Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Pith reviewed 2026-05-21 22:34 UTC · model grok-4.3
The pith
PROF curates RL training data by PRM-ORM consistency to improve both final accuracy and reasoning quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that selecting training samples by consistency between PRM and ORM scores allows RL to harmonize process and outcome rewards without the instability of direct optimization or naive combination under distribution shift, producing policies that improve both final-answer accuracy and intermediate reasoning quality.
What carries the argument
PRocess cOnsistency Filter (PROF), a data curation method that selects samples using agreement between process reward model scores and outcome reward model scores rather than direct reward optimization.
Load-bearing premise
Selecting samples based on PRM-ORM consistency produces stable training signals under distribution shift and avoids introducing new biases while maintaining a balanced training ratio.
What would settle it
A controlled experiment on a reasoning benchmark under distribution shift where PROF-filtered data produces no gain or a loss in measured reasoning quality metrics such as step-wise correctness compared to unfiltered RLVR baselines.
Figures





read the original abstract
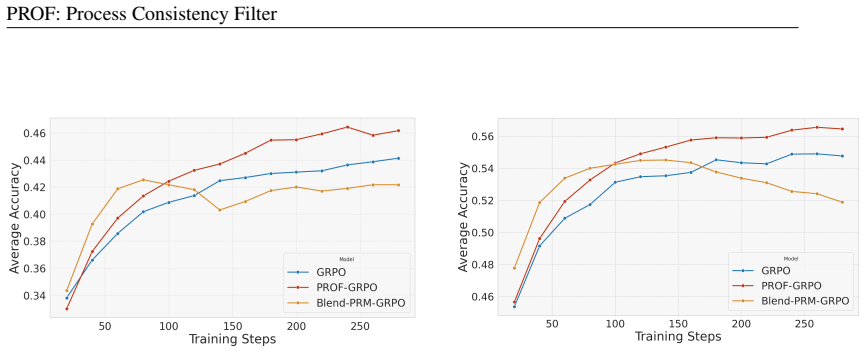
Reinforcement Learning with Verifiable Rewards (RLVR) improves final-answer accuracy on reasoning tasks, but it does not reliably improve reasoning quality. Because outcome rewards only assess final answers, they also reward spurious successes: flawed reasoning can still receive maximal reward when it accidentally reaches the correct outcome. This outcome reward hacking creates biased gradients, making current RLVR insufficient for learning faithful reasoning. Process Reward Models (PRMs) provide step-wise supervision, but directly optimizing PRMs or naively combining them with outcome rewards is unstable under distribution shift during RL training process. We introduce PRocess cOnsistency Filter (PROF), a data curation method that uses PRM--ORM consistency for sample selection rather than direct reward optimization. PROF keeps correct responses with strong process support and incorrect responses with weak process support while maintaining a balanced training ratio. Experiments show that PROF consistently improves both final-answer accuracy and intermediate reasoning quality over strong baselines, with less dependence on strong PRMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PROF (PRocess cOnsistency Filter), a data curation technique for RLVR on reasoning tasks. Instead of directly optimizing or combining PRMs with outcome rewards, PROF selects training samples by retaining correct trajectories that receive high PRM scores and incorrect trajectories that receive low PRM scores, while preserving a balanced ratio. The central claim is that this curation produces more stable training signals, yielding simultaneous gains in final-answer accuracy and intermediate reasoning quality with reduced dependence on strong PRMs.
Significance. If the empirical results hold under the reported conditions, the work is significant because it offers a practical alternative to unstable direct PRM optimization in RL for faithful reasoning. The explicit credit for providing reproducible code, multiple baseline comparisons, and quantitative checks on reasoning quality metrics strengthens the contribution; a curation method that demonstrably lowers reliance on high-quality PRMs could influence data pipelines for reasoning models.
major comments (2)
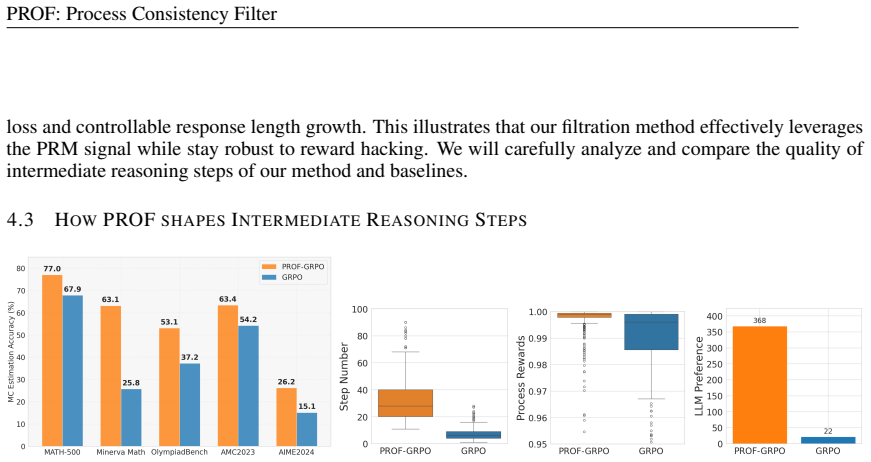
- [§4.3, Table 4] §4.3 and Table 4: the claim of reduced dependence on strong PRMs is supported by one ablation, but the paper does not report the correlation between PROF-selected process scores and human-annotated reasoning errors; without this check the selection-bias concern (that the filter may reinforce PRM-preferred spurious patterns rather than causal reasoning steps) remains unaddressed and is load-bearing for the faithfulness claim.
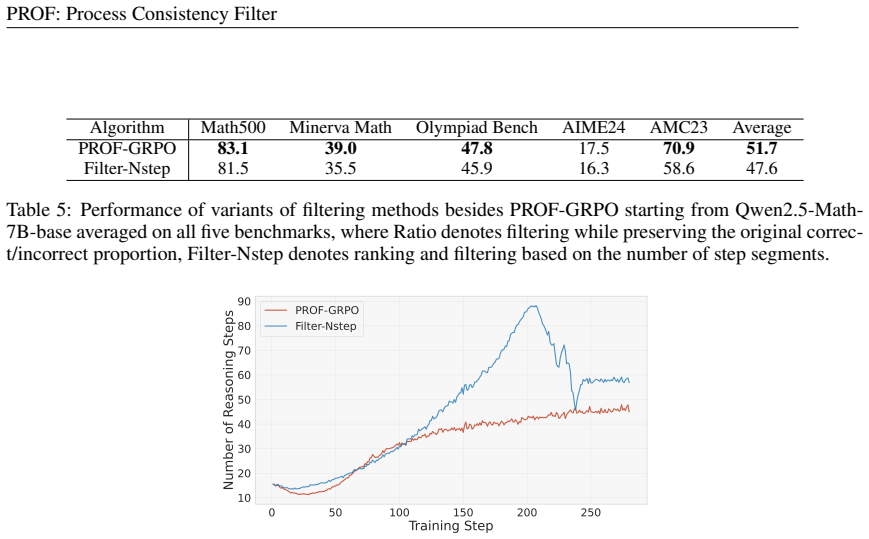
- [§3.2] §3.2: the consistency rule is described only procedurally; no equation formalizes the exact threshold or scoring function used to decide 'strong' vs. 'weak' process support, making it impossible to verify whether the method is parameter-free or how it behaves under the distribution shift that occurs once RL updates begin.
minor comments (2)
- [Figure 2] Figure 2 caption: the legend does not distinguish the PROF curve from the PRM-only baseline in the printed version; add line-style or marker differentiation.
- [§3] The acronym expansion for PROF appears only in the abstract; repeat the full name on first use in §3.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and outline revisions to improve clarity and address concerns about selection bias.
read point-by-point responses
-
Referee: [§4.3, Table 4] §4.3 and Table 4: the claim of reduced dependence on strong PRMs is supported by one ablation, but the paper does not report the correlation between PROF-selected process scores and human-annotated reasoning errors; without this check the selection-bias concern (that the filter may reinforce PRM-preferred spurious patterns rather than causal reasoning steps) remains unaddressed and is load-bearing for the faithfulness claim.
Authors: We acknowledge that a direct correlation with human-annotated reasoning errors is not reported. However, the ablation in §4.3 and Table 4 shows consistent gains in both final-answer accuracy and reasoning quality metrics when PROF is used with weaker PRMs. This robustness across PRM strengths indicates that the consistency filter does not primarily amplify spurious patterns captured only by strong PRMs. We will add a discussion paragraph in the revision elaborating on how the balanced retention of high-consistency correct and low-consistency incorrect trajectories mitigates selection bias. revision: partial
-
Referee: [§3.2] §3.2: the consistency rule is described only procedurally; no equation formalizes the exact threshold or scoring function used to decide 'strong' vs. 'weak' process support, making it impossible to verify whether the method is parameter-free or how it behaves under the distribution shift that occurs once RL updates begin.
Authors: We agree that a formal definition would improve verifiability. In the revised manuscript we will add an equation in §3.2 that defines the process consistency score as a function of PRM and ORM outputs, specifies the thresholds for strong versus weak support, and states that the filter is re-applied at each RL iteration using the current PRM. This will also allow explicit discussion of behavior under distribution shift. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents PROF as an empirical data curation method that selects samples based on PRM-ORM consistency to balance process and outcome signals during RL training. Improvements to final-answer accuracy and intermediate reasoning quality are demonstrated via experiments against baselines rather than any mathematical derivation or first-principles chain. No equations, self-citations, or fitted parameters are shown to reduce the central claims to inputs by construction; the selection rule is an independent curation step whose effects are measured externally.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Outcome rewards alone reward spurious successes in reasoning tasks
- domain assumption Direct optimization of PRMs or naive combination with outcome rewards is unstable under distribution shift
invented entities (1)
-
PROF (Process cOnsistency Filter)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PROF keeps correct responses with strong process support and incorrect responses with weak process support while maintaining a balanced training ratio.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose PRocess cOnsistency Filtering (PROF) to robustly integrate noisy Process Reward Models (PRMs) with Outcome Reward Models (ORMs).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
HiPRAG adds hierarchical process rewards to RL training for agentic RAG, reducing over-search to 2.3% and achieving 65.4-67.2% accuracy on seven QA benchmarks across 3B and 7B models.
-
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
DGPO reinterprets distribution deviation as a guiding signal in a critic-free policy optimization framework to enable fine-grained credit assignment for LLM chain-of-thought reasoning.
-
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
DGPO is a critic-free RL framework that uses bounded Hellinger distance and entropy-gated advantage redistribution to enable fine-grained token-level credit assignment in long CoT generations for LLM alignment, report...
-
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
The paper introduces the Proxy Compression Hypothesis as a unifying framework explaining reward hacking in RLHF as an emergent result of compressing high-dimensional human objectives into proxy reward signals under op...
-
PubSwap: Public-Data Off-Policy Coordination for Federated RLVR
PubSwap uses a small public dataset for selective off-policy response swapping in federated RLVR to improve coordination and performance over standard baselines on math and medical reasoning tasks.
-
LLM Reasoning with Process Rewards for Outcome-Guided Steps
PROGRS uses outcome-conditioned centering on PRM scores to safely integrate process rewards into GRPO for improved Pass@1 on math benchmarks.
Reference graph
Works this paper leans on
-
[1]
Edward Beeching, Shengyi Costa Huang, Albert Jiang, Jia Li, Benjamin Lipkin, Zihan Qina, Kashif Rasul, Ziju Shen, Roman Soletskyi, and Lewis Tunstall. Numinamath 7b cot. https://huggingface.co/AI-MO/NuminaMath-7B-CoT, 2024
work page 2024
-
[2]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
work page 1952
-
[3]
Bridging supervised learning and reinforcement learning in math reasoning
Huayu Chen, Kaiwen Zheng, Qinsheng Zhang, Ganqu Cui, Yin Cui, Haotian Ye, Tsung-Yi Lin, Ming-Yu Liu, Jun Zhu, and Haoxiang Wang. Bridging supervised learning and reinforcement learning in math reasoning. arXiv preprint arXiv:2505.18116, 2025
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp.\ arXiv--2407, 2024
work page 2024
-
[9]
J., Fisch, A., Heller, K., Pfohl, S., Ramachandran, D., Shaw, P., and Berant, J
Jacob Eisenstein, Chirag Nagpal, Alekh Agarwal, Ahmad Beirami, Alex D'Amour, DJ Dvijotham, Adam Fisch, Katherine Heller, Stephen Pfohl, Deepak Ramachandran, et al. Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking. arXiv preprint arXiv:2312.09244, 2023
-
[10]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Process reward models that think
Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, and Lu Wang. Process reward models that think. arXiv preprint arXiv:2504.16828, 2025
-
[15]
Sunnie SY Kim, Q Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. " i'm not sure, but...": Examining the impact of large language models' uncertainty expression on user reliance and trust. In Proceedings of the 2024 ACM conference on fairness, accountability, and transparency, pp.\ 822--835, 2024
work page 2024
-
[16]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. Advances in neural information processing systems, 35: 0 3843--3857, 2022
work page 2022
-
[17]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[18]
Mitigating the alignment tax of rlhf
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, et al. Mitigating the alignment tax of rlhf. arXiv preprint arXiv:2309.06256, 2023
-
[19]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. Improve mathematical reasoning in language models by automated process supervision, 2024. URL https://arxiv.org/abs/2406.06592
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. In The 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023), 2023
work page 2023
-
[21]
Understanding learned reward functions
Eric J Michaud, Adam Gleave, and Stuart Russell. Understanding learned reward functions. arXiv preprint arXiv:2012.05862, 2020
-
[22]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pp.\ 1279--1297, 2025
work page 2025
-
[25]
Causal confusion and reward misidentification in preference-based reward learning
Jeremy Tien, Jerry Zhi-Yang He, Zackory Erickson, Anca D Dragan, and Daniel S Brown. Causal confusion and reward misidentification in preference-based reward learning. arXiv preprint arXiv:2204.06601, 2022
-
[26]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Building math agents with multi-turn iterative preference learning
Wei Xiong, Chengshuai Shi, Jiaming Shen, Aviv Rosenberg, Zhen Qin, Daniele Calandriello, Misha Khalman, Rishabh Joshi, Bilal Piot, Mohammad Saleh, et al. Building math agents with multi-turn iterative preference learning. arXiv preprint arXiv:2409.02392, 2024 a
-
[28]
An implementation of generative prm, 2024 b
Wei Xiong, Hanning Zhang, Nan Jiang, and Tong Zhang. An implementation of generative prm, 2024 b
work page 2024
-
[29]
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, et al. A minimalist approach to llm reasoning: from rejection sampling to reinforce. arXiv preprint arXiv:2504.11343, 2025 a
-
[30]
Self-rewarding correction for mathematical reasoning.arXiv preprint arXiv:2502.19613,
Wei Xiong, Hanning Zhang, Chenlu Ye, Lichang Chen, Nan Jiang, and Tong Zhang. Self-rewarding correction for mathematical reasoning. arXiv preprint arXiv:2502.19613, 2025 b
-
[31]
Stepwiser: Stepwise generative judges for wiser reasoning, 2025 c
Wei Xiong, Wenting Zhao, Weizhe Yuan, Olga Golovneva, Tong Zhang, Jason Weston, and Sainbayar Sukhbaatar. Stepwiser: Stepwise generative judges for wiser reasoning, 2025 c . URL https://arxiv.org/abs/2508.19229
-
[32]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Yixuan Even Xu, Yash Savani, Fei Fang, and Zico Kolter. Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning. arXiv preprint arXiv:2504.13818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Wei Jie Yeo, Ranjan Satapathy, Rick Siow Mong Goh, and Erik Cambria. How interpretable are reasoning explanations from prompting large language models? arXiv preprint arXiv:2402.11863, 2024
-
[35]
Rip: Better models by survival of the fittest prompts
Ping Yu, Weizhe Yuan, Olga Golovneva, Tianhao Wu, Sainbayar Sukhbaatar, Jason Weston, and Jing Xu. Rip: Better models by survival of the fittest prompts. arXiv preprint arXiv:2501.18578, 2025 a
-
[36]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020, 3, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Rl tango: Reinforcing generator and verifier together for language reasoning
Kaiwen Zha, Zhengqi Gao, Maohao Shen, Zhang-Wei Hong, Duane S Boning, and Dina Katabi. Rl tango: Reinforcing generator and verifier together for language reasoning. arXiv preprint arXiv:2505.15034, 2025
-
[39]
Policy filtration in rlhf to fine-tune llm for code generation
Chuheng Zhang, Wei Shen, Li Zhao, Xuyun Zhang, Lianyong Qi, Wanchun Dou, and Jiang Bian. Policy filtration in rlhf to fine-tune llm for code generation. 2024
work page 2024
-
[40]
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
arXiv preprint arXiv:2504.00891
Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, and Bowen Zhou. Genprm: Scaling test-time compute of process reward models via generative reasoning, 2025. URL https://arxiv.org/abs/2504.00891
-
[42]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559, 2024
-
[43]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Chain-of-thought matters: improving long-context language models with reasoning path supervision
Dawei Zhu, Xiyu Wei, Guangxiang Zhao, Wenhao Wu, Haosheng Zou, Junfeng Ran, Xun Wang, Lin Sun, Xiangzheng Zhang, and Sujian Li. Chain-of-thought matters: improving long-context language models with reasoning path supervision. arXiv preprint arXiv:2502.20790, 2025
-
[45]
Reasonflux-prm: Trajectory-aware prms for long chain-of-thought reasoning in llms
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. Reasonflux-prm: Trajectory-aware prms for long chain-of-thought reasoning in llms. arXiv preprint arXiv:2506.18896, 2025
-
[46]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[47]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[48]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[49]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.