Nano World Models: A Minimalist Implementation of Future Video Prediction
Pith reviewed 2026-06-30 18:50 UTC · model grok-4.3
The pith
A minimalist codebase supplies a unified interface for studying components of world models in future video prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Nano World Models, a minimalist codebase for future video prediction centered around diffusion forcing. Nano World Models provides a unified interface for generative objectives, model scales, action-conditioning mechanisms, latent observation spaces, datasets, evaluation protocols, and long-horizon rollout procedures. This design enables controlled studies of world-modeling components that are often entangled across separate implementations. Through experiments across simple control environments, game simulation, and real-robot data, we examine how prediction parameterization, architecture scale, action injection, sampling budget, and domain complexity affect video prediction qu
What carries the argument
The Nano World Models codebase with its unified interface for generative objectives, model scales, action-conditioning mechanisms, latent observation spaces, datasets, evaluation protocols, and long-horizon rollout procedures, centered on diffusion forcing.
If this is right
- Prediction parameterization and architecture scale can be varied independently to measure their impact on video quality.
- Action injection and sampling budget can be isolated to observe effects on autoregressive rollout stability.
- Domain complexity can be compared directly across control tasks, games, and robot data using the same protocol.
- Releasing code and checkpoints allows other researchers to replicate and extend the controlled studies.
Where Pith is reading between the lines
- The standardized setup could reduce duplication of effort when different groups want to test new conditioning methods.
- It may support systematic scaling experiments by making it easier to swap model sizes without changing other variables.
- Longer-term use could reveal whether certain components matter more for downstream planning than for pure prediction accuracy.
Load-bearing premise
Experiments across simple control environments, game simulation, and real-robot data suffice to reveal how prediction parameterization, architecture scale, action injection, sampling budget, and domain complexity affect video prediction quality and autoregressive rollout behavior.
What would settle it
If the same design choices produce inconsistent effects on prediction quality when tested in the unified codebase versus in separate existing implementations.
Figures


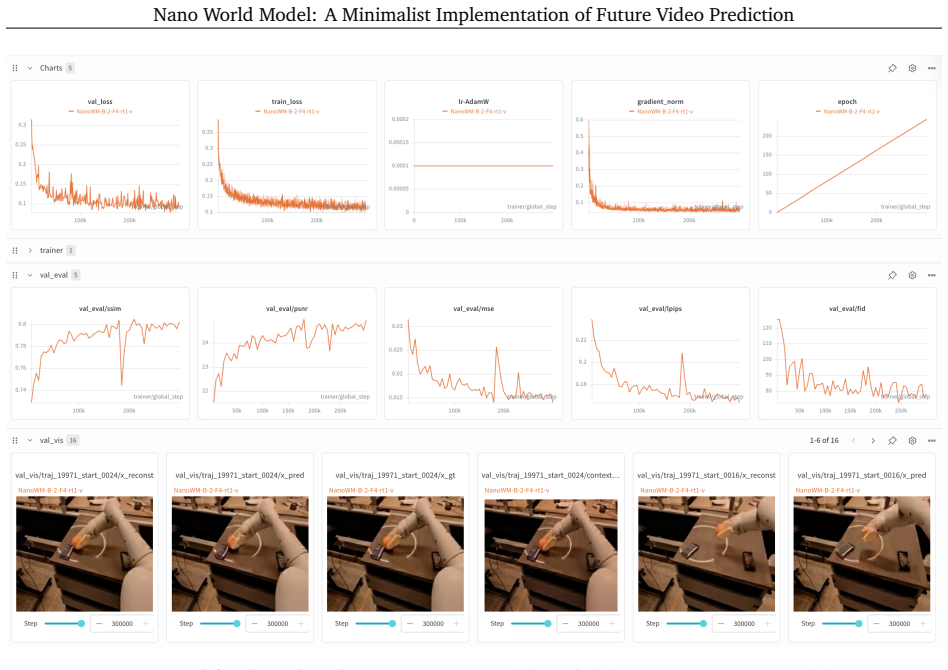
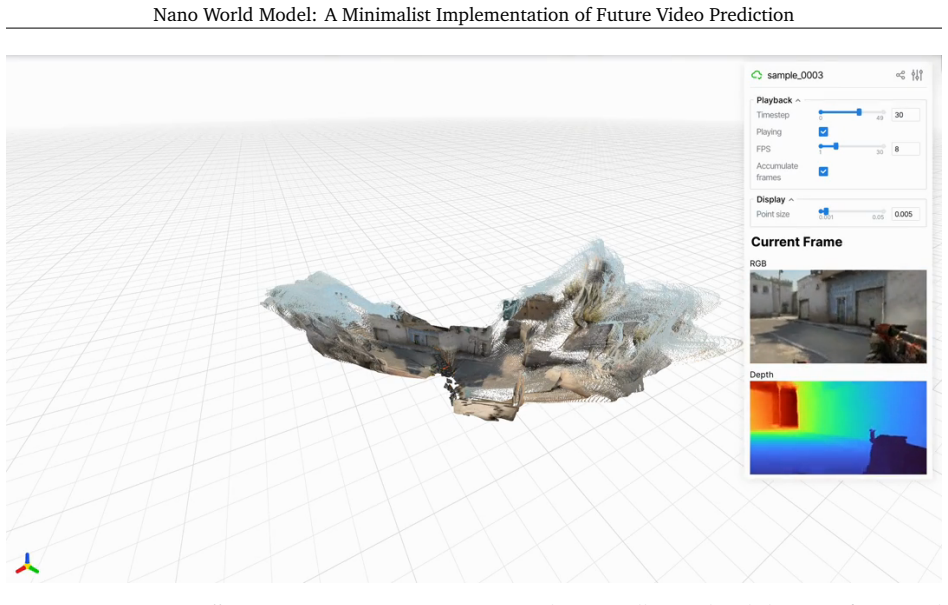

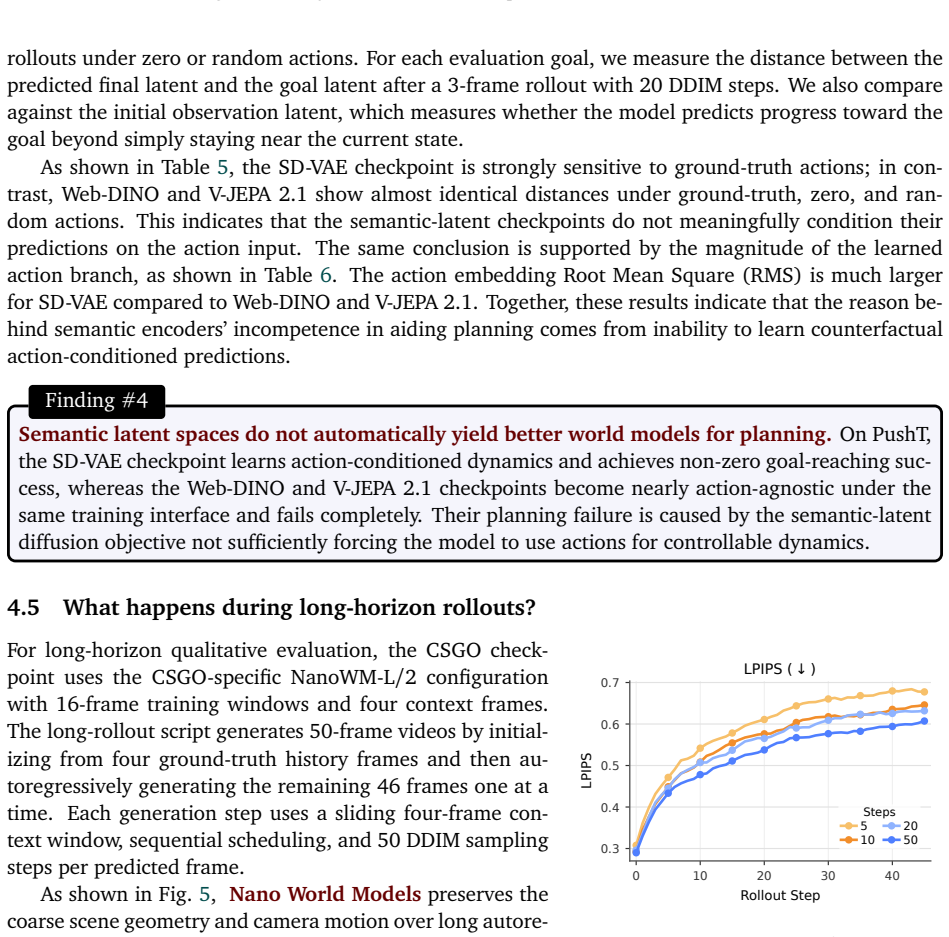
read the original abstract
World models have become a central paradigm for learning predictive simulators that support generation, planning, and decision-making. Yet, despite rapid progress in industry-scale interactive video generation, the broader research community still lacks compact, reproducible, and easily extensible implementations for studying the design choices underlying modern world models. We introduce Nano World Models, a minimalist codebase for future video prediction centered around diffusion forcing. Nano World Models provides a unified interface for generative objectives, model scales, action-conditioning mechanisms, latent observation spaces, datasets, evaluation protocols, and long-horizon rollout procedures. This design enables controlled studies of world-modeling components that are often entangled across separate implementations. Through experiments across simple control environments, game simulation, and real-robot data, we examine how prediction parameterization, architecture scale, action injection, sampling budget, and domain complexity affect video prediction quality and autoregressive rollout behavior. By releasing code, configurations, evaluation scripts, and pretrained checkpoints, Nano World Models aims to provide a compact yet extensible experimental substrate for open, reproducible, and scientific world-model research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Nano World Models, a minimalist codebase for future video prediction using diffusion forcing. It supplies a unified interface covering generative objectives, model scales, action-conditioning mechanisms, latent spaces, datasets, evaluation protocols, and long-horizon rollouts. Experiments across control environments, game simulation, and real-robot data examine effects of prediction parameterization, architecture scale, action injection, sampling budget, and domain complexity on prediction quality and autoregressive behavior. Code, configurations, evaluation scripts, and pretrained checkpoints are released to support reproducible research.
Significance. If the implementation delivers the claimed unified interface and the experiments isolate the listed factors, the work supplies a compact, extensible substrate that addresses the scarcity of reproducible world-model codebases. The explicit release of checkpoints and scripts strengthens reproducibility and enables controlled ablation studies that are otherwise entangled across separate codebases.
minor comments (3)
- [Abstract] The abstract lists the examined factors but does not name the concrete environments or datasets used; adding one sentence with the specific domains (e.g., the control suite, game title, and robot platform) would improve immediate readability.
- [Section 3] Section 3 (Implementation) refers to 'unified interface' without a diagram or table summarizing the modular components and their call signatures; a compact interface table would clarify extensibility for readers.
- [Section 4] Evaluation metrics are described in prose; providing the exact formulas or pseudocode for the rollout quality metric in an appendix would aid exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Nano World Models and the recommendation to accept. The summary accurately captures the paper's focus on a unified, minimalist codebase for diffusion-forcing-based video prediction and its emphasis on reproducibility through released code and checkpoints.
Circularity Check
No significant circularity identified
full rationale
The manuscript is an implementation release and empirical study introducing a unified codebase for diffusion-forcing world models, with experiments on control environments, games, and robot data. No derivations, uniqueness theorems, fitted-parameter predictions, or self-citation chains are present; the claims concern code interfaces and observed experimental trends rather than any quantity defined in terms of itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Cor- rado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems.arXiv preprint arXiv:1603.04467,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
URLhttps://arxiv.org/abs/2511.08544. Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. arXiv:2404.08471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://www.wandb. com/. Software available from wandb.com. Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv: 2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
URLhttp: //github.com/jax-ml/jax. Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics trans- former for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Geometric Context Transformer for Streaming 3D Reconstruction
15 Nano World Model: A Minimalist Implementation of Future Video Prediction Lin-Zhuo Chen, Jian Gao, Yihang Chen, Ka Leong Cheng, Yipengjing Sun, Liangxiao Hu, Nan Xue, Xing Zhu, Yujun Shen, Yao Yao, and Yinghao Xu. Geometric context transformer for streaming 3d reconstruction.arXiv preprint arXiv:2604.14141,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Wow: Towards a world omni- scient world model through embodied interaction,
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642,
-
[8]
doi: 10.1088/1742-5468/ad292b. David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar, et al. Scaling language-free visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 370–382,
-
[9]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[10]
Ctrl-World: A Controllable Generative World Model for Robot Manipulation
Google DeepMind Blog. Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022a. Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei- Fei. Pointworld: Scaling 3d world models for in-the-wild robotic manipulation.arXiv preprint arXiv:2601.03782, 2026a. Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normaliza- tion. InProceedings of the IEEE internati...
-
[14]
Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
16 Nano World Model: A Minimalist Implementation of Future Video Prediction Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems, 38:167283–167308, 2026b. Saurav Jha, Artem Zholus, Sarath Chandar, et al. Reconstructi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Latte: Latent Diffusion Transformer for Video Generation
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision, pages 23–40. Springer, 2024a. Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
URLhttps://pdoom.org/ jasmine.html. https://pdoom.org/blog.html. Lorenzo Mur-Labadia, Matthew Muckley , Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann Le- Cun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2506.01622 , year=
URLhttps://openreview.net/ forum?id=hidBHy1CAw. Jonathan Richens, David Abel, Alexis Bellot, and Tom Everitt. General agents contain world models. arXiv preprint arXiv:2506.01622,
- [23]
-
[24]
Lyra 2.0: Explorable Generative 3D Worlds
Tianchang Shen, Sherwin Bahmani, Kai He, Sangeetha Grama Srinivasan, Tianshi Cao, Jiawei Ren, Ruilong Li, Zian Wang, Nicholas Sharp, Zan Gojcic, et al. Lyra 2.0: Explorable generative 3d worlds. arXiv preprint arXiv:2604.13036,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advancing Open-source World Models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly . Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025a. Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Tesseract: learning 4d embodied world models,
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: learning 4d embodied world models.arXiv preprint arXiv:2504.20995,
-
[30]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.