Looking Is Not Picking: An Attention-Segment Account of Tool-Selection Failures in LLM Agents
Pith reviewed 2026-06-30 10:48 UTC · model grok-4.3
The pith
LLM agents attend most to the correct tool yet still select the wrong one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
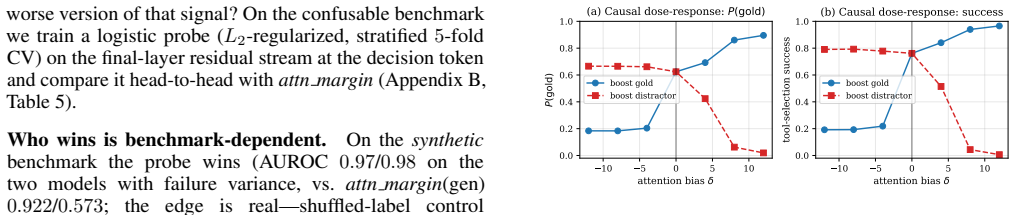
By per-candidate attention argmax the model attends most to the correct tool 80% of the time (vs. 21% chance), and the gold is the under-attended segment on only 10%: it looks at the right tool and still picks wrong. This directly refutes the intuitive crowded-harness explanation: the failure is at the decision readout, not the harness, and we pin it there three ways with input repairs, representation-invariant interventions, and a training-free selector.
What carries the argument
Per-candidate attention argmax on labeled tool-definition segments, which identifies the tool receiving the model's primary focus during selection.
If this is right
- Input-side repairs recover at most 23% of failures while readout interventions recover 59-91%.
- Additive attention bias and residual-stream steering fix largely the same set of failures across representations.
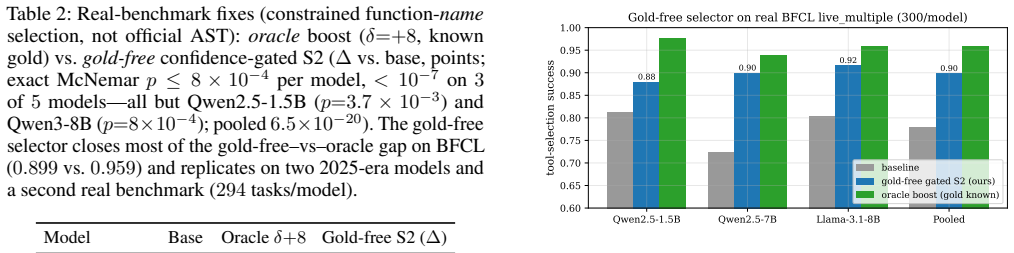
- Per-segment attention as a selector recovers most of the gap to oracle performance on function-name selection.
- The causal attention-bias effect is bidirectional and monotonic across model sizes.
Where Pith is reading between the lines
- Attention signals could be directly read out at inference time to rerank or bias tool choices in deployed agents.
- The readout localization may extend to other tasks where models must choose among many context options.
- The selector's positive results on single-turn settings suggest testing in multi-turn agent loops.
Load-bearing premise
That attention argmax on a labeled tool segment means the model has effectively processed that tool for the purpose of making its selection choice.
What would settle it
An experiment that artificially reduces attention on the correct tool while measuring whether selection accuracy drops would test whether attention tracks the information used for the final pick.
Figures



read the original abstract
LLM agents mis-call tools, and the natural guess is that the model failed to see the right tool in a crowded harness. We show the opposite through a lens concurrent work sets aside -- the model's attention to labeled tool-definition segments. On real BFCL failures, by per-candidate attention argmax the model attends most to the correct tool 80% of the time (vs. 21% chance), and the gold is the under-attended segment on only 10%: it looks at the right tool and still picks wrong. This directly refutes the intuitive "crowded-harness / lost-in-the-middle" explanation: the failure is at the decision readout, not the harness, and we pin it there three ways. (1) Input vs. readout: repairing the prompt (reordering or duplicating the gold tool) recovers <=23% of failures, while readout-side interventions recover 59-91%. (2) Representation-invariance: two gold-pointed interventions in different representations -- an additive attention-logit bias and a residual-stream steering vector -- recover largely the same failures (per-task Jaccard 0.865 pooled, 0.79-0.91 per model), so the bottleneck is localized to the readout independent of which representation is poked. (3) A training-free, gold-free selector: per-segment attention closes most of the gold-free-vs-oracle gap on BFCL (+11.9 pts pooled function-name selection vs. +17.9-pt oracle headroom) and adds +14.9 pts on Seal-Tools; every model positive (exact McNemar p<=8e-4 each). Scopes differ: the causal attention-bias dose-response is bidirectional and monotonic on 10 mask-honoring models (3-32B), the full 0.5-32B span carrying only the correlational diagnostic; the deployable selector is evaluated on 5 single-turn models and does not yet transfer to a multi-turn loop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool-selection failures in LLM agents (e.g., on BFCL) are not primarily due to failing to attend to the correct tool in crowded prompts, but instead occur at the decision readout stage. Key evidence: on real failures, per-candidate attention argmax shows the model attends most to the correct tool 80% of the time (vs. 21% chance) and the gold tool is under-attended in only 10% of cases; prompt repairs recover <=23% of failures while readout interventions recover 59-91%; two readout interventions in different representations recover largely the same failures (Jaccard 0.865 pooled); and a training-free per-segment attention selector closes most of the gold-free-vs-oracle gap (+11.9 pts pooled on BFCL, +14.9 on Seal-Tools).
Significance. If the results hold, the work offers a concrete localization of agent tool-use failures to readout rather than harness/attention, with practical value in the training-free selector and the bidirectional dose-response of attention bias. The representation-invariance result and the attention-based diagnostic provide falsifiable, intervention-grounded evidence that distinguishes this account from the intuitive crowded-harness explanation.
major comments (2)
- [Abstract / attention diagnostic] Abstract and the attention diagnostic: the central claim that 'it looks at the right tool and still picks wrong' rests on interpreting per-candidate attention argmax as evidence that the model has effectively processed the tool's semantics for selection. Attention to labeled segments could instead be driven by surface cues (tool name tokens, label position, or format) without encoding the parameter schema needed for correct choice. The readout interventions are independent of this diagnostic and do not validate whether the attention weights reflect the internal state used for the final decision.
- [Methods / Results] Methods and results sections: the reported percentages (80% attention to correct tool, 59-91% readout recovery, Jaccard overlaps) and the definition of 'failures' and 'attention segments' lack explicit details on data exclusion rules, exact computation of per-candidate argmax, and how segments are labeled. These gaps directly affect verification of the load-bearing numbers and the claim that the failure is localized to readout.
minor comments (1)
- [Abstract / Scope] Scope paragraph at end of abstract: the distinction between the causal attention-bias results (10 mask-honoring models) and the correlational diagnostic (full 0.5-32B span) should be stated more explicitly in the main text to avoid overgeneralization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications and agree to revisions that improve verifiability while preserving the core claims supported by the convergent evidence.
read point-by-point responses
-
Referee: [Abstract / attention diagnostic] Abstract and the attention diagnostic: the central claim that 'it looks at the right tool and still picks wrong' rests on interpreting per-candidate attention argmax as evidence that the model has effectively processed the tool's semantics for selection. Attention to labeled segments could instead be driven by surface cues (tool name tokens, label position, or format) without encoding the parameter schema needed for correct choice. The readout interventions are independent of this diagnostic and do not validate whether the attention weights reflect the internal state used for the final decision.
Authors: The attention diagnostic is correlational and serves to rule out the simplest 'failure to attend' account by showing that the correct segment receives the highest average attention in 80% of failures. We acknowledge that attention could be driven partly by surface features rather than full semantic integration of schemas, and that argmax alone does not prove the model has encoded the parameter details needed for selection. The readout interventions and their representation-invariance provide independent causal evidence for localization to the decision stage. We will revise the abstract and add an explicit limitations paragraph noting this interpretive boundary while retaining the claim that the pattern is inconsistent with harness/attention failure. revision: partial
-
Referee: [Methods / Results] Methods and results sections: the reported percentages (80% attention to correct tool, 59-91% readout recovery, Jaccard overlaps) and the definition of 'failures' and 'attention segments' lack explicit details on data exclusion rules, exact computation of per-candidate argmax, and how segments are labeled. These gaps directly affect verification of the load-bearing numbers and the claim that the failure is localized to readout.
Authors: We agree these details are required for verification. The revised Methods section will include a dedicated subsection specifying: (i) exclusion rules (single-tool BFCL failures where a function call was emitted but mismatched the gold; no multi-gold or no-call cases), (ii) per-candidate argmax (mean attention over all tokens within each delimited segment, followed by argmax across candidates), and (iii) segment labeling (boundaries taken from the prompt's tool-definition delimiters). We will also release the exact analysis code. revision: yes
Circularity Check
No circularity: empirical attention diagnostics and interventions are independent measurements
full rationale
The paper's central claims rest on direct computation of per-candidate attention argmax over labeled tool segments on BFCL failure cases, plus measured recovery rates from prompt repairs versus readout interventions (additive bias, steering vectors) and a training-free selector. These are observational and interventional statistics computed from model activations and outputs on external benchmarks; none reduce by definition or self-citation to the target quantities. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain is self-contained against the reported data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-candidate attention argmax on tool-definition segments indicates the model is attending to that tool for selection purposes.
Reference graph
Works this paper leans on
-
[1]
Transactions of the Association for Computational Linguistics (TACL) , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics (TACL) , volume =
-
[2]
International Conference on Learning Representations (ICLR) , year =
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations (ICLR) , year =
-
[3]
Findings of the Association for Computational Linguistics (ACL Findings) , year =
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization , author =. Findings of the Association for Computational Linguistics (ACL Findings) , year =
-
[4]
International Conference on Learning Representations (ICLR) , year =
Retrieval Head Mechanistically Explains Long-Context Factuality , author =. International Conference on Learning Representations (ICLR) , year =
-
[5]
International Conference on Learning Representations (ICLR) , year =
Function Vectors in Large Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[6]
International Conference on Machine Learning (ICML) , year =
Which Attention Heads Matter for In-Context Learning? , author =. International Conference on Machine Learning (ICML) , year =
-
[7]
Transformer Circuits Thread , year =
In-context Learning and Induction Heads , author =. Transformer Circuits Thread , year =
-
[8]
Instruction Following by Principled Boosting Attention of Large Language Models , author =. 2025 , note =. 2506.13734 , archivePrefix =
-
[9]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Mixture of In-Context Experts Enhance LLMs' Long Context Awareness , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
Spotlight Your Instructions: Instruction-following with Dynamic Attention Steering , author =. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =. 2026 , note =
2026
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
ContextCite: Attributing Model Generation to Context , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
International Conference on Machine Learning (ICML) , year =
AttnLRP: Attention-Aware Layer-Wise Relevance Propagation for Transformers , author =. International Conference on Machine Learning (ICML) , year =
-
[15]
Proceedings of the Association for Computational Linguistics (ACL) , pages =
Quantifying Attention Flow in Transformers , author =. Proceedings of the Association for Computational Linguistics (ACL) , pages =
-
[16]
Proceedings of NAACL-HLT , pages =
Attention is not Explanation , author =. Proceedings of NAACL-HLT , pages =
-
[17]
Proceedings of EMNLP-IJCNLP , pages =
Attention is not not Explanation , author =. Proceedings of EMNLP-IJCNLP , pages =
-
[18]
2024 , howpublished =
Berkeley Function-Calling Leaderboard (BFCL) , author =. 2024 , howpublished =
2024
-
[19]
and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E
Patil, Shishir G. and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The
-
[20]
Yi: Open Foundation Models by 01.AI
Yi: Open Foundation Models by 01.AI , author =. arXiv preprint arXiv:2403.04652 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author =. arXiv preprint arXiv:2404.14219 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , booktitle =
-
[23]
International Conference on Learning Representations (ICLR) , year =
AgentBench: Evaluating LLMs as Agents , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
International Conference on Learning Representations (ICLR) , year =
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Proceedings of the ACM SIGOPS Symposium on Operating Systems Principles (SOSP) , year =
Efficient Memory Management for Large Language Model Serving with PagedAttention , author =. Proceedings of the ACM SIGOPS Symposium on Operating Systems Principles (SOSP) , year =
-
[29]
Tool Calling is Linearly Readable and Steerable in Language Models
Tool Calling is Linearly Readable and Steerable in Language Models , author =. 2026 , note =. 2605.07990 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
ASA: Backbone-Training-Free Representation Engineering for Tool-Calling Agents
Wang, Youjin and Zhou, Run and Fu, Rong and Cao, Shuaishuai and Zeng, Hongwei and Lu, Jiaxuan and Fan, Sicheng and Zhao, Jiaqiao and Pan, Liangming , year =. 2602.04935 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Beyond the Black Box: Interpretability of Agentic AI Tool Use
Tatsat, Hariom and Shater, Ariye , year =. Beyond the Black Box: Interpretability of Agentic. 2605.06890 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Internal Representations as Indicators of Hallucinations in Agent Tool Selection , author =. 2026 , note =. 2601.05214 , archivePrefix =
-
[33]
LLM Agents Already Know When to Call Tools -- Even Without Reasoning
Sun, Chung-En and Liu, Linbo and Yan, Ge and Wang, Zimo and Weng, Tsui-Wei , year =. 2605.09252 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Tell Your Model Where to Attend: Post-hoc Attention Steering for
Zhang, Qingru and Singh, Chandan and Liu, Liyuan and Liu, Xiaodong and Yu, Bin and Gao, Jianfeng and Zhao, Tuo , booktitle =. Tell Your Model Where to Attend: Post-hoc Attention Steering for. 2024 , note =
2024
-
[35]
Wang, Zhiqiang and Du, Haohua and Shi, Guanquan and Zhang, Junyang and Cheng, HaoRan and Yao, Yunhao and Guo, Kaiwen and Li, Xiang-Yang , year =. 2508.20412 , archivePrefix =
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Detecting High-Stakes Interactions with Activation Probes , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[37]
Sadani, Anuj and Kumar, Deepak , year =. Tool Attention Is All You Need: Dynamic Tool Gating and Lazy Schema Loading for Eliminating the. 2604.21816 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
CCF International Conference on Natural Language Processing and Chinese Computing (NLPCC) , pages =
Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark , author =. CCF International Conference on Natural Language Processing and Chinese Computing (NLPCC) , pages =. 2024 , note =
2024
-
[39]
Enhancing Multi-Agent Communication through Attention Steering with Context Relevance
Enhancing Multi-Agent Communication through Attention Steering with Context Relevance , author =. 2026 , note =. 2605.30136 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Accurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention , author =. 2026 , note =. 2602.03338 , archivePrefix =
-
[41]
Qwen3 Technical Report , author =. 2025 , note =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Prabhakar, Akshara and Liu, Zuxin and Zhu, Ming and Zhang, Jianguo and Awalgaonkar, Tulika and Wang, Shiyu and Liu, Zhiwei and Chen, Haolin and Hoang, Thai and Niebles, Juan Carlos and Heinecke, Shelby and Yao, Weiran and Wang, Huan and Savarese, Silvio and Xiong, Caiming , year =. 2504.03601 , archivePrefix =
-
[43]
arXiv preprint arXiv:2602.08082 , year =
Spectral Guardrails for Agents in the Wild: Detecting Tool-Use Hallucinations via Attention Topology , author =. arXiv preprint arXiv:2602.08082 , year =
-
[44]
Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking , author =. arXiv preprint arXiv:2602.22591 , note =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
How Many Tools Should an LLM Agent See? A Chance-Corrected Answer
How Many Tools Should an LLM Agent See? A Chance-Corrected Answer , author =. arXiv preprint arXiv:2605.24660 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Skillrouter: Retrieve-and-rerank skill selection for llm agents at scale,
SkillRouter: Skill Routing for LLM Agents at Scale , author =. arXiv preprint arXiv:2603.22455 , year =
-
[47]
Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use , author =. arXiv preprint arXiv:2605.14038 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.