Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints
Pith reviewed 2026-05-22 19:39 UTC · model grok-4.3
The pith
Fluid model of KV-cache growth yields admission rules that approximate optimal LLM inference scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors formulate inference as a multi-stage online scheduling problem with endogenous memory growth, linear iteration times, and GPU-resident KV-cache constraints. They introduce a fluid model that characterizes equilibrium batch composition, memory requirement, and stability region. Guided by the fluid model, they design WAIT and Nested WAIT policies that approximate the fluid benchmark asymptotically under the stated memory conditions, with Nested WAIT adding a safety buffer for unknown output lengths. In Vidur simulations for Llama-2-7B on an A100 GPU, the policies enlarge the stable operating range and reduce latency relative to baselines, particularly in near-overloaded and loaded.
What carries the argument
Fluid model characterizing equilibrium batch composition, memory requirement, and stability region, which is used to derive threshold-based admission rules for requests.
Load-bearing premise
The fluid model accurately captures equilibrium batch composition, memory requirement, and stability region for the real multi-stage inference process with endogenous KV-cache growth.
What would settle it
If Vidur simulations configured for Llama-2-7B on an A100 GPU show that the policies do not enlarge the stable operating range or reduce latency compared to baseline algorithms, the approximation and performance claims would be falsified.
Figures

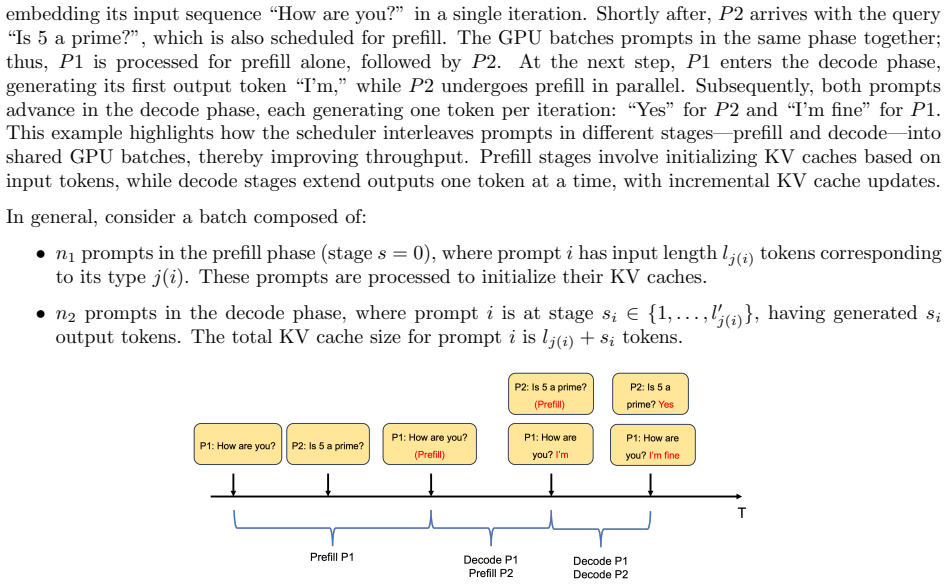







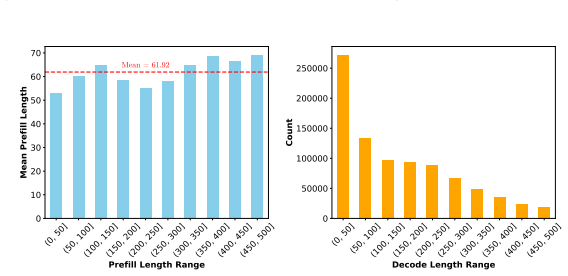








read the original abstract
Large language models now serve millions of users daily, with providers incurring costs exceeding $700,000 per day. Each request requires token-by-token inference, making GPU scheduling central to latency, capacity, and cost. The difficulty is endogenous memory growth: generated tokens expand the Key-Value (KV) cache, and overflow can evict in-progress requests and waste prior computation. We formulate inference as a multi-stage online scheduling problem with endogenous memory growth, linear iteration times, and GPU-resident KV-cache constraints. We introduce a fluid model that characterizes equilibrium batch composition, memory requirement, and stability region. Guided by the fluid model, we design WAIT (Waiting for Accumulated Inference Threshold), a threshold-based admission rule for known output lengths, and Nested WAIT, which extends the rule to unknown output lengths by regulating how requests advance across decode-stage segments. Both algorithms approximate the fluid benchmark asymptotically under the stated memory conditions. Nested WAIT uses an additional safety buffer of moderate scale to hedge against memory-overflow-induced evictions under unknown output lengths. In Vidur simulations configured for Llama-2-7B on an A100 GPU, with supplemental real-GPU validation reported in the appendix, the policies enlarge the empirically observed stable operating range relative to widely used baseline algorithms and reduce latency especially in near-overloaded and overloaded regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates LLM inference as a multi-stage online scheduling problem with endogenous KV-cache memory growth and linear iteration times. It introduces a fluid model characterizing equilibrium batch composition, memory usage, and stability region, then derives WAIT (for known output lengths) and Nested WAIT (for unknown lengths with a safety buffer) as threshold-based admission policies. Both are claimed to asymptotically approximate the fluid benchmark under stated memory conditions. Vidur simulations for Llama-2-7B on A100 (plus appendix real-GPU runs) show enlarged stable operating range and reduced latency versus baselines, especially near and beyond overload.
Significance. If the fluid-to-discrete translation holds, the work supplies an analytically grounded method for memory-aware scheduling that could improve utilization and tail latency in production LLM serving systems. The fluid equilibrium analysis offers a reusable lens for stability regions in systems with growing per-request state, which is a timely contribution given rising inference costs.
major comments (2)
- [§3] §3 (Fluid Model): The derivation assumes continuous-time equilibrium batching and linear per-iteration costs with known/segmented output lengths, yet the central claim that WAIT/Nested WAIT remain near-optimal for the discrete multi-stage process with stochastic output lengths and endogenous KV-cache growth is not accompanied by a quantitative bound on the approximation gap or a proof of stability preservation under bursty arrivals.
- [§5.3] §5.3 (Simulation Results): The reported enlargement of the stable operating range and latency reductions in near-overloaded regimes are presented without confidence intervals, variance estimates, or statistical significance tests across the Vidur runs; this weakens the empirical support for the claim that the fluid-guided thresholds outperform widely used baselines under realistic conditions.
minor comments (2)
- [§4.2] The definition of the safety buffer scale in Nested WAIT (around Eq. (12) or equivalent) should include a brief sensitivity analysis showing how performance varies with buffer size.
- [§5] Figure 3 (or equivalent stability-region plot) would benefit from explicit annotation of the fluid-derived thresholds used in the simulated policies.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the opportunity to improve our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Fluid Model): The derivation assumes continuous-time equilibrium batching and linear per-iteration costs with known/segmented output lengths, yet the central claim that WAIT/Nested WAIT remain near-optimal for the discrete multi-stage process with stochastic output lengths and endogenous KV-cache growth is not accompanied by a quantitative bound on the approximation gap or a proof of stability preservation under bursty arrivals.
Authors: We agree that our fluid model provides an asymptotic characterization rather than a finite-time bound. The policies are derived to approximate the fluid benchmark asymptotically under the memory conditions specified in the paper. While we do not provide a quantitative error bound for the discrete stochastic case or a stability proof for arbitrary bursty arrivals, the Vidur simulations validate the practical performance, including under the arrival processes tested. In the revision, we will clarify the scope of the asymptotic claim and add a discussion of the limitations, including the challenges in deriving such bounds for systems with endogenous memory growth. revision: partial
-
Referee: [§5.3] §5.3 (Simulation Results): The reported enlargement of the stable operating range and latency reductions in near-overloaded regimes are presented without confidence intervals, variance estimates, or statistical significance tests across the Vidur runs; this weakens the empirical support for the claim that the fluid-guided thresholds outperform widely used baselines under realistic conditions.
Authors: We concur that statistical rigor would enhance the presentation of the results. We will revise Section 5.3 to include confidence intervals and variance estimates computed over multiple independent simulation runs. Additionally, we will report the results of statistical significance tests comparing the performance of WAIT and Nested WAIT against the baselines. revision: yes
- A quantitative bound on the approximation gap or a formal proof of stability preservation under bursty arrivals in the discrete stochastic setting
Circularity Check
No significant circularity in fluid model derivation or policy design
full rationale
The paper constructs a fluid model from first principles to characterize equilibrium batch composition, memory requirements, and stability region under linear iteration times and KV-cache constraints. Threshold rules for WAIT and Nested WAIT are then derived from this model, with the asymptotic approximation claim being a direct mathematical consequence within the fluid limit rather than a restatement of fitted data. Vidur simulations and real-GPU runs constitute independent empirical tests on discrete request streams, not tautological outputs from the same parameters. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
M* = d0 λj (l'j+1)(lj + l'j/2) / (1 - d1 λj (l'j+1)(lj + l'j/2))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
SuperInfer improves TTFT SLO attainment by up to 74.7% on GH200 Superchips via SLO-aware rotary scheduling (RotaSched) and full-duplex KV cache rotation (DuplexKV) over NVLink-C2C while preserving TBT and throughput.
-
Tackling the Data-Parallel Load Balancing Bottleneck in LLM Serving: Practical Online Routing at Scale
BalanceRoute reduces data-parallel imbalance in LLM inference via F-score routing and lookahead, yielding higher end-to-end throughput on 144-NPU clusters versus vLLM baselines.
-
Tackling the Data-Parallel Load Balancing Bottleneck in LLM Serving: Practical Online Routing at Scale
BalanceRoute uses a piecewise-linear F-score (with optional short lookahead) for sticky request routing in LLM serving, reducing DP imbalance and raising end-to-end throughput versus vLLM baselines on production and A...
-
A Queueing-Theoretic Framework for Stability Analysis of LLM Inference with KV Cache Memory Constraints
A queueing model derives stability conditions for LLM inference services under combined compute and KV cache memory limits, with experimental validation showing typical deviations under 10%.
-
Flow-Controlled Scheduling for LLM Inference with Provable Stability Guarantees
A flow-control framework for LLM inference derives necessary and sufficient stability conditions and experimentally improves throughput, latency, and KV cache stability over common baselines.
-
Position: LLM Serving Needs Mathematical Optimization and Algorithmic Foundations, Not Just Heuristics
LLM serving requires mathematical optimization and algorithms with provable guarantees rather than generic heuristics that fail unpredictably on LLM workloads.
Reference graph
Works this paper leans on
-
[1]
Agrawal, A., Kedia, N., Mohan, J., Panwar, A., Kwatra, N., Gulavani, B., Ramjee, R., and Tumanov, A. (2024a). Vidur: A large-scale simulation framework for llm inference.Proceedings of Machine Learning and Systems, 6:351–366. Agrawal, A., Kedia, N., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B., Tumanov, A., and Ramjee, R. (2024b). Taming{Throughput-Lat...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Springer. Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al. (2023). Qwen technical report.arXiv preprint arXiv:2309.16609. Balkanski, E., Rubinstein, A., and Singer, Y. (2016). The power of optimization from samples.Advances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
B¨ auerle, N. (2002). Optimal control of queueing networks: An approach via fluid models.Advances in Applied Probability, 34(2):313–328. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners.Advances in neural information processing...
-
[4]
Scaling Laws for Neural Language Models
Cambridge university press. Fu, Y., Zhu, S., Su, R., Qiao, A., Stoica, I., and Zhang, H. (2025). Efficient llm scheduling by learning to rank. Advances in Neural Information Processing Systems, 37:59006–59029. Garc´ ıa-Mart´ ın, E., Rodrigues, C. F., Riley, G., and Grahn, H. (2019). Estimation of energy consumption in machine learning.Journal of Parallel ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Li, W., Wang, L., Chai, X., and Yuan, H. (2020). Online batch scheduling of simple linear deteriorating jobs with incompatible families.Mathematics, 8(2):170. Li, Y., Dai, J., and Peng, T. (2025b). Throughput-optimal scheduling algorithms for llm inference and ai agents. Accessed: 2025-04-11. Liu, P. and Lu, X. (2015). Online unbounded batch scheduling on...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
”In vLLM V1, the default preemption mode is RECOMPUTE rather than SWAP, as recomputation has lower overhead in the V1 architecture”. Wang, M., Ye, Y., and Zhou, Z. (2025). Llm serving optimization with variable prefill and decode lengths.arXiv preprint arXiv:2508.06133. Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bos...
-
[7]
At stage 0 and stage 1, both types appear identical to the scheduler
The key constraint is that prompt types cannot be distinguished until a type-2 prompt enters stage 2 (generates its second output token). At stage 0 and stage 1, both types appear identical to the scheduler. Consider any admissible batching policy. For each possible batch configuration, one of the following must hold: 1.Memory underutilization:The batch l...
work page 2003
-
[8]
Define{ ˜W b}by: ˜W 0 = 2λ, ˜W b+1 = max{2λ, ˜W b +X b −λ}
and maintains dominance throughout. Define{ ˜W b}by: ˜W 0 = 2λ, ˜W b+1 = max{2λ, ˜W b +X b −λ}. Then ˜W b ≥W b +λfor allb∈N. The proof is in Appendix E.2. 36 Lindley recursion.To analyze the coupled process, we apply the Lindley recursion representation (As- mussen 2003, Proposition 6.3): Lemma 3 (Lindley Representation)LetS k =Pk r=1(X r −λ)be the partia...
work page 2003
-
[9]
lj + l′ j 2 ≥M ∗. (19) These constraints ensure that for anyπ∈Π: when allmtypes are batched together, arrivals do not exceed completions for each type (i.e., Arrival j ≤Completion j). The equilibrium policy corresponds to π∗ = [ n∗ 1 l′ 1+1 ,· · ·, n∗ m l′m+1] whenM π =M ∗. Notation.Letbdenote the batch index,J b the set of types in batchb,t s(b) the star...
work page 1962
-
[10]
Negative drift ensures queue stability, preventing unbounded growth that would lead to eviction
Expected Queue Length.SinceE h X b (k) i =n k−1pk −n k <0 (negative drift), by Kingman’s inequality (Kingman 1962): E h W b (k) i ≤E h ˜W b (k) i ≤n k + nk−1 ·p k(1−p k) 2 (nk −n k−1 ·p k) . Negative drift ensures queue stability, preventing unbounded growth that would lead to eviction. This bound ensures finite expected queue length for each segmentk≥2, ...
work page 1962
-
[11]
This zero-drift property in log space enables Doob’s inequality to bound tail probabilities. By Doob’s martingale inequality (Durrett 2019), we have that P( max 1≤i≤b−1 {eθkSi (k) } ≥a)≤ E M i a = E M0 a = 1 a . Exponentiating both sides of the inequality event, we obtain: P( max 1≤i≤b−1 {eθS i (k) } ≥e θc)≤ 1 eθc ⇒P( max 1≤i≤b−1 {Si (k)} ≥c)≤e −θc. Using...
work page 2019
-
[12]
Thus we have the dominance chain: W b (1) ≤ ¯W b (1) ≤ ˜W b (1) ≤ W b (1),∀b∈N
The process{ ˜W b (1)} is dominated by a Lindley process: W 0 (1) = 2n1, W b+1 (1) = max{2n1, W b (1) +X b (1)},∀b∈N. Thus we have the dominance chain: W b (1) ≤ ¯W b (1) ≤ ˜W b (1) ≤ W b (1),∀b∈N. Sincen 1 >Λ π, the process{ W b (1)}has negative drift. By Kingman’s inequality (Kingman 1962), with Var(Xb (1)) =Λ π, E h X b (1) i =n 1 −Λ π, we obtain E h W...
work page 1962
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.