World-Env: Leveraging World Model as a Virtual Environment for VLA Post-Training
Pith reviewed 2026-05-18 12:44 UTC · model grok-4.3
The pith
A world model can replace real-world robot interactions for safe reinforcement learning post-training of vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
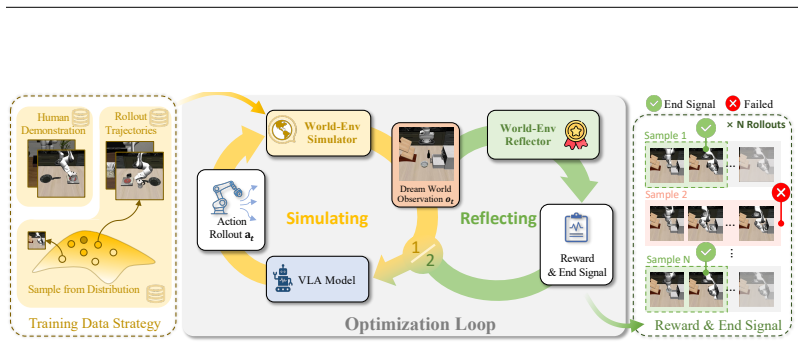
World-Env replaces physical robot interactions with a low-cost world model-based virtual simulator consisting of a physically-consistent world simulator that generates temporally consistent future visual observations and a VLM-guided instant reflector that provides continuous reward signals and predicts action termination, enabling VLA models to safely explore and generalize beyond their initial imitation learning distribution.
What carries the argument
Physically-consistent world simulator that produces temporally stable future visual observations, paired with a VLM-guided instant reflector for rewards and termination signals.
If this is right
- VLA models can undergo RL post-training without risking physical damage or requiring environment resets.
- Task success rates rise when the reflector supplies reliable termination signals that stop redundant actions.
- Meaningful gains appear with only five expert demonstrations per task instead of large demonstration sets.
- The same virtual environment supports safe exploration that extends beyond the original imitation distribution.
- Post-training becomes practical in resource-limited settings such as industrial automation.
Where Pith is reading between the lines
- The method could lower the data-collection burden for training embodied agents across a wider range of tasks.
- If the simulator remains accurate over longer horizons, it might support multi-step planning without real-world rollouts.
- Industrial deployments could adopt the framework to iterate policies safely before any physical trial.
- The approach invites tests on whether the same virtual loop works for non-manipulation skills such as navigation.
Load-bearing premise
The world model must generate future visual observations that remain accurate and stable enough for reinforcement learning to improve the policy without any real-world correction.
What would settle it
Train a VLA policy to convergence inside World-Env and then measure whether its real-world success rate on the same manipulation tasks exceeds the rate achieved by the original imitation-learning baseline.
Figures










read the original abstract
Vision-Language-Action (VLA) models trained via imitation learning suffer from significant performance degradation in data-scarce scenarios due to their reliance on large-scale demonstration datasets. Although reinforcement learning (RL)-based post-training has proven effective in addressing data scarcity, its application to VLA models is hindered by the non-resettable nature of real-world environments. This limitation is particularly critical in high-risk domains such as industrial automation, where interactions often induce state changes that are costly or infeasible to revert. Furthermore, existing VLA approaches lack a reliable mechanism for detecting task completion, leading to redundant actions that reduce overall task success rates. To address these challenges, we propose World-Env, an RL-based post-training framework that replaces physical interaction with a low-cost world model-based virtual simulator. World-Env consists of two key components: (1) a physically-consistent world simulator that generates temporally consistent future visual observations, and (2) a vision-language model (VLM)-guided instant reflector that provides continuous reward signals and predicts action termination. This simulated environment enables VLA models to safely explore and generalize beyond their initial imitation learning distribution. Our method achieves notable performance gains with as few as five expert demonstrations per task. Experiments on complex robotic manipulation tasks demonstrate that World-Env effectively overcomes the data inefficiency, safety constraints, and inefficient execution of conventional VLA models that rely on real-world interaction, offering a practical and scalable solution for post-training in resource-constrained settings. Our code is available at https://github.com/amap-cvlab/world-env.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes World-Env, an RL-based post-training framework for Vision-Language-Action (VLA) models. It replaces real-world interaction with a virtual simulator built from a physically-consistent world model that generates future visual observations, combined with a VLM-guided reflector that supplies rewards and predicts action termination. The central claim is that this setup enables safe exploration and generalization beyond the imitation-learning distribution, yielding notable performance gains on complex robotic manipulation tasks using as few as five expert demonstrations per task while addressing data inefficiency, safety constraints, and inefficient execution.
Significance. If the world-model simulator proves sufficiently accurate and temporally stable, the approach could meaningfully advance data-efficient and safe post-training of VLAs in robotics, especially in resource-limited or high-risk settings where real-world resets are costly. The explicit linkage of world models to VLA post-training via RL, together with the linked code repository, represents a practical contribution that could be built upon by the community.
major comments (2)
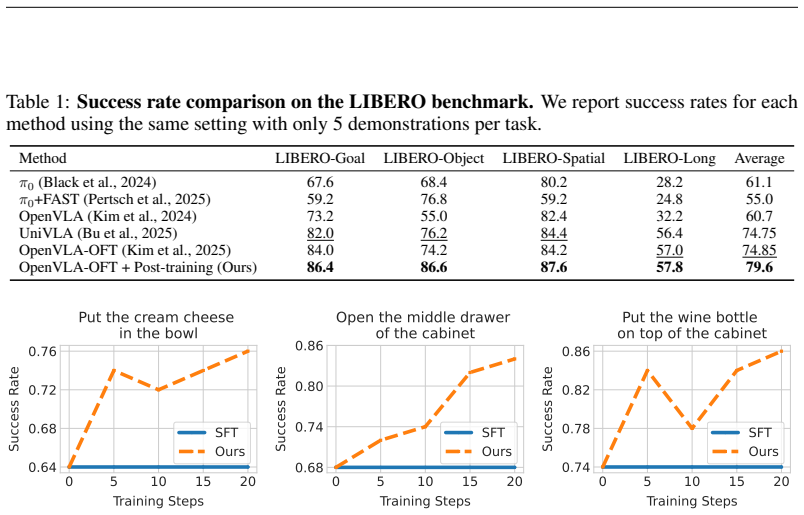
- [Abstract / Experimental evaluation] Abstract and experimental evaluation: the claim of 'notable performance gains with as few as five expert demonstrations' is presented without any quantitative metrics, baseline comparisons, error bars, ablation studies, or statistical tests. This information is load-bearing for the central empirical claim and must be supplied with concrete numbers and controls to allow evaluation of whether the method actually overcomes data inefficiency.
- [Method (world simulator component)] Method section describing the physically-consistent world simulator: no quantitative validation is reported for multi-step visual prediction accuracy, temporal stability, or enforcement of physical constraints over the horizons required for manipulation tasks. Because the RL post-training occurs entirely inside this simulator without real-world correction, compounding errors would cause the policy to optimize against simulator artifacts rather than true dynamics; explicit metrics (e.g., prediction MSE, constraint violation rates, or sim-to-real transfer) are therefore required.
minor comments (2)
- [Method] The description of the VLM-guided instant reflector would benefit from a clearer statement of how the termination prediction is trained and how false-positive terminations affect the RL objective.
- [Figures / Results] Figure captions and axis labels in the experimental results should explicitly state the number of random seeds and whether shaded regions represent standard deviation or standard error.
Simulated Author's Rebuttal
We sincerely thank the referee for their thorough and constructive feedback on our manuscript. The comments have helped us identify areas where the presentation and validation can be strengthened. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] Abstract and experimental evaluation: the claim of 'notable performance gains with as few as five expert demonstrations' is presented without any quantitative metrics, baseline comparisons, error bars, ablation studies, or statistical tests. This information is load-bearing for the central empirical claim and must be supplied with concrete numbers and controls to allow evaluation of whether the method actually overcomes data inefficiency.
Authors: We acknowledge the referee's concern regarding the lack of specific quantitative support for the central claim in the abstract and experimental evaluation. While the manuscript reports experimental results on complex manipulation tasks, we agree that more detailed metrics, baselines, error bars, ablations, and statistical tests are necessary to substantiate the performance gains with only five demonstrations. In the revised version, we will update the abstract with concrete numbers (such as success rate improvements) and expand the experimental section to include these elements for a rigorous evaluation. revision: yes
-
Referee: [Method (world simulator component)] Method section describing the physically-consistent world simulator: no quantitative validation is reported for multi-step visual prediction accuracy, temporal stability, or enforcement of physical constraints over the horizons required for manipulation tasks. Because the RL post-training occurs entirely inside this simulator without real-world correction, compounding errors would cause the policy to optimize against simulator artifacts rather than true dynamics; explicit metrics (e.g., prediction MSE, constraint violation rates, or sim-to-real transfer) are therefore required.
Authors: We thank the referee for this important observation. The method section emphasizes the physical consistency and temporal aspects of the world simulator, but we recognize that quantitative metrics for multi-step accuracy, stability, and constraint enforcement are not explicitly provided. Given the reliance on the simulator for RL post-training, this is a critical gap. We will add quantitative validation results, including prediction errors, stability measures, and sim-to-real comparisons, to the revised manuscript to demonstrate the simulator's reliability. revision: yes
Circularity Check
No significant circularity; framework builds on external world models and VLMs without self-referential reduction
full rationale
The paper proposes World-Env as an RL post-training framework that substitutes real-world interaction with a world-model-based virtual simulator and a VLM-guided reflector. No equations, derivations, or fitted parameters are described that reduce claimed performance gains to quantities defined by construction from the same inputs or self-citations. The method explicitly relies on pre-existing components (physically-consistent world simulators and VLMs) whose accuracy is treated as an external assumption rather than derived internally. Experiments are presented as empirical validation rather than tautological predictions. This is a standard non-circular engineering contribution that assembles known modules for a new application.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A world model can produce temporally consistent future visual observations that remain physically plausible across multiple steps.
- domain assumption A vision-language model can reliably detect task completion and provide continuous reward signals from simulated observations.
Forward citations
Cited by 17 Pith papers
-
ALAM: Algebraically Consistent Latent Action Model for Vision-Language-Action Models
ALAM creates algebraically consistent latent action transitions from videos to act as auxiliary generative targets, raising robot policy success rates from 47.9% to 85.0% on MetaWorld MT50 and 94.1% to 98.1% on LIBERO.
-
One Token Per Frame: Reconsidering Visual Bandwidth in World Models for VLA Policy
Reducing visual input to one token per frame in VLA world models maintains or improves long-horizon performance on MetaWorld, LIBERO, and real-robot tasks.
-
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
DreamDojo is a foundation world model pretrained on the largest human video dataset to date that uses continuous latent actions to transfer interaction knowledge and achieves controllable physics simulation after robo...
-
Reinforcing VLAs in Task-Agnostic World Models
RAW-Dream disentangles world-model learning from task data by using a pre-trained task-agnostic world model and VLM rewards, with dual-noise filtering, to enable zero-shot VLA adaptation in simulation and real settings.
-
Reinforcing VLAs in Task-Agnostic World Models
RAW-Dream lets VLAs learn new tasks in zero-shot imagination by using a world model pre-trained only on task-free behaviors and an unmodified VLM to supply rewards, with dual-noise verification to limit hallucinations.
-
ALAM: Algebraically Consistent Latent Action Model for Vision-Language-Action Models
ALAM introduces algebraic consistency regularization on latent action transitions from videos, raising VLA success rates from 47.9% to 85.0% on MetaWorld MT50 and 94.1% to 98.1% on LIBERO.
-
One Token Per Frame: Reconsidering Visual Bandwidth in World Models for VLA Policy
Reducing visual input to one token per frame in world models for vision-language-action policies maintains long-horizon performance while improving success rates on MetaWorld, LIBERO, and real-robot tasks.
-
One Token Per Frame: Reconsidering Visual Bandwidth in World Models for VLA Policy
Reducing visual input to one token per frame via adaptive attention pooling and a unified flow-matching objective improves long-horizon performance in VLA policies on MetaWorld, LIBERO, and real-robot tasks.
-
Hi-WM: Human-in-the-World-Model for Scalable Robot Post-Training
Hi-WM uses human interventions inside an action-conditioned world model with rollback and branching to generate dense corrective data, raising real-world success by 37.9 points on average across three manipulation tasks.
-
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Video generation models can function as world simulators if efficiency gaps in spatiotemporal modeling are bridged via organized paradigms, architectures, and algorithms.
-
VLANeXt: Recipes for Building Strong VLA Models
VLANeXt distills 12 design insights from a unified VLA study into a model that outperforms prior methods on LIBERO benchmarks while releasing code for further exploration.
-
Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-Tuning
LifeLong-RFT applies chunking-level on-policy reinforcement learning with Quantized Action Consistency Reward, Continuous Trajectory Alignment Reward, and Format Compliance Reward to fine-tune VLA models, achieving a ...
-
WorldArena 2.0: Extending Embodied World Model Benchmarking on Modality, Functionality and Platform
WorldArena 2.0 extends embodied world model benchmarks to visuotactile perception, interactive policy training, and diverse real and simulated robotic platforms under a unified protocol.
-
DyGRO-VLA: Cross-Task Scaling of Vision-Language-Action Models via Dynamic Grouped Residual Optimization
DyGRO-VLA is a two-stage optimization framework for cross-task scaling of Vision-Language-Action models via dynamic grouped residual optimization in RL.
-
Learning Action Manifold with Multi-view Latent Priors for Robotic Manipulation
The method uses multi-view diffusion priors and action manifold learning to resolve depth ambiguity and improve action prediction in VLA robotic manipulation models, reporting higher success rates than baselines on LI...
-
World-Value-Action Model: Implicit Planning for Vision-Language-Action Systems
The World-Value-Action model enables implicit planning for VLA systems by performing inference over a learned latent representation of high-value future trajectories instead of direct action prediction.
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gall ´e, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet ¨Ust¨un, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learn- ing from human feedback in llms.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Diwa: Diffusion policy adaptation with world models.arXiv preprint arXiv:2508.03645,
Akshay L Chandra, Iman Nematollahi, Chenguang Huang, Tim Welschehold, Wolfram Burgard, and Abhinav Valada. Diwa: Diffusion policy adaptation with world models.arXiv preprint arXiv:2508.03645,
-
[7]
Reinforcement learning for long-horizon interactive llm agents.arXiv preprint arXiv:2502.01600, 2025
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Kr ¨ahenb¨uhl. Reinforcement learning for long-horizon interactive llm agents.arXiv preprint arXiv:2502.01600,
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with dis- crete world models.arXiv preprint arXiv:2010.02193,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Anqing Jiang, Yu Gao, Yiru Wang, Zhigang Sun, Shuo Wang, Yuwen Heng, Hao Sun, Shichen Tang, Lijuan Zhu, Jinhao Chai, et al. Irl-vla: Training an vision-language-action policy via reward world model.arXiv preprint arXiv:2508.06571, 2025a. Yuxin Jiang, Shengcong Chen, Siyuan Huang, Liliang Chen, Pengfei Zhou, Yue Liao, Xindong He, Chiming Liu, Hongsheng Li,...
-
[12]
Improved Baselines with Visual Instruction Tuning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. InNeurIPS, 2023a. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744, 2023b. Haotian Liu, Chunyuan Li, Qingyang Wu, an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Interactive Post-Training for Vision-Language-Action Models
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Kr ¨ahenb¨uhl. Interactive post-training for vision- language-action models.arXiv preprint arXiv:2505.17016,
work page internal anchor Pith review arXiv
-
[17]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Ar- mand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron, Louis Martin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
doi: 10.1109/ACCESS.2020.2983149. 13 A ALGORITHM Algorithm 1World-Env Training Algorithm Input:Pretrained VLA policyπ θ, scale headβ θ, VLM-based reward functionR(o 1:t,g), context datasetD context 1:fortraining iteration= 1toMdo 2:Set behavior policy:π ϕ ←π θ,β ϕ ←β θ ▷Fix old policy and scale head 3:Initialize rollout bufferD rollout ← ∅ 4:while|D rollo...
-
[21]
31:end for 32:end for B MOREIMPLEMENTATIONDETAILS B.1 DEATILS OFSCALEHEAD Our method builds upon OpenVLA-OFT (Kim et al., 2025), which predicts continuous actions via an action head that takes hidden statesf∈R d as input and employs L1 loss for action regression: LL1 =∥a gt −µ∥ 1 whereµ=MLP action(f).(6) To model heteroscedastic uncertainty in action pred...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.