On The Landscape of Spoken Language Models: A Comprehensive Survey
Pith reviewed 2026-05-22 20:42 UTC · model grok-4.3
The pith
Spoken language models are categorized by architecture, training, and evaluation to unify the field.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
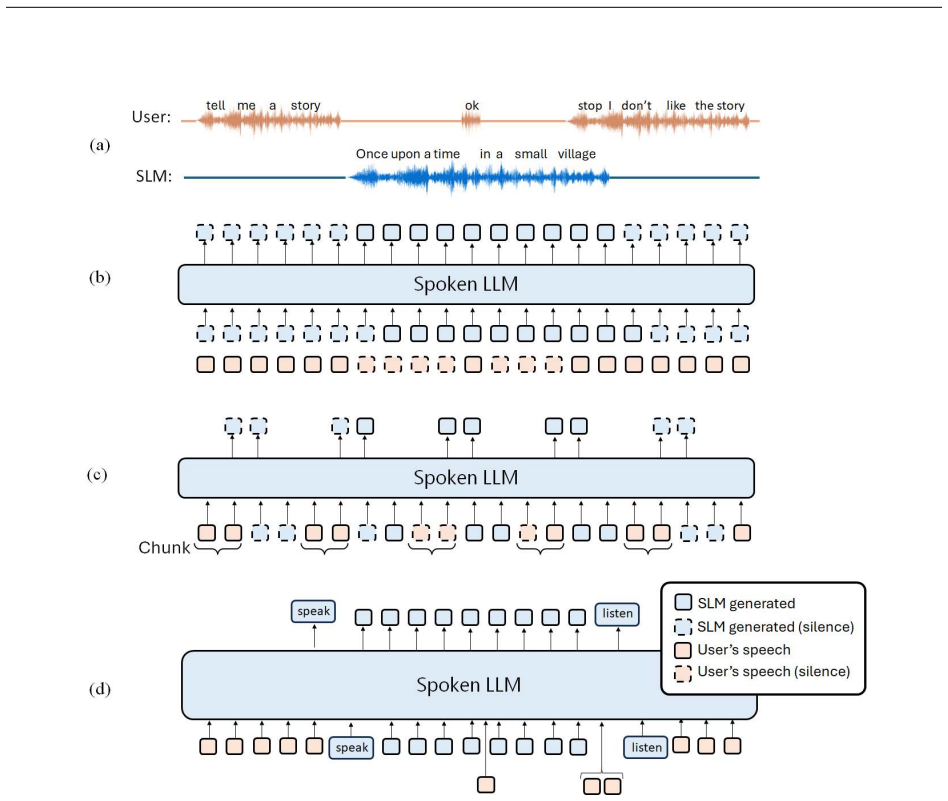
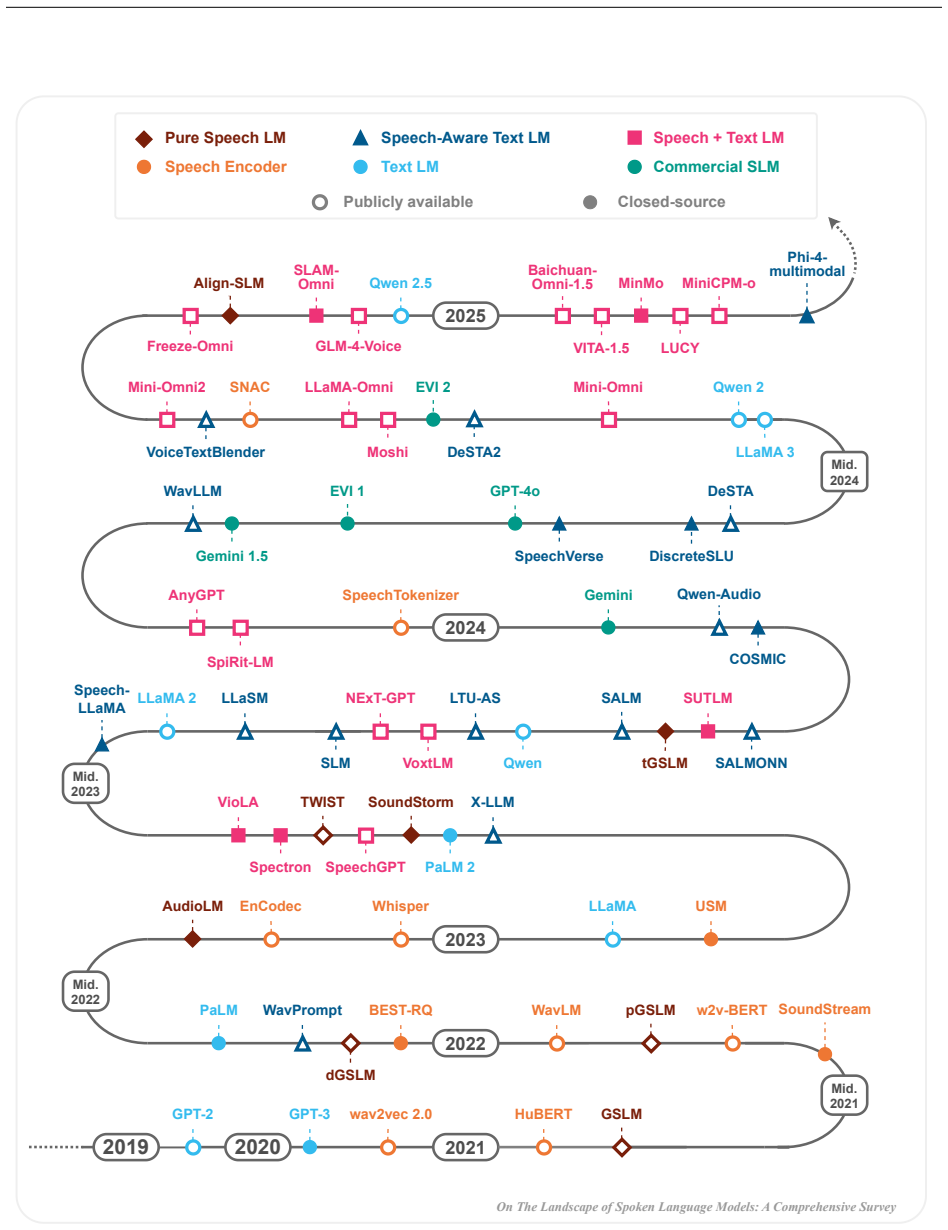
Work on spoken language models, which include both pure language models over speech token sequences and hybrid models that combine speech encoders with text language models, can be organized into a coherent landscape through categorization by model architecture, training, and evaluation choices, yielding an improved understanding of the field as it evolves toward universal speech processing systems.
What carries the argument
A three-way categorization of SLM literature according to model architecture, training choices, and evaluation choices.
If this is right
- A shared categorization makes it easier to compare models across different papers and settings.
- Key challenges in SLM development become more visible once the work is grouped this way.
- Future research directions can be identified by spotting patterns and missing combinations within the categories.
- The field gains a clearer path toward universal speech systems similar to those in text NLP.
Where Pith is reading between the lines
- The same categorization could be used to track how new models fit into or extend the existing landscape over time.
- Hybrid models might show faster progress on certain tasks because they reuse text LM scaling techniques.
- Evaluation choices could become a bottleneck if the categories reveal inconsistent metrics across papers.
Load-bearing premise
The body of existing SLM papers can be grouped into architecture, training, and evaluation categories without leaving major gaps or misrepresenting individual contributions.
What would settle it
Multiple recent SLM papers that cannot be placed into any of the architecture, training, or evaluation categories defined in the survey.
Figures




read the original abstract
The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys the emerging field of spoken language models (SLMs), which include both pure speech language models (modeling distributions over tokenized speech sequences) and hybrid models that combine speech encoders with text LMs (often supporting mixed spoken/written input/output). It frames this work as part of a broader shift from task-specific models to universal systems, analogous to the development of text LMs, and organizes the literature by choices in model architecture, training, and evaluation while noting key challenges and future directions.
Significance. A well-executed survey in this area would provide a valuable organizing framework for a rapidly diversifying literature with inconsistent terminology and evaluation practices. By unifying disparate strands of work under consistent axes, it could help researchers navigate the space, avoid redundant efforts, and focus on open problems in universal speech processing.
minor comments (2)
- [Abstract] Abstract: the claim that the survey 'categorizes the work in this area by model architecture, training, and evaluation choices' would be strengthened by a brief indication of the number of papers covered or the main sub-categories used within each axis.
- The manuscript would benefit from an explicit discussion of inclusion/exclusion criteria for the surveyed papers and any systematic search strategy employed, to allow readers to assess potential gaps.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of our survey and for recognizing its potential value in organizing the rapidly evolving literature on spoken language models. The recommendation for minor revision is noted, and we will prepare a revised manuscript accordingly.
Circularity Check
No significant circularity in this literature survey
full rationale
This paper is a descriptive survey that organizes existing SLM literature by architecture, training, and evaluation choices. It contains no equations, derivations, fitted parameters, predictions, or load-bearing claims that reduce to self-definitions or self-citations. The central contribution is a categorization of prior work, which draws from external sources and does not create any internal closed loop or force results by construction. As a review without original predictive or causal modeling, the derivation chain is empty and self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our survey categorizes the work in this area by model architecture, training, and evaluation choices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 9 Pith papers
-
TraceAV-Bench: Benchmarking Multi-Hop Trajectory Reasoning over Long Audio-Visual Videos
TraceAV-Bench is the first benchmark for multi-hop trajectory reasoning over long audio-visual videos, showing top models reach only 51-68% accuracy with substantial room for improvement.
-
A framework for analyzing concept representations in neural models
A new framework shows concept subspaces are not unique, estimator choice affects containment and disentanglement, LEACE works well but generalizes poorly, and HuBERT encodes phone info as contained and disentangled fr...
-
Game-Time: Evaluating Temporal Dynamics in Spoken Language Models
Game-Time Benchmark shows spoken language models handle basic tasks but degrade sharply under temporal constraints like tempo adherence and synchronized responses.
-
An Exploration of Mamba for Speech Self-Supervised Models
Mamba-based HuBERT models match or exceed Transformer versions on speech tasks while using far less compute for long sequences and streaming ASR.
-
Aligning Backchannel and Dialogue Context Representations via Contrastive LLM Fine-Tuning
A contrastive LLM fine-tuning method creates joint embeddings for dialogue contexts and backchannel realizations, improving retrieval performance and alignment with human judgments over raw WavLM features.
-
ASPIRin: Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models
ASPIRin decouples speaking timing from token content via binary action space projection and applies GRPO with rule-based rewards to optimize interactivity in SLMs without semantic collapse or repetition.
-
TASU2: Controllable CTC Simulation for Alignment and Low-Resource Adaptation of Speech LLMs
TASU2 adds controllability over uncertainty and error rate to text-derived CTC simulation, enabling better cross-modal alignment and low-resource adaptation for speech LLMs than prior text-only or TTS methods.
-
When Silence Matters: The Impact of Irrelevant Audio on Text Reasoning in Large Audio-Language Models
Irrelevant audio including silence reduces accuracy and increases volatility in text reasoning for large audio-language models, with effects worsening at longer durations, higher amplitudes, and higher temperatures.
-
A Survey of Audio Reasoning in Multimodal Foundation Models
A survey that provides a unified formulation of audio reasoning and reviews advances across Audio-to-Text, Audio-to-Speech, Audio-Visual, and Agentic paradigms while discussing challenges and future directions.
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. MusicLM: Generating music from text.arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, et al. Funaudiollm: Voice understanding and generation foundation models for natural interaction between humans and llms.arXiv preprint arXiv:2407.04051,
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
AudioLM: A language modeling approach to audio generation.IEEE/ACM Trans
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Do- minik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. AudioLM: A language modeling approach to audio generation.IEEE/ACM Trans. Audio, Speech, Lang. Process., 31: 2523–2533, 2023a. Zalán Borsos, Matt Sharifi, Damien Vincen...
-
[5]
Feilong Chen, Minglun Han, Haozhi Zhao, Qingyang Zhang, Jing Shi, Shuang Xu, and Bo Xu. X-LLM: Bootstrapping advanced large language models by treating multi-modalities as foreign languages.arXiv preprint arXiv:2305.04160,
-
[6]
Liang Chen, Zekun Wang, Shuhuai Ren, Lei Li, Haozhe Zhao, Yunshui Li, Zefan Cai, Hongcheng Guo, Lei Zhang, Yizhe Xiong, Yichi Zhang, Ruoyu Wu, Qingxiu Dong, Ge Zhang, Jian Yang, Lingwei Meng, Shujie Hu, Yulong Chen, Junyang Lin, Shuai Bai, Andreas Vlachos, Xu Tan, Minjia Zhang, Wen Xiao, Aaron Yee, Tianyu Liu, and Baobao Chang. Next token prediction towar...
-
[7]
Neural codec language models are zero-shot text to speech synthesizers.IEEE Trans
Sanyuan Chen, Chengyi Wang, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Neural codec language models are zero-shot text to speech synthesizers.IEEE Trans. Audio, Speech, Lang. Process., 33:705–718, 2025b. Wenxi Chen, Ziyang Ma, Ruiqi Yan, Yuzhe Liang, Xiquan Li, Ruiyang Xu,...
-
[8]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-Audio: Advancing universal audio understanding via unified large-scale audio-language models. arXiv preprint arXiv:2311.07919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-Audio technical report. arXiv preprint arXiv:2407.10759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Recent advances in speech language models: A survey.arXiv preprint arXiv:2410.03751,
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, and Irwin King. Recent advances in speech language models: A survey.arXiv preprint arXiv:2410.03751,
-
[11]
Nilaksh Das, Saket Dingliwal, Srikanth Ronanki, Rohit Paturi, David Huang, Prashant Mathur, Jie Yuan, Dhanush Bekal, Xing Niu, Sai Muralidhar Jayanthi, Xilai Li, Karel Mundnich, Monica Sunkara, Sun- dararajan Srinivasan, Kyu J. Han, and Katrin Kirchhoff. SpeechVerse: A large-scale generalizable audio language model. arXiv preprint arXiv:2405.08295,
-
[12]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: A speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
-
[14]
CodecFake-Omni: A large-scale codec-based deepfake speech dataset
Jiawei Du, Xuanjun Chen, Haibin Wu, Lin Zhang, I-Ming Lin, I-Hsiang Chiu, Wenze Ren, Yuan Tseng, Yu Tsao, Jyh-Shing Roger Jang, and Hung-yi Lee. CodecFake-Omni: A large-scale codec-based deepfake speech dataset. arXiv preprint arXiv:2501.08238,
work page internal anchor Pith review arXiv
-
[15]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. CosyVoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
The zero resource speech challenge 2021: Spoken language modelling
Ewan Dunbar, Mathieu Bernard, Nicolas Hamilakis, Tu Anh Nguyen, Maureen De Seyssel, Patricia Rozé, Morgane Rivière, Eugene Kharitonov, and Emmanuel Dupoux. The zero resource speech challenge 2021: Spoken language modelling. InProc. Interspeech,
work page 2021
-
[17]
Ruchao Fan, Bo Ren, Yuxuan Hu, Rui Zhao, Shujie Liu, and Jinyu Li. AlignFormer: Modality matching can achieve better zero-shot instruction-following speech-LLM.arXiv preprint arXiv:2412.01145,
-
[18]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Recent advances in discrete speech tokens: A review
Yiwei Guo, Zhihan Li, Hankun Wang, Bohan Li, Chongtian Shao, Hanglei Zhang, Chenpeng Du, Xie Chen, Shujie Liu, and Kai Yu. Recent advances in discrete speech tokens: A review. arXiv preprint arXiv:2502.06490,
-
[22]
Distilling an end-to-end voice as- sistant without instruction training data,
William Held, Ella Li, Michael J. Ryan, Weiyan Shi, Yanzhe Zhang, and Diyi Yang. Distilling an end-to-end voice assistant without instruction training data.arXiv preprint arXiv:2410.02678,
-
[23]
Ted-lium 3: Twice as much data and corpus repartition for experiments on speaker adaptation
François Hernandez, Vincent Nguyen, Sahar Ghannay, Natalia Tomashenko, and Yannick Esteve. Ted-lium 3: Twice as much data and corpus repartition for experiments on speaker adaptation. InSpeech and Computer: 20th International Conference, SPECOM 2018, Leipzig, Germany, September 18–22, 2018, Proceedings 20, pp. 198–208. Springer,
work page 2018
-
[24]
Chain-of-thought prompting for speech translation.arXiv preprint arXiv:2409.11538, 2024a
Ke Hu, Zhehuai Chen, Chao-Han Huck Yang, Piotr Żelasko, Oleksii Hrinchuk, Vitaly Lavrukhin, Ja- gadeesh Balam, and Boris Ginsburg. Chain-of-thought prompting for speech translation.arXiv preprint arXiv:2409.11538, 2024a. Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan ...
-
[25]
WavChat: A survey of spoken dialogue models.arXiv preprint arXiv:2411.13577,
Shengpeng Ji, Yifu Chen, Minghui Fang, Jialong Zuo, Jingyu Lu, Hanting Wang, Ziyue Jiang, Long Zhou, Shujie Liu, Xize Cheng, Xiaoda Yang, Zehan Wang, Qian Yang, Jian Li, Yidi Jiang, Jingzhen He, Yunfei Chu, Jin Xu, and Zhou Zhao. WavChat: A survey of spoken dialogue models.arXiv preprint arXiv:2411.13577,
-
[26]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
29 Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Chun-Yi Kuan and Hung-yi Lee. Can large audio-language models truly hear? Tackling hallucinations with multi-task assessment and stepwise audio reasoning.arXiv preprint arXiv:2410.16130,
-
[28]
Instruction-following speech recognition
Cheng-I Jeff Lai, Zhiyun Lu, Liangliang Cao, and Ruoming Pang. Instruction-following speech recognition. arXiv preprint arXiv:2309.09843,
- [29]
-
[30]
30 LCM team, Loïc Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R. Costa-jussà, David Dale, Hady Elsahar, Kevin Heffernan, João Maria Janeiro, Tuan Tran, Christophe Ropers, Eduardo Sánchez, Robin San Ro- man, Alexandre Mourachko, Safiyyah Saleem, and Holger Sch...
-
[31]
Guan-Ting Lin, Cheng-Han Chiang, and Hung-yi Lee. Advancing large language models to capture varied speaking styles and respond properly in spoken conversations. InProc. ACL, 2024a. Guan-Ting Lin, Prashanth Gurunath Shivakumar, Aditya Gourav, Yile Gu, Ankur Gandhe, Hung-yi Lee, and Ivan Bulyko. Align-SLM: Textless spoken language models with reinforcement...
-
[32]
DeSTA: Enhancing speech language models through descriptive speech-text alignment
Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, He Huang, Boris Ginsburg, Yu-Chiang Frank Wang, and Hung-yi Lee. DeSTA: Enhancing speech language models through descriptive speech-text alignment. In Proc. Interspeech, 2024a. Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, Chao-Han Huck Yang, Jagadeesh Balam, Boris Ginsburg, Yu- Chiang Frank Wang, and Hung-yi Lee. Developing in...
-
[33]
A suite for acoustic language model evaluation.arXiv preprint arXiv:2409.07437,
31 Gallil Maimon, Amit Roth, and Yossi Adi. A suite for acoustic language model evaluation.arXiv preprint arXiv:2409.07437,
-
[34]
Slamming: Training a speech language model on one gpu in a day.arXiv preprint arXiv:2502.15814,
Gallil Maimon, Avishai Elmakies, and Yossi Adi. Slamming: Training a speech language model on one gpu in a day.arXiv preprint arXiv:2502.15814,
-
[35]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture- of-loras. arXiv preprint arXiv:2503.01743,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
DASB - Discrete Audio and Speech Benchmark
Pooneh Mousavi, Luca Della Libera, Jarod Duret, Artem Ploujnikov, Cem Subakan, and Mirco Ravanelli. DASB–discrete audio and speech benchmark.arXiv preprint arXiv:2406.14294, 2024a. Pooneh Mousavi, Jarod Duret, Salah Zaiem, Luca Della Libera, Artem Ploujnikov, Cem Subakan, and Mirco Ravanelli. How should we extract discrete audio tokens from self-supervise...
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
URLhttps://openai.com/index/gpt-4o-system-card/. OpenAI et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Long-form speech generation with spoken language models.arXiv preprint arXiv:2412.18603,
Se Jin Park, Julian Salazar, Aren Jansen, Keisuke Kinoshita, Yong Man Ro, and RJ Skerry-Ryan. Long-form speech generation with spoken language models.arXiv preprint arXiv:2412.18603,
-
[39]
A survey on speech large language models
Jing Peng, Yucheng Wang, Yu Xi, Xu Li, Xizhuo Zhang, and Kai Yu. A survey on speech large language models. arXiv preprint arXiv:2410.18908, 2024a. Yifan Peng, Yui Sudo, Shakeel Muhammad, and Shinji Watanabe. DPHuBERT: Joint distillation and pruning of self-supervised speech models. InProc. Interspeech, 2023a. Yifan Peng, Jinchuan Tian, Brian Yan, Dan Berr...
-
[40]
LLaSM: Large language and speech model.arXiv preprint arXiv:2308.15930,
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, and Yemin Shi. LLaSM: Large language and speech model.arXiv preprint arXiv:2308.15930,
-
[41]
Snac: Multi-scale neural audio codec.arXiv preprint arXiv:2410.14411,
Hubert Siuzdak, Florian Grötschla, and Luca A Lanzendörfer. Snac: Multi-scale neural audio codec.arXiv preprint arXiv:2410.14411,
-
[42]
Espnet-speechlm: An open speech language model toolkit
Jinchuan Tian, Jiatong Shi, William Chen, Siddhant Arora, Yoshiki Masuyama, Takashi Maekaku, Yihan Wu, Junyi Peng, Shikhar Bharadwaj, Yiwen Zhao, et al. Espnet-speechlm: An open speech language model toolkit. arXiv preprint arXiv:2502.15218,
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron et al. LLaMA 2: Ope...
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
LAST: Language model aware speech tokenization
Arnon Turetzky and Yossi Adi. LAST: Language model aware speech tokenization. arXiv preprint arXiv:2409.03701,
-
[45]
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy F. Chen. AudioBench: A universal benchmark for audio large language models.arXiv preprint arXiv:2406.16020, 2024a. Chen Wang, Minpeng Liao, Zhongqiang Huang, Jinliang Lu, Junhong Wu, Yuchen Liu, Chengqing Zong, and Jiajun Zhang. BLSP: Bootstrapping langu...
-
[46]
Felix Wu, Kwangyoun Kim, Shinji Watanabe, Kyu J
URL https://github.com/collabora/WhisperSpeech. Felix Wu, Kwangyoun Kim, Shinji Watanabe, Kyu J. Han, Ryan McDonald, Kilian Q. Weinberger, and Yoav Artzi. Wav2Seq: Pre-training speech-to-text encoder-decoder models using pseudo languages. InProc. ICASSP, 2023a. Haibin Wu, Xuanjun Chen, Yi-Cheng Lin, Kai-wei Chang, Ho-Lam Chung, Alexander H. Liu, and Hung-...
-
[47]
Enabling real-time conversations with minimal training costs.arXiv preprint arXiv:2409.11727,
Wang Xu, Shuo Wang, Weilin Zhao, Xu Han, Yukun Yan, Yudi Zhang, Zhe Tao, Zhiyuan Liu, and Wanxiang Che. Enabling real-time conversations with minimal training costs.arXiv preprint arXiv:2409.11727,
-
[48]
Continuous speech tokens makes llms robust multi- modality learners
Ze Yuan, Yanqing Liu, Shujie Liu, and Sheng Zhao. Continuous speech tokens makes llms robust multi- modality learners. arXiv preprint arXiv:2412.04917,
-
[49]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. GLM-4-Voice: Towards intelligent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612, 2024a. Aohan Zeng, Zhengxiao Du, Mingdao Liu, Lei Zhang, Shengmin Jiang, Yuxiao Dong, and Jie Tang. Scaling speech-text pre-training with synthet...
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. In Findings of EMNLP, 2023a. Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. MM-LLMs: Recent advances in multimodal large language models....
-
[51]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
S., Haghani, P., Riesa, J., Perng, G., Soltau, H., Strohman, T., Ramabhadran, B., Sainath, T
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. SpeechTokenizer: Unified speech tokenizer for speech language models. InProc. ICLR, 2024b. Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, and Zhiyuan Liu. Beyond the turn-based game: Enabling real-time conversations with duplex models. In Pro...
-
[53]
A Appendix 37 Table 3: Spoken language models. P.: Phonetic token. A.: Acoustic token. C.: Continuous feature. For components not explicitly cited in the table, please see the following references: SSE Algayres et al. (2022), USM (Zhang et al., 2023b), SNAC (Siuzdak et al., 2024), SenseVoice (An et al., 2024), and Canary (Puvvada et al.,
work page 2022
-
[54]
for speech representation models, and Tacotron 2 (Shen et al., 2018), WaveFit (Koizumi et al., 2023), and CosyVoice (Du et al.,
work page 2018
-
[55]
Text + Conformer En- coder(C.)→Text X MLP 38 GSLM 20212019 GPT-2 GPT-3 wav2vec 2.0 HuBERT SoundStreamw2v-BERTpGSLMWavLM dGSLM WavPromptPaLM AudioLM WhisperEnCodec LLaMA 2023 TWIST SoundStormVioLA SpeechGPTSpectron X-LLM PaLM 2 Speech- LLaMALLaMA 2 LLaSM NExT-GPT LTU-AS Qwen tGSLM SUTLM SALMONN COSMIC GeminiSpeechTokenizer SpiRit-LM 2024 On The Landscape o...
work page 2023
-
[56]
Model Training Strategy Training Tasks Evaluation Tasks Training Data Findings SLM Wang et al
39 Table 4: A representative set of training and evaluation strategies for speech-aware text language models, along with key tasks, details on the training data, and key insights for further context. Model Training Strategy Training Tasks Evaluation Tasks Training Data Findings SLM Wang et al. (2023b) IT ASR, ST, Alpaca tasks ASR, ST, contextual biasing, ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.