, 2024
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, Liuyi Yao, Hongyi Peng, Zeyu Zhang, Lin Zhu, ChenCheng, HongzhuShi, YaliangLi, BolinDing, andJingrenZhou. AgentScope: AFlexible yet Robust Multi-Agent Platform, 2024. Preprint, arXiv. doi:10.48550/arXiv.2402.14034
-
[16]
Thomas R. Gruber. Toward principles for the design of ontologies used for knowl- edge sharing.International Journal of Human-Computer Studies, 43(5-6):907–928, 1995. doi:10.1006/ijhc.1995.1081
-
[17]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, ZiliWang, StevenKaShing Yau, Zijuan Lin, LiyangZhou, ChenyuRan, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.00352. 16
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.00352 2023
-
[18]
Large Language Models for Software Engineering: A Systematic Literature Review, 2023
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large Language Models for Software Engineering: A Systematic Literature Review, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.10620
-
[19]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations, 2023. Preprint, arXiv. doi:10.48550/arXiv.2312.06674
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.06674 2023
-
[20]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2023
-
[21]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, 2020. Preprint, arXiv. doi:10.48550/arXiv.2005.11401
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.11401 2020
-
[22]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.17760
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17760 2023
-
[23]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs, 2023. Preprint, arXiv. doi:10.48550/arXiv.2304.08244
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.08244 2023
-
[24]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.01210
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.01210 2023
-
[25]
Large Language Model-Based Agents for Software Engineering: A Survey
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large Language Model-Based Agents for Software Engineering: A Survey, 2024. Preprint, arXiv. doi:10.48550/arXiv.2409.02977
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.02977 2024
-
[26]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the Middle: How Language Models Use Long Contexts,
-
[27]
In-Context Retrieval-Augmented Language Models , journal =
Preprint, arXiv. doi:10.48550/arXiv.2307.03172
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.03172
-
[28]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as Agents, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.03688
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03688 2023
-
[29]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, Leo Yu Zhang, and Yang Liu. Prompt Injection attack against LLM-integrated Applications, 2023. Preprint, arXiv. doi:10.48550/arXiv.2306.05499
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05499 2023
-
[30]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegr- effe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bod- hisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative Refinement with Self-Feedback, 2023. Preprint, arXiv. doi:10.48550/arXiv.2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[31]
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey, 2024. Preprint, arXiv. doi:10.48550/arXiv.2404.11584. 17
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.11584 2024
-
[32]
A Survey of Context Engineering for Large Language Models
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. A Survey of Context Engineering for Large Language Models, 2025. Preprint, arXiv. doi:10.48550/arXiv.2507.13334
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.13334 2025
-
[33]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[34]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as Operating Systems, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[35]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior,
-
[36]
Generative Agents: Interactive Simulacra of Human Behavior
Preprint, arXiv. doi:10.48550/arXiv.2304.03442
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.03442
-
[37]
Gorilla: Large Language Model Connected with Massive APIs
ShishirG.Patil, TianjunZhang, XinWang, andJoseph E. Gonzalez. Gorilla: LargeLanguage Model Connected with Massive APIs, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.15334
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.15334 2023
-
[38]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative Agents for Software Development, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.07924
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.07924 2023
-
[39]
Tool Learning with Foundation Models
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yux...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.08354 2023
-
[40]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitat- ing Large Language Models to Master 16000+ Real-world APIs, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.16789
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.16789 2023
-
[41]
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails, 2023
Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.10501
-
[42]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools, 2023. Preprint, arXiv. doi:10.48550/arXiv.2302.04761
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761 2023
-
[43]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.17580
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17580 2023
-
[44]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language Agents with Verbal Reinforcement Learning, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.11366. 18
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[45]
RestGPT: Con- necting Large Language Models with Real-World RESTful APIs, 2023
Yifan Song, Weimin Xiong, Dawei Zhu, Wenhao Wu, Han Qian, Mingbo Song, Hail- iang Huang, Cheng Li, Ke Wang, Rong Yao, Ye Tian, and Sujian Li. RestGPT: Con- necting Large Language Models with Real-World RESTful APIs, 2023. Preprint, arXiv. doi:10.48550/arXiv.2306.06624
-
[46]
Cognitive Architectures for Language Agents
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths. Cognitive Architectures for Language Agents, 2023. Preprint, arXiv. doi:10.48550/arXiv.2309.02427
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.02427 2023
-
[47]
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A Survey on Large Language Model based Autonomous Agents, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.11432
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.11432 2023
-
[48]
Executable Code Actions Elicit Better LLM Agents, 2024
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable Code Actions Elicit Better LLM Agents, 2024. Preprint, arXiv. doi:10.48550/arXiv.2402.01030
-
[49]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An Open Platform for AI Soft...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.16741 2024
-
[50]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2022. Preprint, arXiv. doi:10.48550/arXiv.2203.11171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2022
-
[51]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent Workflow Memory, 2024. Preprint, arXiv. doi:10.48550/arXiv.2409.07429
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.07429 2024
-
[52]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How Does LLM Safety Training Fail?, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.02483
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.02483 2023
-
[53]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent Abilities of Large Language Models, 2022. Preprint, arXiv. doi:10.48550/arXiv.2206.07682
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2206.07682 2022
-
[54]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022. Preprint, arXiv. doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[55]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.08155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[56]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.07864 2023
-
[57]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agent- less: Demystifying LLM-based Software Engineering Agents, 2024. Preprint, arXiv. doi:10.48550/arXiv.2407.01489
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.01489 2024
-
[58]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, 2024. Preprint, arXiv. doi:10.48550/arXiv.2405.15793
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.15793 2024
-
[59]
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, Diyi Yang, Sida I. Wang, and Ofir Press. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?, 2024. Preprint, arXiv. doi:10.48550/arXiv.2410.03859
-
[60]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A Bench- mark for Tool-Agent-User Interaction in Real-World Domains, 2024. Preprint, arXiv. doi:10.48550/arXiv.2406.12045
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045 2024
-
[61]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.10601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[62]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models, 2022. Preprint, arXiv. doi:10.48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2022
-
[63]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on Evaluation of LLM-based Agents, 2025. Preprint, arXiv. doi:10.48550/arXiv.2503.16416
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.16416 2025
-
[64]
AutoCodeRover: Autonomous Program Improvement, 2024
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. AutoCodeRover: Autonomous Program Improvement, 2024. Preprint, arXiv. doi:10.48550/arXiv.2404.05427
-
[65]
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A Survey on the Memory Mechanism of Large Language Model based Agents, 2024. Preprint, arXiv. doi:10.48550/arXiv.2404.13501
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.13501 2024
-
[66]
Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, and Rui Wang. Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code, 2023. Preprint, arXiv. doi:10.48550/arXiv.2311.07989
-
[67]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A Survey of Large Language Models, 2023. Preprint, arXiv. doi:10.48550/arXiv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223 2023
-
[68]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.13854
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.13854 2023
-
[69]
Agents: An Open-source Framework for Autonomous Language Agents, 2023
Wangchunshu Zhou, Yuchen Eleanor Jiang, Long Li, Jialong Wu, Tiannan Wang, Shi Qiu, Jintian Zhang, Jing Chen, Ruipu Wu, Shuai Wang, Shiding Zhu, Jiyu Chen, Wentao Zhang, Xiangru Tang, Ningyu Zhang, Huajun Chen, Peng Cui, and Mrinmaya Sachan. Agents: An Open-source Framework for Autonomous Language Agents, 2023. Preprint, arXiv. doi:10.48550/arXiv.2309.07870. 20
-
[70]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and Transferable Adversarial Attacks on Aligned Language Models, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.15043. 21
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15043 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.