Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Pith reviewed 2026-05-19 06:32 UTC · model grok-4.3
The pith
Robots achieve manipulation performance matching real demonstrations by imitating filtered AI-generated videos
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating demonstration videos with an off-the-shelf diffusion model, automatically filtering them with a vision-language model, extracting 6D object trajectories, and retargeting those trajectories to the robot, the method produces real-world manipulation performance that equals the performance obtained from genuine human demonstrations, with effectiveness increasing as video generation quality improves.
What carries the argument
The RIGVid pipeline that turns a language command and scene image into filtered generated videos, extracts object trajectories via 6D pose tracking, and retargets the trajectories to the robot in an embodiment-agnostic manner.
If this is right
- Filtered generated videos achieve performance equivalent to real demonstrations across real-world evaluations of pouring, wiping, and mixing.
- Robot success rates increase as the quality of the generated videos improves.
- Generated videos outperform more compact alternatives such as keypoint prediction using vision-language models.
- Strong 6D pose tracking yields better trajectory extraction than dense feature point tracking.
Where Pith is reading between the lines
- The approach could reduce the expense of collecting robot training data by substituting synthetic videos for physical recordings.
- Continued improvement in video generation models would likely expand the range of tasks that can be taught this way without any additional real-world data.
- Because retargeting does not depend on robot embodiment, the same generated videos might be reused across different robot hardware platforms.
Load-bearing premise
The 6D pose tracker extracts reliable object trajectories from the generated videos and these trajectories can be retargeted to the robot without embodiment-specific failures or safety issues.
What would settle it
A side-by-side real-robot experiment in which success rates with filtered generated videos fall substantially below those with real demonstrations, or in which 6D tracking errors produce visibly incorrect trajectories that cause task failure.
Figures



















read the original abstract
This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks--such as pouring, wiping, and mixing--purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RIGVid, a system for robotic manipulation that generates candidate demonstration videos using an off-the-shelf video diffusion model conditioned on a language command and initial scene image, filters them via a VLM to retain only those matching the command, extracts 6D object trajectories with a pose tracker, and retargets those trajectories to the robot in an embodiment-agnostic manner. Through real-world experiments on tasks such as pouring, wiping, and mixing, it claims that filtered generated videos achieve performance comparable to real physical demonstrations, that results improve with higher generation quality, and that the approach outperforms alternatives such as VLM keypoint prediction or dense feature tracking.
Significance. If the empirical claims hold under detailed scrutiny, the work would be significant for demonstrating that synthetic video generation can serve as a viable, scalable substitute for physical demonstration collection in imitation learning. This could lower the cost and hardware requirements for training complex manipulation policies and highlight the utility of combining generative models with classical tracking and retargeting pipelines.
major comments (2)
- [§4] §4 (Real-world Evaluations): The central claim that filtered generated videos are 'as effective as real demonstrations' is load-bearing for the contribution, yet the manuscript provides no quantitative success rates, trial counts, error bars, or statistical tests comparing the two conditions. Without these data, the equivalence result and the statement that 'performance improves with generation quality' cannot be assessed for robustness or effect size.
- [§3.2] §3.2 (6D Pose Tracking): The method assumes that a standard 6D pose tracker can extract accurate, low-jitter trajectories from diffusion-generated videos despite potential frame-to-frame geometric or lighting inconsistencies. No ablation or metric (e.g., mean pose error or tracking success rate) is reported comparing tracker output on generated versus real videos; if tracking noise is materially higher on generated footage, downstream retargeting would introduce errors absent from the real-demonstration baseline, undermining the equivalence result.
minor comments (2)
- [Abstract] Abstract: The phrase 'embodiment-agnostic fashion' for retargeting is used without a short description of the mapping procedure; adding one sentence would improve accessibility.
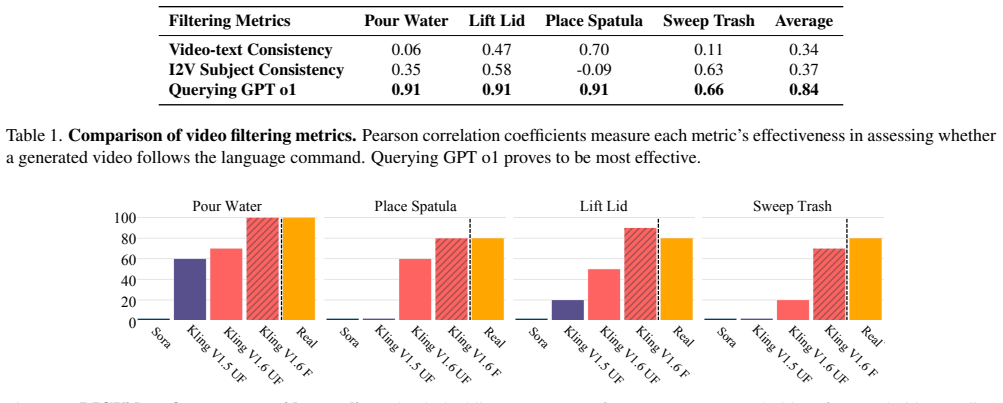
- [Figure 3] Figure 3 or equivalent experimental figure: Captions should explicitly state the number of trials per condition and whether success is defined by task completion within a time limit or by a distance threshold.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback, which identifies key areas where additional quantitative details can strengthen the presentation of our empirical results. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [§4] §4 (Real-world Evaluations): The central claim that filtered generated videos are 'as effective as real demonstrations' is load-bearing for the contribution, yet the manuscript provides no quantitative success rates, trial counts, error bars, or statistical tests comparing the two conditions. Without these data, the equivalence result and the statement that 'performance improves with generation quality' cannot be assessed for robustness or effect size.
Authors: We agree that explicit quantitative comparisons are essential for substantiating the central claim. While the manuscript describes real-world experiments on pouring, wiping, and mixing and states that filtered generated videos achieve comparable performance, we acknowledge that success rates, trial counts, error bars, and statistical tests are not presented in tabular or statistical form in the main text. In the revised version, we will add a new table in §4 reporting per-task success rates (as percentages) for both generated-video and real-demonstration conditions, along with the number of trials conducted (typically 10 per condition), standard deviations, and results of statistical tests (e.g., two-sample t-tests or Wilcoxon rank-sum tests) to evaluate equivalence. We will also include results from videos generated at different quality levels to support the claim that performance improves with generation quality. These additions will allow readers to assess effect sizes and robustness directly. revision: yes
-
Referee: [§3.2] §3.2 (6D Pose Tracking): The method assumes that a standard 6D pose tracker can extract accurate, low-jitter trajectories from diffusion-generated videos despite potential frame-to-frame geometric or lighting inconsistencies. No ablation or metric (e.g., mean pose error or tracking success rate) is reported comparing tracker output on generated versus real videos; if tracking noise is materially higher on generated footage, downstream retargeting would introduce errors absent from the real-demonstration baseline, undermining the equivalence result.
Authors: We appreciate the referee’s point that direct validation of the pose tracker on generated videos is necessary to rule out confounding tracking errors. The current manuscript relies on an off-the-shelf 6D pose tracker and reports strong end-to-end task performance, but does not provide separate tracking-quality metrics. In revision we will add an ablation subsection (or appendix) that reports mean pose error, frame-to-frame jitter, and tracking success rate on a held-out set of both generated and real videos for the evaluated tasks. If materially higher noise is observed on generated footage, we will discuss any smoothing or filtering steps applied during retargeting and quantify its effect on final policy performance. This will clarify whether the equivalence result holds independently of tracking differences. revision: yes
Circularity Check
No circularity: empirical pipeline with external validation
full rationale
The paper presents an empirical system (RIGVid) that uses off-the-shelf video diffusion models to generate candidate demonstrations from language and scene input, applies VLM filtering, extracts trajectories via 6D pose tracking, and retargets them for robot execution. Real-world evaluations directly compare success rates against real physical demonstrations and alternative trajectory extraction methods (e.g., keypoint prediction, dense feature tracking). No mathematical derivations, equations, or fitted parameters are described that reduce any claimed result to inputs defined by the same data. The central claim of equivalence to real demos rests on external, falsifiable robot trials rather than self-referential definitions or self-citation chains. Self-citations, if present for the diffusion or tracking modules, are not load-bearing for the equivalence result. This is a standard empirical robotics paper whose performance claims are independently testable outside the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Generated videos contain extractable 6D object trajectories that correspond to feasible real-world actions.
- domain assumption VLM-based filtering selects videos that are both command-compliant and robot-executable.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that filtered generated videos are as effective as real demonstrations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 8 Pith papers
-
PlayWorld: Learning Robot World Models from Autonomous Play
PlayWorld learns high-fidelity robot world models from unsupervised self-play, producing physically consistent video predictions that outperform models trained on human data and enabling 65% better real-world policy p...
-
Imagine2Real: Towards Zero-shot Humanoid-Object Interaction via Video Generative Priors
Imagine2Real enables zero-shot humanoid-object interaction by unifying motions as 4D point trajectories, tracking only base/hands/object keypoints inside a BFM latent space, and training with progressive simple reward...
-
AnchorD: Metric Grounding of Monocular Depth Using Factor Graphs
AnchorD anchors monocular depth priors in metric sensor data via patch-wise affine alignment using factor graph optimization, improving accuracy on non-Lambertian objects and introducing a new benchmark dataset with d...
-
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Video generation models can function as world simulators if efficiency gaps in spatiotemporal modeling are bridged via organized paradigms, architectures, and algorithms.
-
Imagine2Real: Towards Zero-shot Humanoid-Object Interaction via Video Generative Priors
Imagine2Real is a zero-shot humanoid-object interaction method that unifies robot and object motion as 4D point trajectories, tracks only sparse keypoints inside a behavior foundation model latent space, and trains wi...
-
From Video to Control: A Survey of Learning Manipulation Interfaces from Temporal Visual Data
A survey introduces an interface-centric taxonomy for video-to-control methods in robotic manipulation and identifies the robotics integration layer as the central open challenge.
-
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
This survey organizes large VLM-based VLA models for robotic manipulation into monolithic and hierarchical paradigms, reviews their integrations and datasets, and outlines future directions.
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
https://www.klingai.com/ , 2024
Kling ai. https://www.klingai.com/ , 2024. Ac- cessed: 2024-02-10. 1
work page 2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Composi- tional foundation models for hierarchical planning
Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenenbaum, Leslie Kael- bling, Akash Srivastava, and Pulkit Agrawal. Composi- tional foundation models for hierarchical planning. Ad- vances in Neural Information Processing Systems , 36: 22304–22325, 2023. 3
work page 2023
-
[4]
Nil: No-data imitation learning by leveraging pre-trained video diffusion models
Mert Albaba, Chenhao Li, Markos Diomataris, Omid Taheri, Andreas Krause, and Michael Black. Nil: No-data imitation learning by leveraging pre-trained video diffusion models. arXiv preprint arXiv:2503.10626, 2025. 3
-
[5]
Flowcontrol: Optical flow based visual servoing
Max Argus, Lukas Hermann, Jon Long, and Thomas Brox. Flowcontrol: Optical flow based visual servoing. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7534–7541. IEEE, 2020. 2
work page 2020
-
[6]
Zs6d: Zero-shot 6d object pose estimation using vision transform- ers
Philipp Ausserlechner, David Haberger, Stefan Thalham- mer, Jean-Baptiste Weibel, and Markus Vincze. Zs6d: Zero-shot 6d object pose estimation using vision transform- ers. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 463–469. IEEE, 2024. 3
work page 2024
-
[7]
Screwmimic: Bimanual imitation from human videos with screw space projection
Arpit Bahety, Priyanka Mandikal, Ben Abbatematteo, and Roberto Mart´ın-Mart´ın. Screwmimic: Bimanual imitation from human videos with screw space projection. arXiv preprint arXiv:2405.03666, 2024. 1
-
[8]
Human-to-robot imitation in the wild,
Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. Human-to-robot imitation in the wild. arXiv preprint arXiv:2207.09450, 2022. 1, 2
-
[9]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023. 1, 3
work page 2023
-
[10]
Video pretraining (vpt): Learning to act by watching unlabeled online videos
Bowen Baker, Ilge Akkaya, Peter Zhokov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampe- dro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos. Advances in Neural Information Processing Systems, 35:24639–24654, 2022. 3
work page 2022
-
[11]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Eval- uating physical commonsense for video generation. arXiv preprint arXiv:2406.03520, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[12]
Leonardo Barcellona, Andrii Zadaianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Compositional world models em- powering robot imitation learning with imagination. arXiv preprint arXiv:2412.14957, 2024. 3
-
[13]
Zero-shot robot manipulation from pas- sive human videos.arXiv preprint arXiv:2302.02011, 2023
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tulsiani, and Vikash Kumar. Zero-shot robot manipulation from pas- sive human videos.arXiv preprint arXiv:2302.02011, 2023. 1
-
[14]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios en- ables generalizable robot manipulation. arXiv preprint arXiv:2409.16283, 2024. 1, 2, 3, 8, 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables diverse zero-shot robot manip- ulation, 2024. 1, 2, 7, 18
work page 2024
-
[16]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators
-
[17]
Reconstruct locally, localize glob- ally: A model free method for object pose estimation
Ming Cai and Ian Reid. Reconstruct locally, localize glob- ally: A model free method for object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3153–3163, 2020. 3
work page 2020
-
[18]
A tutorial on task-parameterized move- ment learning and retrieval
Sylvain Calinon. A tutorial on task-parameterized move- ment learning and retrieval. Intelligent service robotics, 9: 1–29, 2016. 3
work page 2016
-
[19]
Freeze: Training-free zero-shot 6d pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, and Fabio Poiesi. Freeze: Training-free zero-shot 6d pose estimation with geometric and vision foundation models. European Conference on Computer Vision (ECCV), 2024. 3
work page 2024
-
[20]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the International Conference on Com- puter Vision (ICCV), 2021. 6, 21
work page 2021
-
[21]
Learning video-conditioned policies for unseen manipu- lation tasks
Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Learning video-conditioned policies for unseen manipu- lation tasks. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 909–916. IEEE,
work page 2023
-
[22]
Se- mantic visual navigation by watching youtube videos
Matthew Chang, Arjun Gupta, and Saurabh Gupta. Se- mantic visual navigation by watching youtube videos. In NeurIPS, 2020. 1, 3
work page 2020
-
[23]
Matthew Chang, Theophile Gervet, Mukul Khanna, Sriram Yenamandra, Dhruv Shah, So Yeon Min, Kavit Shah, Chris Paxton, Saurabh Gupta, Dhruv Batra, Roozbeh Mottaghi, Jitendra Malik, and Devendra Singh Chaplot. Goat: Go to any thing. arXiv preprint arXiv:2311.06430, 2023. 4
- [24]
-
[25]
Nonparametric motion retargeting for humanoid robots on shared latent space
Sungjoon Choi, Matthew KXJ Pan, and Joohyung Kim. Nonparametric motion retargeting for humanoid robots on shared latent space. In Robotics: science and systems ,
-
[26]
Transformers for one- shot visual imitation
Sudeep Dasari and Abhinav Gupta. Transformers for one- shot visual imitation. In Conference on Robot Learning , pages 2071–2084. PMLR, 2021. 1, 2
work page 2071
-
[27]
An unbiased look at datasets for visuo- motor pre-training
Sudeep Dasari, Mohan Kumar Srirama, Unnat Jain, and Abhinav Gupta. An unbiased look at datasets for visuo- motor pre-training. In Conference on Robot Learning , pages 1183–1198. PMLR, 2023. 3
work page 2023
-
[28]
Bootstap: Boot- strapped training for tracking-any-point
Carl Doersch, Yi Yang, Dilara Gokay, Pauline Luc, Skanda Koppula, Ankush Gupta, Joseph Heyward, Ross Goroshin, Jo˜ao Carreira, and Andrew Zisserman. Bootstap: Boot- strapped training for tracking-any-point. arXiv preprint arXiv:2402.00847, 2024. 18
-
[29]
arXiv preprint arXiv:2310.10625 (2023)
Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B Tenenbaum, et al. Video language plan- ning. arXiv preprint arXiv:2310.10625, 2023. 3
-
[30]
Learning universal policies via text-guided video genera- tion
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video genera- tion. Advances in Neural Information Processing Systems, 36, 2024. 1, 3
work page 2024
-
[31]
Anygrasp: Robust and efficient grasp percep- tion in spatial and temporal domains
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp percep- tion in spatial and temporal domains. IEEE Transactions on Robotics, 2023. 4
work page 2023
- [32]
-
[33]
Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
Peter R Florence, Lucas Manuelli, and Russ Tedrake. Dense object nets: Learning dense visual object descrip- tors by and for robotic manipulation. arXiv preprint arXiv:1806.08756, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Humanplus: Hu- manoid shadowing and imitation from humans.arXiv preprint arXiv:2406.10454, 2024
Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, and Chelsea Finn. Humanplus: Humanoid shadowing and im- itation from humans. arXiv preprint arXiv:2406.10454 ,
-
[35]
Chongkai Gao, Haozhuo Zhang, Zhixuan Xu, Zhehao Cai, and Lin Shao. Flip: Flow-centric generative planning for general-purpose manipulation tasks. arXiv preprint arXiv:2412.08261, 2024. 2
-
[36]
Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions. arXiv preprint arXiv:2503.18938, 2025. 1
-
[37]
Navigating to objects in the real world
Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world. Science Robotics, 2023. 4
work page 2023
-
[38]
Retargetting motion to new characters
Michael Gleicher. Retargetting motion to new characters. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques, pages 33–42, 1998. 3
work page 1998
-
[39]
Xuyang Guo, Jiayan Huo, Zhenmei Shi, Zhao Song, Jiahao Zhang, and Jiale Zhao. T2vphysbench: A first-principles benchmark for physical consistency in text-to-video gener- ation. arXiv preprint arXiv:2505.00337, 2025. 1
-
[40]
Multiple view ge- ometry in computer vision
Richard Hartley and Andrew Zisserman. Multiple view ge- ometry in computer vision . Cambridge university press,
-
[41]
Learning human- to-humanoid real-time whole-body teleoperation
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Learning human- to-humanoid real-time whole-body teleoperation. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8944–8951. IEEE, 2024. 3
work page 2024
-
[42]
Onepose++: Keypoint- free one-shot object pose estimation without cad models
Xingyi He, Jiaming Sun, Yuang Wang, Di Huang, Hu- jun Bao, and Xiaowei Zhou. Onepose++: Keypoint- free one-shot object pose estimation without cad models. Advances in Neural Information Processing Systems , 35: 35103–35115, 2022. 3
work page 2022
-
[43]
Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation
Yisheng He, Wei Sun, Haibin Huang, Jianran Liu, Hao- qiang Fan, and Jian Sun. Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11632–11641, 2020. 3
work page 2020
-
[44]
Ffb6d: A full flow bidirectional fusion network for 6d pose estimation
Yisheng He, Haibin Huang, Haoqiang Fan, Qifeng Chen, and Jian Sun. Ffb6d: A full flow bidirectional fusion network for 6d pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3003–3013, 2021. 3
work page 2021
-
[45]
Fs6d: Few-shot 6d pose estimation of novel objects
Yisheng He, Yao Wang, Haoqiang Fan, Jian Sun, and Qifeng Chen. Fs6d: Few-shot 6d pose estimation of novel objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 6814– 6824, 2022. 3
work page 2022
-
[46]
Spot: Se (3) pose trajectory diffusion for object-centric manipulation,
Cheng-Chun Hsu, Bowen Wen, Jie Xu, Yashraj Narang, Xi- aolong Wang, Yuke Zhu, Joydeep Biswas, and Stan Birch- field. Spot: Se (3) pose trajectory diffusion for object- centric manipulation. arXiv preprint arXiv:2411.00965 ,
-
[47]
Online human walking imitation in task and joint space based on quadratic programming
Kai Hu, Christian Ott, and Dongheui Lee. Online human walking imitation in task and joint space based on quadratic programming. In 2014 IEEE International Conference on Robotics and Automation (ICRA), pages 3458–3464. IEEE,
work page 2014
-
[48]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reasoning of rela- tional keypoint constraints for robotic manipulation. arXiv preprint arXiv:2409.01652, 2024. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying- Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Zi- wei Liu. Vbench++: Comprehensive and versatile bench- mark suite for video generative models. arXiv preprint arXiv:2411.13503, 2024. 6, 21, 22
-
[51]
Motiongpt: Human motion as a foreign lan- guage
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign lan- guage. Advances in Neural Information Processing Sys- tems, 36:20067–20079, 2023. 3
work page 2023
-
[52]
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Min- grun Jiang, and Huazhe Xu. Robo-abc: Affordance general- ization beyond categories via semantic correspondence for robot manipulation. In European Conference on Computer Vision, pages 222–239. Springer, 2024. 3
work page 2024
-
[53]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos. arXiv preprint arXiv:2410.11831 ,
-
[54]
Siddharth Karamcheti, Suraj Nair, Annie S Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics.arXiv preprint arXiv:2302.12766, 2023. 3
-
[55]
Egomimic: Scaling imitation learning via egocentric video,
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Dan- fei Xu. Egomimic: Scaling imitation learning via egocen- tric video. arXiv preprint arXiv:2410.24221, 2024. 1, 2
-
[56]
Video depth without video models,
Bingxin Ke, Dominik Narnhofer, Shengyu Huang, Lei Ke, Torben Peters, Katerina Fragkiadaki, Anton Obukhov, and Konrad Schindler. Video depth without video models,
-
[57]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph., 42(4):139–1,
-
[58]
Robot see robot do: Imitating articulated object manipu- lation with monocular 4d reconstruction
Justin Kerr, Chung Min Kim, Mingxuan Wu, Brent Yi, Qianqian Wang, Ken Goldberg, and Angjoo Kanazawa. Robot see robot do: Imitating articulated object manipu- lation with monocular 4d reconstruction. arXiv preprint arXiv:2409.18121, 2024. 2, 3, 8, 18
-
[59]
Garfield: Group anything with radiance fields
Chung Min Kim, Mingxuan Wu, Justin Kerr, Ken Gold- berg, Matthew Tancik, and Angjoo Kanazawa. Garfield: Group anything with radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21530–21539, 2024. 18
work page 2024
-
[60]
Learning to act from actionless videos through dense correspondences
Po-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, and Joshua B Tenenbaum. Learning to act from actionless videos through dense correspondences. arXiv preprint arXiv:2310.08576, 2023. 2, 3, 8, 18
-
[61]
Scott Kuindersma, Robin Deits, Maurice Fallon, Andr ´es Valenzuela, Hongkai Dai, Frank Permenter, Twan Koolen, Pat Marion, and Russ Tedrake. Optimization-based lo- comotion planning, estimation, and control design for the atlas humanoid robot. Autonomous robots, 40:429–455,
-
[62]
Cosypose: Consistent multi-view multi-object 6d pose estimation
Yann Labb ´e, Justin Carpentier, Mathieu Aubry, and Josef Sivic. Cosypose: Consistent multi-view multi-object 6d pose estimation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVII 16, pages 574–591. Springer, 2020. 3
work page 2020
-
[63]
Mega- pose: 6d pose estimation of novel objects via render & compare
Yann Labb ´e, Lucas Manuelli, Arsalan Mousavian, Stephen Tyree, Stan Birchfield, Jonathan Tremblay, Justin Carpen- tier, Mathieu Aubry, Dieter Fox, and Josef Sivic. Mega- pose: 6d pose estimation of novel objects via render & compare. In Proceedings of the 6th Conference on Robot Learning (CoRL), 2022. 3, 4, 20
work page 2022
-
[64]
Kinematic motion retargeting for contact- rich anthropomorphic manipulations
Arjun S Lakshmipathy, Jessica K Hodgins, and Nancy S Pollard. Kinematic motion retargeting for contact- rich anthropomorphic manipulations. arXiv preprint arXiv:2402.04820, 2024. 3
-
[65]
Phantom: Training robots without robots using only human videos, 2025
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Phan- tom: Training robots without robots using only human videos. arXiv preprint arXiv:2503.00779, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[66]
Ep n p: An accurate o (n) solution to the p n p problem
Vincent Lepetit, Francesc Moreno-Noguer, and Pascal Fua. Ep n p: An accurate o (n) solution to the p n p problem. In- ternational journal of computer vision , 81:155–166, 2009. 3
work page 2009
-
[67]
Fu Li, Shishir Reddy Vutukur, Hao Yu, Ivan Shugurov, Benjamin Busam, Shaowu Yang, and Slobodan Ilic. Nerf- pose: A first-reconstruct-then-regress approach for weakly- supervised 6d object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 2123–2133, 2023. 3
work page 2023
-
[68]
One-shot open affordance learning with foundation models
Gen Li, Deqing Sun, Laura Sevilla-Lara, and Varun Jam- pani. One-shot open affordance learning with foundation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 3086– 3096, 2024. 3
work page 2024
-
[69]
Learning precise affordances from ego- centric videos for robotic manipulation
Gen Li, Nikolaos Tsagkas, Jifei Song, Ruaridh Mon- Williams, Sethu Vijayakumar, Kun Shao, and Laura Sevilla-Lara. Learning precise affordances from ego- centric videos for robotic manipulation. arXiv preprint arXiv:2408.10123, 2024. 3
-
[70]
Okami: Teaching humanoid robots manipulation skills through single video imitation
Jinhan Li, Yifeng Zhu, Yuqi Xie, Zhenyu Jiang, Mingyo Seo, Georgios Pavlakos, and Yuke Zhu. Okami: Teaching humanoid robots manipulation skills through single video imitation. In 8th Annual Conference on Robot Learning ,
-
[71]
Amt: All-pairs multi- field transforms for efficient frame interpolation
Zhen Li, Zuo-Liang Zhu, Ling-Hao Han, Qibin Hou, Chun- Le Guo, and Ming-Ming Cheng. Amt: All-pairs multi- field transforms for efficient frame interpolation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 21
work page 2023
-
[72]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sud- hakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learn- ing via video generation. arXiv preprint arXiv:2406.16862,
-
[73]
Dynamic movement primitive based motion retargeting for dual-arm sign language mo- tions
Yuwei Liang, Weijie Li, Yue Wang, Rong Xiong, Yichao Mao, and Jiafan Zhang. Dynamic movement primitive based motion retargeting for dual-arm sign language mo- tions. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8195–8201. IEEE, 2021. 3
work page 2021
-
[74]
Reconx: Reconstruct any scene from sparse views with video diffusion model, 2025
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, and Yueqi Duan. Re- conx: Reconstruct any scene from sparse views with video diffusion model. arXiv preprint arXiv:2408.16767, 2024. 1
-
[75]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Unopose: Unseen object pose estimation with an unposed rgb-d refer- ence image
Xingyu Liu, Gu Wang, Ruida Zhang, Chenyangguang Zhang, Federico Tombari, and Xiangyang Ji. Unopose: Unseen object pose estimation with an unposed rgb-d refer- ence image. arXiv preprint arXiv:2411.16106, 2024. 3
-
[77]
Imitation from observation: Learning to imitate behaviors from raw video via context translation
YuXuan Liu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Imitation from observation: Learning to imitate behaviors from raw video via context translation. In 2018 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 1118–1125. IEEE, 2018. 3
work page 2018
-
[78]
Gen6d: General- izable model-free 6-dof object pose estimation from rgb im- ages
Yuan Liu, Yilin Wen, Sida Peng, Cheng Lin, Xiaoxiao Long, Taku Komura, and Wenping Wang. Gen6d: General- izable model-free 6-dof object pose estimation from rgb im- ages. In European Conference on Computer Vision, pages 298–315. Springer, 2022. 3
work page 2022
-
[79]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023. 3
work page 2023
-
[80]
Roboturk: A crowdsourcing platform for robotic skill learning through imitation
Ajay Mandlekar, Yuke Zhu, Animesh Garg, Jonathan Booher, Max Spero, Albert Tung, Julian Gao, John Em- mons, Anchit Gupta, Emre Orbay, et al. Roboturk: A crowdsourcing platform for robotic skill learning through imitation. In Conference on Robot Learning , pages 879–
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.