Responsible Agentic AI Requires Explicit Provenance
Pith reviewed 2026-05-20 14:03 UTC · model grok-4.3
The pith
Explicit provenance across the full agentic lifecycle is the necessary condition for making responsibility in AI computable and actionable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Explicit provenance is not optional but the necessary condition for responsible agentic AI, as only it supplies the quantifiable, traceable, and interventionable data needed to assign responsibility when harm emerges from agent compositions no single party designed.
What carries the argument
Explicit provenance, encoded through a causal attribution function and responsibility tensor and maintained across four lifecycle layers to support online estimation and intervention.
If this is right
- Responsibility gaps across sociotechnical dimensions become identifiable once provenance records are available.
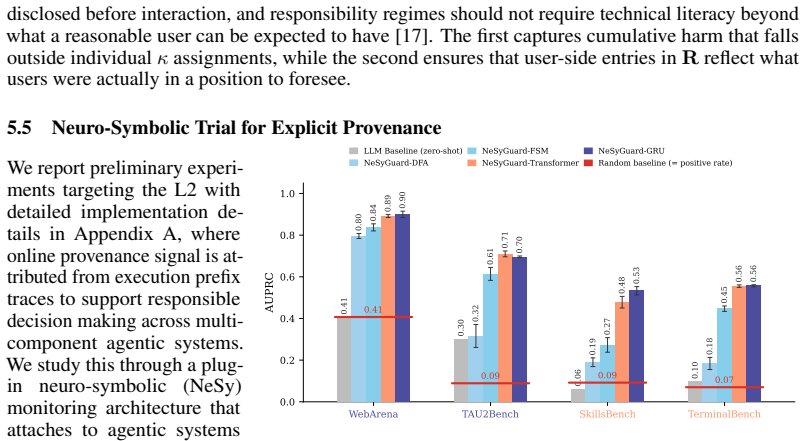
- Provenance becomes estimable and interveneable online in preliminary experiments before irreversible harm accumulates.
- A concrete agentic incident can be analyzed to determine which parties bear responsibility.
- No stakeholder in the agentic AI ecosystem can treat explicit provenance as discretionary.
Where Pith is reading between the lines
- Mandates for provenance logging could emerge in future AI regulations to enforce accountability.
- Performance or privacy costs of maintaining detailed provenance would need separate measurement in deployed systems.
- The same traceability approach might apply to harms in non-agentic AI that involve chained decisions.
- Automated tools for real-time responsibility scoring could be built on top of the proposed tensor.
Load-bearing premise
That current agentic systems generate no usable provenance today and that adding explicit provenance will directly render responsibility computable without extra mechanisms or major trade-offs.
What would settle it
A concrete multi-agent incident in which full explicit provenance is recorded yet responsibility for resulting harm still cannot be assigned to any stakeholder or intervened upon before damage occurs.
Figures

read the original abstract
Agentic AI is rapidly proliferating across diverse real-world domains such as software engineering, yet public trust has not kept pace. The central reason is that responsibility, despite being widely discussed, remains a subjective and unenforced concept, as no current agentic framework produces the quantifiable, traceable, and interventionable provenance needed to assign it when harm emerges from compositions no single party designed. We position that what is missing is not better benchmark-level evaluation but $\textbf{explicit provenance}$ across the full agentic lifecycle, which is the only viable basis for making responsibility computable and actionable. We advance this agenda along four axes: establishing $\textit{why}$ such provenance is a structural necessity by identifying responsibility gaps across sociotechnical dimensions, formalizing $\textit{what}$ it must encode through a causal attribution function and responsibility tensor, discussing $\textit{how}$ it can be made computable across four lifecycle layers with preliminary experiments showing that provenance is estimable and interveneable online before irreversible harm accumulates, and examining $\textit{who}$ bears responsibility through a concrete agentic incident. Explicit provenance is not a discretionary refinement but the necessary condition for responsible agentic AI, and no stakeholder across its ecosystem can afford to treat it as optional.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that current agentic AI frameworks fail to produce quantifiable, traceable, and interventionable provenance, leaving responsibility subjective and unenforced when harm emerges from compositions with no single designer. It positions explicit provenance across the full lifecycle as the necessary condition for making responsibility computable, formalized via a causal attribution function and responsibility tensor. The work advances this via four axes: sociotechnical responsibility gaps, formal encoding, computability across four lifecycle layers (with preliminary experiments on online estimability and interveneability), and illustration through a concrete agentic incident.
Significance. If the proposed provenance structures can be shown to suffice without unstated mechanisms or prohibitive trade-offs, the framework could provide a concrete basis for accountability in multi-agent systems, addressing a core barrier to trust in deployed agentic AI. The four-axis structure offers a useful organizing agenda, and the preliminary experiments on estimability provide an initial empirical foothold.
major comments (3)
- [Abstract] Abstract and central positioning paragraph: the claim that explicit provenance is 'the only viable basis for making responsibility computable' is load-bearing yet rests on the unverified premise that the causal attribution function and responsibility tensor suffice for emergent interactions in compositions with no single designer; the cited preliminary experiments demonstrate estimability and interveneability but do not test generalization or elimination of supplementary causal assumptions.
- [Formalization section] Formalization of the responsibility tensor and causal attribution function (in the 'what' axis section): these constructs risk circularity because they appear defined primarily with reference to the desired responsibility outcomes rather than independent external benchmarks or falsifiable criteria, which weakens the assertion that they render responsibility computable.
- [Lifecycle layers section] Discussion of computability across four lifecycle layers (in the 'how' axis section): while preliminary experiments are reported as showing online estimability and interveneability before irreversible harm, the manuscript does not examine scalability limits, performance/privacy trade-offs, or additional mechanisms needed when harm arises from agent interactions, leaving the necessity claim under-supported.
minor comments (2)
- [Notation and definitions] The introduction of novel terms such as 'responsibility tensor' would be clarified by an explicit comparison to related concepts in causal inference and data provenance literature.
- [Incident analysis] Ensure the concrete agentic incident example includes sufficient detail on the four lifecycle layers to allow readers to trace the provenance encoding.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We address each of the major comments point by point below, providing clarifications and indicating planned revisions where necessary.
read point-by-point responses
-
Referee: [Abstract] Abstract and central positioning paragraph: the claim that explicit provenance is 'the only viable basis for making responsibility computable' is load-bearing yet rests on the unverified premise that the causal attribution function and responsibility tensor suffice for emergent interactions in compositions with no single designer; the cited preliminary experiments demonstrate estimability and interveneability but do not test generalization or elimination of supplementary causal assumptions.
Authors: The manuscript argues that explicit provenance is necessary due to the structural responsibility gaps in existing agentic AI systems, as detailed in the 'why' axis. The causal attribution function draws from established causal inference methods, and the responsibility tensor provides a formal structure for aggregation. While we recognize that the preliminary experiments are limited and do not fully test generalization across all emergent interactions, the claim is positioned as a necessary condition rather than a complete sufficiency proof. We will revise the abstract to clarify this distinction and add a new subsection on assumptions and limitations to better support the positioning. revision: partial
-
Referee: [Formalization section] Formalization of the responsibility tensor and causal attribution function (in the 'what' axis section): these constructs risk circularity because they appear defined primarily with reference to the desired responsibility outcomes rather than independent external benchmarks or falsifiable criteria, which weakens the assertion that they render responsibility computable.
Authors: We maintain that the formalization avoids circularity. The causal attribution function is specified using interventionist causal models (e.g., via do-operators on agent interaction graphs), which are defined independently of responsibility outcomes. The responsibility tensor then operationalizes these attributions into a computable form. To prevent any misinterpretation of circularity, we will include additional explanations linking to falsifiable criteria from causal discovery literature and external benchmarks in the revised formalization section. revision: yes
-
Referee: [Lifecycle layers section] Discussion of computability across four lifecycle layers (in the 'how' axis section): while preliminary experiments are reported as showing online estimability and interveneability before irreversible harm, the manuscript does not examine scalability limits, performance/privacy trade-offs, or additional mechanisms needed when harm arises from agent interactions, leaving the necessity claim under-supported.
Authors: We agree with this observation. The current experiments focus on demonstrating basic online estimability and interveneability in controlled settings. The manuscript does not delve into scalability or specific trade-offs, which are indeed important for real-world applicability, especially in multi-agent scenarios. We will revise the 'how' axis to include an expanded discussion of these aspects, potential performance and privacy implications, and proposed mechanisms for handling emergent interactions, along with directions for future empirical work. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper identifies gaps in current agentic frameworks (no quantifiable/traceable/interventionable provenance for harm from multi-party compositions) and positions explicit provenance as the necessary condition for making responsibility computable. It advances this via sociotechnical analysis, formalization through a causal attribution function and responsibility tensor, lifecycle-layer discussion, and a concrete incident example. No equations, self-citations, or definitions are present in the provided text that reduce the central claim to its inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop where the tensor is defined solely in terms of computability). The formal constructs are introduced as an independent proposal rather than a renaming or self-referential fit. The argument remains self-contained against external benchmarks of responsibility gaps and does not rely on load-bearing self-citation chains or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current agentic frameworks produce no quantifiable, traceable, and interventionable provenance for responsibility assignment.
invented entities (2)
-
responsibility tensor
no independent evidence
-
causal attribution function
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 4.1 (Causal Contribution) … κ(p, ω, τ) = Pr[ω|τ]−Pr[ω|τ−p]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 4.5 (Responsibility Tensor) … R[p, ω, dk]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Frontier ai regulation: Managing emerging risks to public safety, 2023
Markus Anderljung, Joslyn Barnhart, Anton Korinek, Jade Leung, Cullen O’Keefe, Jess Whittle- stone, Shahar Avin, Miles Brundage, Justin Bullock, Duncan Cass-Beggs, Ben Chang, Tantum Collins, Tim Fist, Gillian Hadfield, Alan Hayes, Lewis Ho, Sara Hooker, Eric Horvitz, Noam Kolt, Jonas Schuett, Yonadav Shavit, Divya Siddarth, Robert Trager, and Kevin Wolf. ...
work page 2023
-
[3]
Agentharm: A benchmark for measuring harmfulness of llm agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents. InThe Thirteenth International Conference on Learning Representations
-
[4]
Anastasios Nikolas Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Conformal risk control. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[5]
Anthropic. Tool use with claude, 2026. Claude API documentation
work page 2026
-
[6]
The conclusion of contracts by software agents in the eyes of the law
Tina Balke and Torsten Eymann. The conclusion of contracts by software agents in the eyes of the law. InProceedings of the 7th international joint conference on Autonomous agents and multiagent systems-Volume 2, pages 771–778, 2008
work page 2008
-
[7]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-Bench: Evaluating conversational agents in a dual-control environment.arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Rishi Bommasani, Kathleen A Creel, Ananya Kumar, Dan Jurafsky, and Percy S Liang. Picking on the same person: Does algorithmic monoculture lead to outcome homogenization?Advances in neural information processing systems, 35:3663–3678, 2022
work page 2022
-
[9]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[10]
Harms from increasingly agentic algorithmic systems
Alan Chan, Rebecca Salganik, Alva Markelius, Chris Pang, Nitarshan Rajkumar, Dmitrii Krasheninnikov, Lauro Langosco, Zhonghao He, Yawen Duan, Micah Carroll, et al. Harms from increasingly agentic algorithmic systems. InProceedings of the 2023 ACM conference on fairness, accountability, and transparency, pages 651–666, 2023
work page 2023
-
[11]
A survey on trust modeling.ACM Computing Surveys (CSUR), 48(2):1–40, 2015
Jin-Hee Cho, Kevin Chan, and Sibel Adali. A survey on trust modeling.ACM Computing Surveys (CSUR), 48(2):1–40, 2015
work page 2015
-
[12]
Understanding accountability in algorithmic supply chains
Jennifer Cobbe, Michael Veale, and Jatinder Singh. Understanding accountability in algorithmic supply chains. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1186–1197, 2023
work page 2023
-
[13]
EU Commission et al. Proposal for a directive of the european parliament and of the council on adapting noncontractual civil liability rules to artificial intelligence (ai liability directive). European Commission, 2022
work page 2022
-
[14]
Allan Dafoe. Ai governance: a research agenda.Governance of AI Program, Future of Humanity Institute, University of Oxford: Oxford, UK, 1442:1443, 2018
work page 2018
-
[15]
Business and it leaders report ai agents are scaling faster than their guardrails, 2026
Deloitte. Business and it leaders report ai agents are scaling faster than their guardrails, 2026
work page 2026
-
[16]
Safeguarding large language models: A survey.Artificial intelligence review, 58(12):382, 2025
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, et al. Safeguarding large language models: A survey.Artificial intelligence review, 58(12):382, 2025. 10
work page 2025
-
[17]
Accountability of ai under the law: The role of explanation,
Finale Doshi-Velez, Mason Kortz, Ryan Budish, Chris Bavitz, Sam Gershman, David O’Brien, Kate Scott, Stuart Schieber, James Waldo, David Weinberger, et al. Accountability of ai under the law: The role of explanation.arXiv preprint arXiv:1711.01134, 2017
-
[18]
Emilio Ferrara. Genai against humanity: Nefarious applications of generative artificial intel- ligence and large language models.Journal of Computational Social Science, 7(1):549–569, 2024
work page 2024
-
[19]
arXiv preprint arXiv:2404.16244 (2024).https://doi.org/10.48550/arXiv.2404.16244
Iason Gabriel, Arianna Manzini, Geoff Keeling, Lisa Anne Hendricks, Verena Rieser, Hasan Iqbal, Nenad Tomašev, Ira Ktena, Zachary Kenton, Mikel Rodriguez, et al. The ethics of advanced ai assistants.arXiv preprint arXiv:2404.16244, 2024
-
[20]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Neurosymbolic ai: The 3 rd wave.Artificial Intelligence Review, 56(11):12387–12406, 2023
Artur d’Avila Garcez and Luis C Lamb. Neurosymbolic ai: The 3 rd wave.Artificial Intelligence Review, 56(11):12387–12406, 2023
work page 2023
-
[22]
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks.Advances in neural information processing systems, 34:9574–9586, 2021
work page 2021
-
[23]
Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration
Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang. Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration. arXiv preprint arXiv:2603.21019, 2026
-
[24]
Ibrahim Habli, Tom Lawton, and Zoe Porter. Artificial intelligence in health care: accountability and safety.Bulletin of the World Health Organization, 98(4):251, 2020
work page 2020
-
[25]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[26]
Jinwei Hu, Yi Dong, Shuang Ao, Zhuoyun Li, Boxuan Wang, Lokesh Singh, Guangliang Cheng, Sarvapali D. Ramchurn, and Xiaowei Huang. Stop reducing responsibility in llm-powered multi-agent systems to local alignment, 2025
work page 2025
-
[27]
Jinwei HU, Yi DONG, Zhengtao DING, and Xiaowei HUANG. Enhancing robustness of llm- driven multi-agent systems through randomized smoothing.Chinese Journal of Aeronautics, page 103779, 2025
work page 2025
-
[28]
Jinwei Hu, Yi Dong, Youcheng Sun, and Xiaowei Huang. Tapas are free! training-free adaptation of programmatic agents via llm-guided program synthesis in dynamic environments. Proceedings of the AAAI Conference on Artificial Intelligence, 40(35):29477–29485, Mar. 2026
work page 2026
-
[29]
Jinwei Hu, Xinmiao Huang, Youcheng Sun, Yi Dong, and Xiaowei Huang. Lying with truths: Open-channel multi-agent collusion for belief manipulation via generative montage, 2026
work page 2026
-
[30]
Kristin F. Hurst and Nicole D. Sintov. Trusting autonomous vehicles as moral agents improves related policy support.Frontiers in Psychology, V olume 13 - 2022, 2022
work page 2022
-
[31]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills–beyond tool use in llm agents.arXiv preprint arXiv:2602.20867, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Os-harm: A benchmark for measuring safety of computer use agents
Thomas Kuntz, Agatha Duzan, Hao Zhao, Francesco Croce, J Zico Kolter, Nicolas Flammarion, and Maksym Andriushchenko. Os-harm: A benchmark for measuring safety of computer use agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[33]
Messi HJ Lee, Jacob M Montgomery, and Calvin K Lai. Large language models portray socially subordinate groups as more homogeneous, consistent with a bias observed in humans. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1321–1340, 2024. 11
work page 2024
-
[34]
Trustworthy ai: From principles to practices.ACM Computing Surveys, 55(9):1–46, 2023
Bo Li, Peng Qi, Bo Liu, Shuai Di, Jingen Liu, Jiquan Pei, Jinfeng Yi, and Bowen Zhou. Trustworthy ai: From principles to practices.ACM Computing Surveys, 55(9):1–46, 2023
work page 2023
-
[35]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Holistic evaluation of language models.Transactions on Machine Learning Research
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.Transactions on Machine Learning Research
-
[37]
Haochen Liu, Yiqi Wang, Wenqi Fan, Xiaorui Liu, Yaxin Li, Shaili Jain, Yunhao Liu, Anil Jain, and Jiliang Tang. Trustworthy ai: A computational perspective.ACM Transactions on Intelligent Systems and Technology, 14(1):1–59, 2022
work page 2022
-
[38]
Shuo Lu, Yingsheng Wang, Lijun Sheng, Lingxiao He, Aihua Zheng, and Jian Liang. Out-of- distribution detection: A task-oriented survey of recent advances.ACM Computing Surveys, 58(2):1–39, 2025
work page 2025
-
[39]
Andreas Matthias. The responsibility gap: Ascribing responsibility for the actions of learning automata.Ethics and information technology, 6(3):175–183, 2004
work page 2004
-
[40]
The state of ai in 2025: Agents, innovation, and transformation, 2025
McKinsey & Company. The state of ai in 2025: Agents, innovation, and transformation, 2025
work page 2025
-
[41]
State of ai trust in 2026: Shifting to the agentic era, 2026
McKinsey & Company. State of ai trust in 2026: Shifting to the agentic era, 2026
work page 2026
-
[42]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Exploring the potential of llms as personalized assistants: Dataset, evaluation, and analysis
Jisoo Mok, Ik-hwan Kim, Sangkwon Park, and Sungroh Yoon. Exploring the potential of llms as personalized assistants: Dataset, evaluation, and analysis. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10212–10239, 2025
work page 2025
-
[44]
Claudio Novelli, Mariarosaria Taddeo, and Luciano Floridi. Accountability in artificial intelli- gence: what it is and how it works.Ai & Society, 39(4):1871–1882, 2024
work page 2024
-
[45]
Audit trails for accountability in large language models.arXiv preprint arXiv:2601.20727, 2026
Victor Ojewale, Harini Suresh, and Suresh Venkatasubramanian. Audit trails for accountability in large language models.arXiv preprint arXiv:2601.20727, 2026
-
[46]
Matthew Oliver. Contracting by artificial intelligence: Open offers, unilateral mistakes, and why algorithms are not agents.ANU Journal of Law and Technology, 2(1):45–87, 2021
work page 2021
- [47]
- [48]
-
[49]
Clawhub: Skill directory for openclaw, 2026
OpenClaw. Clawhub: Skill directory for openclaw, 2026
work page 2026
-
[50]
Openclaw: Personal ai assistant, 2026
OpenClaw. Openclaw: Personal ai assistant, 2026
work page 2026
-
[51]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[52]
Jonas Peters, Dominik Janzing, and Bernhard Scholkopf.Elements of causal inference: founda- tions and learning algorithms. MIT press, 2017
work page 2017
-
[53]
Unravelling responsibility for ai.Journal of Responsible Technology, page 100124, 2025
Zoe Porter, Philippa Ryan, Phillip Morgan, Joanna Al-Qaddoumi, Bernard Twomey, Paul Noordhof, John McDermid, and Ibrahim Habli. Unravelling responsibility for ai.Journal of Responsible Technology, page 100124, 2025. 12
work page 2025
- [54]
-
[55]
Inioluwa Deborah Raji, Andrew Smart, Rebecca N White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. Closing the ai accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 conference on fairness, accountability, and transparency, pages 33–44, 2020
work page 2020
-
[56]
Identifying the risks of lm agents with an lm-emulated sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox. InThe Twelfth International Conference on Learning Representations
-
[57]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215, 2019
work page 2019
-
[58]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[59]
The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems
Leon Staufer, Kevin Feng, Kevin Wei, Luke Bailey, Yawen Duan, Mick Yang, A Pinar Ozisik, Stephen Casper, and Noam Kolt. The 2025 ai agent index: Documenting technical and safety features of deployed agentic ai systems.arXiv preprint arXiv:2602.17753, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Hao Sun, Alihan Hüyük, Daniel Jarrett, and Mihaela van der Schaar. Accountability in offline reinforcement learning: Explaining decisions with a corpus of examples.Advances in Neural Information Processing Systems, 36:3143–3172, 2023
work page 2023
-
[61]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Find the gap: Ai, responsible agency and vulnerability
Shannon Vallor and Tillmann Vierkant. Find the gap: Ai, responsible agency and vulnerability. Minds and Machines, 34(3):20, 2024
work page 2024
-
[63]
Springer Science & Business Media, 2011
Nicole A Vincent, Ibo Van de Poel, and Jeroen Van Den Hoven.Moral responsibility: Beyond free will and determinism. Springer Science & Business Media, 2011
work page 2011
-
[64]
Machines without principals: liability rules and artificial intelligence.Wash
David C Vladeck. Machines without principals: liability rules and artificial intelligence.Wash. L. Rev., 89:117, 2014
work page 2014
-
[65]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[66]
Freematch: Self- adaptive thresholding for semi-supervised learning
Yidong Wang, Hao Chen, Qiang Heng, Wenxin Hou, Yue Fan, Zhen Wu, Jindong Wang, Marios Savvides, Takahiro Shinozaki, Bhiksha Raj, Bernt Schiele, and Xing Xie. Freematch: Self- adaptive thresholding for semi-supervised learning. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[67]
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al. Taxonomy of risks posed by language models.Proceedings of the ACM Conference on Fairness, Accountability, and Transparency, pages 214–229, 2022
work page 2022
-
[68]
Maranke Wieringa. What to account for when accounting for algorithms: a systematic literature review on algorithmic accountability. InProceedings of the 2020 conference on fairness, accountability, and transparency, pages 1–18, 2020
work page 2020
-
[69]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024. 13
work page 2024
-
[70]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
work page 2025
-
[71]
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Zhiruo Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Melroy Maben, Raj Mehta, Wayne Chi, Lawrence Keunho Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. Theagentcompany: Benchmarking LLM agents on consequential real ...
work page 2026
-
[72]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[73]
Tongxin Yin, Reilly Raab, Mingyan Liu, and Yang Liu. Long-term fairness with unknown dynamics.Advances in Neural Information Processing Systems, 36:55110–55139, 2023
work page 2023
-
[74]
R-judge: Benchmarking safety risk awareness for LLM agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. R-judge: Benchmarking safety risk awareness for LLM agents. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages ...
work page 2024
-
[75]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, Bangkok, Thailand, August 2024. Association for Comput...
work page 2024
-
[76]
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng YAN. Agentracer: Who is inducing failure in the LLM agentic systems? InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[77]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. Which agent causes task failures and when? On automated failure attribution of LLM multi-agent systems. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff...
work page 2025
-
[78]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024. 14 A Implementation Details of Neuro-Symbolic Trial Thi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.