Recognition: no theorem link
MoRight: Motion Control Done Right
Pith reviewed 2026-05-10 17:34 UTC · model grok-4.3
The pith
MoRight separates object motion from camera viewpoint and models causal interactions in video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MoRight, a unified framework for motion-controlled video generation that specifies object motion in a canonical static view, transfers it to arbitrary target viewpoints using temporal cross-view attention for disentangled control, and decomposes motion into active and passive components to learn causality from data, supporting both forward prediction of consequences and inverse recovery of actions.
What carries the argument
Temporal cross-view attention for transferring canonical object motion to target views, together with active-passive motion decomposition for causality learning.
If this is right
- Users gain independent control over object movements and camera positions in generated videos.
- The system predicts coherent passive reactions from user-specified active motions.
- Desired passive outcomes can be used to infer plausible active driving actions.
- Performance improves on benchmarks for video quality, motion accuracy, and interaction realism.
Where Pith is reading between the lines
- This separation could support interactive tools where users sketch actions and receive physically consistent scene updates in real time.
- The inverse reasoning path might help in animation pipelines by letting artists specify end effects and recovering the required inputs.
- If the causality learning generalizes, the approach could transfer to simulation domains needing forward prediction of multi-object dynamics.
Load-bearing premise
The training data contains enough examples of causal object interactions so the model can learn to separate active from passive motions without supervision, and the attention transfer works without artifacts even for large viewpoint changes.
What would settle it
Provide an active motion such as one object pushing another, then verify whether the model produces the expected passive reactions like collisions or falls when the camera viewpoint changes substantially from the canonical one.
Figures







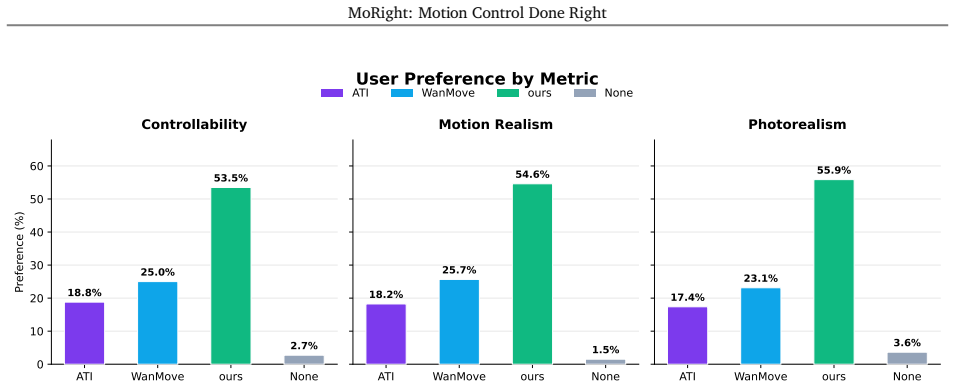







read the original abstract
Generating motion-controlled videos--where user-specified actions drive physically plausible scene dynamics under freely chosen viewpoints--demands two capabilities: (1) disentangled motion control, allowing users to separately control the object motion and adjust camera viewpoint; and (2) motion causality, ensuring that user-driven actions trigger coherent reactions from other objects rather than merely displacing pixels. Existing methods fall short on both fronts: they entangle camera and object motion into a single tracking signal and treat motion as kinematic displacement without modeling causal relationships between object motion. We introduce MoRight, a unified framework that addresses both limitations through disentangled motion modeling. Object motion is specified in a canonical static-view and transferred to an arbitrary target camera viewpoint via temporal cross-view attention, enabling disentangled camera and object control. We further decompose motion into active (user-driven) and passive (consequence) components, training the model to learn motion causality from data. At inference, users can either supply active motion and MoRight predicts consequences (forward reasoning), or specify desired passive outcomes and MoRight recovers plausible driving actions (inverse reasoning), all while freely adjusting the camera viewpoint. Experiments on three benchmarks demonstrate state-of-the-art performance in generation quality, motion controllability, and interaction awareness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MoRight, a unified framework for motion-controlled video generation. Object motion is defined in a canonical static view and transferred to arbitrary target viewpoints using temporal cross-view attention, achieving disentangled control over object motion and camera. Motion is further decomposed into active (user-driven) and passive (consequence) components, with the model trained to learn motion causality from data. This enables forward reasoning (predict consequences from active motion) and inverse reasoning (recover actions from desired passive outcomes) at inference, while allowing free viewpoint adjustment. The work claims state-of-the-art results on three benchmarks for generation quality, motion controllability, and interaction awareness.
Significance. If the disentanglement via cross-view attention and the unsupervised active-passive decomposition hold up under rigorous validation, the approach could advance controllable video synthesis by enabling more physically plausible interactions and bidirectional reasoning. The inverse mode, in particular, would be a useful capability for applications in animation and simulation if the causality modeling proves robust rather than correlational.
major comments (2)
- [Abstract / Method] Abstract and method description (no section/equation numbers provided in the supplied text): The central claim that active-passive decomposition is learned from data to capture motion causality lacks any mention of an auxiliary loss, architectural separation, or inductive bias that would penalize non-causal mappings. In the absence of such mechanisms, the training objective can be satisfied by learning kinematic correlations or viewpoint-dependent patterns, directly undermining the forward and inverse reasoning modes asserted at inference.
- [Experiments] Experiments section (referenced but not detailed): The abstract asserts SOTA performance on three benchmarks for quality, controllability, and interaction awareness, yet provides no quantitative metrics, ablation studies on the active-passive split, or error analysis comparing against baselines that lack explicit causality modeling. This makes it impossible to assess whether the claimed gains are attributable to the proposed decomposition or to other factors.
minor comments (2)
- [Abstract] The abstract would benefit from a brief reference to the specific quantitative improvements (e.g., percentage gains on key metrics) rather than a high-level SOTA claim.
- [Method] Notation for active/passive components and the temporal cross-view attention mechanism should be introduced with equations or pseudocode in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas for clarification on the causality modeling and for strengthening the experimental validation. We address each major comment point by point below. We plan to incorporate revisions that improve clarity without altering the core technical contributions.
read point-by-point responses
-
Referee: [Abstract / Method] The central claim that active-passive decomposition is learned from data to capture motion causality lacks any mention of an auxiliary loss, architectural separation, or inductive bias that would penalize non-causal mappings. In the absence of such mechanisms, the training objective can be satisfied by learning kinematic correlations or viewpoint-dependent patterns, directly undermining the forward and inverse reasoning modes asserted at inference.
Authors: We appreciate this observation on the need for explicit mechanisms. The method implements the active-passive decomposition via separate prediction branches for user-driven (active) and consequence (passive) motions, with the overall training objective combining reconstruction losses on both components and a temporal consistency term that requires passive motions to be predictable from active ones under the canonical-view transfer. This architectural separation and consistency constraint serve as the inductive bias. We acknowledge that the abstract and high-level method overview do not sufficiently detail these elements, which could lead to the interpretation raised. We will revise the method section to explicitly describe the loss formulation and branch separation, including how they discourage purely correlational solutions and support the bidirectional reasoning at inference. revision: yes
-
Referee: [Experiments] The abstract asserts SOTA performance on three benchmarks for quality, controllability, and interaction awareness, yet provides no quantitative metrics, ablation studies on the active-passive split, or error analysis comparing against baselines that lack explicit causality modeling. This makes it impossible to assess whether the claimed gains are attributable to the proposed decomposition or to other factors.
Authors: We agree that additional experimental details are warranted to substantiate the claims. The full experiments section reports quantitative results (FID, FVD, motion accuracy, and interaction metrics) across the three benchmarks with comparisons to prior methods. However, we did not include dedicated ablations isolating the active-passive split or error breakdowns versus non-causal baselines. We will add these ablations and analyses in the revised version, including quantitative comparisons that isolate the contribution of the decomposition to controllability and interaction awareness. revision: yes
Circularity Check
No circularity: claims rest on data-driven learning without self-referential reductions
full rationale
The paper presents MoRight as a learned neural framework that decomposes motion into active/passive components and uses temporal cross-view attention, with all capabilities emerging from training on video data. No equations, derivations, or parameter-fitting steps are described that would make any 'prediction' or 'result' equivalent to its inputs by construction. No self-citations are invoked as load-bearing premises, and the central claims (disentangled control, forward/inverse reasoning) are positioned as outcomes of standard supervised or self-supervised training rather than tautological redefinitions. This is the expected non-finding for a data-driven generative model without explicit mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
J. Bai, M. Xia, X. Wang, Z. Yuan, X. Fu, Z. Liu, H. Hu, P. Wan, and D. Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints.Proc. ICLR, 2025. 4, 7, 8
2025
-
[3]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang, Q....
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
H. Bansal, C. Peng, Y. Bitton, R. Goldenberg, A. Grover, and K.-W. Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025. 18
-
[6]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y. LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025. 2
2025
-
[7]
Blattmann, R
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023. 2
2023
-
[8]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y. Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video generation models as world simulators.OpenAI technical reports, 2024. 2
2024
-
[9]
Q. Bu, J. Cai, L. Chen, X. Cui, Y. Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669,
work page internal anchor Pith review arXiv
-
[10]
Burgert, Y
R. Burgert, Y. Xu, W. Xian, O. Pilarski, P. Clausen, M. He, L. Ma, Y. Deng, L. Li, M. Mousavi, et al. Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13–23, 2025. 2
2025
-
[11]
B. Chen, H. Jiang, S. Liu, S. Gupta, Y. Li, H. Zhao, and S. Wang. Physgen3d: Crafting a miniature interactive world from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6178–6189, 2025. 2, 3
2025
- [12]
-
[13]
T.-S. Chen, A. Siarohin, W. Menapace, E. Deyneka, H.-w. Chao, B. E. Jeon, Y. Fang, H.-Y. Lee, J. Ren, M.-H. Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 8
2024
-
[14]
Y. Chen, Y. Men, Y. Yao, M. Cui, and L. Bo. Perception-as-control: Fine-grained controllable image animation with 3d-aware motion representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14380–14389, 2025. 3
2025
- [15]
-
[16]
T. Cosmos. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 4 23 Appendix
work page internal anchor Pith review arXiv 2025
-
[17]
Doersch, Y
C. Doersch, Y. Yang, M. Vecerik, D. Gokay, A. Gupta, Y. Aytar, J. Carreira, and A. Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023. 3
2023
-
[18]
Elfwing, E
S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018. 16
2018
-
[19]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE international conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017. 6
2017
- [21]
- [22]
-
[23]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y. Dong, K. Mo, C.-H. Lin, Q. Ma, S. Nah, L. Magne, J. Xiang, Y. Xie, R. Zheng, D. Niu, Y. L. Tan, K. Zentner, G. Kurian, S. Indupuru, P. Jannaty, J. Gu, J. Zhang, J. Malik, P. Abbeel, M.-Y. Liu, Y. Zhu, J. Jang, and L. J. Fan. Dreamdojo: A generalist robot world model from large-scale human...
-
[24]
D. Geng, C. Herrmann, J. Hur, F. Cole, S. Zhang, T. Pfaff, T. Lopez-Guevara, C. Doersch, Y. Aytar, M. Rubinstein, C. Sun, O. Wang, A. Owens, and D. Sun. Motion prompting: Controlling video generation with motion trajectories. arXiv preprint arXiv:2412.02700, 2024. 2, 3, 5, 8, 9, 11
-
[25]
N. Gillman, C. Herrmann, M. Freeman, D. Aggarwal, E. Luo, D. Sun, and C. Sun. Force prompting: Video generation models can learn and generalize physics-based control signals.arXiv preprint arXiv:2505.19386, 2025. 3
-
[26]
Z. Gu, R. Yan, J. Lu, P. Li, Z. Dou, C. Si, Z. Dong, Q. Liu, C. Lin, Z. Liu, et al. Diffusion as shader: 3d-aware video diffusion for versatile video generation control. InSIGGRAPH, 2025. 3
2025
-
[27]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019. 2
work page internal anchor Pith review arXiv 1912
-
[28]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019. 6
2019
-
[29]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[30]
A. W. Harley, Y. You, X. Sun, Y. Zheng, N. Raghuraman, Y. Gu, S. Liang, W.-H. Chu, A. Dave, S. You, et al. Alltracker: Efficient dense point tracking at high resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5253–5262, 2025. 3, 6, 7
2025
-
[31]
H. He, Y. Xu, Y. Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 8
work page internal anchor Pith review arXiv 2024
-
[32]
X. He, C. Peng, Z. Liu, B. Wang, Y. Zhang, Q. Cui, F. Kang, B. Jiang, M. An, Y. Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InProc. NeurIPS, 2017. 8
2017
-
[34]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 2
work page internal anchor Pith review arXiv 2022
- [35]
-
[36]
arXiv preprint arXiv:2508.10934 (2025)
J. Huang, Q. Zhou, H. Rabeti, A. Korovko, H. Ling, X. Ren, T. Shen, J. Gao, D. Slepichev, C.-H. Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025. 3, 6, 7, 8, 16
-
[37]
Huang, W
N. Huang, W. Zheng, C. Xu, K. Keutzer, S. Zhang, A. Kanazawa, and Q. Wang. Segment any motion in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3406–3416, 2025. 3
2025
-
[38]
W. Jin, Q. Dai, C. Luo, S.-H. Baek, and S. Cho. Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis. InProc. CVPR, 2025. 3
2025
-
[39]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. Cotracker: It is better to track together. InProc. ECCV, 2024. 3
2024
-
[40]
J. Kopf, X. Rong, and J.-B. Huang. Robust consistent video depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1611–1621, 2021. 3
2021
-
[41]
Q. Li, Z. Xing, R. Wang, H. Zhang, Q. Dai, and Z. Wu. Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12112–12123,
-
[42]
Z. Li, S. Niklaus, N. Snavely, and O. Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. InCVPR, 2021. 3
2021
-
[43]
Z. Li, R. Tucker, F. Cole, Q. Wang, L. Jin, V. Ye, A. Kanazawa, A. Holynski, and N. Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025. 3
2025
-
[44]
Li, H.-X
Z. Li, H.-X. Yu, W. Liu, Y. Yang, C. Herrmann, G. Wetzstein, and J. Wu. Wonderplay: Dynamic 3d scene generation from a single image and actions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9080–9090, 2025. 2, 3
2025
- [45]
-
[46]
Liang, B
F. Liang, B. Wu, J. Wang, L. Yu, K. Li, Y. Zhao, I. Misra, J.-B. Huang, P. Zhang, P. Vajda, et al. Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8207–8216, 2024. 3
2024
-
[47]
H. Lin, S. Chen, J. Liew, D. Y. Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 5
work page internal anchor Pith review arXiv 2025
-
[48]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
S. Liu, C. Guo, B. Zhou, and J. Wang. Ponimator: Unfolding interactive pose for versatile human-human interaction animation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12068–12077, 2025. 2, 3
2025
-
[50]
S. Liu, Z. Ren, S. Gupta, and S. Wang. Physgen: Rigid-body physics-grounded image-to-video generation. InEuropean Conference on Computer Vision, pages 360–378. Springer, 2024. 2, 3
2024
- [51]
-
[52]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 8
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
J. Lv, Y. Huang, M. Yan, J. Huang, J. Liu, Y. Liu, Y. Wen, X. Chen, and S. Chen. Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1430–1440, 2024. 3
2024
- [54]
-
[55]
Montanaro, L
A. Montanaro, L. Savant Aira, E. Aiello, D. Valsesia, and E. Magli. Motioncraft: Physics-based zero-shot video generation.Advances in Neural Information Processing Systems, 37:123155–123181, 2024. 3
2024
-
[56]
M. Niu, X. Cun, X. Wang, Y. Zhang, Y. Shan, and Y. Zheng. Mofa-video: Controllable image animation via generative motion field adaptions in frozen image-to-video diffusion model. InEuropean conference on computer vision, pages 111–128. Springer, 2024. 3
2024
-
[57]
C. Pan, B. Yaman, T. Nesti, A. Mallik, A. G. Allievi, S. Velipasalar, and L. Ren. Vlp: Vision language planning for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14760–14769, 2024. 3
2024
-
[58]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 4
2023
-
[59]
N. Ravi, V. Gabeur, Y.-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V. Alwala, N. Carion, C.-Y. Wu, R. Girshick, P. Dollár, and C. Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 6, 7, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
X. Ren, T. Shen, J. Huang, H. Ling, Y. Lu, M. Nimier-David, T. Müller, A. Keller, S. Fidler, and J. Gao. Gen3c: 3d- informed world-consistent video generation with precise camera control. InCVPR, pages 6121–6132, 2025. 8, 9, 16
2025
-
[61]
Rockwell, J
C. Rockwell, J. Tung, T.-Y. Lin, M.-Y. Liu, D. F. Fouhey, and C.-H. Lin. Dynamic camera poses and where to find them. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12444–12455, 2025. 8, 9
2025
-
[62]
X. Shi, Z. Huang, F.-Y. Wang, W. Bian, D. Li, Y. Zhang, M. Zhang, K. C. Cheung, S. See, H. Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024. 3
2024
-
[63]
Siarohin, S
A. Siarohin, S. Lathuilière, S. Tulyakov, E. Ricci, and N. Sebe. First order motion model for image animation. In NeurIPS, 2019. 3
2019
-
[64]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024. 16
2024
-
[65]
Tulyakov, M.-Y
S. Tulyakov, M.-Y. Liu, X. Yang, and J. Kautz. Mocogan: Decomposing motion and content for video generation. In CVPR, 2018. 3
2018
-
[66]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018. 8
work page internal anchor Pith review arXiv 2018
-
[67]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2, 4, 8, 9, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [68]
- [69]
- [70]
-
[71]
R. Wang, S. Xu, C. Dai, J. Xiang, Y. Deng, X. Tong, and J. Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision, 2024. 17
2024
-
[72]
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu. Drivedreamer: Towards real-world-drive world models for autonomous driving. InEuropean conference on computer vision, pages 55–72. Springer, 2024. 2
2024
-
[73]
Y. Wang, P. Bilinski, F. Bremond, and A. Dantcheva. G3AN: Disentangling appearance and motion for video generation. InCVPR, 2020. 3 26 Appendix
2020
- [74]
-
[75]
Z. Wang, Z. Yuan, X. Wang, T. Chen, M. Xia, P. Luo, and Y. Shan. Motionctrl: A unified and flexible motion controller for video generation. InSIGGRAPH, 2024. 2, 3
2024
-
[76]
T.-H. Wu, L. Lian, J. E. Gonzalez, B. Li, and T. Darrell. Self-correcting llm-controlled diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6327–6336, 2024. 3
2024
-
[77]
W. Wu, Z. Li, Y. Gu, R. Zhao, Y. He, D. J. Zhang, M. Z. Shou, Y. Li, T. Gao, and D. Zhang. Draganything: Motion control for anything using entity representation. InProc. ECCV, 2024. 2, 3
2024
-
[78]
X. Wu, D. Paschalidou, J. Gao, A. Torralba, L. Leal-Taixé, O. Russakovsky, S. Fidler, and J. Lorraine. Where is motion from? scalable motion attribution for video generation models. In1st Workshop on Reliable and Interactive World Model in Computer Vision Non Archival, 2026. 3
2026
-
[79]
J. Xing, L. Mai, C. Ham, J. Huang, A. Mahapatra, C.-W. Fu, T.-T. Wong, and F. Liu. Motioncanvas: Cinematic shot design with controllable image-to-video generation. InSIGGRAPH, 2025. 3
2025
-
[80]
arXiv preprint arXiv:2310.061141(2), 6 (2023)
M.Yang, Y.Du, K.Ghasemipour, J.Tompson, D.Schuurmans, andP.Abbeel. Learninginteractivereal-worldsimulators. arXiv preprint arXiv:2310.06114, 1(2):6, 2023. 2
-
[81]
Vlipp: Towardsphysicallyplausible video generation with vision and language informed physical prior
X.Yang,B.Li,Y.Zhang,Z.Yin,L.Bai,L.Ma,Z.Wang,J.Cai,T.-T.Wong,H.Lu,etal. Vlipp: Towardsphysicallyplausible video generation with vision and language informed physical prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12360–12370, 2025. 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.