GeoWorld: Geometric World Models
Pith reviewed 2026-05-21 11:35 UTC · model grok-4.3
The pith
GeoWorld maps latent representations to hyperbolic space to preserve geometric and hierarchical structures for stable multi-step planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
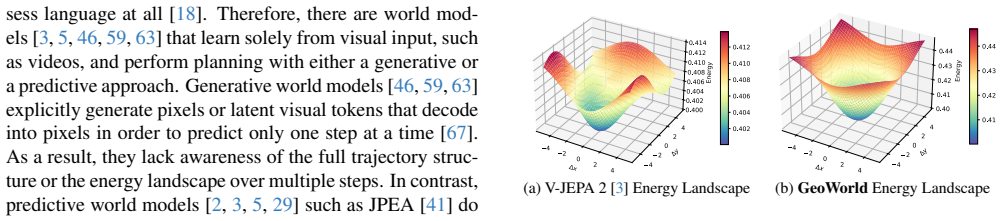
GeoWorld preserves geometric structure and hierarchical relations through a Hyperbolic JEPA, which maps latent representations from Euclidean space onto hyperbolic manifolds, and introduces Geometric Reinforcement Learning for energy-based optimization, enabling stable multi-step planning in hyperbolic latent space with measured gains on standard benchmarks.
What carries the argument
Hyperbolic JEPA that maps Euclidean latent representations onto hyperbolic manifolds to preserve geometric structure and hierarchical relations.
If this is right
- Around 3% success-rate improvement in 3-step planning tasks.
- Around 2% success-rate improvement in 4-step planning tasks compared with V-JEPA 2.
- Reduced degradation across extended rollouts in visual planning.
- Demonstrated effectiveness on the CrossTask and COIN datasets.
Where Pith is reading between the lines
- Hyperbolic latent spaces may help energy-based models handle other naturally hierarchical data such as graphs or tree-structured tasks.
- The same mapping technique could be tested on longer planning horizons or in robotic control settings that rely on visual sequences.
- If the energy landscape remains well-behaved, the approach might combine with other predictive architectures beyond JEPA variants.
Load-bearing premise
Mapping Euclidean latent representations onto hyperbolic manifolds reliably preserves the underlying geometric and hierarchical structure among states without introducing instabilities or new distortions that undermine the energy landscape for planning.
What would settle it
Training an otherwise identical model with Euclidean latents instead of hyperbolic ones and measuring whether success rates in 3-step and 4-step planning on CrossTask or COIN remain the same or drop.
Figures




read the original abstract
Energy-based predictive world models provide a powerful approach for multi-step visual planning by reasoning over latent energy landscapes rather than generating pixels. However, existing approaches face two major challenges: (i) their latent representations are typically learned in Euclidean space, neglecting the underlying geometric and hierarchical structure among states, and (ii) they struggle with long-horizon prediction, which leads to rapid degradation across extended rollouts. To address these challenges, we introduce GeoWorld, a geometric world model that preserves geometric structure and hierarchical relations through a Hyperbolic JEPA, which maps latent representations from Euclidean space onto hyperbolic manifolds. We further introduce Geometric Reinforcement Learning for energy-based optimization, enabling stable multi-step planning in hyperbolic latent space. Extensive experiments on CrossTask and COIN demonstrate around 3% SR improvement in 3-step planning and 2% SR improvement in 4-step planning compared to the state-of-the-art V-JEPA 2. Project website: https://steve-zeyu-zhang.github.io/GeoWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoWorld, a geometric world model for multi-step visual planning in energy-based predictive models. It identifies two challenges with prior work: Euclidean latent spaces that neglect geometric and hierarchical state structure, and rapid degradation in long-horizon rollouts. The proposed solution maps Euclidean latents to hyperbolic manifolds via a Hyperbolic JEPA to preserve structure and hierarchy, combined with Geometric Reinforcement Learning for energy-based optimization in hyperbolic space. Experiments on CrossTask and COIN report ~3% SR gains in 3-step planning and ~2% SR gains in 4-step planning relative to V-JEPA 2.
Significance. If the hyperbolic mapping demonstrably preserves hierarchical relations and stabilizes the planning energy landscape without new distortions, the work would offer a concrete architectural route to incorporating non-Euclidean geometry into world models. The emphasis on an architectural change rather than additional free parameters is a positive feature. The modest reported gains, however, require stronger mechanistic evidence before the approach can be viewed as a clear advance over Euclidean baselines.
major comments (2)
- [§3] §3 (Hyperbolic JEPA description): The central claim that mapping Euclidean latents onto hyperbolic manifolds reliably preserves geometric and hierarchical structure is unsupported by any explicit fidelity metric, distance-preservation test, or hierarchy-recovery analysis. This is load-bearing for the multi-step planning stability argument; without such checks, curvature-induced distortions remain a plausible risk to the energy landscape.
- [§4] §4 (Experiments and results): The reported 3% and 2% SR improvements on CrossTask/COIN lack ablations that isolate the Hyperbolic JEPA component from the Geometric RL optimizer or other implementation details. Attribution of gains specifically to geometric preservation is therefore not established.
minor comments (2)
- [Abstract] Abstract and §4: The success-rate improvements are stated as 'around 3%' and 'around 2%' without reported standard deviations, number of runs, or statistical significance; adding these would strengthen the empirical claims.
- [§3] Notation: The definition of the hyperbolic manifold and the precise form of the JEPA loss in hyperbolic space would benefit from an explicit equation reference to avoid ambiguity in the mapping procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence would strengthen the claims regarding structure preservation and the source of performance gains. We address each major comment below and will incorporate revisions to provide the requested analyses and controls.
read point-by-point responses
-
Referee: [§3] §3 (Hyperbolic JEPA description): The central claim that mapping Euclidean latents onto hyperbolic manifolds reliably preserves geometric and hierarchical structure is unsupported by any explicit fidelity metric, distance-preservation test, or hierarchy-recovery analysis. This is load-bearing for the multi-step planning stability argument; without such checks, curvature-induced distortions remain a plausible risk to the energy landscape.
Authors: We acknowledge that the current manuscript does not report explicit quantitative fidelity metrics, distance-preservation tests, or hierarchy-recovery analyses to verify structure preservation after the Euclidean-to-hyperbolic mapping. The Hyperbolic JEPA component is motivated by the established theoretical properties of hyperbolic geometry for embedding hierarchical relations with reduced distortion compared to Euclidean space. To directly address the concern about potential curvature-induced distortions, we will add a dedicated subsection to §3 that includes (i) pairwise distance preservation metrics (relative error between original Euclidean distances and hyperbolic geodesic distances) and (ii) a hierarchy-recovery evaluation using measures such as dendrogram purity on sampled state trajectories. These additions will provide empirical support for the stability argument. revision: yes
-
Referee: [§4] §4 (Experiments and results): The reported 3% and 2% SR improvements on CrossTask/COIN lack ablations that isolate the Hyperbolic JEPA component from the Geometric RL optimizer or other implementation details. Attribution of gains specifically to geometric preservation is therefore not established.
Authors: We agree that the reported gains are from the integrated system and that isolating the Hyperbolic JEPA contribution from the Geometric RL optimizer is necessary for clear attribution. The current evaluation compares the full GeoWorld model against V-JEPA 2 but does not include component-wise controls. In the revision we will add ablations that (i) apply Geometric RL on top of the original Euclidean V-JEPA 2 latents and (ii) use Hyperbolic JEPA with standard (non-geometric) energy-based optimization. These controls will help attribute improvements specifically to the geometric mapping while acknowledging that the two components are designed to work together. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained via architectural proposal and empirical evaluation
full rationale
The paper's core derivation consists of proposing a Hyperbolic JEPA to map Euclidean latents onto hyperbolic manifolds for preserving geometric and hierarchical structure, followed by Geometric Reinforcement Learning for energy-based multi-step planning. These are presented as design choices, with performance gains (approximately 3% and 2% SR improvements on 3-step and 4-step planning) reported via direct comparison to the external baseline V-JEPA 2 on CrossTask and COIN. No equations, fitted parameters, or predictions in the abstract reduce to inputs by construction, and there are no load-bearing self-citations or uniqueness theorems invoked from the authors' prior work. The chain is independent: model architecture, training procedure, and benchmark evaluation stand on their own without self-referential reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean and IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJcost definition and CostAlphaLog with cosh(α t) forms; dAlembert_to_ODE_general echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the hyperbolic latent state is obtained as s^x_{t,H} = exp_0(s^x_t) ... d_H(ŝ, s) = (1/√c) arcosh(1 + 2c ∥ŝ−s∥² / ((1−c∥ŝ∥²)(1−c∥s∥²))) ... energy cost c_t = d_H ... triangle inequality regularization L_Δ
-
IndisputableMonolith/Foundation/AlexanderDuality.lean and IndisputableMonolith/Foundation/ArithmeticFromLogic.leanSphereAdmitsCircleLinking and embed_strictMono_of_one_lt (order-preserving embeddings) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
preserves geometric structure and hierarchical relations through a Hyperbolic JEPA ... geodesic distances naturally encode hierarchical relations among states
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
How You Move Tells What You'll Do: Trajectory-Conditioned Egocentric Prediction
TrajPilot predicts candidate future trajectories from egocentric context and uses them to condition action prediction in an embedding space, outperforming VLM and planner baselines on Ego-Exo4D, Ego4D, and other datas...
-
Recovering Physical Dynamics from Discrete Observations via Intrinsic Differential Consistency
Enforcing semi-group consistency on a time-conditioned secant velocity field via Symmetry Rupture improves rollout accuracy and efficiency when learning physical dynamics from discrete observations.
-
HSG: Hyperbolic Scene Graph
Hyperbolic Scene Graph (HSG) learns embeddings in hyperbolic space for better hierarchical structure in scene graphs, achieving graph IoU of 33.51 versus 25.37 for the best Euclidean baseline.
-
Grounded World Model for Semantically Generalizable Planning
A vision-language-aligned world model turns visuomotor MPC into a language-following planner that reaches 87% success on 288 unseen semantic tasks where standard VLAs drop to 22%.
Reference graph
Works this paper leans on
-
[1]
Uncertainty-aware antic- ipation of activities
Yazan Abu Farha and Juergen Gall. Uncertainty-aware antic- ipation of activities. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops, pages 0–0, 2019. 6, 7, 10
work page 2019
-
[2]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023. 2, 3, 1, 4
work page 2023
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self- supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. 1, 2, 3, 6, 7, 8, 4, 10, 12, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Vi- creg: Variance-invariance-covariance regularization for self- supervised learning
Adrien Bardes, Jean Ponce, and Yann Lecun. Vi- creg: Variance-invariance-covariance regularization for self- supervised learning. InICLR 2022-International Conference on Learning Representations, 2022. 2
work page 2022
-
[5]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual rep- resentations from video.Transactions on Machine Learning Research, 2024. 2, 3, 1, 4
work page 2024
-
[6]
Dynamic programming.science, 153 (3731):34–37, 1966
Richard Bellman. Dynamic programming.science, 153 (3731):34–37, 1966. 8
work page 1966
-
[7]
Procedure planning in instructional videos via contextual modeling and model- based policy learning
Jing Bi, Jiebo Luo, and Chenliang Xu. Procedure planning in instructional videos via contextual modeling and model- based policy learning. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15611– 15620, 2021. 3, 6, 7, 9
work page 2021
-
[8]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A Vision–Language– Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Regularizing model-based planning with energy-based models
Rinu Boney, Juho Kannala, and Alexander Ilin. Regularizing model-based planning with energy-based models. InConfer- ence on Robot Learning, pages 182–191. PMLR, 2020. 1
work page 2020
-
[10]
David Brandfonbrener, Ofir Nachum, and Joan Bruna. In- verse dynamics pretraining learns good representations for multitask imitation.Advances in Neural Information Pro- cessing Systems, 36:66953–66978, 2023. 4
work page 2023
-
[11]
Springer Science & Business Media,
Martin R Bridson and André Haefliger.Metric spaces of non-positive curvature. Springer Science & Business Media,
-
[12]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 2
work page 2015
-
[13]
Hyperbolic deep reinforce- ment learning
Edoardo Cetin, Benjamin Paul Chamberlain, Michael M Bronstein, and Jonathan J Hunt. Hyperbolic deep reinforce- ment learning. InThe Eleventh International Conference on Learning Representations, 2023. 5, 7
work page 2023
-
[14]
Hyperbolic graph convolutional neural networks
Ines Chami, Zhitao Ying, Christopher Ré, and Jure Leskovec. Hyperbolic graph convolutional neural networks. Advances in neural information processing systems, 32,
-
[15]
Procedure planning in instructional videos
Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. InEuropean Conference on Computer Vision, pages 334–350. Springer, 2020. 3, 6, 7, 8, 9
work page 2020
-
[16]
Planning with reasoning using vision language world model.arXiv preprint arXiv:2509.02722, 2025
Delong Chen, Theo Moutakanni, Willy Chung, Yejin Bang, Ziwei Ji, Allen Bolourchi, and Pascale Fung. Planning with reasoning using vision language world model.arXiv preprint arXiv:2509.02722, 2025. 3
-
[17]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Why animals don’t have language.Tanner lectures on human values, 19: 173–210, 1998
Dorothy L Cheney and Robert M Seyfarth. Why animals don’t have language.Tanner lectures on human values, 19: 173–210, 1998. 2
work page 1998
-
[19]
Krzysztof Chris Ciesielski, Alexandre Xavier Falcão, and Paulo A V Miranda. Path-value functions for which dijkstra’s algorithm returns optimal mapping.Journal of Mathematical Imaging and Vision, 60(7):1025–1036, 2018. 8
work page 2018
-
[20]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1, 3, 6, 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Balázs Csanád Csáji and László Monostori. Value function based reinforcement learning in changing markovian envi- ronments.Journal of Machine Learning Research, 9(8),
-
[22]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self- forcing++: Towards minute-scale high-quality video genera- tion.arXiv preprint arXiv:2510.02283, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A tutorial on the cross-entropy method.Annals of operations research, 134(1):19–67, 2005
Pieter-Tjerk De Boer, Dirk P Kroese, Shie Mannor, and Reuven Y Rubinstein. A tutorial on the cross-entropy method.Annals of operations research, 134(1):19–67, 2005. 3, 6, 7, 4
work page 2005
-
[24]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation with- out vector quantization.arXiv preprint arXiv:2412.14169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Hyper- bolic image-text representations
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Shanmukha Ramakrishna Vedantam. Hyper- bolic image-text representations. InInternational Confer- ence on Machine Learning, pages 7694–7731. PMLR, 2023. 5, 11
work page 2023
-
[26]
Learning iterative reasoning through energy mini- mization
Yilun Du, Shuang Li, Joshua Tenenbaum, and Igor Mor- datch. Learning iterative reasoning through energy mini- mization. InInternational Conference on Machine Learning, pages 5570–5582. PMLR, 2022. 1
work page 2022
-
[27]
Who let the dogs out? modeling dog behavior from visual data
Kiana Ehsani, Hessam Bagherinezhad, Joseph Redmon, Roozbeh Mottaghi, and Ali Farhadi. Who let the dogs out? modeling dog behavior from visual data. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4051–4060, 2018. 6, 7, 10
work page 2018
-
[28]
Hyperbolic neural networks.Advances in neural informa- tion processing systems, 31, 2018
Octavian Ganea, Gary Bécigneul, and Thomas Hofmann. Hyperbolic neural networks.Advances in neural informa- tion processing systems, 31, 2018. 5, 7
work page 2018
-
[29]
Quentin Garrido, Mahmoud Assran, Nicolas Ballas, Adrien Bardes, Laurent Najman, and Yann LeCun. Learning and leveraging world models in visual representation learning. arXiv preprint arXiv:2403.00504, 2024. 2, 3, 4
-
[30]
Hyperbolic contrastive learning for visual representations beyond objects
Songwei Ge, Shlok Mishra, Simon Kornblith, Chun-Liang Li, and David Jacobs. Hyperbolic contrastive learning for visual representations beyond objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6840–6849, 2023. 5
work page 2023
-
[31]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on com- puter vision, pages 5842...
work page 2017
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Ting Huang, Zeyu Zhang, and Hao Tang. 3d-r1: Enhancing reasoning in 3d vlms for unified scene understanding.arXiv preprint arXiv:2507.23478, 2025. 1
-
[34]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train- test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: A Vision–Language–Action Model with Open-World General- ization.arXiv preprint arXiv:2504.16054, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Propose, assess, search: Harnessing llms for goal-oriented planning in instructional videos
Md Mohaiminul Islam, Tushar Nagarajan, Huiyu Wang, Fu- Jen Chu, Kris Kitani, Gedas Bertasius, and Xitong Yang. Propose, assess, search: Harnessing llms for goal-oriented planning in instructional videos. InEuropean Conference on Computer Vision, pages 436–452. Springer, 2024. 3, 6, 7, 9
work page 2024
-
[37]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics hu- man action video dataset.arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Philip J Kellman, ME Arterberry, W Damon, RM Lerner, D Kuhn, RS Siegler, et al. Infant visual perception. 2006. 1
work page 2006
-
[39]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Bal- akrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InRSS 2024 Workshop: Data Generation for Robotics. 3
work page 2024
-
[40]
Hmdb: a large video database for human motion recognition
Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for human motion recognition. In2011 Inter- national conference on computer vision, pages 2556–2563. IEEE, 2011. 2
work page 2011
-
[41]
A path towards autonomous machine intelli- gence version 0.9
Yann LeCun. A path towards autonomous machine intelli- gence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62,
work page 2022
-
[42]
A language-first approach for procedure planning
Jiateng Liu, Sha Li, Zhenhailong Wang, Manling Li, and Heng Ji. A language-first approach for procedure planning. InFindings of the Association for Computational Linguis- tics: ACL 2023, pages 1941–1954, 2023. 3, 6, 7, 9
work page 2023
-
[43]
Jinlai Liu, Jian Han, Bin Yan, Hui Wu, Fengda Zhu, Xing Wang, Yi Jiang, Bingyue Peng, and Zehuan Yuan. Infini- tystar: Unified spacetime autoregressive modeling for visual generation.arXiv preprint arXiv:2511.04675, 2025. 3
-
[44]
Nav-r1: Reasoning and navigation in embodied scenes
Qingxiang Liu, Ting Huang, Zeyu Zhang, and Hao Tang. Nav-r1: Reasoning and navigation in embodied scenes. arXiv preprint arXiv:2509.10884, 2025. 1
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Struc- tured world models from human videos
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Struc- tured world models from human videos. 2023. 2, 3, 4
work page 2023
-
[47]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InProceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640, 2019. 2
work page 2019
-
[48]
Melanie Mitchell and David C Krakauer. The debate over understanding in ai’s large language models.Proceedings of the National Academy of Sciences, 120(13):e2215907120,
-
[49]
Triangle inequality for in- verse optimal control.IEEE Access, 11:119187–119199,
Sho Mitsuhashi and Shin Ishii. Triangle inequality for in- verse optimal control.IEEE Access, 11:119187–119199,
-
[50]
Why not use your text- book? knowledge-enhanced procedure planning of instruc- tional videos
Kumaranage Ravindu Yasas Nagasinghe, Honglu Zhou, Malitha Gunawardhana, Martin Renqiang Min, Daniel Harari, and Muhammad Haris Khan. Why not use your text- book? knowledge-enhanced procedure planning of instruc- tional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18816– 18826, 2024. 3, 6, 7, 8, 9
work page 2024
-
[51]
Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations.Advances in neural information processing systems, 30, 2017. 2, 5
work page 2017
-
[52]
Yulei Niu, Wenliang Guo, Long Chen, Xudong Lin, and Shih-Fu Chang. Schema: State changes matter for pro- cedure planning in instructional videos.arXiv preprint arXiv:2403.01599, 2024. 3, 6, 7, 8, 9
-
[53]
Gpt-5 system card, version 1.0, 2025-08-13
OpenAI. Gpt-5 system card, version 1.0, 2025-08-13. 2025. https : / / cdn . openai . com / gpt - 5 - system - card.pdf. 1, 3, 6, 8, 9
work page 2025
-
[54]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 2
work page 2022
-
[55]
Avik Pal, Max van Spengler, Guido Maria D’Amely di Me- lendugno, Alessandro Flaborea, Fabio Galasso, and Pascal Mettes. Compositional entailment learning for hyperbolic vision-language models.arXiv preprint arXiv:2410.06912,
-
[56]
Pretrained language models as visual planners for human assistance
Dhruvesh Patel, Hamid Eghbalzadeh, Nitin Kamra, Michael Louis Iuzzolino, Unnat Jain, and Ruta Desai. Pretrained language models as visual planners for human assistance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15302–15314, 2023. 3
work page 2023
-
[57]
An inductive bias for distances: Neural nets that respect the tri- angle inequality
Silviu Pitis, Harris Chan, Kiarash Jamali, and Jimmy Ba. An inductive bias for distances: Neural nets that respect the tri- angle inequality. InInternational Conference on Learning Representations, 2020. 8
work page 2020
-
[58]
Autoregressive video generation beyond next frames prediction.arXiv preprint arXiv:2509.24081, 2025
Sucheng Ren, Chen Chen, Zhenbang Wang, Liangchen Song, Xiangxin Zhu, Alan Yuille, Yinfei Yang, and Jiasen Lu. Autoregressive video generation beyond next frames prediction.arXiv preprint arXiv:2509.24081, 2025. 3
-
[59]
Videoworld: Exploring knowledge learning from unlabeled videos
Zhongwei Ren, Yunchao Wei, Xun Guo, Yao Zhao, Bingyi Kang, Jiashi Feng, and Xiaojie Jin. Videoworld: Exploring knowledge learning from unlabeled videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29029–29039, 2025. 2, 3, 6, 8, 4, 9
work page 2025
-
[60]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Actiondiffu- sion: An action-aware diffusion model for procedure plan- ning in instructional videos
Lei Shi, Paul Bürkner, and Andreas Bulling. Actiondiffu- sion: An action-aware diffusion model for procedure plan- ning in instructional videos. In2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 8816–8825. IEEE, 2025. 3, 6, 7, 9
work page 2025
-
[62]
Mariano Sigman and Stanislas Dehaene. Brain mechanisms of serial and parallel processing during dual-task perfor- mance.Journal of Neuroscience, 28(30):7585–7598, 2008. 1
work page 2008
-
[63]
Hand-object interaction pretraining from videos
Himanshu Gaurav Singh, Antonio Loquercio, Carmelo Sfer- razza, Jane Wu, Haozhi Qi, Pieter Abbeel, and Jitendra Ma- lik. Hand-object interaction pretraining from videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3352–3360. IEEE, 2025. 2, 3, 4
work page 2025
-
[64]
Geri Skenderi, Hang Li, Jiliang Tang, and Marco Cristani. Graph-level representation learning with joint-embedding predictive architectures.Transactions on Machine Learning Research, 2025. 9
work page 2025
-
[65]
Zirui Song, Guangxian Ouyang, Mingzhe Li, Yuheng Ji, Chenxi Wang, Zixiang Xu, Zeyu Zhang, Xiaoqing Zhang, Qian Jiang, Zhenhao Chen, et al. Maniplvm-r1: Rein- forcement learning for reasoning in embodied manipula- tion with large vision-language models.arXiv preprint arXiv:2505.16517, 2025. 1
-
[66]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 2
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[67]
Mark W Spong and Romeo Ortega. On adaptive inverse dy- namics control of rigid robots.IEEE Transactions on Auto- matic Control, 35(1):92–95, 2002. 2, 3, 4
work page 2002
-
[68]
Universal planning networks: Learning generalizable representations for visuomotor control
Aravind Srinivas, Allan Jabri, Pieter Abbeel, Sergey Levine, and Chelsea Finn. Universal planning networks: Learning generalizable representations for visuomotor control. InIn- ternational conference on machine learning, pages 4732–
- [69]
-
[70]
Jiankai Sun, De-An Huang, Bo Lu, Yun-Hui Liu, Bolei Zhou, and Animesh Garg. Plate: Visually-grounded plan- ning with transformers in procedural tasks.IEEE Robotics and Automation Letters, 7(2):4924–4930, 2022. 3, 6, 7, 10
work page 2022
-
[71]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998. 8
work page 1998
-
[72]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207– 1216, 2019. 1, 2, 6, 7, 8, 10, 13
work page 2019
-
[73]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video genera- tion at scale.arXiv preprint arXiv:2505.13211, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Predictive inverse dynam- ics models are scalable learners for robotic manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynam- ics models are scalable learners for robotic manipulation. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 4
work page 2025
-
[75]
Event-guided procedure planning from in- structional videos with text supervision
An-Lan Wang, Kun-Yu Lin, Jia-Run Du, Jingke Meng, and Wei-Shi Zheng. Event-guided procedure planning from in- structional videos with text supervision. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 13565–13575, 2023. 3, 6, 7, 8, 10
work page 2023
-
[76]
Pdpp: Projected diffusion for procedure planning in instructional videos
Hanlin Wang, Yilu Wu, Sheng Guo, and Limin Wang. Pdpp: Projected diffusion for procedure planning in instructional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14836– 14845, 2023. 3, 6, 7, 8, 9
work page 2023
-
[77]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Sheng- long Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 3, 6, 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Yuqing Wang, Tianwei Xiong, Daquan Zhou, Zhijie Lin, Yang Zhao, Bingyi Kang, Jiashi Feng, and Xihui Liu. Loong: Generating minute-level long videos with autoregressive lan- guage models.arXiv preprint arXiv:2410.02757, 2024. 3
-
[79]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 1
work page 2022
-
[80]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1, 3, 6, 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.