Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Pith reviewed 2026-05-22 21:48 UTC · model grok-4.3
The pith
A methodology-centered taxonomy unifies how LLM agents are built, collaborate, and evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
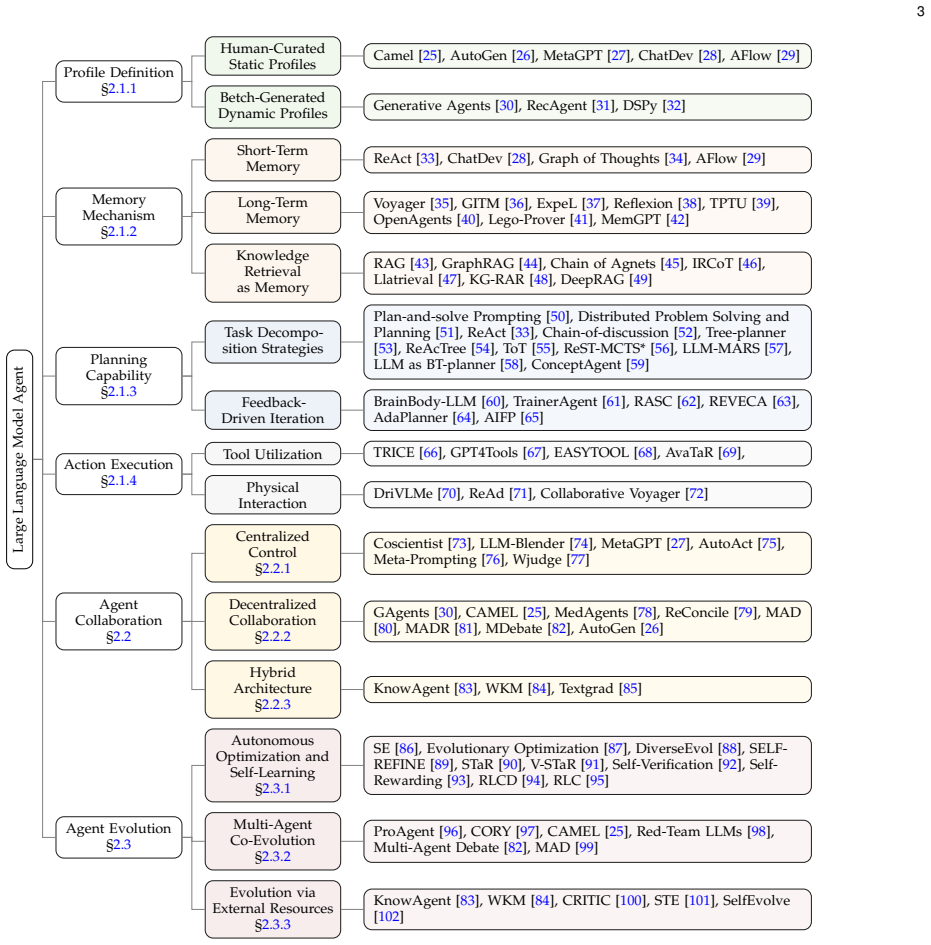
The survey claims that LLM agent systems are best understood by grouping them according to the methods used to construct them, rather than by application or by model size. This grouping reveals direct connections between architectural choices, multi-agent cooperation rules, and the paths agents take as they improve or adapt. The taxonomy therefore turns a fragmented set of papers into one coherent picture that also includes evaluation methods, tool use, open challenges, and real-world domains.
What carries the argument
The methodology-centered taxonomy that groups agent systems by how they are constructed, how they collaborate, and how they change over time.
If this is right
- Future papers can cite the taxonomy to position their contribution instead of starting from scratch.
- Evaluation benchmarks can be organized by the same methodological categories used for design.
- Tool-use and collaboration patterns become comparable across studies once they share the same taxonomy slots.
- Application domains can be mapped to the architectural and evolutionary parts of the taxonomy to spot gaps.
Where Pith is reading between the lines
- If the taxonomy holds, new agent designs could be generated by recombining existing categories rather than starting from scratch.
- The same structure might later be applied to non-LLM agents to test whether the methodological patterns are general.
- Rapid growth in the field will test whether the taxonomy needs frequent updates or whether its top-level categories remain stable.
Load-bearing premise
One fixed taxonomy built around methodology can capture the main patterns in a fast-moving field without leaving out important new designs or forcing unrelated work into the same boxes.
What would settle it
Publication of multiple new LLM agent papers whose designs cannot be placed into any of the taxonomy's main categories without stretching the definitions.
Figures



read the original abstract
The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey on LLM agents that proposes a methodology-centered taxonomy linking architectural foundations, collaboration mechanisms, and evolutionary pathways. It claims to unify fragmented research threads, examines construction, collaboration, evolution, evaluation, tools, challenges, and applications, and provides a GitHub collection of papers.
Significance. If the taxonomy proves comprehensive and representative, the survey would supply a useful organizational framework for a rapidly evolving area, with the GitHub repository serving as a concrete, reusable resource that supports reproducibility of the literature collection.
major comments (2)
- [Abstract / §1] Abstract and §1: The central claim that the survey 'systematically deconstructs LLM agent systems through a methodology-centered taxonomy' and 'unifies fragmented research threads' is load-bearing, yet no details are supplied on literature search strategy, databases, date cutoffs, inclusion/exclusion rules, or total papers reviewed. This omission prevents verification that the taxonomy rests on a representative sample rather than selective or post-hoc groupings.
- [Taxonomy sections] Taxonomy sections (e.g., those presenting the methodology-centered categories): It is unclear how the three main axes (architectural foundations, collaboration mechanisms, evolutionary pathways) were derived from the literature and whether they reflect genuine cross-cutting connections or are imposed categorizations; explicit justification or derivation steps for the taxonomy structure are needed to support the unification assertion.
minor comments (2)
- Ensure the GitHub repository is kept up to date with all references cited in the final version and includes a README describing the collection process.
- Add a short dedicated subsection on survey methodology (search terms, screening process) to make the coverage claims verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. The comments identify opportunities to increase transparency in the survey methodology and taxonomy construction. We address each point below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and §1: The central claim that the survey 'systematically deconstructs LLM agent systems through a methodology-centered taxonomy' and 'unifies fragmented research threads' is load-bearing, yet no details are supplied on literature search strategy, databases, date cutoffs, inclusion/exclusion rules, or total papers reviewed. This omission prevents verification that the taxonomy rests on a representative sample rather than selective or post-hoc groupings.
Authors: We agree that explicit documentation of the literature search process would strengthen verifiability. The revised manuscript will add a dedicated subsection (new §1.3) detailing the systematic review protocol: databases searched (arXiv, ACL Anthology, Google Scholar, NeurIPS/ICLR/ICML proceedings), primary keywords and Boolean combinations used, date range (January 2022–March 2025), inclusion criteria (papers that propose or analyze methodological components of LLM agents), exclusion criteria (purely application-focused works without architectural discussion, non-English papers), and the final count of papers retained. The existing GitHub repository will be annotated with the same protocol to enable independent verification. revision: yes
-
Referee: [Taxonomy sections] Taxonomy sections (e.g., those presenting the methodology-centered categories): It is unclear how the three main axes (architectural foundations, collaboration mechanisms, evolutionary pathways) were derived from the literature and whether they reflect genuine cross-cutting connections or are imposed categorizations; explicit justification or derivation steps for the taxonomy structure are needed to support the unification assertion.
Authors: The three axes emerged from iterative coding of recurring design patterns across the collected papers rather than from a single a-priori framework. In the revision we will insert an explicit derivation paragraph at the start of the taxonomy section that walks through the bottom-up process: (i) clustering of single-agent papers by core architectural choices, (ii) identification of interaction primitives that appear across multi-agent studies, and (iii) extraction of temporal adaptation mechanisms from long-horizon agent work. We will also add a short table showing representative papers that instantiate each axis and the intersections between them, thereby demonstrating that the taxonomy captures observed cross-cutting connections rather than imposing an external structure. revision: yes
Circularity Check
No circularity: survey organizes external literature without derivations or self-referential reductions
full rationale
This is a literature survey paper that proposes a methodology-centered taxonomy to organize existing LLM agent research from external sources. There are no equations, derivations, predictions, fitted parameters, or first-principles results that could reduce to the paper's own inputs by construction. The central claim of unifying threads is an organizational assertion based on reviewed literature, not a load-bearing derivation. No self-citation chains, uniqueness theorems, or ansatzes are invoked in any derivation step, as none exist. The GitHub collection is a supplementary resource for the surveyed papers and does not create circularity under the enumerated patterns. This matches the default expectation for honest non-findings in purely review works that remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 40 Pith papers
-
Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
Agent-ValueBench is the first dedicated benchmark for agent values, showing they diverge from LLM values, form a homogeneous 'Value Tide' across models, and bend under harnesses and skill steering.
-
A Data-Efficient Path to Multilingual LLMs: Language Expansion via Post-training PARAM$\Delta$ Integration into Upcycled MoE
PARAMΔ upcycles dense models to MoE for per-language experts and grafts post-training deltas to enable data-efficient language expansion while preserving original capabilities.
-
Learning Agentic Policy from Action Guidance
ActGuide-RL uses human action data as plan-style guidance in mixed-policy RL to overcome exploration barriers in LLM agents, matching SFT+RL performance on search benchmarks without cold-start training.
-
DRIP-R: A Benchmark for Decision-Making and Reasoning Under Real-World Policy Ambiguity in the Retail Domain
DRIP-R is a new benchmark showing that frontier LLMs systematically disagree on how to resolve identical ambiguous retail policy scenarios, highlighting ambiguity as a core challenge for agent decision-making.
-
WaterAdmin: Orchestrating Community Water Distribution Optimization via AI Agents
WaterAdmin uses a bi-level design with LLM agents for dynamic context abstraction and optimization for real-time pump/valve control, achieving better pressure reliability and lower energy use than traditional methods ...
-
Skill-Conditioned Visual Geolocation for Vision-Language Models
GeoSkill uses an evolving Skill-Graph initialized from expert trajectories and grown via autonomous analysis of successful and failed reasoning rollouts to boost geolocation accuracy, faithfulness, and generalization ...
-
Skill-Conditioned Visual Geolocation for Vision-Language Models
GeoSkill lets vision-language models improve geolocation accuracy and reasoning by maintaining an evolving Skill-Graph that grows through autonomous analysis of successful and failed rollouts on web-scale image data.
-
GenCellAgent: Generalizable, Training-Free Cellular Image Segmentation via Large Language Model Agents
GenCellAgent deploys a planner-executor-evaluator LLM agent loop to automatically select, adapt, and refine segmentation tools for diverse cellular microscopy images, matching or exceeding specialist performance on 4,...
-
From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills
A systematic study across five domains finds model-generated skills yield average gains but non-uniform negative transfer, with a meta-skill improving extraction quality.
-
OEP: Poisoning Self-Evolving LLM Agents via Locally Correct but Non-Transferable Experiences
OEP poisons self-evolving LLM agents by constructing clean edge-case experiences that appear locally valid yet cause harmful over-generalization during reflection, achieving over 50% attack success rate on GPT-4o agen...
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes active external skills in agentic RL via leave-one-skill-out marginal contribution estimates and three lifecycle operations, outperforming baselines by 7.1% on ALFWorld and SearchQA while sh...
-
From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
SSL representation disentangles skill scheduling, structure, and logic using an LLM normalizer, improving skill discovery MRR@50 from 0.649 to 0.729 and risk assessment macro F1 from 0.409 to 0.509 over text baselines.
-
Learning to Evolve: A Self-Improving Framework for Multi-Agent Systems via Textual Parameter Graph Optimization
TPGO represents multi-agent systems as graphs of textual parameters and applies group relative optimization to enable self-improvement from execution history.
-
SafetyALFRED: Evaluating Safety-Conscious Planning of Multimodal Large Language Models
SafetyALFRED shows multimodal LLMs recognize kitchen hazards accurately in QA tests but achieve low success rates when required to mitigate those hazards through embodied planning.
-
ChemGraph-XANES: An Agentic Framework for XANES Simulation and Analysis
An LLM-orchestrated framework automates the full XANES workflow from natural language to normalized spectra and curated data.
-
Chain-of-Authorization: Embedding authorization into large language models
LLMs fine-tuned to output authorization trajectories as a prerequisite for responses achieve high rejection rates for unauthorized prompts while preserving utility in allowed scenarios.
-
EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
EcoGym is a new open benchmark with three economic environments that reveals no leading LLM dominates at sustained plan-and-execute decision making across scenarios.
-
SupChain-Bench: Benchmarking Large Language Models for Real-World Supply Chain Management
SupChain-Bench reveals substantial gaps in LLM reliability for long-horizon supply chain orchestration, while the proposed SupChain-ReAct framework improves tool-calling by autonomously synthesizing procedures.
-
WorldCup Sampling for Multi-bit LLM Watermarking
WorldCup is a new multi-bit LLM watermarking framework that models token sampling as a communication channel and uses hierarchical competition with entropy-aware modulation for robust message embedding and recovery.
-
SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
SciHorizon-GENE is a large-scale benchmark evaluating LLMs on gene-to-function inference across four perspectives, revealing heterogeneity and challenges in faithful, complete, literature-grounded outputs.
-
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
EvolveR enables LLM agents to self-evolve via a closed loop of distilling interaction trajectories into strategic principles offline and retrieving them to guide online decisions with policy reinforcement, yielding be...
-
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Survey that defines agentic RL for LLMs via POMDPs, introduces a taxonomy of planning/tool-use/memory/reasoning capabilities and domains, and compiles open environments from over 500 papers.
-
Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs
Mix-Quant quantizes prefilling to NVFP4 and keeps BF16 for decoding in agentic LLMs, achieving up to 3x prefilling speedup while largely preserving task performance on long-context and agentic benchmarks.
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes the active external skill set in agentic RL via leave-one-skill-out marginal contribution estimates and lifecycle operations, delivering a 7.1% average gain over baselines on ALFWorld and Se...
-
Heterogeneous Scientific Foundation Model Collaboration
Eywa enables language-based agentic AI systems to collaborate with specialized scientific foundation models for improved performance on structured data tasks.
-
Test-time Scaling over Perception: Resolving the Grounding Paradox in Thinking with Images
TTSP resolves the Grounding Paradox by treating perception as a scalable test-time process that generates, filters, and iteratively refines multiple visual exploration traces, outperforming baselines on high-resolutio...
-
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
LLM agent progress depends on externalizing cognitive functions into memory, skills, protocols, and harness engineering that coordinates them reliably.
-
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
The paper identifies twelve protocol-level security risks across MCP, A2A, Agora, and ANP and quantifies wrong-provider tool execution risk in MCP via a measurement-driven case study on multi-server composition.
-
MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
MemOCR renders structured memory as images with adaptive visual density to improve long-horizon reasoning under tight context budgets.
-
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
EvolveR proposes a closed-loop self-evolution system for LLM agents that distills experiences into principles offline and applies reinforcement during online task interactions to achieve better performance on multi-ho...
-
Small Language Models are the Future of Agentic AI
Small language models are sufficiently capable, more suitable, and far more economical than large models for the repetitive tasks that dominate agentic AI systems.
-
CogEvolution: A Human-like Generative Educational Agent to Simulate Student's Cognitive Evolution
CogEvolution combines ICAP cognitive taxonomy, IRT memory retrieval, and evolutionary algorithms into a generative agent that simulates dynamic student cognitive evolution and outperforms baselines in fidelity and lea...
-
Red Skills or Blue Skills? A Dive Into Skills Published on ClawHub
Analysis of ClawHub shows language-based functional divides in agent skills, with over 30% flagged suspicious and submission-time documentation enabling 73% accurate risk prediction.
-
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
The paper surveys agent skills for LLMs across architecture, acquisition, deployment, and security, proposing a four-tier Skill Trust and Lifecycle Governance Framework to address vulnerabilities in community skills.
-
Sentra-Guard: A Real-Time Multilingual Defense Against Adversarial LLM Prompts
Sentra-Guard reports 99.96% detection of adversarial LLM prompts with AUC 1.00 and ASR of 0.004% using a hybrid SBERT-FAISS and transformer classifier architecture with multilingual translation and human feedback.
-
What Factors Affect LLMs and RLLMs in Financial Question Answering?
Prompting and agent methods boost standard LLMs on financial QA by simulating long chain-of-thought reasoning, but reasoning LLMs already have this capability and show limited further gains, while multilingual alignme...
-
Rethinking Agentic Reinforcement Learning In Large Language Models
The paper reviews conceptual foundations, methodological innovations, effective designs, critical challenges, and future directions for LLM-based Agentic Reinforcement Learning.
-
When control meets large language models: From words to dynamics
The paper proposes a bidirectional continuum between LLMs and control systems, covering LLM-assisted controller design, control-based LLM steering, and state-space modeling of LLMs.
-
Rethinking Agentic Reinforcement Learning In Large Language Models
The paper surveys the conceptual foundations, methodological innovations, challenges, and future directions of agentic reinforcement learning frameworks that embed cognitive capabilities like meta-reasoning and self-r...
-
Rethinking Agentic Reinforcement Learning In Large Language Models
This review synthesizes conceptual foundations, methods, challenges, and future directions for agentic reinforcement learning in large language models.
Reference graph
Works this paper leans on
-
[1]
The rise and potential of large language model based agents: A survey,
Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou et al. , “The rise and potential of large language model based agents: A survey,” Science China Information Sciences, vol. 68, no. 2, p. 121101, 2025
work page 2025
-
[2]
Intelligent agents: Theory and practice,
M. Wooldridge and N. R. Jennings, “Intelligent agents: Theory and practice,” The knowledge engineering review, vol. 10, no. 2, pp. 115–152, 1995
work page 1995
-
[3]
Large language models as reliable knowledge bases?
D. Zheng, M. Lapata, and J. Z. Pan, “Large language models as reliable knowledge bases?” arXiv preprint arXiv:2407.13578, 2024
-
[4]
Non-vacuous generalization bounds for large language models,
S. Lotfi, M. Finzi, Y. Kuang, T. G. Rudner, M. Goldblum, and A. G. Wilson, “Non-vacuous generalization bounds for large language models,” arXiv preprint arXiv:2312.17173, 2023
-
[5]
From multimodal llm to human-level ai: Modality, instruction, reasoning, efficiency and beyond,
H. Fei, Y. Yao, Z. Zhang, F. Liu, A. Zhang, and T.-S. Chua, “From multimodal llm to human-level ai: Modality, instruction, reasoning, efficiency and beyond,” in COLING, 2024, pp. 1–8
work page 2024
-
[6]
Towards Reasoning in Large Language Models: A Survey
J. Huang and K. C.-C. Chang, “Towards reasoning in large language models: A survey,” arXiv preprint arXiv:2212.10403, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Tool-lmm: A large multi-modal model for tool agent learning,
C. Wang, W. Luo, Q. Chen, H. Mai, J. Guo, S. Dong, Z. Li, L. Ma, S. Gao et al., “Tool-lmm: A large multi-modal model for tool agent learning,” arXiv e-prints, pp. arXiv–2401, 2024
work page 2024
-
[8]
A Survey on the Memory Mechanism of Large Language Model based Agents
Z. Zhang, X. Bo, C. Ma, R. Li, X. Chen, Q. Dai, J. Zhu, Z. Dong, and J.-R. Wen, “A survey on the memory mechanism of large language model based agents,” arXiv preprint arXiv:2404.13501 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
An in-depth survey of large language model-based artificial intelligence agents,
P . Zhao, Z. Jin, and N. Cheng, “An in-depth survey of large language model-based artificial intelligence agents,” arXiv preprint arXiv:2309.14365, 2023
-
[10]
Cognitive architectures for language agents,
T. Sumers, S. Yao, K. Narasimhan, and T. Griffiths, “Cognitive architectures for language agents,” TMLR, 2023
work page 2023
-
[11]
A survey on large language model-based game agents
S. Hu, T. Huang, F. Ilhan, S. Tekin, G. Liu, R. Kompella, and L. Liu, “A survey on large language model-based game agents,” arXiv preprint arXiv:2404.02039, 2024
-
[12]
A survey on game playing agents and large models: Methods, applications, and challenges,
X. Xu, Y. Wang, C. Xu, Z. Ding, J. Jiang, Z. Ding, and B. F. Karlsson, “A survey on game playing agents and large models: Methods, applications, and challenges,” arXiv preprint arXiv:2403.10249 , 2024
-
[13]
Unleashing the power of edge-cloud generative ai in mobile networks: A survey of aigc services,
M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, S. Mao, Z. Han, A. Jamalipour, D. I. Kim, X. Shen et al., “Unleashing the power of edge-cloud generative ai in mobile networks: A survey of aigc services,” IEEE Communications Surveys & Tutorials, vol. 26, no. 2, pp. 1127–1170, 2024
work page 2024
-
[14]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,” IEEE Communications Surveys & Tutorials, 2025
work page 2025
-
[15]
Agent AI: Surveying the Horizons of Multimodal Interaction
Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkar, R. Taori, Y. Noda, D. Terzopoulos, Y. Choi et al. , “Agent ai: Surveying the horizons of multimodal interaction,” arXiv preprint arXiv:2401.03568, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Y. Wang, Y. Pan, Q. Zhao, Y. Deng, Z. Su, L. Du, and T. H. Luan, “Large model agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,” arXiv preprint arXiv:2409.14457, 2024
-
[17]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin et al., “A survey on large language model based autonomous agents,” Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
work page 2024
-
[18]
A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y. Wu, and Y. Yang, “A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, vol. 1, no. 1, p. 9, 2024
work page 2024
-
[19]
X. Li, “A review of prominent paradigms for llm-based agents: Tool use (including rag), planning, and feedback learning,” arXiv preprint arXiv:2406.05804, 2024
-
[20]
W. Jin, H. Du, B. Zhao, X. Tian, B. Shi, and G. Yang, “A com- prehensive survey on multi-agent cooperative decision-making: Scenarios, approaches, challenges and perspectives,”arXiv preprint arXiv:2503.13415, 2025
-
[21]
A Survey on Vision-Language-Action Models for Embodied AI
Y. Ma, Z. Song, Y. Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,” arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi- agents: A survey of progress and challenges,” arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
T. Masterman, S. Besen, M. Sawtell, and A. Chao, “The landscape of emerging ai agent architectures for reasoning, planning, and tool calling: A survey,” arXiv preprint arXiv:2404.11584, 2024. 20
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Exploring large language model based intelligent agents: Definitions, methods, and prospects
Y. Cheng, C. Zhang, Z. Zhang, X. Meng, S. Hong, W. Li, Z. Wang, Z. Wang, F. Yin, J. Zhao et al., “Exploring large language model based intelligent agents: Definitions, methods, and prospects,” arXiv preprint arXiv:2401.03428, 2024
-
[25]
Camel: Communicative agents for
G. Li, H. A. A. K. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for ”mind” explo- ration of large language model society,” in NeurIPS, 2023
work page 2023
-
[26]
Autogen: Enabling next-gen llm applications via multi- agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “Autogen: Enabling next-gen llm applications via multi- agent conversation,” 2023
work page 2023
-
[27]
Metagpt: Meta programming for a multi-agent collaborative framework,
S. Hong, X. Zheng, J. Chen, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou et al., “Metagpt: Meta programming for a multi-agent collaborative framework,” in ICLR, 2024
work page 2024
-
[28]
Chatdev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y. Dang, J. Li, C. Yang, W. Chen, Y. Su, X. Conget al., “Chatdev: Communicative agents for software development,” in ACL, 2024, pp. 15 174–15 186
work page 2024
-
[29]
AFlow: Automating agentic workflow generation,
J. Zhang, J. Xiang, Z. Yu, F. Teng, X.-H. Chen, J. Chen, M. Zhuge, X. Cheng, S. Hong, J. Wang, B. Liu, Y. Luo, and C. Wu, “AFlow: Automating agentic workflow generation,” in ICLR, 2025
work page 2025
-
[30]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P . Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in UIST, 2023, pp. 1–22
work page 2023
-
[31]
User behavior simulation with large language model-based agents,
L. Wang, J. Zhang, H. Yang, Z.-Y. Chen, J. Tang, Z. Zhang, X. Chen, Y. Lin, H. Sun, R. Song et al., “User behavior simulation with large language model-based agents,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–37, 2025
work page 2025
-
[32]
Dspy: Compiling declarative language model calls into self-improving pipelines,
O. Khattab, A. Singhvi, P . Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts, “Dspy: Compiling declarative language model calls into self-improving pipelines,” in ICLR, 2024
work page 2024
-
[33]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” in ICLR, 2023
work page 2023
-
[34]
Graph of thoughts: Solving elaborate problems with large language models,
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P . Nyczyk et al., “Graph of thoughts: Solving elaborate problems with large language models,” in AAAI, vol. 38, no. 16, 2024, pp. 17 682–17 690
work page 2024
-
[35]
Voyager: An open-ended embodied agent with large language models,
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar, “Voyager: An open-ended embodied agent with large language models,” TMLR, 2023
work page 2023
-
[36]
X. Zhu, Y. Chen, H. Tian, C. Tao, W. Su, C. Yang, G. Huang, B. Li, L. Lu, X. Wang et al., “Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory,” arXiv preprint arXiv:2305.17144, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Expel: Llm agents are experiential learners,
A. Zhao, D. Huang, Q. Xu, M. Lin, Y.-J. Liu, and G. Huang, “Expel: Llm agents are experiential learners,” in AAAI, 2024, pp. 19 632– 19 642
work page 2024
-
[38]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” NeurIPS, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[39]
Tptu: Task planning and tool usage of large language model-based ai agents,
J. Ruan, Y. Chen, B. Zhang, Z. Xu, T. Bao, H. Mao, Z. Li, X. Zeng, R. Zhao et al. , “Tptu: Task planning and tool usage of large language model-based ai agents,” in NeurIPS, 2023
work page 2023
-
[40]
Openagents: An open platform for language agents in the wild,
T. Xie, F. Zhou, Z. Cheng, P . Shi, L. Weng, Y. Liu, T. J. Hua, J. Zhao, Q. Liu, C. Liu et al., “Openagents: An open platform for language agents in the wild,” arXiv preprint arXiv:2310.10634, 2023
-
[41]
Lego-prover: Neural theorem proving with growing libraries,
H. Wang, H. Xin, C. Zheng, Z. Liu, Q. Cao, Y. Huang, J. Xiong, H. Shi, E. Xie, J. Yin et al., “Lego-prover: Neural theorem proving with growing libraries,” in ICLR, 2024
work page 2024
-
[42]
Memgpt: Towards llms as operating systems,
C. Packer, V . Fang, S. G. Patil, K. Lin, S. Wooders, and J. E. Gonzalez, “Memgpt: Towards llms as operating systems,” CoRR, 2023
work page 2023
-
[43]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P . Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschel et al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,” NeurIPS, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[44]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph rag approach to query-focused summarization,” arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Chain of agents: Large language models collaborating on long-context tasks,
Y. Zhang, R. Sun, Y. Chen, T. Pfister, R. Zhang, and S. Arik, “Chain of agents: Large language models collaborating on long-context tasks,” Advances in Neural Information Processing Systems, vol. 37, pp. 132 208–132 237, 2024
work page 2024
-
[46]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Inter- leaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions,” arXiv preprint arXiv:2212.10509, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Llatrieval: Llm- verified retrieval for verifiable generation,
X. Li, C. Zhu, L. Li, Z. Yin, T. Sun, and X. Qiu, “Llatrieval: Llm- verified retrieval for verifiable generation,” in NAACL, 2024, pp. 5453–5471
work page 2024
-
[48]
Graph-augmented reasoning: Evolving step-by-step knowledge graph retrieval for llm reasoning,
W. Wu, Y. Jing, Y. Wang, W. Hu, and D. Tao, “Graph-augmented reasoning: Evolving step-by-step knowledge graph retrieval for llm reasoning,” 2025
work page 2025
-
[49]
Deeprag: Thinking to retrieval step by step for large language models,
X. Guan, J. Zeng, F. Meng, C. Xin, Y. Lu, H. Lin, X. Han, L. Sun, and J. Zhou, “Deeprag: Thinking to retrieval step by step for large language models,” arXiv preprint arXiv:2502.01142, 2025
-
[50]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
L. Wang, W. Xu, Y. Lan, Z. Hu, Y. Lan, R. K.-W. Lee, and E.- P . Lim, “Plan-and-solve prompting: Improving zero-shot chain- of-thought reasoning by large language models,” arXiv preprint arXiv:2305.04091, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Distributed problem solving and planning,
E. H. Durfee, “Distributed problem solving and planning,” in ECCAI Advanced Course on Artificial Intelligence. Springer, 2001, pp. 118–149
work page 2001
-
[52]
Chain-of-discussion: A multi- model framework for complex evidence-based question answer- ing,
M. Tao, D. Zhao, and Y. Feng, “Chain-of-discussion: A multi- model framework for complex evidence-based question answer- ing,” arXiv preprint arXiv:2402.16313, 2024
-
[53]
Tree-planner: Efficient close- loop task planning with large language models,
M. Hu, Y. Mu, X. Yu, M. Ding, S. Wu, W. Shao, Q. Chen, B. Wang, Y. Qiao, and P . Luo, “Tree-planner: Efficient close- loop task planning with large language models,” arXiv preprint arXiv:2310.08582, 2023
-
[54]
Reactree: Hierarchical task planning with dynamic tree expansion using llm agent nodes,
J.-W. Choi, H. Kim, H. Ong, Y. Yoon, M. Jang, J. Kim et al. , “Reactree: Hierarchical task planning with dynamic tree expansion using llm agent nodes,” 2025
work page 2025
-
[55]
In The Twelfth Inter- national Conference on Learning Representations
J. Long, “Large language model guided tree-of-thought,” arXiv preprint arXiv:2305.08291, 2023
-
[56]
Rest- mcts*: Llm self-training via process reward guided tree search,
D. Zhang, S. Zhoubian, Z. Hu, Y. Yue, Y. Dong, and J. Tang, “Rest- mcts*: Llm self-training via process reward guided tree search,” NeurIPS, vol. 37, pp. 64 735–64 772, 2024
work page 2024
-
[57]
A. Lykov, M. Dronova, N. Naglov, M. Litvinov, S. Satsevich, A. Bazhenov, V . Berman, A. Shcherbak, and D. Tsetserukou, “Llm- mars: Large language model for behavior tree generation and nlp- enhanced dialogue in multi-agent robot systems,” arXiv preprint arXiv:2312.09348, 2023
-
[58]
Llm as bt- planner: Leveraging llms for behavior tree generation in robot task planning,
J. Ao, F. Wu, Y. Wu, A. Swikir, and S. Haddadin, “Llm as bt- planner: Leveraging llms for behavior tree generation in robot task planning,” arXiv preprint arXiv:2409.10444, 2024
-
[59]
C. Rivera, G. Byrd, W. Paul, T. Feldman, M. Booker, E. Holmes, D. Handelman, B. Kemp, A. Badger, A. Schmidt et al., “Concepta- gent: Llm-driven precondition grounding and tree search for ro- bust task planning and execution,” arXiv preprint arXiv:2410.06108, 2024
-
[60]
Grounding llms for robot task planning using closed-loop state feedback,
V . Bhat, A. U. Kaypak, P . Krishnamurthy, R. Karri, and F. Khorrami, “Grounding llms for robot task planning using closed-loop state feedback,” arXiv preprint arXiv:2402.08546, 2024
-
[61]
Traineragent: Customizable and efficient model training through llm-powered multi-agent system,
H. Li, H. Jiang, T. Zhang, Z. Yu, A. Yin, H. Cheng, S. Fu, Y. Zhang, and W. He, “Traineragent: Customizable and efficient model training through llm-powered multi-agent system,” arXiv preprint arXiv:2311.06622, 2023
-
[62]
Dynamic self-consistency: Leveraging reasoning paths for efficient llm sampling,
G. Wan, Y. Wu, J. Chen, and S. Li, “Dynamic self-consistency: Leveraging reasoning paths for efficient llm sampling,” arXiv preprint arXiv:2408.17017, 2024
-
[63]
Llm-based cooperative agents using information relevance and plan validation,
S. Seo, J. Lee, S. Noh, and H. Kang, “Llm-based cooperative agents using information relevance and plan validation,” arXiv preprint arXiv:2405.16751, 2024
-
[64]
Adaplan- ner: Adaptive planning from feedback with language models,
H. Sun, Y. Zhuang, L. Kong, B. Dai, and C. Zhang, “Adaplan- ner: Adaptive planning from feedback with language models,” NeurIPS, vol. 36, pp. 58 202–58 245, 2023
work page 2023
-
[65]
Adaptive iterative feedback prompting for obstacle-aware path planning via llms,
M. Jafaripour, S. Golestan, S. Miwa, Y. Mitsuka, and O. Zaiane, “Adaptive iterative feedback prompting for obstacle-aware path planning via llms,” in AAAI Workshop, 2025
work page 2025
-
[66]
Making language models better tool learners with execution feedback,
S. Qiao, H. Gui, C. Lv, Q. Jia, H. Chen, and N. Zhang, “Making language models better tool learners with execution feedback,” arXiv preprint arXiv:2305.13068, 2023
-
[67]
Gpt4tools: Teaching large language model to use tools via self- instruction,
R. Yang, L. Song, Y. Li, S. Zhao, Y. Ge, X. Li, and Y. Shan, “Gpt4tools: Teaching large language model to use tools via self- instruction,” NeurIPS, vol. 36, pp. 71 995–72 007, 2023
work page 2023
-
[68]
Easytool: Enhancing llm-based agents with concise tool instruction,
S. Yuan, K. Song, J. Chen, X. Tan, Y. Shen, R. Kan, D. Li, and D. Yang, “Easytool: Enhancing llm-based agents with concise tool instruction,” arXiv preprint arXiv:2401.06201, 2024. 21
-
[69]
Avatar: Optimizing llm agents for tool usage via contrastive reasoning,
S. Wu, S. Zhao, Q. Huang, K. Huang, M. Yasunaga, K. Cao, V . Ioannidis, K. Subbian, J. Leskovec, and J. Y. Zou, “Avatar: Optimizing llm agents for tool usage via contrastive reasoning,” NeurIPS, vol. 37, pp. 25 981–26 010, 2025
work page 2025
-
[70]
Drivlme: Enhancing llm-based autonomous driving agents with embodied and social experiences,
Y. Huang, J. Sansom, Z. Ma, F. Gervits, and J. Chai, “Drivlme: Enhancing llm-based autonomous driving agents with embodied and social experiences,” in IROS. IEEE, 2024, pp. 3153–3160
work page 2024
-
[71]
Towards efficient llm grounding for embodied multi-agent collab- oration,
Y. Zhang, S. Yang, C. Bai, F. Wu, X. Li, Z. Wang, and X. Li, “Towards efficient llm grounding for embodied multi-agent collab- oration,” arXiv preprint arXiv:2405.14314, 2024
-
[72]
Improving embodied llm agents capabilities through collaboration,
B. Colle, “Improving embodied llm agents capabilities through collaboration,” 2024
work page 2024
-
[73]
Autonomous chemical research with large language models,
D. A. Boiko, R. MacKnight, B. Kline, and G. Gomes, “Autonomous chemical research with large language models,” Nature, vol. 624, no. 7992, pp. 570–578, 2023
work page 2023
-
[74]
Llmlingua: Compressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y. Lin, Y. Yang, and L. Qiu, “Llmlingua: Compressing prompts for accelerated inference of large language models,” in EMNLP, 2023, pp. 13 358–13 376
work page 2023
-
[75]
Autoact: Automatic agent learning from scratch for qa via self-planning,
S. Qiao, N. Zhang, R. Fang, Y. Luo, W. Zhou, Y. E. Jiang, C. Lv, and H. Chen, “Autoact: Automatic agent learning from scratch for qa via self-planning,” arXiv preprint arXiv:2401.05268, 2024
-
[76]
Meta-prompting: Enhancing lan- guage models with task-agnostic scaffolding,
M. Suzgun and A. T. Kalai, “Meta-prompting: Enhancing lan- guage models with task-agnostic scaffolding,” arXiv preprint arXiv:2401.12954, 2024
-
[77]
R., Rocktäschel, T., and Perez, E
A. Khan, J. Hughes, D. Valentine, L. Ruis, K. Sachan, A. Rad- hakrishnan, E. Grefenstette, S. R. Bowman, T. Rockt ¨aschel, and E. Perez, “Debating with more persuasive llms leads to more truthful answers,” arXiv preprint arXiv:2402.06782, 2024
-
[78]
Medagents: Large language models as collaborators for zero-shot medical reasoning,
X. Tang, A. Zou, Z. Zhang, Z. Li, Y. Zhao, X. Zhang, A. Cohan, and M. Gerstein, “Medagents: Large language models as collaborators for zero-shot medical reasoning,” arXiv preprint arXiv:2311.10537, 2023
-
[79]
Reconcile: Round-table conference improves reasoning via consensus among diverse llms,
J. C.-Y. Chen, S. Saha, and M. Bansal, “Reconcile: Round-table conference improves reasoning via consensus among diverse llms,” arXiv preprint arXiv:2309.13007, 2023
-
[80]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
T. Liang, Z. He, W. Jiao, X. Wang, Y. Wang, R. Wang, Y. Yang, S. Shi, and Z. Tu, “Encouraging divergent thinking in large language models through multi-agent debate,” arXiv preprint arXiv:2305.19118, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.